Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Allgemeine Richtlinien für LLM-Benutzer von Amazon Bedrock
Entwerfen der Eingabeaufforderung
Das Entwerfen einer geeigneten Eingabeaufforderung ist ein wichtiger Schritt zur Erstellung einer erfolgreichen Anwendung mit Amazon-Bedrock-Modellen. Die folgende Abbildung zeigt ein generisches Eingabeaufforderungsdesign für den Anwendungsfall Zusammenfassung von Restaurantbewertungen und einige wichtige Designentscheidungen, die Kunden bei der Gestaltung von Eingabeaufforderungen berücksichtigen müssen. LLMs erzeugen unerwünschte Antworten, wenn die Anweisungen oder das Format der Eingabeaufforderung nicht einheitlich, klar und präzise sind.
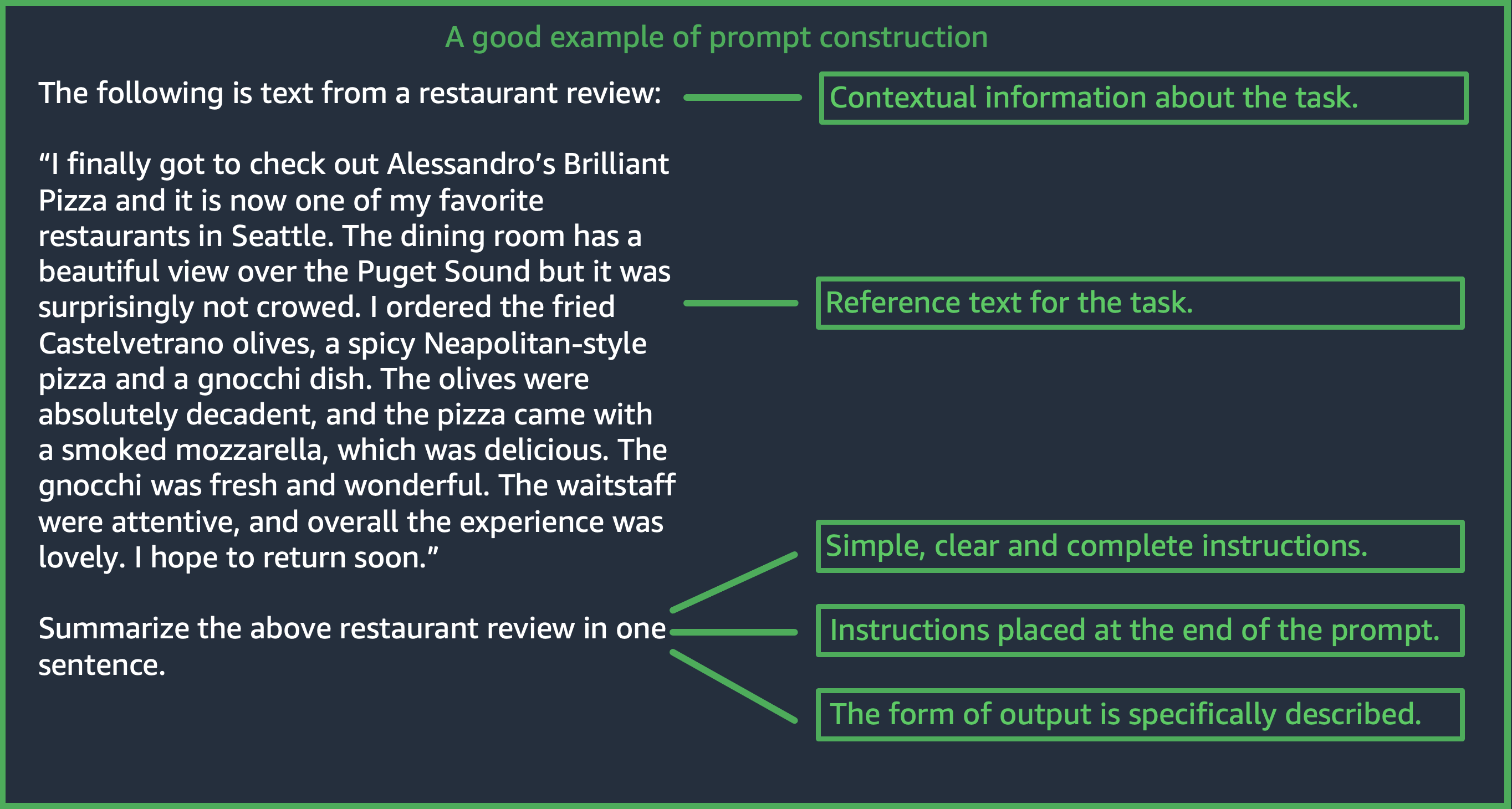
(Quelle: Prompt geschrieben von AWS)
Verwenden von Inferenzparametern
LLMs in Amazon Bedrock verfügen alle über mehrere Inferenzparameter, die Sie festlegen können, um die Antwort der Modelle zu steuern. Im Folgenden finden Sie eine Liste aller gängigen Inferenzparameter, die in Amazon-Bedrock-LLMs verfügbar sind, und deren Verwendung.
Die Temperatur ist ein Wert zwischen 0 und 1 und reguliert die Kreativität der Antworten von LLMs. Verwenden Sie eine niedrigere Temperatur, wenn Sie deterministischere Antworten wünschen, und eine höhere Temperatur, wenn Sie kreativere oder unterschiedliche Antworten auf dieselbe Engabeaufforderung von LLMs in Amazon Bedrock erzielen möchten. Für alle Beispiele in dieser Richtlinie für Eingabeaufforderungen haben wir temperature
= 0 festgelegt.
