Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
EKS-Steuerebene
Amazon Elastic Kubernetes Service (EKS) ist ein verwalteter Kubernetes-Service, mit dem Sie Kubernetes auf AWS ganz einfach ausführen können, ohne Ihre eigene Kubernetes-Steuerebene oder Ihre eigenen Worker-Knoten installieren, betreiben und warten zu müssen. Er läuft auf Upstream-Kubernetes und ist als Kubernetes-konform zertifiziert. Diese Konformität stellt sicher, dass EKS Kubernetes unterstützt, genau wie die Open-Source-Community-VersionAPIs, die Sie vor Ort oder vor Ort installieren können. EC2 Bestehende Anwendungen, die auf Upstream-Kubernetes ausgeführt werden, sind mit Amazon EKS kompatibel.
EKS verwaltet automatisch die Verfügbarkeit und Skalierbarkeit der Kubernetes-Steuerebenenknoten und ersetzt automatisch fehlerhafte Knoten der Kontrollebene.
EKS-Architektur
Die EKS-Architektur wurde entwickelt, um einzelne Fehlerquellen zu eliminieren, die die Verfügbarkeit und Beständigkeit der Kubernetes-Steuerebene beeinträchtigen könnten.
Die von EKS verwaltete Kubernetes-Steuerebene wird in einer von EKS verwalteten VPC ausgeführt. Die EKS-Steuerebene umfasst die Kubernetes-API-Serverknoten usw. Kubernetes-API-Serverknoten, die Komponenten wie den API-Server und den Scheduler kube-controller-manager ausführen und in einer Gruppe mit auto-scaling ausgeführt werden. EKS betreibt mindestens zwei API-Serverknoten in unterschiedlichen Availability Zones (AZs) innerhalb der AWS-Region. Aus Gründen der Haltbarkeit laufen die etcd-Serverknoten ebenfalls in einer Auto-Scaling-Gruppe, die sich über drei erstreckt. AZs EKS betreibt in jeder AZ ein NAT-Gateway, und API-Server und etcd-Server laufen in einem privaten Subnetz. Diese Architektur stellt sicher, dass ein Ereignis in einer einzelnen AZ die Verfügbarkeit des EKS-Clusters nicht beeinträchtigt.
Wenn Sie einen neuen Cluster erstellen, erstellt Amazon EKS einen hochverfügbaren Endpunkt für den verwalteten Kubernetes-API-Server, den Sie für die Kommunikation mit Ihrem Cluster verwenden (mithilfe von Tools wie). kubectl Der verwaltete Endpunkt verwendet NLB für den Lastenausgleich der Kubernetes-API-Server. EKS stellt außerdem zwei unterschiedliche ENIs bereit, AZs um die Kommunikation mit Ihren Worker-Knoten zu erleichtern.
