Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewährte Methoden für die Verarbeitung von Zeitreihendaten in DynamoDB
Laut den allgemeinen Designgrundsätzen in Amazon DynamoDB empfiehlt es sich, die Anzahl der verwendeten Tabellen auf ein Minimum zu beschränken. Für die meisten Anwendungen benötigen Sie nur eine einzige Tabelle. Beachten Sie jedoch, dass mit Zeitreihendaten oft am besten umgegangen wird, indem eine Tabelle pro Anwendung pro Zeitraum verwendet wird.
Entwurfsmuster für Zeitreihendaten
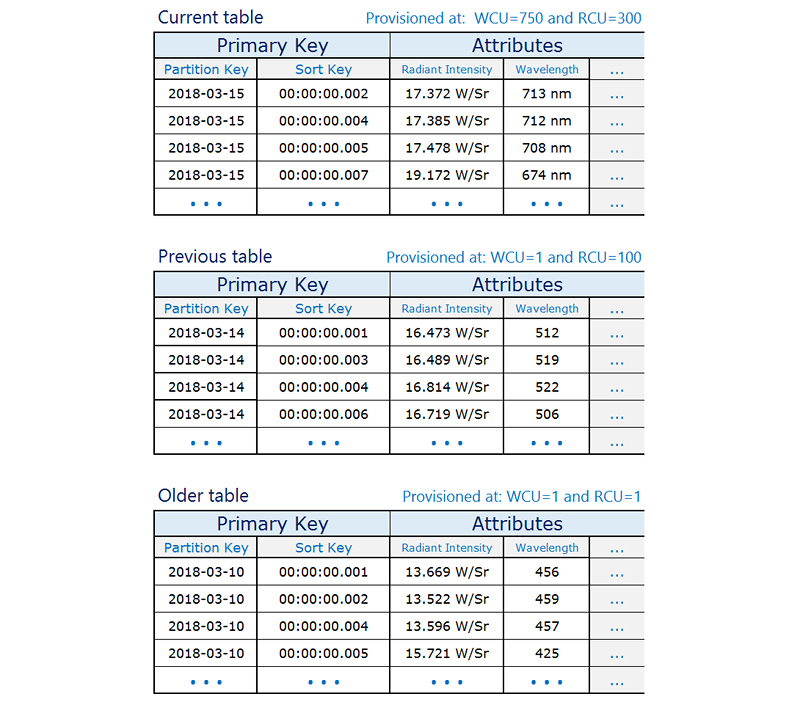
Stellen Sie sich ein typisches Zeitserienszenario vor, in dem Sie große Volumen an Ereignissen nachverfolgen möchten. Laut Ihrem Schreibzugriffsmuster haben alle Ereignisse, die aufgezeichnet werden, das Datum des aktuellen Tages. Ihr Lesezugriffsmuster könnte so aussehen, dass die Ereignisse des aktuellen Tages am häufigsten, die Ereignisse des Tags zuvor viel weniger häufig und die noch älteren Ereignisse überhaupt nur sehr wenig gelesen werden. Dies kann z. B. durch Integration des aktuellen Datums und der aktuellen Uhrzeit in den Primärschlüssel verwirklicht werden.
Diese Art von Szenario kann oft mit dem folgenden Entwurfsmuster effektiv bewältigt werden:
-
Erstellen Sie eine Tabelle pro Zeitraum, die mit der benötigten Lese- und Schreibkapazität und den erforderlichen Indizes bereitgestellt wird.
-
Erstellen Sie vor dem Ende jedes Zeitraums die Tabelle für den nächsten Zeitraum. Sobald der aktuelle Zeitraum endet, leiten Sie den Ereignisdatenverkehr zu der neuen Tabelle um. Sie können diesen Tabellen Namen zuweisen, die angeben, welche Zeiträume aufgezeichnet wurden.
-
Sobald nicht mehr in eine Tabelle geschrieben wird, reduzieren Sie die für sie bereitgestellte Schreibkapazität auf einen geringeren Wert (z. B. 1 WCU) und stellen Sie eine angemessene Lesekapazität bereit. Reduzieren Sie die bereitgestellte Lesekapazität mit dem Altern früherer Tabellen. Es empfiehlt sich, die die Tabellen zu archivieren oder zu löschen, deren Inhalt selten oder nie benötigt wird.
Auf diese Weise soll sichergestellt werden, dass die erforderlichen Ressourcen für den aktuellen Zeitraum mit dem höchsten Datenverkehrsvolumen zugeordnet werden und die Bereitstellung für ältere Tabellen, die nicht aktiv verwendet werden, herunterskaliert wird, wodurch Kosten gesenkt werden. Je nach Ihren geschäftlichen Anforderungen können Sie die Nutzung von Schreib-Sharding in Betracht ziehen, um den Datenverkehr gleichmäßig an den logischen Partitionsschlüssel zu verteilen. Weitere Informationen finden Sie unter Verwenden von Write-Sharding zur gleichmäßigen Verteilung von Workloads in Ihrer DynamoDB-Tabelle.
Beispiele für Zeitreihentabellen
Im Folgenden finden Sie ein Beispiel für Zeitreihendaten, in dem die aktuelle Tabelle mit einer höheren read/write Kapazität bereitgestellt wird und die älteren Tabellen herunterskaliert werden, da nur selten auf sie zugegriffen wird.