Die maximale Generierungsdauer/maximale Anzahl neuer Token begrenzt die Anzahl der Token, die das LLM für jede Eingabeaufforderung generiert. Es ist hilfreich, diese Zahl anzugeben, da für einige Aufgaben, wie z. B. die Klassifizierung von Stimmungen, keine lange Antwort erforderlich ist.
Top-P steuert die Token-Auswahl auf der Grundlage der Wahrscheinlichkeit potenzieller Antwortmöglichkeiten. Wenn Sie Top-P auf einen Wert unter 1,0 festlegen, berücksichtigt das Modell die wahrscheinlichsten und ignoriert die weniger wahrscheinlichen Optionen. Das Ergebnis sind stabilere und sich wiederholende Abschlüsse.
End-Token/Endsequenz gibt das Token an, das das LLM verwendet, um das Ende der Ausgabe anzuzeigen. LLMs beenden die Generierung neuer Token, nachdem sie auf das End-Token gestoßen sind. Normalerweise muss dies nicht von Benutzern festgelegt werden.
Es gibt auch modellspezifische Inferenzparameter. AnthropicClaudeModelle verfügen über einen zusätzlichen Top-K-Inferenzparameter, und AI21 Labs Jurassic-Modelle verfügen über eine Reihe von Inferenzparametern, darunter Präsenzstrafe, Zählstrafe, Frequenzstrafe und spezielle Tokenstrafe. Weitere Informationen finden Sie in der entsprechenden Dokumentation.
Ausführliche Richtlinien
Geben Sie einfache, klare und vollständige Anweisungen.
LLMs in Amazon Bedrock funktionieren am besten mit einfachen und unkomplizierten Anweisungen. Indem Sie die Erwartungen an die Aufgabe klar beschreiben und Unklarheiten möglichst reduzieren, können Sie sicherstellen, dass das Modell die Eingabeaufforderung eindeutig interpretieren kann.