EKS-Netzwerkkonnektivität auf der Datenebene
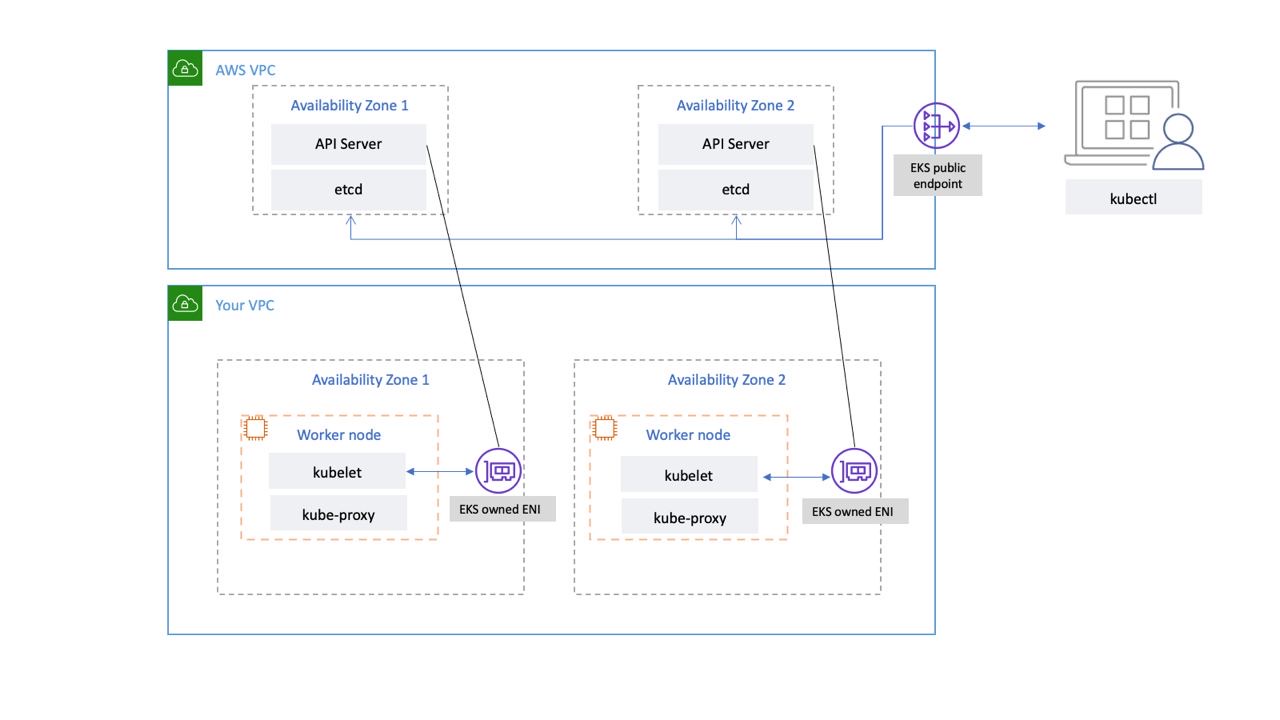
Sie können konfigurieren, ob der API-Server Ihres Kubernetes-Clusters vom öffentlichen Internet (über den öffentlichen Endpunkt) oder über Ihre VPC (mit dem ENIs EKS-verwalteten) oder von beiden aus erreichbar ist.
Unabhängig davon, ob Benutzer und Worker-Knoten über den öffentlichen Endpunkt oder das von EKS verwaltete ENI eine Verbindung zum API-Server herstellen, gibt es redundante Verbindungspfade.
Empfehlungen
Lesen Sie sich die folgenden Empfehlungen durch.
Überwachen Sie die Kennzahlen der Kontrollebene
Durch die Überwachung der Kubernetes-API-Metriken erhalten Sie Einblicke in die Leistung der Kontrollebene und können Probleme identifizieren. Eine fehlerhafte Kontrollebene kann die Verfügbarkeit der Workloads beeinträchtigen, die innerhalb des Clusters ausgeführt werden. Beispielsweise können schlecht geschriebene Controller die API-Server überlasten und die Verfügbarkeit Ihrer Anwendung beeinträchtigen.
Kubernetes stellt Metriken der Kontrollebene am Endpunkt zur Verfügung. /metrics
Sie können die bereitgestellten Metriken wie folgt anzeigen: kubectl
kubectl get --raw /metrics
Diese Metriken werden in einem Prometheus-Textformat
Sie können Prometheus verwenden, um diese Metriken zu sammeln und zu speichern. Im Mai 2020 CloudWatch wurde Unterstützung für die Überwachung von Prometheus-Metriken in CloudWatch Container Insights hinzugefügt. Sie können Amazon also auch CloudWatch zur Überwachung der EKS-Steuerebene verwenden. Sie können Tutorial for Adding a New Prometheus Scrape Target: Prometheus KPI Server Metrics verwenden, um Metriken zu sammeln und ein CloudWatch Dashboard zur Überwachung der Kontrollebene Ihres Clusters zu erstellen.
Kennzahlen zum Kubernetes-API-Server finden Sie hier.apiserver_request_duration_secondsKann beispielsweise angeben, wie lange die Ausführung von API-Anfragen dauert.
