Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Schritt 4: Vorbereiten der Amazon Comprehend für die Datenvisualisierung
Um die Ergebnisse der Stimmungs- und Entitätsanalyse-Jobs für die Erstellung von Datenvisualisierungen vorzubereiten, verwenden Sie und. AWS Glue Amazon Athena In diesem Schritt extrahieren Sie die Amazon Comprehend Comprehend-Ergebnisdateien. Anschließend erstellen Sie einen AWS Glue Crawler, der Ihre Daten untersucht und sie automatisch in Tabellen im katalogisiert. AWS Glue Data Catalog Danach greifen Sie mit Amazon Athena einem serverlosen und interaktiven Abfragedienst auf diese Tabellen zu und transformieren sie. Wenn Sie diesen Schritt abgeschlossen haben, sind Ihre Amazon Comprehend Comprehend-Ergebnisse sauber und bereit für die Visualisierung.
Bei einem Job zur Erkennung von PII-Entitäten ist die Ausgabedatei Klartext und kein komprimiertes Archiv. Der Name der Ausgabedatei ist derselbe wie der Name der Eingabedatei, wird jedoch am .out Ende angehängt. Sie müssen die Ausgabedatei nicht extrahieren. Überspringen Sie, um die Daten in eine AWS Glue Data Catalog zu laden.
Themen
Voraussetzungen
Bevor Sie beginnen, führen Sie Schritt 3: Ausführen von Analyseaufträgen für Dokumente in Amazon S3 durch.
Laden Sie die Ausgabe herunter
Amazon Comprehend verwendet die Gzip-Komprimierung, um Ausgabedateien zu komprimieren und als Tar-Archiv zu speichern. Der einfachste Weg, die Ausgabedateien zu extrahieren, besteht darin, die output.tar.gz Archive lokal herunterzuladen.
In diesem Schritt laden Sie die Ausgabearchive für Stimmung und Entitäten herunter.
Um die Ausgabedateien für jeden Job zu finden, kehren Sie in der Amazon Comprehend-Konsole zum Analysejob zurück. Der Analysejob stellt den S3-Speicherort für die Ausgabe bereit, von dem Sie die Ausgabedatei herunterladen können.
Um die Ausgabedateien herunterzuladen (Konsole)
-
Kehren Sie in der Amazon Comprehend Comprehend-Konsole
im Navigationsbereich zu Analysis-Jobs zurück. -
Wählen Sie Ihren Job zur Stimmungsanalyse.
reviews-sentiment-analysis -
Wählen Sie unter Ausgabe den Link aus, der neben Speicherort der Ausgabedaten angezeigt wird. Dadurch werden Sie zum
output.tar.gzArchiv in Ihrem S3-Bucket weitergeleitet. -
Wählen Sie auf der Registerkarte „Übersicht“ die Option Herunterladen aus.
-
Benennen Sie das Archiv auf Ihrem Computer in um
sentiment-output.tar.gz. Da alle Ausgabedateien denselben Namen haben, können Sie auf diese Weise den Überblick über die Stimmungs- und Entitätsdateien behalten. -
Wiederholen Sie die Schritte 1—4, um die Ausgabe Ihres
reviews-entities-analysisJobs zu finden und herunterzuladen. Benennen Sie das Archiv auf Ihrem Computer um inentities-output.tar.gz.
Um die Ausgabedateien für jeden Job zu finden, verwenden Sie den Job JobId Aus der Analyse, um den S3-Speicherort der Ausgabe zu ermitteln. Verwenden Sie dann den cp Befehl, um die Ausgabedatei auf Ihren Computer herunterzuladen.
