Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Als Replikatsatz eine Verbindung zu Amazon DocumentDB herstellen
Wenn Sie mit Amazon DocumentDB (mit MongoDB-Kompatibilität) entwickeln, empfehlen wir, dass Sie eine Verbindung zu Ihrem Cluster als Replikatsatz herstellen und Lesevorgänge mithilfe der integrierten Leseeinstellungen Ihres Treibers an Replikatinstanzen verteilen. In diesem Abschnitt wird genauer beschrieben, was das bedeutet, und es wird beschrieben, wie Sie am Beispiel des SDK für Python eine Verbindung zu Ihrem Amazon DocumentDB-Cluster als Replikatsatz herstellen können.
Amazon DocumentDB hat drei Endpunkte, über die Sie eine Verbindung zu Ihrem Cluster herstellen können:
-
Cluster-Endpunkt
-
Leser-Endpunkt
-
Instance-Endpunkte
In den meisten Fällen, wenn Sie eine Verbindung zu Amazon DocumentDB herstellen, empfehlen wir, den Cluster-Endpunkt zu verwenden. Dies ist ein CNAME, der auf die primäre Instance in Ihrem Cluster verweist wie im folgenden Diagramm gezeigt.
Wenn Sie einen SSH-Tunnel verwenden, empfehlen wir, dass Sie über den Clusterendpunkt eine Verbindung mit Ihrem Cluster herstellen und nicht versuchen, eine Verbindung im Replikatsatzmodus herzustellen (d. h. replicaSet=rs0 in der Verbindungszeichenfolge anzugeben), da dies zu einem Fehler führt.
Anmerkung
Weitere Informationen zu Amazon DocumentDB DocumentDB-Endpunkten finden Sie unter. Amazon DocumentDB DocumentDB-Endpunkte
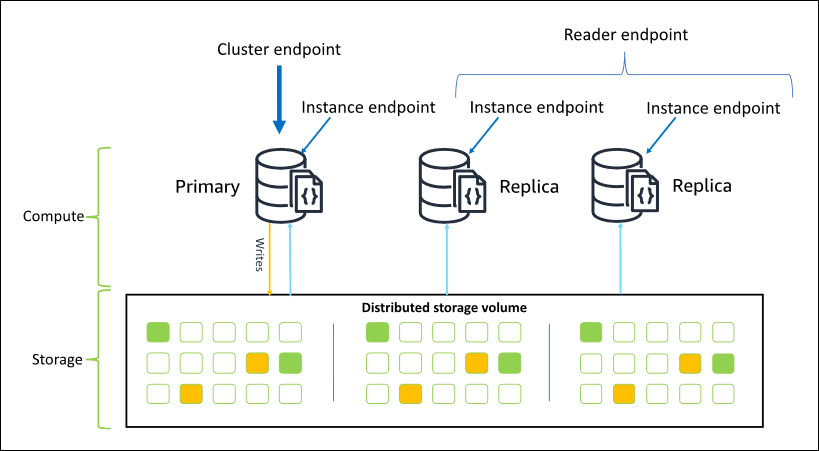
Mithilfe des Cluster-Endpunkts können Sie im Replikatsatzmodus eine Verbindung zu Ihrem Cluster herstellen. Anschließend können Sie die integrierten Treiberfunktionen für Leseeinstellungen verwenden. Im folgenden Beispiel signalisiert die Angabe von /?replicaSet=rs0 dem SDK, das Sie eine Verbindung als Replikatsatz herstellen möchten. Wenn Sie /?replicaSet=rs0' auslassen, leitet der Client alle Anfragen an den Cluster-Endpunkt weiter, d. h. Ihre primäre Instance.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0')
Der Vorteil der Verbindung als Replikatsatz besteht darin, dass Ihr SDK die Cluster-Topographie automatisch erkennt, auch wenn Instances dem Cluster hinzugefügt oder aus dem Cluster entfernt werden. Anschließend können Sie den Cluster effizienter nutzen, indem Sie Leseanforderungen an Ihre Replikat-Instances weiterleiten.
Wenn Sie eine Verbindung als Replikatsatz herstellen, können Sie die readPreference für die Verbindung angeben. Wenn Sie die Leseeinstellung secondaryPreferred angeben, leitet der Client Leseabfragen an Ihre Replikate und Schreibabfragen an Ihre primäre Instance weiter (wie im folgenden Diagramm gezeigt). Damit werden Ihre Cluster-Ressourcen besser genutzt. Weitere Informationen finden Sie unter Lesen Sie die Einstellungsoptionen.
## Create a MongoDB client, open a connection to Amazon DocumentDB as a ## replica set and specify the read preference as secondary preferred client = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')

Lesevorgänge von Amazon DocumentDB DocumentDB-Replikaten sind letztendlich konsistent. Sie geben die Daten in der gleichen Reihenfolge zurück, in der sie auf dem primären Knoten geschrieben wurden. Die Replikationsverzögerung beträgt häufig weniger als 50 ms. Sie können die Replikatverzögerung für Ihren Cluster mithilfe der CloudWatch Amazon-Metriken DBInstanceReplicaLag und DBClusterReplicaLagMaximum überwachen. Weitere Informationen finden Sie unter Überwachen von Amazon DocumentDB mit CloudWatch.
Im Gegensatz zur herkömmlichen monolithischen Datenbankarchitektur trennt Amazon DocumentDB Speicher und Datenverarbeitung. Aufgrund dieser modernen Architektur sollten Sie Lesevorgänge auf Replikat-Instances skalieren. Lesevorgänge auf Replikat-Instances blockieren keine Schreibvorgänge, die von der primären Instance repliziert werden. Sie können einem Cluster bis zu 15 Read-Reaplica-Instances hinzufügen und auf Millionen von Lesevorgängen pro Sekunde skalieren.
Der Hauptvorteil der Verbindung als Replikatsatz und der Verteilung von Lesevorgängen an Replikate besteht darin, dass dies die Gesamtzahl der Ressourcen im Cluster erhöht, die für Ihre Anwendung verfügbar sind. Wir empfehlen die Verbindung als Replikatsatz als bewährte Methode. Darüber hinaus empfehlen wir diesen Ansatz besonders für die folgenden Szenarien:
-
Sie nutzen nahezu 100 Prozent der CPU-Leistung auf Ihrer primären Instance.
-
Das Puffer-Cache-Treffer-Verhältnis ist beinahe Null.
-
Sie erreichen die Verbindungs- oder Cursor-Limits für eine einzelne Instance.
Die Aufwärtsskalierung einer Cluster-Instance-Größe ist eine Option und kann in einigen Fällen die beste Möglichkeit für die Skalierung des Clusters darstellen. Sie sollten jedoch auch überlegen, wie Sie die Replikate, die in Ihrem Cluster bereits vorhanden sind, besser nutzen können. So können Sie die Skalierung erhöhen, ohne dass für Sie höhere Kosten für die Verwendung eines größeren Instance-Typs anfallen. Wir empfehlen außerdem, diese Grenzwerte (d. h., undBufferCacheHitRatio) mithilfe von CloudWatch Alarmen zu überwachen und Warnmeldungen zu erstellen CPUUtilizationDatabaseConnections, damit Sie wissen, wenn eine Ressource stark beansprucht wird.
Weitere Informationen finden Sie unter den folgenden Themen:
Verwenden von Clusterverbindungen
Betrachten Sie ein Szenario, in dem alle Verbindungen in Ihrem Cluster genutzt werden. Beispielsweise hat eine r5.2xlarge-Instance ein Limit von 4.500 Verbindungen (und 450 offenen Cursors). Wenn Sie einen Amazon DocumentDB-Cluster mit drei Instanzen erstellen und nur über den Cluster-Endpunkt eine Verbindung zur primären Instance herstellen, liegen Ihre Cluster-Grenzwerte für offene Verbindungen und Cursor bei 4.500 bzw. 450. Sie können diese Limits erreichen, wenn Sie Anwendungen mit zahlreichen Workern verwenden, die in Containern gestartet werden. Die Container öffnen mehrere Verbindungen gleichzeitig und sättigen den Cluster.
Stattdessen könnten Sie sich als Replikatsatz mit dem Amazon DocumentDB-Cluster verbinden und Ihre Lesevorgänge an die Replikatinstanzen verteilen. Anschließend könnten Sie die Anzahl der verfügbaren Verbindungen und Cursors im Cluster effektiv auf 13.500 bzw. 1.350 verdreifachen. Das Hinzufügen weiterer Instances zum Cluster erhöht lediglich die Anzahl der Verbindungen und Cursors für Lese-Workloads. Wenn Sie die Anzahl der Verbindungen für Schreibvorgänge in Ihrem Cluster erhöhen müssen, sollten Sie die Instance-Größe erhöhen.
Anmerkung
Die Anzahl der Verbindungen für large, xlarge, und 2xlarge Instances erhöht sich mit der Instance-Größe bis zu 4.500. Die maximale Anzahl von Verbindungen pro Instance für 4xlarge Instances oder größer beträgt 4.500. Weitere Hinweise zu Beschränkungen nach Instance-Typ finden Sie unter Instance-Limits.
In der Regel empfehlen wir das Herstellen von Verbindungen mit Ihrem Cluster unter Verwendung der Leseeinstellung secondary nicht. Der Grund hierfür ist, dass die Lesevorgänge fehlschlagen, wenn es keine Replikat-Instances im Cluster gibt. Nehmen wir zum Beispiel an, Sie haben einen Amazon DocumentDB-Cluster mit zwei Instanzen, einem primären und einem Replikat. Wenn die Replikat-Instance ein Problem aufweist, schlagen Leseanforderungen aus einem als secondary festgelegten Verbindungspool fehl. Der Vorteil von secondaryPreferred besteht darin, dass der Client für Lesevorgänge auf den primären Knoten zurückgreift, wenn er keine geeignete Replikat-Instance für die Verbindung finden kann.
Mehrere Verbindungspools
In einigen Szenarien müssen Lesevorgänge in einer Anwendung read-after-write konsistent sein, sodass sie nur von der primären Instance in Amazon DocumentDB bedient werden können. In diesen Szenarien könnten Sie zwei Client-Verbindungspools erstellen: einen für Schreibvorgänge und einen für Lesevorgänge, die read-after-write Konsistenz erfordern. Ihr Code würde in diesem Fall ungefähr wie folgt aussehen.
## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as primary clientPrimary = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=primary') ## Create a MongoDB client, ## open a connection to Amazon DocumentDB as a replica set and specify the readPreference as secondaryPreferred secondaryPreferred = pymongo.MongoClient('mongodb://<user-name>:<password>@mycluster.node.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0&readPreference=secondaryPreferred')
Eine weitere Möglichkeit besteht darin, einen einzelnen Verbindungspool zu erstellen und die Leseeinstellung für eine bestimmte Sammlung zu überschreiben.
##Specify the collection and set the read preference level for that collection col = db.review.with_options(read_preference=ReadPreference.SECONDARY_PREFERRED)
Übersicht
Um die Ressourcen im Cluster besser zu nutzen, sollten Sie Verbindungen mit dem Cluster über den Replikatsatzmodus herstellen. Sie können die Zahl der Lesevorgänge für Ihre Anwendung skalieren, indem Sie Ihre Lesevorgänge an die Replikat-Instances verteilen, wenn dies für Ihre Anwendung geeignet ist.