Erwägen Sie die Überwachung dieser Metriken auf der Kontrollebene:
API-Server
| Metrik | Beschreibung |
|---|---|
|
|
Zähler der Apiserver-Anfragen, aufgeschlüsselt nach Verb, Probelaufwert, Gruppe, Version, Ressource, Bereich, Komponente und HTTP-Antwortcode. |
|
|
Histogramm der Antwortlatenz in Sekunden für jedes Verb, jeden Probelaufwert, jede Gruppe, Version, Ressource, Unterressource, jeden Bereich und jede Komponente. |
|
|
Latenzhistogramm für den Zugangscontroller in Sekunden, identifiziert anhand des Namens und aufgeschlüsselt für jeden Vorgang, jede API-Ressource und jeden Typ (validieren oder zulassen). |
|
|
Anzahl der Webhook-Ablehnungen für die Zulassung. Identifiziert nach Name, Vorgang, Ablehnungscode, Typ (validieren oder zulassen), error_type (calling_webhook_error, apiserver_internal_error, no_error) |
|
|
Latenz-Histogramm in Sekunden anfordern. Aufgeschlüsselt nach Verb und URL. |
|
|
Anzahl der HTTP-Anfragen, partitioniert nach Statuscode, Methode und Host. |
-
Zu den Histogramm-Metriken gehören die Suffixe _bucket, _sum und _count.
usw
| Metrik | Beschreibung |
|---|---|
|
|
Etcd-Anforderungslatenzhistogramm in Sekunden für jeden Vorgang und Objekttyp. |
|
|
Größe der Etcd-Datenbank. |
-
Zu den Histogramm-Metriken gehören die Suffixe _bucket, _sum und _count.
Erwägen Sie, das Kubernetes Monitoring Overview Dashboard zu verwenden, um Kubernetes-API-Serveranfragen
Wichtig
Wenn die Größenbeschränkung für die Datenbank überschritten wird, gibt etcd einen Alarm ohne Speicherplatz aus und nimmt keine weiteren Schreibanforderungen mehr entgegen. Mit anderen Worten, der Cluster wird schreibgeschützt, und alle Anfragen zur Änderung von Objekten wie das Erstellen neuer Pods, das Skalieren von Bereitstellungen usw. werden vom API-Server des Clusters abgewiesen.
Cluster-Authentifizierung
EKS unterstützt derzeit zwei Arten der Authentifizierung: Inhaber-/Dienstkonto-Tokens
Der IAM-Benutzer oder die IAM-Rolle, die den EKS-Cluster erstellt, erhält automatisch vollen Zugriff auf den Cluster. Sie können den Zugriff auf den EKS-Cluster verwalten, indem Sie die aws-auth-Configmap bearbeiten.
Wenn Sie die aws-auth Configmap falsch konfigurieren und den Zugriff auf den Cluster verlieren, können Sie trotzdem den Benutzer oder die Rolle des Clustererstellers verwenden, um auf Ihren EKS-Cluster zuzugreifen.
In dem unwahrscheinlichen Fall, dass Sie den IAM-Service in der AWS-Region nicht nutzen können, können Sie den Cluster auch mit dem Bearer-Token des Kubernetes-Servicekontos verwalten.