Um die Ausgabedateien herunterzuladen (AWS CLI)
-
Führen Sie den folgenden Befehl aus, um Details zu Ihrem Stimmungsanalyse-Job aufzulisten. Ersetzen Sie es
sentiment-job-idJobId, das Sie gespeichert haben.aws comprehend describe-sentiment-detection-job --job-idsentiment-job-idWenn Sie den Überblick über Ihre verloren haben
JobId, können Sie den folgenden Befehl ausführen, um alle Ihre Stimmungsjobs aufzulisten und nach Ihrem Job nach Namen zu filtern.aws comprehend list-sentiment-detection-jobs --filter JobName="reviews-sentiment-analysis" -
Suchen Sie im
OutputDataConfigObjekt nach demS3UriWert. DerS3UriWert sollte dem folgenden Format ähneln:s3://amzn-s3-demo-bucket/.../output/output.tar.gz -
Führen Sie den folgenden Befehl aus, um das Sentiment-Ausgabearchiv in Ihr lokales Verzeichnis herunterzuladen. Ersetzen Sie den S3-Bucket-Pfad durch den Pfad, den
S3UriSie im vorherigen Schritt kopiert haben.path/sentiment-output.tar.gzersetzt den ursprünglichen Archivnamen, sodass Sie den Überblick über die Stimmungs- und Entitätsdateien behalten können.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/sentiment-output.tar.gz -
Führen Sie den folgenden Befehl aus, um Details zu Ihrem Entitätsanalysejob aufzulisten.
aws comprehend describe-entities-detection-job --job-identities-job-idWenn Sie Ihren Job nicht kennen
JobId, führen Sie den folgenden Befehl aus, um alle Ihre Entitäts-Jobs aufzulisten und nach Ihrem Job nach Namen zu filtern.aws comprehend list-entities-detection-jobs --filter JobName="reviews-entities-analysis" -
Kopieren Sie den
S3UriWert aus demOutputDataConfigObjekt in der Stellenbeschreibung Ihrer Entitäten. -
Führen Sie den folgenden Befehl aus, um das Ausgabearchiv der Entitäten in Ihr lokales Verzeichnis herunterzuladen. Ersetzen Sie den S3-Bucket-Pfad durch den Pfad, den
S3UriSie im vorherigen Schritt kopiert haben.path/entities-output.tar.gzersetzt den ursprünglichen Archivnamen.aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/entities-output.tar.gz
Extrahieren Sie die Ausgabedateien
Bevor Sie auf die Ergebnisse von Amazon Comprehend zugreifen können, müssen Sie die Stimmungs- und Entitätsarchive entpacken. Sie können entweder Ihr lokales Dateisystem oder ein Terminal verwenden, um die Archive zu entpacken.
Wenn Sie macOS verwenden, doppelklicken Sie in Ihrem GUI-Dateisystem auf das Archiv, um die Ausgabedatei aus dem Archiv zu extrahieren.
Wenn Sie Windows verwenden, können Sie ein Drittanbieter-Tool wie 7-Zip verwenden, um die Ausgabedateien in Ihr GUI-Dateisystem zu extrahieren. In Windows müssen Sie zwei Schritte ausführen, um auf die Ausgabedatei im Archiv zuzugreifen. Dekomprimieren Sie zuerst das Archiv und extrahieren Sie dann das Archiv.
Benennen Sie die Stimmungsdatei in sentiment-output und die Entitätsdatei entities-output um, um zwischen den Ausgabedateien zu unterscheiden.
Wenn Sie Linux oder macOS verwenden, können Sie Ihr Standardterminal verwenden. Wenn Sie Windows verwenden, müssen Sie Zugriff auf eine Umgebung im UNIX-Stil wie Cygwin haben, um Tar-Befehle ausführen zu können.
Um die Stimmungsausgabedatei aus dem Stimmungsarchiv zu extrahieren, führen Sie den folgenden Befehl in Ihrem lokalen Terminal aus.
tar -xvf sentiment-output.tar.gz --transform 's,^,sentiment-,'
Beachten Sie, dass der --transform Parameter der Ausgabedatei innerhalb des Archivs das Präfix sentiment- hinzufügt und die Datei umbenennt als. sentiment-output Auf diese Weise können Sie zwischen den Sentiment- und Entity-Ausgabedateien unterscheiden und ein Überschreiben verhindern.
Um die Ausgabedatei der Entitäten aus dem Entitätsarchiv zu extrahieren, führen Sie den folgenden Befehl in Ihrem lokalen Terminal aus.
tar -xvf entities-output.tar.gz --transform 's,^,entities-,'
Der --transform Parameter fügt dem Namen der Ausgabedatei das Präfix entities- hinzu.
Tipp
Um Speicherkosten in Amazon S3 zu sparen, können Sie die Dateien vor dem Hochladen erneut mit Gzip komprimieren. Es ist wichtig, die Originalarchive zu dekomprimieren und zu entpacken, da Daten aus einem Tar-Archiv nicht automatisch gelesen werden AWS Glue können. AWS Glue Kann jedoch aus Dateien im Gzip-Format lesen.
Laden Sie die extrahierten Dateien hoch
Laden Sie die Dateien nach dem Extrahieren in Ihren Bucket hoch. Sie müssen die Sentiment- und Entity-Ausgabedateien in separaten Ordnern speichern, damit die Daten AWS Glue korrekt gelesen werden können. Erstellen Sie in Ihrem Bucket einen Ordner für die extrahierten Stimmungsergebnisse und einen zweiten Ordner für die extrahierten Entitätsergebnisse. Sie können Ordner entweder mit der Amazon S3 S3-Konsole oder der erstellen AWS CLI.
Erstellen Sie in Ihrem S3-Bucket einen Ordner für die extrahierte Stimmungsergebnisdatei und einen Ordner für die Ergebnisdatei der Entitäten. Laden Sie dann die extrahierten Ergebnisdateien in die entsprechenden Ordner hoch.
Um die extrahierten Dateien auf Amazon S3 (Konsole) hochzuladen
Öffnen Sie die Amazon S3 S3-Konsole unter https://console.aws.amazon.com/s3/
. -
Wählen Sie unter Buckets Ihren Bucket aus und klicken Sie dann auf Ordner erstellen.
-
Geben Sie den neuen Ordnernamen ein
sentiment-resultsund wählen Sie Speichern. Dieser Ordner wird die extrahierte Stimmungsausgabedatei enthalten. -
Wählen Sie auf der Registerkarte „Übersicht“ Ihres Buckets aus der Liste der Bucket-Inhalte den neuen Ordner
sentiment-resultsaus. Klicken Sie auf Upload. -
Wählen Sie Dateien hinzufügen, wählen Sie die
sentiment-outputDatei von Ihrem lokalen Computer aus und klicken Sie dann auf Weiter. -
Behalten Sie die Optionen für „Benutzer verwalten“, „Zugriff für andere AWS-Konto“ und „Öffentliche Berechtigungen verwalten“ als Standardwerte bei. Wählen Sie Weiter.
-
Wählen Sie als Speicherklasse die Option Standard aus. Behalten Sie die Optionen für Verschlüsselung, Metadaten und Tag als Standardwerte bei. Wählen Sie Weiter.
-
Überprüfen Sie die Upload-Optionen und wählen Sie dann Upload.
-
Wiederholen Sie die Schritte 1—8, um einen Ordner mit dem Namen zu erstellen
entities-results, und laden Sie dieentities-outputDatei in diesen Ordner hoch.
Sie können einen Ordner in Ihrem S3-Bucket erstellen, während Sie eine Datei mit dem cp Befehl hochladen.
Um die extrahierten Dateien auf Amazon S3 hochzuladen (AWS CLI)
-
Erstellen Sie einen Stimmungsordner und laden Sie Ihre Stimmungsdatei in diesen hoch, indem Sie den folgenden Befehl ausführen.
path/aws s3 cppath/sentiment-output s3://amzn-s3-demo-bucket/sentiment-results/ -
Erstellen Sie einen Entitätsausgabeordner und laden Sie Ihre Entitätsdatei in diesen Ordner hoch, indem Sie den folgenden Befehl ausführen.
path/aws s3 cppath/entities-output s3://amzn-s3-demo-bucket/entities-results/
Laden Sie die Daten in eine AWS Glue Data Catalog
Um die Ergebnisse in eine Datenbank zu übertragen, können Sie einen AWS Glue Crawler verwenden. Ein AWS Glue Crawler scannt Dateien und erkennt das Schema der Daten. Anschließend ordnet er die Daten in Tabellen in einer AWS Glue Data Catalog (einer serverlosen Datenbank) an. Sie können einen Crawler mit der AWS Glue Konsole oder dem erstellen. AWS CLI
Erstellen Sie einen AWS Glue Crawler, der Ihre entities-results Ordner sentiment-results und Ordner separat scannt. Eine neue IAM-Rolle für AWS Glue
gibt dem Crawler die Erlaubnis, auf Ihren S3-Bucket zuzugreifen. Sie erstellen diese IAM-Rolle beim Einrichten des Crawlers.