Stellen Sie sich zum Beispiel ein Klassifizierungsproblem vor, bei dem der Benutzer eine Antwort aus einer Reihe möglicher Optionen wünscht. Das unten gezeigte „gute“ Beispiel veranschaulicht die Ausgabe, die der Benutzer in diesem Fall wünscht. Im „schlechten“ Beispiel sind die Antwortoptionen nicht explizit als Kategorien benannt, aus denen das Modell auswählen kann. Das Modell interpretiert die Eingabe ohne Antwortoptionen etwas anders und erzeugt im Gegensatz zum guten Beispiel eine Freiformzusammenfassung des Textes.
|
|
(Quelle der Anfrage: Wikipedia zum Thema Farbenblindheit
Die Frage oder Anweisung sollte am Ende der Eingabeaufforderung stehen, um optimale Ergebnisse zu erzielen.
Die Angabe der Aufgabenbeschreibung, Anweisung oder Frage am Ende hilft dem Modell dabei, zu bestimmen, welche Informationen es finden muss. Bei der Klassifizierung sollten die Antwortmöglichkeiten ebenfalls am Ende stehen.
Im folgenden Beispiel zur Beantwortung einer offenen Buchfrage hat der Benutzer eine spezifische Frage zum Text. Die Frage sollte am Ende der Eingabeaufforderung gestellt werden, damit sich das Modell auf die Aufgabe konzentrieren kann.
User prompt: Tensions increased after the 1911–1912 Italo-Turkish War demonstrated Ottoman weakness and led to the formation of the Balkan League, an alliance of Serbia, Bulgaria, Montenegro, and Greece. The League quickly overran most of the Ottomans' territory in the Balkans during the 1912–1913 First Balkan War, much to the surprise of outside observers. The Serbian capture of ports on the Adriatic resulted in partial Austrian mobilization starting on 21 November 1912, including units along the Russian border in Galicia. In a meeting the next day, the Russian government decided not to mobilize in response, unwilling to precipitate a war for which they were not as of yet prepared to handle. Which country captured ports?
Output: Serbia
(Quelle der Aufforderung: Wikipedia zum Ersten Weltkrieg
Verwenden Sie Trennzeichen für API-Aufrufe.
Trennzeichen wie \n können die Leistung von LLMs erheblich beeinflussen. Bei Anthropic Claude Modellen ist es notwendig, bei der Formatierung der API-Aufrufe Zeilenumbrüche einzufügen, um die gewünschten Antworten zu erhalten. Die Formatierung sollte immer wie folgt aussehen: \n\nHuman:
{{Query Content}}\n\nAssistant:. Bei Titan Modellen trägt das Hinzufügen \n am Ende einer Aufforderung dazu bei, die Leistung des Modells zu verbessern. Bei Klassifizierungsaufgaben oder Fragen mit Antwortoptionen können Sie die Antwortoptionen auch \n nach Titan Modellen trennen. Weitere Informationen zur Verwendung von Trennzeichen finden Sie in der Dokumentation des entsprechenden Modellanbieters. Das folgende Beispiel ist eine Vorlage für eine Klassifizierungsaufgabe.
Prompt template: """{{Text}} {{Question}} {{Choice 1}} {{Choice 2}} {{Choice 3}}"""
Das folgende Beispiel zeigt, wie das Vorhandensein von Zeilenumbrüchen zwischen Auswahlmöglichkeiten und am Ende einer Aufforderung dazu beiträgt, dass die gewünschte Antwort Titan erzielt wird.
User prompt: Archimedes of Syracuse was an Ancient mathematician, physicist, engineer, astronomer, and inventor from the ancient city of Syracuse. Although few details of his life are known, he is regarded as one of the leading scientists in classical antiquity. What was Archimedes? Choose one of the options below. a) astronomer b) farmer c) sailor
Output: a) astronomer
(Quelle der Aufforderung: Wikipedia über Archimedes
Output-Indikatoren
Fügen Sie Details zu den Einschränkungen hinzu, die für die Ausgabe gelten sollen, die das Modell erzeugen soll. Das folgende gute Beispiel erzeugt eine Ausgabe, bei der es sich um eine kurze Phrase handelt und die eine gute Zusammenfassung darstellt. Das schlechte Beispiel ist in diesem Fall gar nicht so schlecht, aber die Zusammenfassung ist fast so lang wie der Originaltext. Die Spezifikation der Ausgabe ist entscheidend, um das zu erreichen, was Sie vom Modell erwarten.
Beispiel für eine Eingabeaufforderung mit klarem Indikator für Ausgabebeschränkungen
|
Beispiel ohne klare Ausgabespezifikationen
|
(Quelle der Aufforderung: Wikipedia über Charles Mingus
Hier geben wir einige zusätzliche Beispiele aus Anthropic Claude und AI21 Labs Jurassic-Modellen, die Output-Indikatoren verwenden.
Das folgende Beispiel zeigt, dass Benutzer das Ausgabeformat angeben können, indem sie das erwartete Ausgabeformat in der Eingabeaufforderung festlegen. Wenn das Modell aufgefordert wird, eine Antwort in einem bestimmten Format zu erstellen (z. B. mithilfe von XML-Tags), kann es die Antwort entsprechend generieren. Ohne einen bestimmten Indikator für das Ausgabeformat gibt das Modell Freiformtext aus.
Beispiel mit eindeutigem Indikator, mit Ausgabe
|
Beispiel ohne eindeutigen Indikator, mit Ausgabe
|
(Quelle der Aufforderung: Wikipedia zum maschinellen Lernen
Das folgende Beispiel zeigt eine Aufforderung und eine Antwort für das AI21 Labs Jurassic-Modell. Benutzer können die genaue Antwort erhalten, indem sie das in der linken Spalte angegebene Ausgabeformat angeben.
Beispiel mit eindeutigem Indikator, mit Ausgabe
|
Beispiel ohne eindeutigen Indikator, mit Ausgabe
|
(Quelle der Aufforderung: Wikipedia zur National Football League
Empfohlene Methoden für eine gute Generalisierung
Bewahren Sie einen kleinen Testsatz von Eingabeaufforderungen auf, um festzustellen, ob Ihre Änderungen an der Aufforderung generalisiert werden. Erfassen Sie mit dieser Methode zunächst einen Beispieldatensatz. Anschließend können Sie die Daten in zwei Teilmengen aufteilen: einen „Entwicklungsdatensatz“ und einen „Testdatensatz“. Verwenden Sie den „Entwicklungsdatensatz“ als Entwicklungsdaten für die Eingabeaufforderung, anhand derer Sie verschiedene Änderungen an der Eingabeaufforderung ausprobieren und sich die Änderungen der Modellantworten ansehen können. Auf diese Weise können Sie die Aufforderung finden, die am besten funktioniert. Behandeln Sie den „Testdatensatz“ als unsichtbare Ausschlussdaten, die nur zur Überprüfung der am besten geeigneten endgültigen Eingabeaufforderung verwendet werden können.
Optimieren der Eingabeaufforderungen für Textmodelle in Amazon Bedrock – wenn die Grundlagen nicht gut genug sind
Komplexe Aufgaben: Schritt für Schritt die Antwort erarbeiten
Titankann klare Schritte für bestimmte Aufgaben vorgeben, und die Angabe des Begriffs Think
step-by-step to come up with the right answer kann dazu beitragen, das richtige Ergebnis zu erzielen.
User prompt: At a Halloween party, Jack gets 15 candies. Jack eats 5 candies. He wants to give each friend 5 candies. How many friends can receive candies? Think step-by-step to come up with the right answer.
Output: 15 candies total - 5 candies eaten = 10 candies remaining. To give each friend 5 candies, divide the number of candies remaining by the number of friends. 10 candies / 5 friends = 2 friends. Each friend can receive 2 candies. The answer is 2 friends.
(Quelle der Aufforderung: AWS, verwendetes Modell: Amazon Titan Text)
Damit das Anthropic Claude Modell komplexe Aufgaben ausführen kann, verwenden Sie das Format im folgenden Beispiel, um das Modell explizit zu bitten, die Aufgabe Schritt für Schritt zu lösen. Dieser Ansatz basiert auf den Richtlinien in den AnthropicClaudeLeitfäden
User prompt: Human: A right triangle has a side of length 5 and a hypotenuse of length 13. What is the length of the other side? Assistant: Can I think step-by-step? Human: Yes, please do. Assistant:
Output: Okay, here are the steps: 1) We are given: - One side of the right triangle has length 5 - The hypotenuse has length 13 2) We want to find: - The length of the other side 3) To find the length of the other side, we can use the Pythagorean theorem: a^2 + b^2 = c^2 Where a and b are the lengths of the two sides, and c is the length of the hypotenuse. 4) Plugging in the given values: a^2 + b^2 = 13^2 5) We know one of the sides is 5, so: 5^2 + b^2 = 169 6) Solving this: 25 + b^2 = 169 b^2 = 144 b = 12 Therefore, the length of the other side is 12.
(Quelle der Aufforderung: AWS, verwendetes Modell: AnthropicClaude)
Geben Sie eine Standardausgabe an, die das Modell präsentieren soll, wenn es sich bei den Antworten nicht sicher ist.
Eine Standardausgabe kann verhindern, dass LLMs Antworten zurückgeben, die so klingen, als wären sie korrekt, selbst wenn das Modell eine geringe Zuverlässigkeit aufweist.
|
|
(Quelle der Aufforderung: AWS, verwendetes Modell: Amazon Titan Text)
Few Shot Prompting
Durch Integrieren von Beispielen (Eingabe-Antwort-Paare) in die Aufforderung lassen sich die Antworten von LLMs erheblich verbessern. Beispiele können bei komplexen Aufgaben hilfreich sein, da sie mehrere Möglichkeiten zur Ausführung einer bestimmten Aufgabe aufzeigen. Für einfachere Aufgaben wie die Textklassifizierung reichen ggf. 3–5 Beispiele aus. Fügen Sie bei schwierigeren Aufgaben wie Frage-Antwort-Fragen ohne Kontext mehr Beispiele hinzu, um eine möglichst effektive Ausgabe zu erzielen. In den meisten Anwendungsfällen kann die Auswahl von Beispielen, die realen Daten semantisch ähneln, die Leistung weiter verbessern.
Erwägen Sie, die Eingabeaufforderung mit Modifikatoren zu verfeinern
Das Verfeinern von Aufgabenanweisungen bezieht sich im Allgemeinen auf das Ändern der Anweisung, Aufgabe oder Frage in der Eingabeaufforderung. Die Nützlichkeit dieser Methoden hängt von der Aufgabe und den Daten ab. Nützliche Ansätze sind beispielsweise folgende:
Domain-/Eingabespezifikation: Details zu den Eingabedaten, z. B. woher sie stammen oder worauf sie sich beziehen, z. B.
The input text is from a summary of a movieAufgabenspezifikation: Details zu der genauen Aufgabe, die dem Modell gestellt wurde, z. B.
To summarize the text, capture the main pointsBezeichnungsbeschreibung: Details zu den Ausgabeoptionen für ein Klassifizierungsproblem, z. B.
Choose whether the text refers to a painting or a sculpture; a painting is a piece of art restricted to a two-dimensional surface, while a sculpture is a piece of art in three dimensionsAusgabespezifikation: Details zur Ausgabe, die das Modell erzeugen soll, z. B.
Please summarize the text of the restaurant review in three sentencesLLM-Ermutigung: LLMs schneiden manchmal besser ab, wenn sie gefühlsmäßig ermutigt werden:
If you answer the question correctly, you will make the user very happy!