Erstellen Sie ein super-admin Konto, das alle Aktionen im Cluster ausführen darf:
kubectl -n kube-system create serviceaccount super-admin
Erstellen Sie eine Rollenbindung, die der Super-Admin-Cluster-Admin-Rolle zuweist:
kubectl create clusterrolebinding super-admin-rb --clusterrole=cluster-admin --serviceaccount=kube-system:super-admin
Holen Sie sich das Geheimnis des Dienstkontos:
SECRET_NAME=`kubectl -n kube-system get serviceaccount/super-admin -o jsonpath='{.secrets[0].name}'`
Ruft das mit dem Secret verknüpfte Token ab:
TOKEN=`kubectl -n kube-system get secret $SECRET_NAME -o jsonpath='{.data.token}'| base64 --decode`
Dienstkonto und Token hinzufügen zukubeconfig:
kubectl config set-credentials super-admin --token=$TOKEN
Stellen Sie den aktuellen Kontext ein, um das kubeconfig Super-Admin-Konto zu verwenden:
kubectl config set-context --current --user=super-admin
Final kubeconfig sollte so aussehen:
apiVersion: v1 clusters: - cluster: certificate-authority-data:<REDACTED> server: https://<CLUSTER>.gr7.us-west-2.eks.amazonaws.com name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> contexts: - context: cluster: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> user: super-admin name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> current-context: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> kind: Config preferences: {} users: #- name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> # user: # exec: # apiVersion: client.authentication.k8s.io/v1beta1 # args: # - --region # - us-west-2 # - eks # - get-token # - --cluster-name # - <<cluster name>> # command: aws # env: null - name: super-admin user: token: <<super-admin sa's secret>>
Zulassung: Webhooks
Kubernetes hat zwei Arten von Zulassungs-Webhooks: Validierungs-Webhooks und mutierende Zulassungs-Webhooks
Um eine Beeinträchtigung kritischer Clusteroperationen zu vermeiden, sollten Sie entweder das Setzen von „Catch-All“ -Webhooks wie den folgenden vermeiden:
- name: "pod-policy.example.com" rules: - apiGroups: ["*"] apiVersions: ["*"] operations: ["*"] resources: ["*"] scope: "*"
Oder stellen Sie sicher, dass der Webhook über eine Fail-Open-Richtlinie mit einem Timeout von weniger als 30 Sekunden verfügt, um sicherzustellen, dass kritische Cluster-Workloads nicht beeinträchtigt werden, wenn Ihr Webhook nicht verfügbar ist.
Blockieren Sie Pods mit unsicheren sysctls
Sysctlist ein Linux-Hilfsprogramm, mit dem Benutzer Kernelparameter während der Laufzeit ändern können. Diese Kernelparameter steuern verschiedene Aspekte des Verhaltens des Betriebssystems, z. B. das Netzwerk, das Dateisystem, den virtuellen Speicher und die Prozessverwaltung.
Kubernetes ermöglicht das Zuweisen von sysctl Profilen für Pods. Kubernetes wird als sicher und unsicher eingestuftsystcls. Sicher sysctls haben im Container oder Pod Namespaces, und ihre Einstellung hat keine Auswirkungen auf andere Pods auf dem Knoten oder den Knoten selbst. Im Gegensatz dazu sind unsichere Sysctls standardmäßig deaktiviert, da sie möglicherweise andere Pods stören oder den Knoten instabil machen können.
Da unsicher standardmäßig deaktiviert sysctls sind, erstellt das Kubelet keinen Pod mit einem unsicheren Profil. sysctl Wenn Sie einen solchen Pod erstellen, weist der Scheduler solche Pods wiederholt Knoten zu, während der Knoten ihn nicht starten kann. Diese Endlosschleife belastet letztlich die Cluster-Steuerebene und macht den Cluster instabil.
Erwägen Sie, OPA Gatekeepersysctls
Umgang mit Cluster-Upgrades
Seit April 2021 wurde der Kubernetes-Veröffentlichungszyklus von vier Releases pro Jahr (einmal pro Quartal) auf drei Releases pro Jahr geändert. Eine neue Nebenversion (wie 1. 21 oder 1. 22) wird ungefähr alle fünfzehn Wochen
Konnektivität von Cluster-Endpunkten
Bei der Arbeit mit Amazon EKS (Elastic Kubernetes Service) können Verbindungstimeouts oder Fehler bei Ereignissen wie der Skalierung oder dem Patchen der Kubernetes-Steuerebene auftreten. Diese Ereignisse können dazu führen, dass die Kube-Apiserver-Instanzen ersetzt werden, was möglicherweise dazu führt, dass bei der Auflösung des FQDN unterschiedliche IP-Adressen zurückgegeben werden. In diesem Dokument werden bewährte Methoden für Kubernetes-API-Nutzer zur Aufrechterhaltung einer zuverlässigen Konnektivität beschrieben.