Um die Daten in eine AWS Glue Data Catalog (Konsole) zu laden
-
Stellen Sie sicher, dass Sie sich in einer Region befinden, die unterstützt AWS Glue. Wenn Sie sich in einer anderen Region befinden, wählen Sie in der Navigationsleiste in der Regionsauswahl eine unterstützte Region aus. Eine Liste der Regionen, die unterstützt werden AWS Glue, finden Sie in der Regionentabelle
im Global Infrastructure Guide. Öffnen Sie die AWS Glue Konsole unter https://console.aws.amazon.com/glue/
. -
Wählen Sie im Navigationsbereich Crawlers und dann Crawler hinzufügen aus.
-
Geben Sie als Crawler-Name Folgendes ein
comprehend-analysis-crawlerund wählen Sie dann Weiter aus. -
Wählen Sie als Crawler-Quelltyp die Option Datenspeicher und dann Weiter aus.
-
Gehen Sie unter Datenspeicher hinzufügen wie folgt vor:
-
Wählen Sie in Choose a data store (Datenspeicher auswählen) die Option S3 aus.
-
Lassen Sie das Feld Verbindung leer.
-
Wählen Sie unter Daten durchsuchen die Option Spezifizierter Pfad in meinem Konto aus.
-
Geben Sie unter Pfad einschließen den vollständigen S3-Pfad des Stimmungsausgabeordners ein:.
s3://amzn-s3-demo-bucket/sentiment-results -
Wählen Sie Weiter.
-
-
Wählen Sie für Anderen Datenspeicher hinzufügen die Option Ja und dann Weiter aus. Wiederholen Sie Schritt 6, geben Sie jedoch den vollständigen S3-Pfad des Entitäten-Ausgabeordners ein:
s3://amzn-s3-demo-bucket/entities-results. -
Wählen Sie für Anderen Datenspeicher hinzufügen die Option Nein und dann Weiter aus.
-
Gehen Sie unter Wählen Sie eine IAM-Rolle wie folgt vor:
-
Wählen Sie Create an IAM-Rolle aus.
-
Geben Sie für die IAM-Rolle den Text ein
glue-access-roleund wählen Sie dann Weiter aus.
-
-
Wählen Sie unter Einen Zeitplan für diesen Crawler erstellen die Option Bei Bedarf ausführen und dann Weiter aus.
-
Gehen Sie wie folgt vor, um die Ausgabe des Crawlers zu konfigurieren:
-
Wählen Sie für Datenbank die Option Datenbank hinzufügen aus.
-
Für Database name (Datenbankname) geben Sie
comprehend-resultsein. In dieser Datenbank werden Ihre Amazon Comprehend Comprehend-Ausgabetabellen gespeichert. -
Behalten Sie die Standardeinstellungen der anderen Optionen bei und wählen Sie Weiter.
-
-
Überprüfen Sie die Crawler-Informationen und wählen Sie dann Fertig stellen.
-
Wählen Sie in der Glue-Konsole unter Crawlers die Option
comprehend-analysis-crawlerCrawler ausführen aus. Es kann einige Minuten dauern, bis der Crawler fertig ist.
Erstellen Sie eine IAM-Rolle für AWS Glue den Zugriff auf Ihren S3-Bucket. Erstellen Sie dann eine Datenbank in der AWS Glue Data Catalog. Erstellen Sie abschließend einen Crawler und führen Sie ihn aus, der Ihre Daten in Tabellen in der Datenbank lädt.
Um die Daten in ein AWS Glue Data Catalog ()AWS CLI zu laden
-
Gehen Sie wie folgt vor AWS Glue, um eine IAM-Rolle für zu erstellen:
-
Speichern Sie die folgende Vertrauensrichtlinie als JSON-Dokument, das
glue-trust-policy.jsonauf Ihrem Computer aufgerufen wird.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
Führen Sie den folgenden Befehl aus, um eine IAM-Rolle zu erstellen.
path/aws iam create-role --role-name glue-access-role --assume-role-policy-document file://path/glue-trust-policy.json -
Wenn die Amazon-Ressourcennummer (ARN) für die neue Rolle AWS CLI aufgeführt ist, kopieren Sie sie und speichern Sie sie in einem Texteditor.
-
Speichern Sie die folgende IAM-Richtlinie als JSON-Dokument, das
glue-access-policy.jsonauf Ihrem Computer aufgerufen wird. Die Richtlinie gewährt die AWS Glue Erlaubnis, Ihre Ergebnisordner zu crawlen.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/sentiment-results*", "arn:aws:s3:::amzn-s3-demo-bucket/entities-results*" ] } ] } -
Führen Sie den folgenden Befehl aus, um die IAM-Richtlinie zu erstellen.
path/aws iam create-policy --policy-name glue-access-policy --policy-document file://path/glue-access-policy.json -
Wenn der den ARN der Zugriffsrichtlinie AWS CLI auflistet, kopieren Sie ihn und speichern Sie ihn in einem Texteditor.
-
Fügen Sie die neue Richtlinie der IAM-Rolle hinzu, indem Sie den folgenden Befehl ausführen.
policy-arnaws iam attach-role-policy --policy-arnpolicy-arn--role-name glue-access-role -
Fügen Sie die AWS verwaltete Richtlinie Ihrer IAM-Rolle
AWSGlueServiceRolehinzu, indem Sie den folgenden Befehl ausführen.aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole --role-name glue-access-role
-
-
Erstellen Sie eine AWS Glue Datenbank, indem Sie den folgenden Befehl ausführen.
aws glue create-database --database-input Name="comprehend-results" -
Erstellen Sie einen neuen AWS Glue Crawler, indem Sie den folgenden Befehl ausführen.
glue-iam-role-arnaws glue create-crawler --name comprehend-analysis-crawler --roleglue-iam-role-arn--targets S3Targets=[ {Path="s3://amzn-s3-demo-bucket/sentiment-results"}, {Path="s3://amzn-s3-demo-bucket/entities-results"}] --database-name comprehend-results -
Starten Sie den Crawler, indem Sie den folgenden Befehl ausführen.
aws glue start-crawler --name comprehend-analysis-crawlerEs kann einige Minuten dauern, bis der Crawler fertig ist.
Bereiten Sie die Daten für die Analyse vor
Jetzt haben Sie eine Datenbank, die mit den Amazon Comprehend Comprehend-Ergebnissen gefüllt ist. Die Ergebnisse sind jedoch verschachtelt. Um sie zu entflechten, führen Sie einige SQL-Anweisungen aus. Amazon Athena Amazon Athena ist ein interaktiver Abfrageservice, der es einfach macht, Daten in Amazon S3 mithilfe von Standard-SQL zu analysieren. Athena ist serverlos, sodass keine Infrastruktur verwaltet werden muss, und es gibt ein pay-per-query Preismodell. In diesem Schritt erstellen Sie neue Tabellen mit bereinigten Daten, die Sie zur Analyse und Visualisierung verwenden können. Sie verwenden die Athena-Konsole, um die Daten vorzubereiten.
Um die Daten vorzubereiten
Öffnen Sie die Athena-Konsole unter https://console.aws.amazon.com/athena/
. -
Wählen Sie im Abfrage-Editor Einstellungen und anschließend Verwalten aus.
-
Geben Sie für Speicherort der Abfrageergebnisse den Wert ein
s3://amzn-s3-demo-bucket/query-results/. Dadurch wird ein neuer Ordner mit dem Namenquery-resultsin Ihrem Bucket erstellt, in dem die Ausgabe der von Ihnen Amazon Athena ausgeführten Abfragen gespeichert wird. Wählen Sie Save (Speichern) aus. -
Wählen Sie im Abfrage-Editor Editor aus.
-
Wählen Sie für Datenbank die AWS Glue Datenbank aus
comprehend-results, die Sie erstellt haben. -
Im Abschnitt Tabellen sollten Sie zwei Tabellen mit dem Namen
sentiment_resultsund habenentities_results. Zeigen Sie eine Vorschau der Tabellen an, um sicherzustellen, dass der Crawler die Daten geladen hat. Wählen Sie in den Optionen jeder Tabelle (die drei Punkte neben dem Tabellennamen) die Option Tabellenvorschau aus. Eine kurze Abfrage wird automatisch ausgeführt. Überprüfen Sie im Ergebnisbereich, ob die Tabellen Daten enthalten.Tipp
Wenn die Tabellen keine Daten enthalten, versuchen Sie, die Ordner in Ihrem S3-Bucket zu überprüfen. Stellen Sie sicher, dass es einen Ordner für Entitätsergebnisse und einen Ordner für Stimmungsergebnisse gibt. Versuchen Sie dann, einen neuen AWS Glue Crawler auszuführen.
-
Um die
sentiment_resultsTabelle zu entwirren, geben Sie die folgende Abfrage in den Abfrage-Editor ein und wählen Sie Ausführen aus.CREATE TABLE sentiment_results_final AS SELECT file, line, sentiment, sentimentscore.mixed AS mixed, sentimentscore.negative AS negative, sentimentscore.neutral AS neutral, sentimentscore.positive AS positive FROM sentiment_results -
Um die Verschachtelung der Entitätstabelle zu entfernen, geben Sie die folgende Abfrage in den Abfrage-Editor ein und wählen Sie Ausführen aus.
CREATE TABLE entities_results_1 AS SELECT file, line, nested FROM entities_results CROSS JOIN UNNEST(entities) as t(nested) -
Um die Verschachtelung der Entitätstabelle zu beenden, geben Sie die folgende Abfrage in den Abfrage-Editor ein und wählen Sie Abfrage ausführen aus.
CREATE TABLE entities_results_final AS SELECT file, line, nested.beginoffset AS beginoffset, nested.endoffset AS endoffset, nested.score AS score, nested.text AS entity, nested.type AS category FROM entities_results_1
Ihre sentiment_results_final Tabelle sollte wie folgt aussehen, mit den Spalten Datei, Zeile, Stimmung, gemischt, negativ, neutral und positiv. Die Tabelle sollte einen Wert pro Zelle haben. Die Stimmungsspalte beschreibt die wahrscheinlichste allgemeine Stimmung einer bestimmten Bewertung. Die gemischten, negativen, neutralen und positiven Spalten geben Werte für jeden Stimmungstyp an.
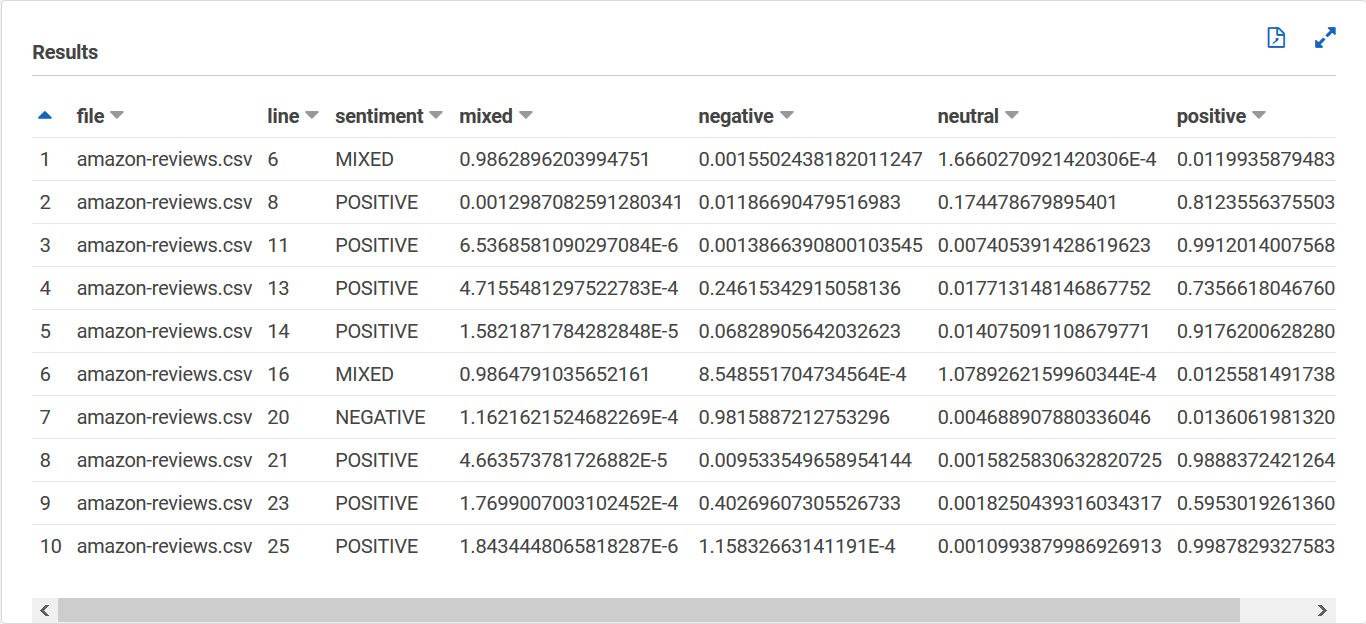
Ihre entities_results_final Tabelle sollte wie folgt aussehen, mit Spalten mit den Namen file, line, beginoffset, endoffset, score, entity und category. Die Tabelle sollte einen Wert pro Zelle haben. Die Bewertungsspalte gibt das Vertrauen von Amazon Comprehend in die erkannte Entität an. Die Kategorie gibt an, welche Art von Entität Comprehend erkannt wurde.
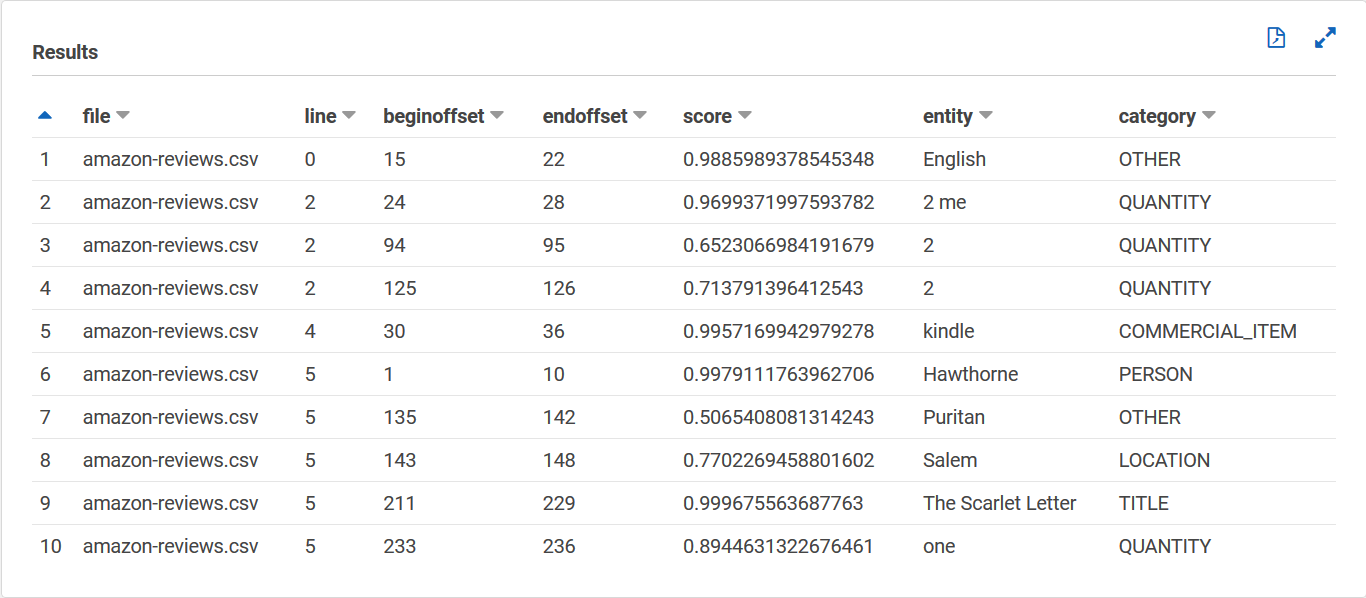
Nachdem Sie die Amazon Comprehend Comprehend-Ergebnisse in Tabellen geladen haben, können Sie die Daten visualisieren und aussagekräftige Erkenntnisse daraus gewinnen.