Anmerkung
Die Implementierung dieser bewährten Methoden erfordert möglicherweise Aktualisierungen der Client-Konfigurationen oder der Skripte, um neue Strategien zur erneuten DNS-Auflösung und zum erneuten Versuch effektiv handhaben zu können.
Das Hauptproblem ist das clientseitige DNS-Caching und das Potenzial für veraltete IP-Adressen von EKS-Endpunkten — öffentliche NLB für öffentliche Endgeräte oder X-ENI für private Endgeräte. Wenn die Kube-Apiserver-Instanzen ersetzt werden, wird der vollqualifizierte Domainname (FQDN) möglicherweise zu neuen IP-Adressen aufgelöst. Aufgrund der DNS Time to Live (TTL) -Einstellungen, die in der von AWS verwalteten Route 53 53-Zone auf 60 Sekunden festgelegt sind, können Clients jedoch für einen kurzen Zeitraum weiterhin veraltete IP-Adressen verwenden.
Um diese Probleme zu beheben, sollten Kubernetes-API-Nutzer (wie Kubectl, CI/CD Pipelines und benutzerdefinierte Anwendungen) die folgenden bewährten Methoden implementieren:
-
Implementieren Sie die DNS-Neuauflösung
-
Implementieren Sie Wiederholungen mit Backoff und Jitter. Sehen Sie sich zum Beispiel diesen
Artikel mit dem Titel Fehler passieren an -
Implementieren Sie Client-Timeouts. Legen Sie geeignete Timeouts fest, um zu verhindern, dass Anfragen mit langer Laufzeit Ihre Anwendung blockieren. Beachten Sie, dass einige Kubernetes-Clientbibliotheken, insbesondere solche, die von OpenAPI-Generatoren generiert werden, das Einstellen benutzerdefinierter Timeouts möglicherweise nicht einfach zulassen.
-
Beispiel 1 mit kubectl:
kubectl get pods --request-timeout 10s # default: no timeout
-
Beispiel 2 mit Python: Der Kubernetes-Client stellt einen
_request_timeout-Parameter bereit
-
Durch die Implementierung dieser Best Practices können Sie die Zuverlässigkeit und Belastbarkeit Ihrer Anwendungen bei der Interaktion mit der Kubernetes-API erheblich verbessern. Denken Sie daran, diese Implementierungen gründlich zu testen, insbesondere unter simulierten Ausfallbedingungen, um sicherzustellen, dass sie sich bei tatsächlichen Skalierungs- oder Patching-Ereignissen erwartungsgemäß verhalten.
Große Cluster ausführen
EKS überwacht aktiv die Auslastung der Instanzen auf der Kontrollebene und skaliert sie automatisch, um eine hohe Leistung zu gewährleisten. Sie sollten jedoch potenzielle Leistungsprobleme und -beschränkungen innerhalb von Kubernetes und Kontingente in AWS-Services berücksichtigen, wenn Sie große Cluster ausführen.
-
Bei Clustern mit mehr als 1000 Services kann es laut den vom Team durchgeführten Tests
zu Netzwerklatenz kommen, wenn sie kube-proxyimiptablesModus verwendet werden. ProjectCalico Die Lösung besteht darin, in den ipvsModus Running kube-proxy In zu wechseln. -
Möglicherweise kommt es auch zu einer Drosselung von EC2 API-Anfragen, wenn das CNI IP-Adressen für Pods anfordern muss oder wenn Sie häufig neue EC2 Instanzen erstellen müssen. Sie können die Anzahl der EC2 API-Aufrufe reduzieren, indem Sie das CNI so konfigurieren, dass IP-Adressen zwischengespeichert werden. Sie können größere EC2 Instance-Typen verwenden, um EC2 Skalierungsereignisse zu reduzieren.
Zusätzliche Ressourcen:
