Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Kostenoptimierung — Netzwerke
Die Architektur von Systemen für hohe Verfügbarkeit (HA) ist eine bewährte Methode, um Ausfallsicherheit und Fehlertoleranz zu erreichen. In der Praxis bedeutet dies, dass Sie Ihre Workloads und die zugrunde liegende Infrastruktur auf mehrere Availability Zones (AZs) in einer bestimmten AWS-Region verteilen. Wenn Sie sicherstellen, dass diese Eigenschaften für Ihre Amazon EKS-Umgebung vorhanden sind, wird die allgemeine Zuverlässigkeit Ihres Systems verbessert. In Verbindung damit werden Ihre EKS-Umgebungen wahrscheinlich auch aus einer Vielzahl von Konstrukten (d. h. VPCs), Komponenten (d. h.) und Integrationen (d. h. ECR und anderen Container-Registern ELBs) bestehen.
Die Kombination aus hochverfügbaren Systemen und anderen anwendungsspezifischen Komponenten kann eine wichtige Rolle bei der Übertragung und Verarbeitung von Daten spielen. Dies wird sich wiederum auf die Kosten auswirken, die durch die Datenübertragung und -verarbeitung entstehen.
Die unten aufgeführten Methoden helfen Ihnen beim Entwerfen und Optimieren Ihrer EKS-Umgebungen, um Kosteneffektivität für verschiedene Bereiche und Anwendungsfälle zu erreichen.
Kommunikation von Pod zu Pod
Abhängig von Ihrer Konfiguration können Netzwerkkommunikation und Datenübertragung zwischen Pods erhebliche Auswirkungen auf die Gesamtkosten der Ausführung von Amazon EKS-Workloads haben. In diesem Abschnitt werden verschiedene Konzepte und Ansätze zur Reduzierung der mit der Kommunikation zwischen Pods verbundenen Kosten behandelt, wobei hochverfügbare Architekturen (HA), Anwendungsleistung und Ausfallsicherheit berücksichtigt werden.
Beschränkung des Datenverkehrs auf eine Availability Zone
Das Kubernetes-Projekt begann schon früh mit der Entwicklung topologieorientierter Konstrukte, einschließlich Bezeichnungen wie Kubernetes. io/hostname, topology.kubernetes.io/region, and topology.kubernetes.io/zoneKnoten zugewiesen, um Funktionen wie die Verteilung der Arbeitslast auf Ausfalldomänen und topologieorientierte Volume Provisioner zu ermöglichen. Nach Abschluss des Studiums in Kubernetes 1.17 wurden die Labels auch genutzt, um topologieorientierte Routing-Funktionen für die Pod-zu-Pod-Kommunikation zu ermöglichen.
Im Folgenden finden Sie einige Strategien zur Steuerung des AZ-übergreifenden Datenverkehrs zwischen Pods in Ihrem EKS-Cluster, um die Kosten zu senken und die Latenz zu minimieren.
Wenn Sie einen detaillierten Überblick über die Menge des AZ-übergreifenden Datenverkehrs zwischen Pods in Ihrem Cluster wünschen (z. B. die Menge der übertragenen Daten in Byte), lesen Sie
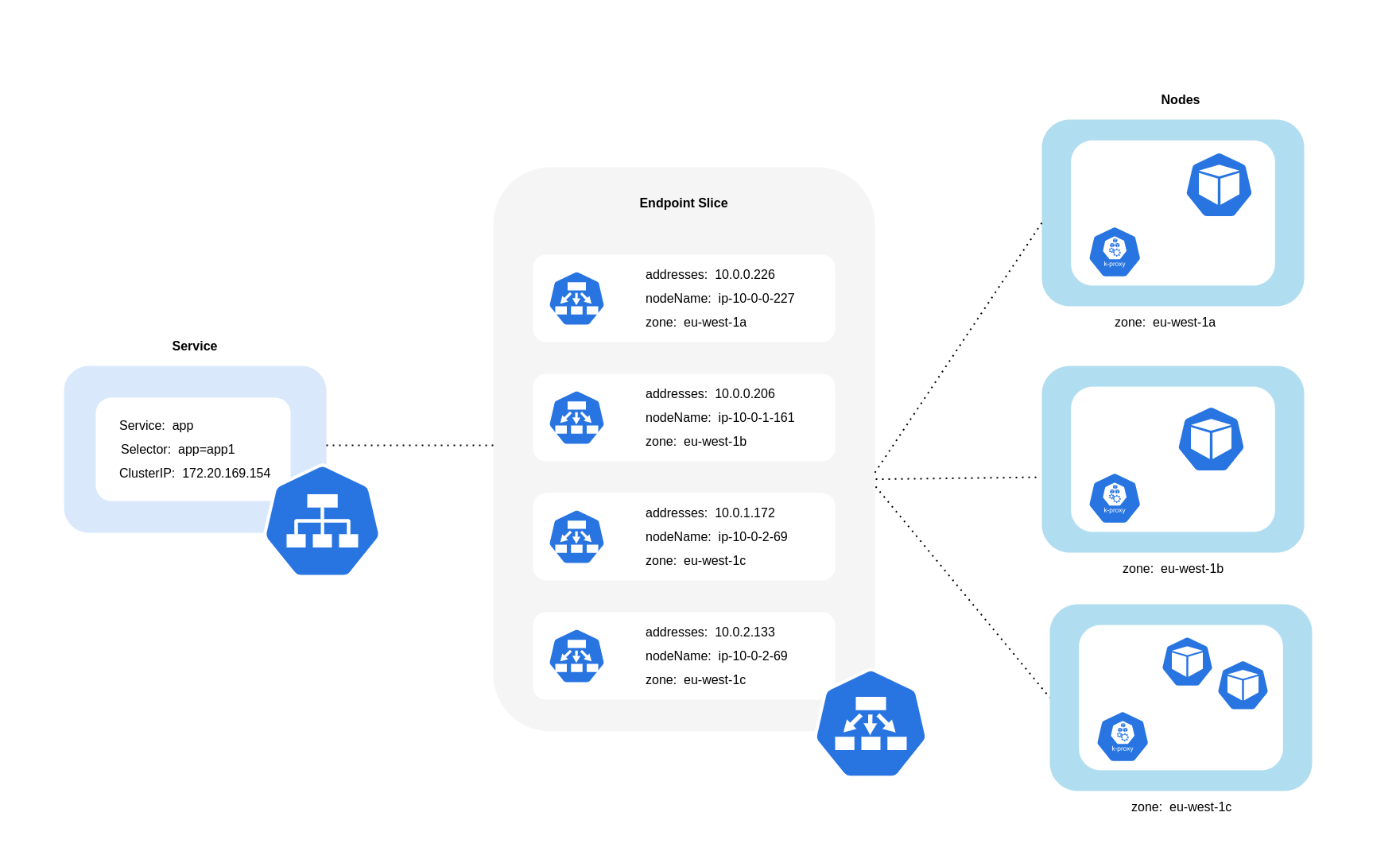
Wie das obige Diagramm zeigt, sind Dienste die stabile Netzwerkabstraktionsschicht, die den für Ihre Pods bestimmten Datenverkehr empfängt. Wenn ein Dienst erstellt wird, werden mehrere EndpointSlices erstellt. Jeder EndpointSlice hat eine Liste von Endpunkten, die eine Teilmenge von Pod-Adressen zusammen mit den Knoten, auf denen sie ausgeführt werden, und allen zusätzlichen Topologieinformationen enthält. Bei Verwendung des Amazon VPC CNI verwaltet kube-proxy, ein Daemonset, das auf jedem Knoten läuft, Netzwerkregeln, um die Pod-Kommunikation und die Serviceerkennung zu ermöglichen (alternative EBPF-basierte Lösungen verwenden CNIs möglicherweise keinen Kube-Proxy, bieten aber ein gleichwertiges Verhalten). Es erfüllt die Rolle des internen Routings, tut dies jedoch auf der Grundlage dessen, was es von den erstellten Daten verbraucht. EndpointSlices
Auf EKS verwendet Kube-Proxy hauptsächlich iptables-NAT-Regeln (oder IPVS NFTables
Verwenden von Topology Aware Routing (früher bekannt als Topology Aware Hints)
Wenn topologiebewusstes Routingkube-proxyleitet dann den Verkehr von einer Zone zu einem Endpunkt weiter, basierend auf den Hinweisen, die angewendet werden.
Das folgende Diagramm zeigt, wie EndpointSlices die With-Hinweise so organisiert sind, dass anhand ihres zonalen Ausgangspunkts sofort erkannt werden kube-proxy kann, zu welchem Ziel sie gehen sollen. Ohne Hinweise gibt es keine solche Zuordnung oder Organisation, und der Verkehr wird an verschiedene zonale Ziele weitergeleitet, unabhängig davon, woher er kommt.
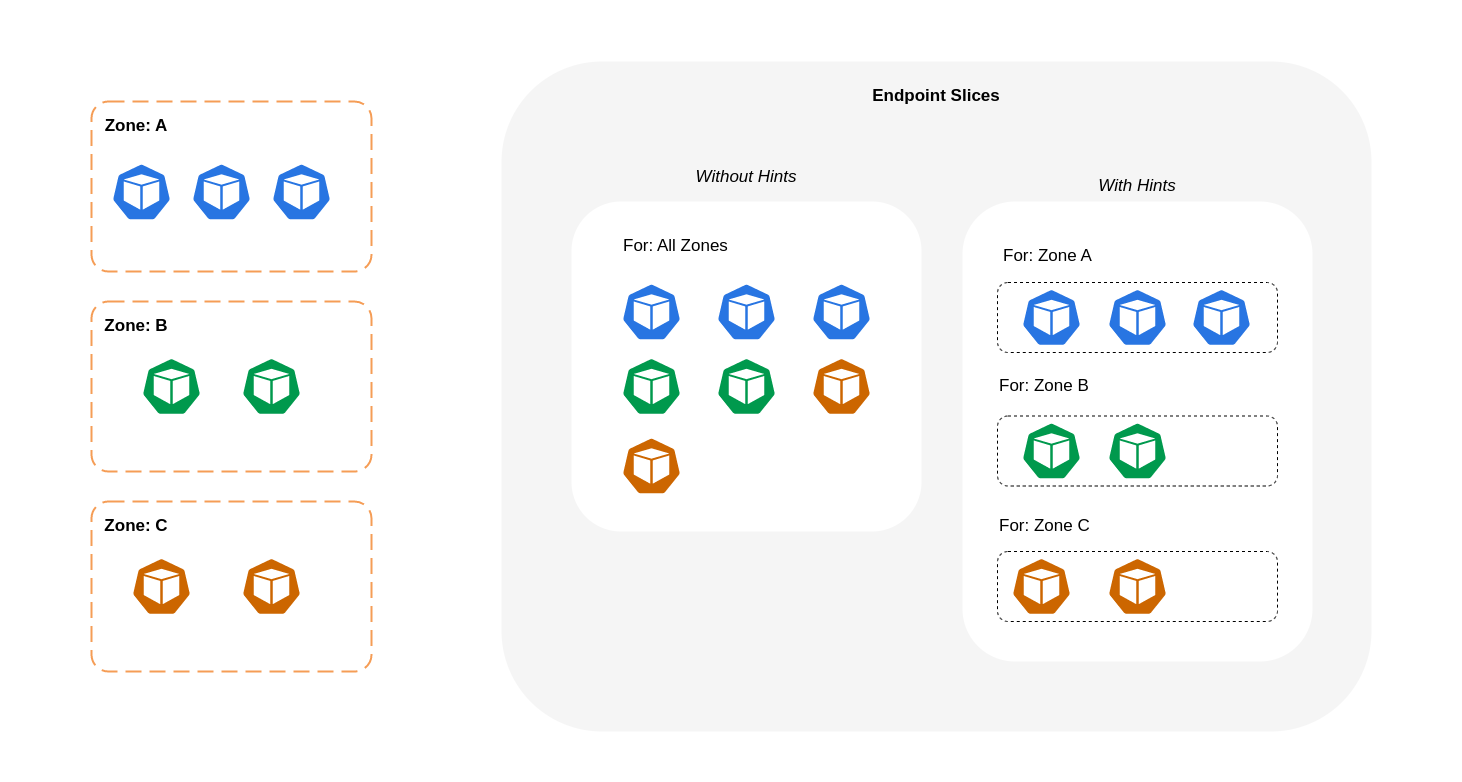
In einigen Fällen wendet der EndpointSlice Controller möglicherweise einen Hinweis für eine andere Zone an, was bedeutet, dass der Endpunkt am Ende Datenverkehr aus einer anderen Zone bedienen könnte. Der Grund dafür ist der Versuch, eine gleichmäßige Verteilung des Datenverkehrs zwischen Endpunkten in verschiedenen Zonen aufrechtzuerhalten.
Im Folgenden finden Sie einen Codeausschnitt zur Aktivierung von topologieorientiertem Routing für einen Dienst.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Der folgende Screenshot zeigt das Ergebnis, dass der EndpointSlice Controller erfolgreich einen Hinweis auf einen Endpunkt für ein Pod-Replikat angewendet hat, das in der AZ ausgeführt wird. eu-west-1a

Anmerkung
Es ist wichtig zu beachten, dass sich topologiebewusstes Routing noch in der Betaphase befindet. Bei gleichmäßig über die Clustertopologie verteilten Arbeitslasten arbeitet diese Funktion besser vorhersehbar, da der Controller die Endpunkte proportional auf die Zonen verteilt, aber die Zuweisungen von Hinweisen überspringen kann, wenn die Knotenressourcen in einer Zone zu unausgewogen sind, um eine übermäßige Überlastung zu vermeiden. Es wird daher dringend empfohlen, sie zusammen mit Einschränkungen bei der Terminplanung zu verwenden, die die Verfügbarkeit einer Anwendung erhöhen, wie z. B. Einschränkungen bei der Verteilung der Pod-Topologie.
Verwendung der Verkehrsverteilung
Traffic Distribution wurde in Kubernetes 1.30 eingeführt und in Version 1.33 allgemein verfügbar gemacht. Es bietet eine einfachere Alternative zu topologiebewusstem Routing, um Traffic
Im Folgenden finden Sie einen Codeausschnitt zur Aktivierung der Verkehrsverteilung für einen Dienst.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Bei der Aktivierung der Verkehrsverteilung tritt ein häufiges Problem auf: Endpunkte innerhalb einer einzelnen AZ können überlastet werden, wenn der Großteil des Datenverkehrs aus derselben Zone stammt. Diese Überlastung kann zu erheblichen Problemen führen:
-
Ein einziger Horizontal Pod Autoscaler (HPA), der eine Multi-AZ-Bereitstellung verwaltet, kann darauf reagieren, indem er Pods auf verschiedene Pods skaliert. AZs Mit dieser Aktion kann die erhöhte Last in der betroffenen Zone jedoch nicht wirksam behoben werden.
-
Diese Situation wiederum kann zu einer ineffizienten Nutzung der Ressourcen führen. Wenn Cluster-Autoscaler wie Karpenter erkennen, dass der Pod über verschiedene Bereiche skaliert wird, können sie zusätzliche Knoten in den nicht betroffenen Gebieten bereitstellen AZs, was zu einer AZs unnötigen Ressourcenzuweisung führt.
Um diese Herausforderung zu bewältigen:
-
Erstellen Sie separate Bereitstellungen pro Zone, die über eigene Bereitstellungen verfügen HPAs , sodass sie unabhängig voneinander skaliert werden können.
-
Nutzen Sie Topology Spread Constraints, um die Verteilung der Arbeitslast im Cluster sicherzustellen und so eine Überlastung der Endpunkte in stark frequentierten Zonen zu verhindern.
Verwenden von Autoscalern: Stellen Sie Knoten für eine bestimmte AZ bereit
Wir empfehlen dringend, Ihre Workloads in hochverfügbaren Umgebungen in mehreren Umgebungen auszuführen. AZs Dies verbessert die Zuverlässigkeit Ihrer Anwendungen, insbesondere wenn ein Problem mit einer AZ auftritt. Falls Sie bereit sind, die Zuverlässigkeit zu opfern, um die Netzwerkkosten zu senken, können Sie Ihre Knoten auf eine einzige AZ beschränken.
Um all Ihre Pods in derselben AZ auszuführen, stellen Sie entweder die Worker-Knoten in derselben AZ bereit oder planen Sie die Pods auf den Worker-Knoten, die auf derselben AZ laufen. Um Knoten innerhalb einer einzigen AZ bereitzustellen, definieren Sie mit Cluster Autoscaler (topology.kubernetes.io/zone und geben Sie sie an. Das folgende Karpenter-Provisioner-Snippet stellt beispielsweise die Knoten in der AZ us-west-2a bereit.
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
Cluster-Autoscaler (Kalifornien)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
Verwendung von Pod-Zuweisung und Knotenaffinität
Wenn Sie Worker-Knoten haben, die in mehreren ausgeführt werden AZs, hätte alternativ jeder Knoten die Bezeichnung topology.kubernetes.io/zonenodeSelector nodeAffinity Mit der folgenden Manifestdatei wird beispielsweise der Pod innerhalb eines Knotens geplant, der in AZ us-west-2a ausgeführt wird.
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
Beschränkung des Datenverkehrs auf einen Knoten
Es gibt Fälle, in denen es nicht ausreicht, den Verkehr auf zonaler Ebene zu beschränken. Neben der Kostensenkung müssen Sie möglicherweise auch die Netzwerklatenz zwischen bestimmten Anwendungen reduzieren, die häufig miteinander kommunizieren. Um eine optimale Netzwerkleistung zu erzielen und die Kosten zu senken, benötigen Sie eine Möglichkeit, den Datenverkehr auf einen bestimmten Knoten zu beschränken. Beispielsweise sollte Microservice A immer mit Microservice B auf Knoten 1 kommunizieren, selbst in Umgebungen mit hoher Verfügbarkeit (HA). Wenn Microservice A auf Knoten 1 mit Microservice B auf Knoten 2 kommuniziert, kann sich dies negativ auf die gewünschte Leistung für Anwendungen dieser Art auswirken, insbesondere wenn sich Knoten 2 in einer separaten AZ befindet.
Verwendung der internen Verkehrsrichtlinie des Dienstes
Um den Pod-Netzwerkverkehr auf einen Knoten zu beschränken, können Sie die interne Verkehrsrichtlinie des DienstesLocal, wird der Verkehr auf Endpunkte auf dem Knoten beschränkt, von dem der Datenverkehr stammt. Diese Richtlinie schreibt die ausschließliche Verwendung von knotenlokalen Endpunkten vor. Das bedeutet, dass Ihre mit dem Netzwerkverkehr verbundenen Kosten für diesen Workload niedriger sein werden, als wenn die Verteilung clusterweit erfolgen würde. Außerdem wird die Latenz geringer sein, wodurch Ihre Anwendung leistungsfähiger wird.
Anmerkung
Es ist wichtig zu beachten, dass diese Funktion nicht mit topologieorientiertem Routing in Kubernetes kombiniert werden kann.
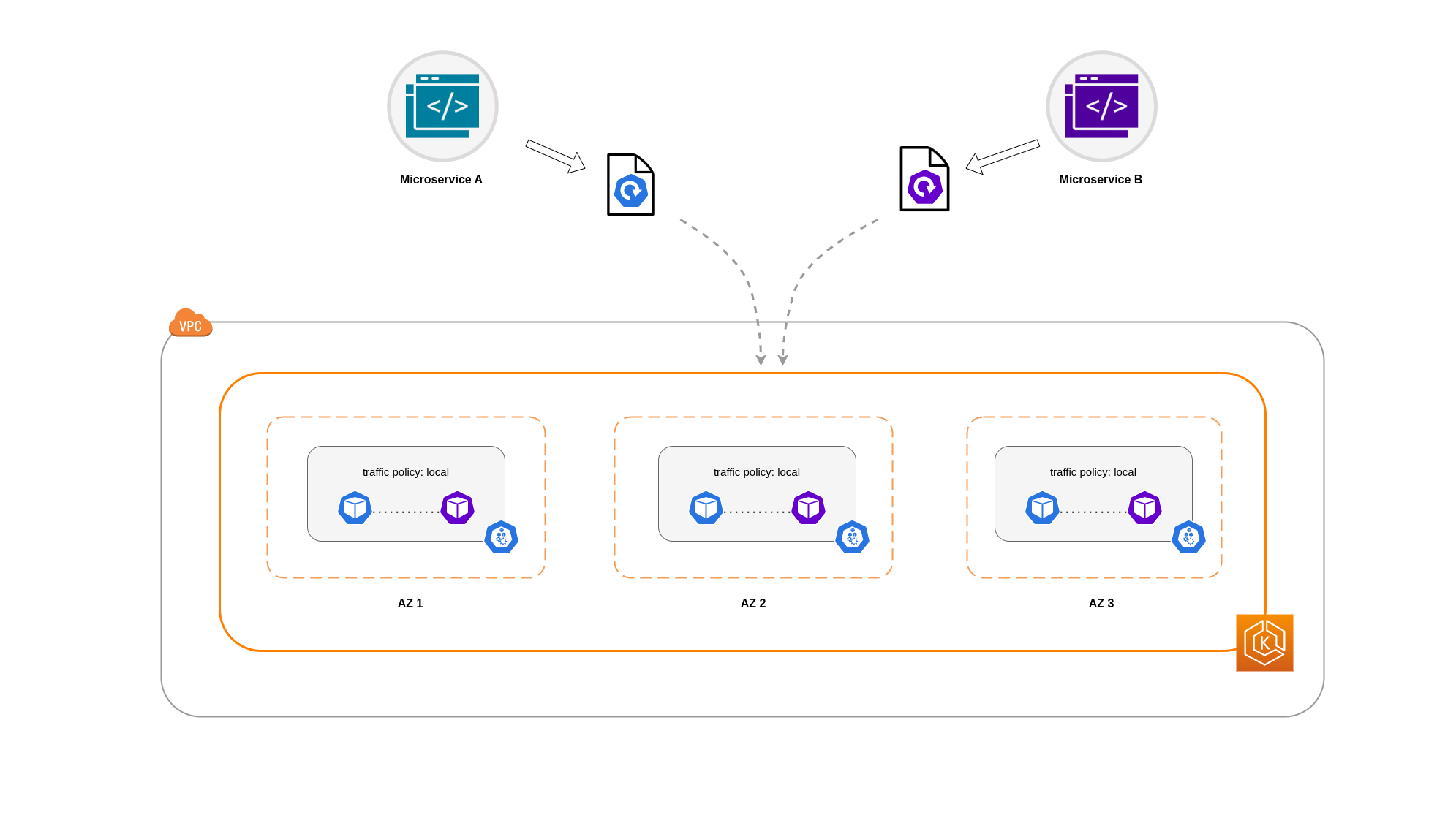
Im Folgenden finden Sie einen Codeausschnitt zum Festlegen der internen Verkehrsrichtlinie für einen Dienst.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
Um ein unerwartetes Verhalten Ihrer Anwendung aufgrund von Datenverkehrsausfällen zu vermeiden, sollten Sie die folgenden Ansätze in Betracht ziehen:
-
Führen Sie genügend Replikate für jeden der kommunizierenden Pods aus
-
Sorgen Sie mithilfe von Beschränkungen der Topologieverteilung
für eine relativ gleichmäßige Verteilung der Pods -
Verwenden Sie Pod-Affinitätsregeln für die Kolokation kommunizierender Pods
In diesem Beispiel haben Sie 2 Replikate von Microservice A und 3 Repliken von Microservice B. Wenn Microservice A seine Replikate auf Knoten 1 und 2 verteilt hat und Microservice B alle 3 Replikate auf Knoten 3 hat, können sie aufgrund der internen Datenverkehrsrichtlinie nicht kommunizieren. Local Wenn keine knotenlokalen Endpunkte verfügbar sind, wird der Datenverkehr unterbrochen.
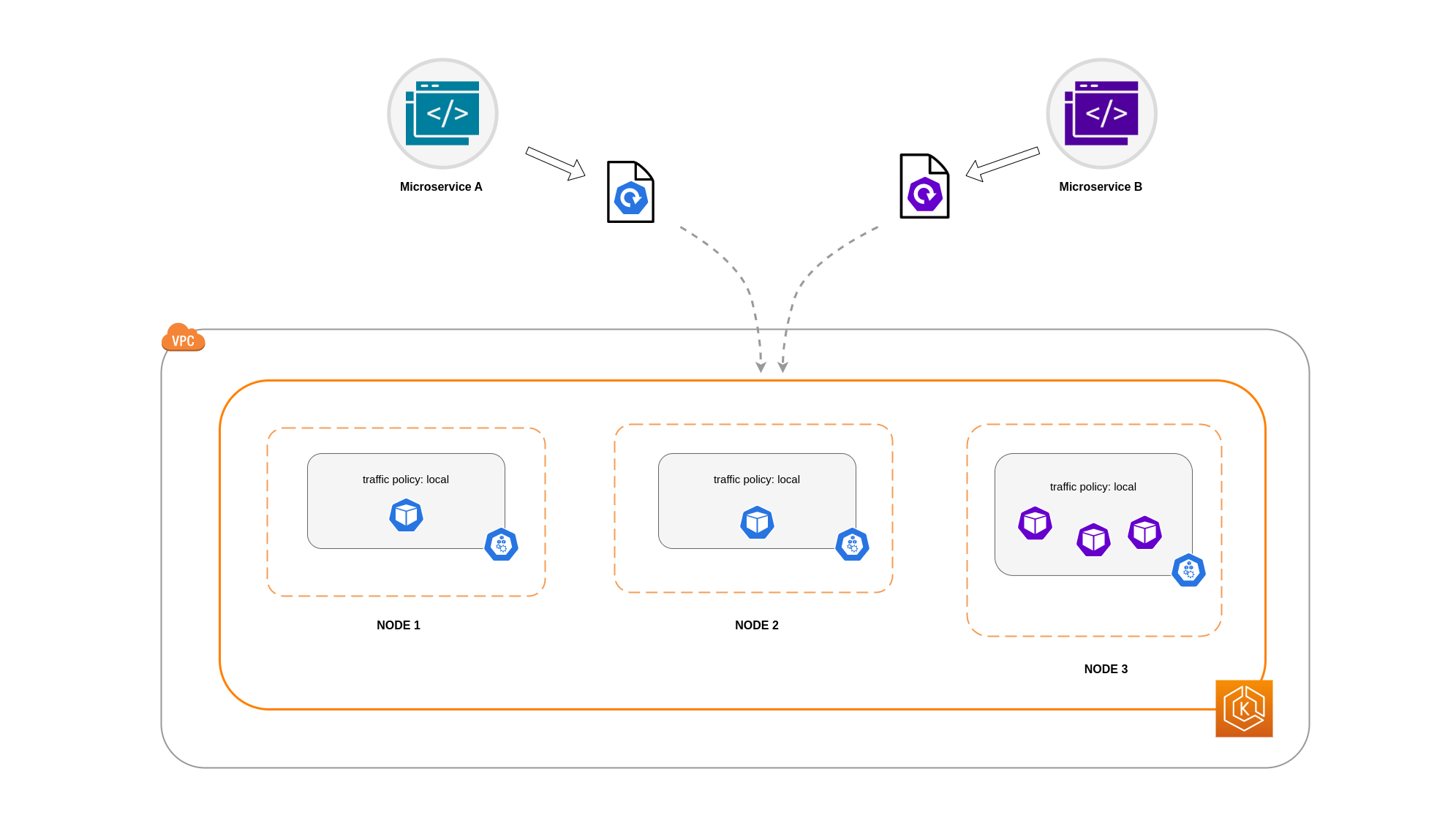
Wenn Microservice B 2 seiner 3 Replikate auf den Knoten 1 und 2 hat, findet eine Kommunikation zwischen den Peer-Anwendungen statt. Aber Sie hätten immer noch ein isoliertes Replikat von Microservice B ohne ein Peer-Replikat, mit dem Sie kommunizieren könnten.
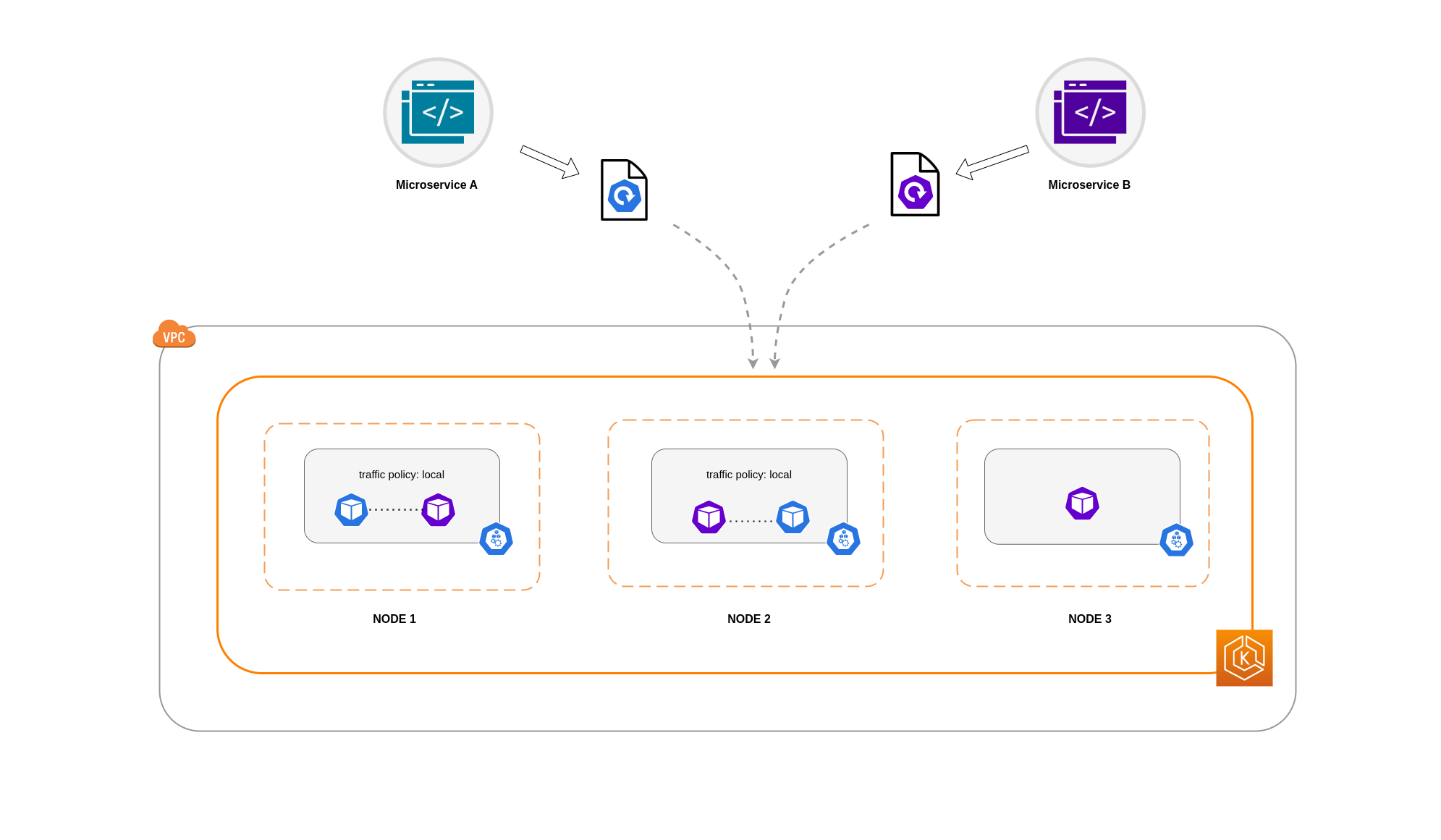
Anmerkung
In einigen Szenarien ist ein isoliertes Replikat wie das im obigen Diagramm dargestellte möglicherweise kein Grund zur Sorge, wenn es immer noch einem Zweck dient (z. B. der Bearbeitung von Anfragen aus eingehendem externen Verkehr).
Verwenden der internen Datenverkehrsrichtlinie des Dienstes mit Einschränkungen der Topologieverteilung
Die Verwendung der internen Verkehrsrichtlinie in Verbindung mit Einschränkungen der Topologieverteilung kann nützlich sein, um sicherzustellen, dass Sie über die richtige Anzahl von Replikaten für die Kommunikation von Microservices auf verschiedenen Knoten verfügen.
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
Verwenden der internen Verkehrsrichtlinie des Dienstes mit Pod-Affinitätsregeln
Ein anderer Ansatz besteht darin, Pod-Affinitätsregeln zu verwenden, wenn die interne Verkehrsrichtlinie des Dienstes verwendet wird. Mit Pod-Affinität können Sie den Terminplaner so beeinflussen, dass er bestimmte Pods aufgrund ihrer häufigen Kommunikation zusammenbringt. Durch die Anwendung strenger Planungsbeschränkungen (requiredDuringSchedulingIgnoredDuringExecution) auf bestimmte Pods erzielen Sie auf diese Weise bessere Ergebnisse bei der Pod-Kolokation, wenn der Scheduler Pods auf Knoten platziert.
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Kommunikation zwischen Load Balancer und Pod
EKS-Workloads werden in der Regel von einem Load Balancer unterstützt, der den Datenverkehr an die entsprechenden Pods in Ihrem EKS-Cluster verteilt. Ihre Architektur kann interne, nach and/or außen gerichtete Load Balancer umfassen. Abhängig von Ihrer Architektur und der Konfiguration des Netzwerkverkehrs kann die Kommunikation zwischen Load Balancern und Pods einen erheblichen Beitrag zu den Datenübertragungsgebühren leisten.
Sie können den AWS Load Balancer Controller
Wenn Sie den Instance-Modus verwenden, NodePort wird auf jedem Knoten in Ihrem EKS-Cluster eine geöffnet. Der Load Balancer leitet den Datenverkehr dann gleichmäßig über die Knoten weiter. Wenn auf einem Knoten der Ziel-Pod ausgeführt wird, fallen keine Datenübertragungskosten an. Befindet sich der Ziel-Pod jedoch auf einem separaten Knoten und in einer anderen AZ als der, der den Datenverkehr NodePort empfängt, erfolgt ein zusätzlicher Netzwerk-Hop vom Kube-Proxy zum Ziel-Pod. In einem solchen Szenario fallen AZ-übergreifende Datenübertragungsgebühren an. Aufgrund der gleichmäßigen Verteilung des Datenverkehrs auf die Knoten ist es sehr wahrscheinlich, dass im Zusammenhang mit zonenübergreifenden Netzwerk-Traffic-Hops von Kube-Proxys zu den entsprechenden Ziel-Pods zusätzliche Datenübertragungsgebühren anfallen.
Das folgende Diagramm zeigt einen Netzwerkpfad für den Datenverkehr, der vom Load Balancer zum und anschließend vom Ziel-Pod auf einem separaten kube-proxy Knoten in einer anderen AZ fließt. NodePort Dies ist ein Beispiel für die Einstellung des Instanzmodus.
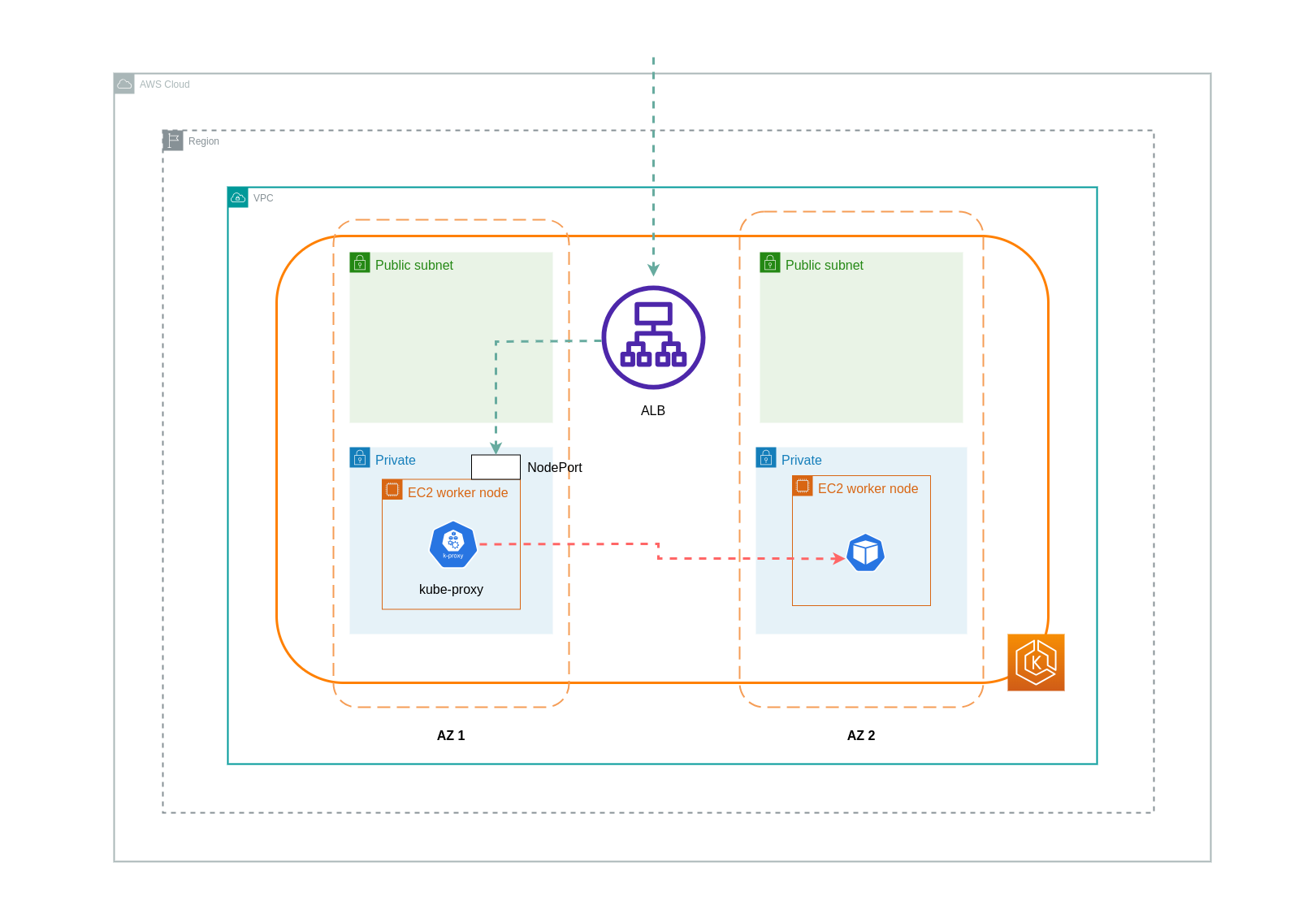
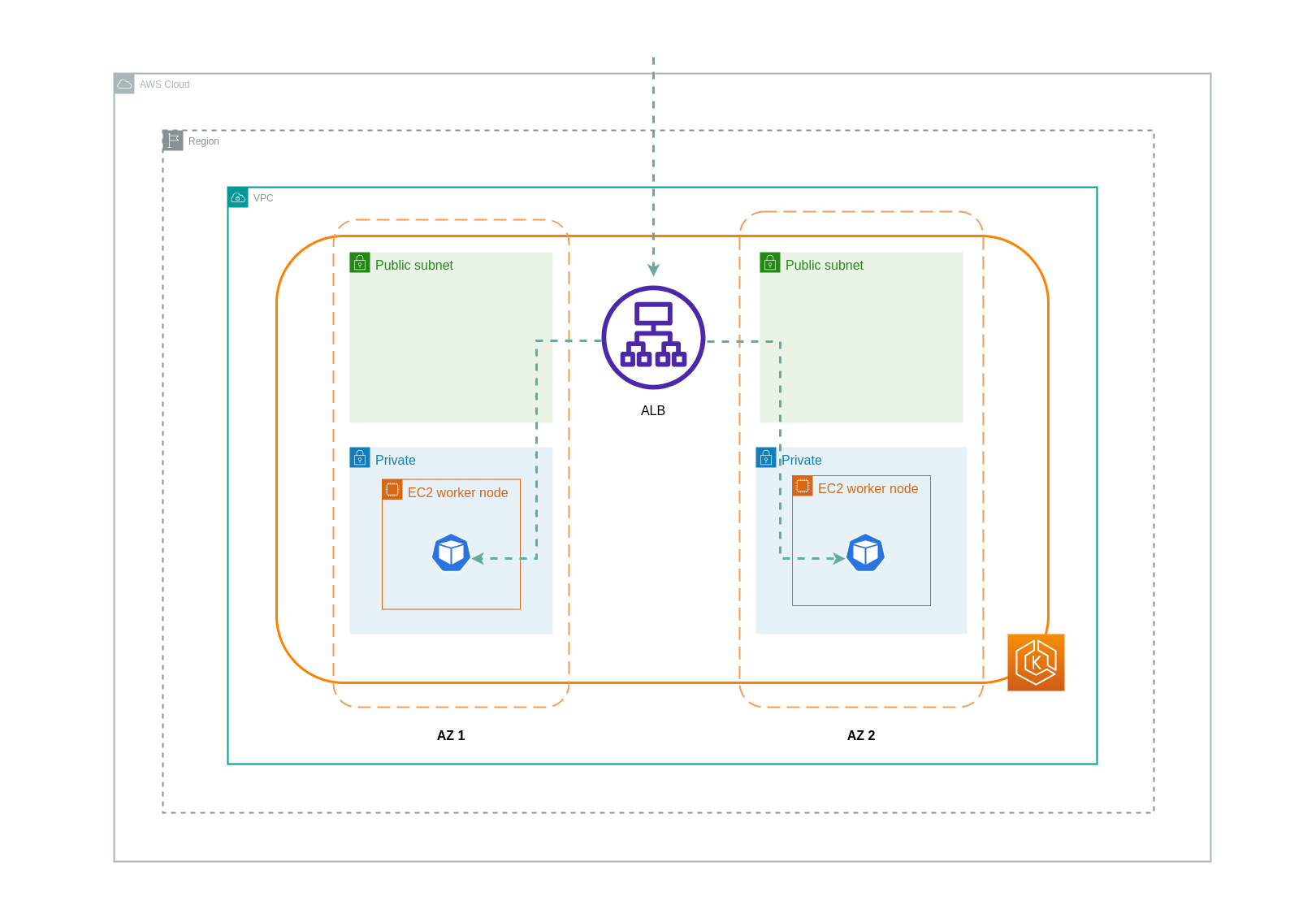
Bei Verwendung des IP-Modus wird der Netzwerkverkehr vom Load Balancer direkt an den Ziel-Pod weitergeleitet. Daher fallen bei diesem Ansatz keine Datenübertragungsgebühren an.
Anmerkung
Es wird empfohlen, Ihren Load Balancer auf den IP-Verkehrsmodus einzustellen, um die Datenübertragungsgebühren zu senken. Für dieses Setup ist es auch wichtig, sicherzustellen, dass Ihr Load Balancer in allen Subnetzen in Ihrer VPC eingesetzt wird.
Das folgende Diagramm zeigt Netzwerkpfade für den Datenverkehr, der im Netzwerk-IP-Modus vom Load Balancer zu den Pods fließt.
Datenübertragung aus Container Registry
Amazon ECR
Die Datenübertragung in die private Registrierung von Amazon ECR ist kostenlos. Für die Datenübertragung innerhalb der Region fallen keine Kosten an, aber für Datenübertragungen ins Internet und zwischen Regionen fallen Gebühren für die Internet-Datenübertragung auf beiden Seiten der Übertragung an.
Sie sollten die ECRs integrierte Image-Replikationsfunktion verwenden, um die relevanten Container-Images in dieselbe Region zu replizieren, in der sich Ihre Workloads befinden. Auf diese Weise würde die Replikation einmal in Rechnung gestellt werden, und alle Abrufe von Images aus derselben Region (innerhalb der Region) wären kostenlos.
Sie können die mit dem Abrufen von Bildern aus ECR (ausgehende Datenübertragung) verbundenen Datenübertragungskosten weiter reduzieren, indem Sie Interface VPC Endpoints verwenden, um eine Verbindung zu den ECR-Repositorys in der Region herzustellen. Der alternative Ansatz, eine Verbindung zum öffentlichen AWS-Endpunkt von ECR herzustellen (über ein NAT-Gateway und ein Internet Gateway), wird höhere Datenverarbeitungs- und Übertragungskosten mit sich bringen. Im nächsten Abschnitt wird die Reduzierung der Datenübertragungskosten zwischen Ihren Workloads und AWS-Services ausführlicher behandelt.
Wenn Sie Workloads mit besonders großen Images ausführen, können Sie Ihre eigenen benutzerdefinierten Amazon Machine Images (AMIs) mit vorab zwischengespeicherten Container-Images erstellen. Dadurch können die Zeit für den ersten Abruf von Images und die potenziellen Kosten für die Datenübertragung von einer Container-Registry zu den EKS-Worker-Knoten reduziert werden.
Datenübertragung ins Internet und zu AWS-Services
Es ist üblich, Kubernetes-Workloads über das Internet in andere AWS-Services oder Tools und Plattformen von Drittanbietern zu integrieren. Die zugrunde liegende Netzwerkinfrastruktur, die für die Weiterleitung des Datenverkehrs zum und vom jeweiligen Ziel verwendet wird, kann sich auf die Kosten auswirken, die beim Datenübertragungsprozess anfallen.
Verwendung von NAT-Gateways
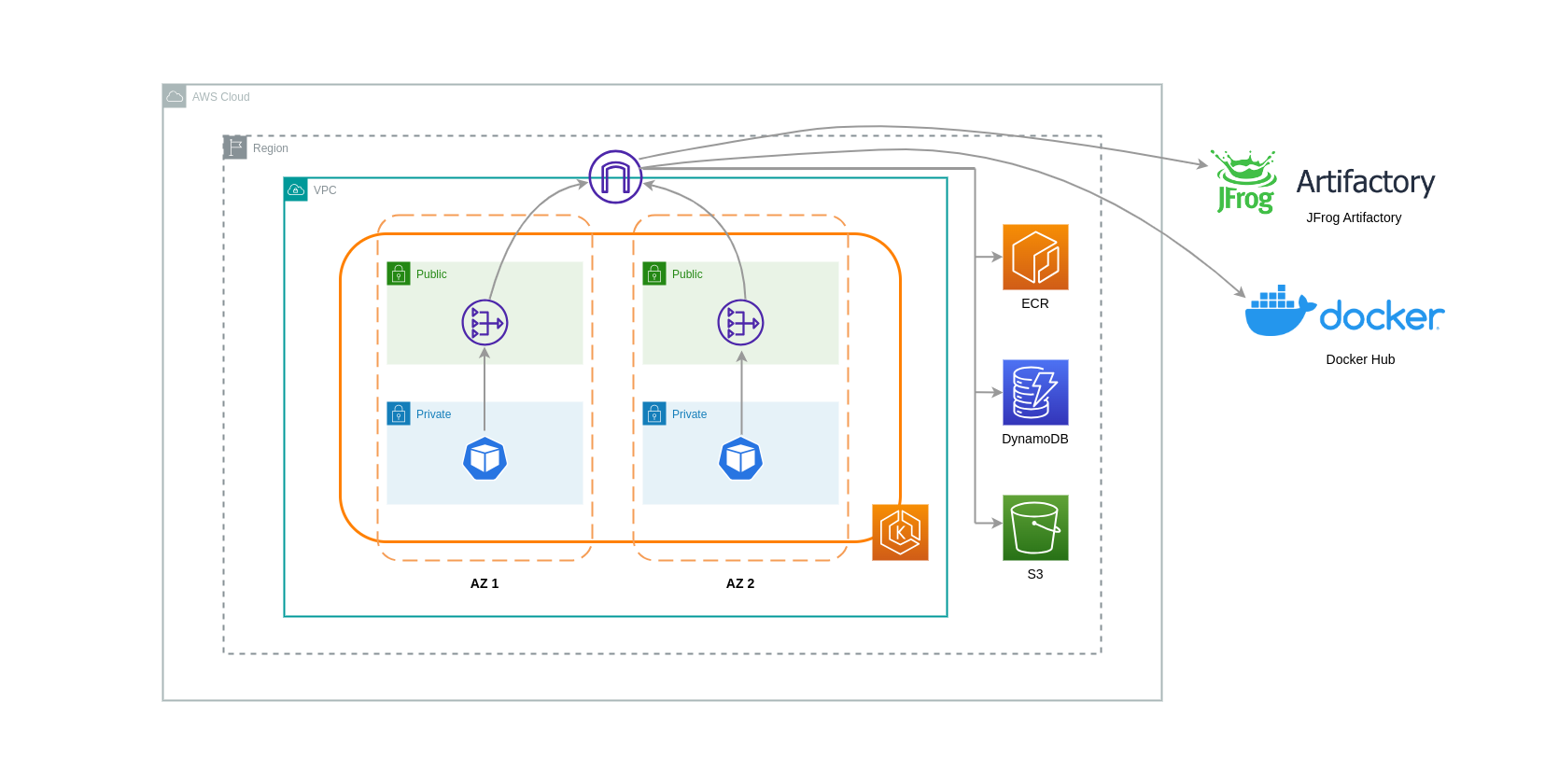
NAT-Gateways sind Netzwerkkomponenten, die die Netzwerkadressübersetzung (NAT) durchführen. Das folgende Diagramm zeigt Pods in einem EKS-Cluster, die mit anderen AWS-Services (Amazon ECR, DynamoDB und S3) und Plattformen von Drittanbietern kommunizieren. In diesem Beispiel werden die Pods in separaten privaten Subnetzen ausgeführt. AZs Zum Senden und Empfangen von Datenverkehr aus dem Internet wird ein NAT-Gateway im öffentlichen Subnetz einer AZ bereitgestellt, sodass alle Ressourcen mit privaten IP-Adressen gemeinsam auf eine einzige öffentliche IP-Adresse zugreifen können, um auf das Internet zuzugreifen. Dieses NAT-Gateway kommuniziert wiederum mit der Internet-Gateway-Komponente, sodass Pakete an ihr endgültiges Ziel gesendet werden können.
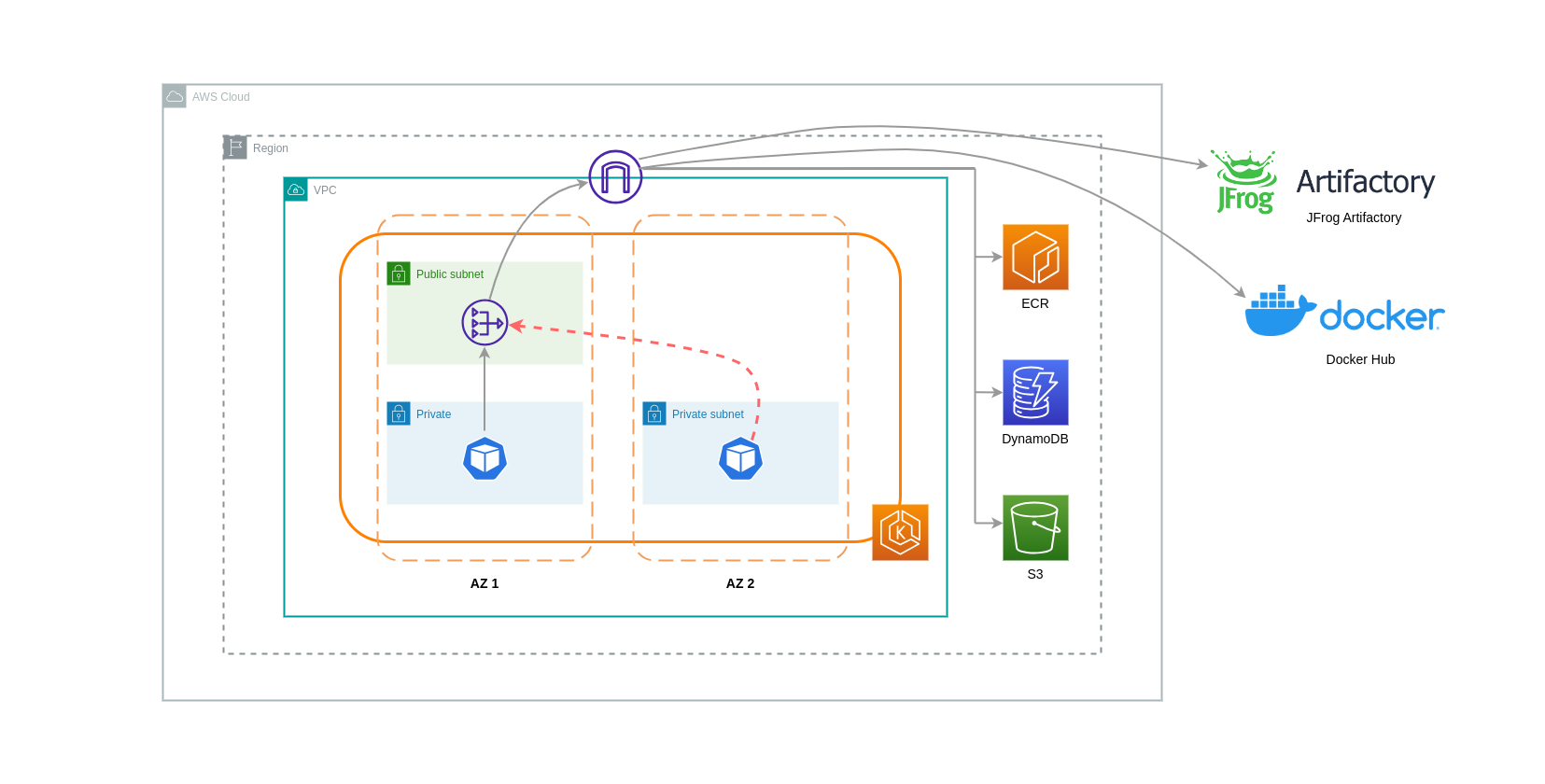
Wenn Sie NAT-Gateways für solche Anwendungsfälle verwenden, können Sie die Datenübertragungskosten minimieren, indem Sie in jeder AZ ein NAT-Gateway bereitstellen. Auf diese Weise wird der an das Internet weitergeleitete Datenverkehr über das NAT-Gateway in derselben AZ geleitet, wodurch eine Datenübertragung zwischen den AZ vermieden wird. Sie sparen zwar die Kosten für die Datenübertragung zwischen den AZ-Datenbanken, aber diese Konfiguration hat zur Folge, dass Ihnen die Kosten für ein zusätzliches NAT-Gateway in Ihrer Architektur entstehen.
Dieser empfohlene Ansatz ist in der folgenden Abbildung dargestellt.
Verwenden eines VPC-Endpunkts
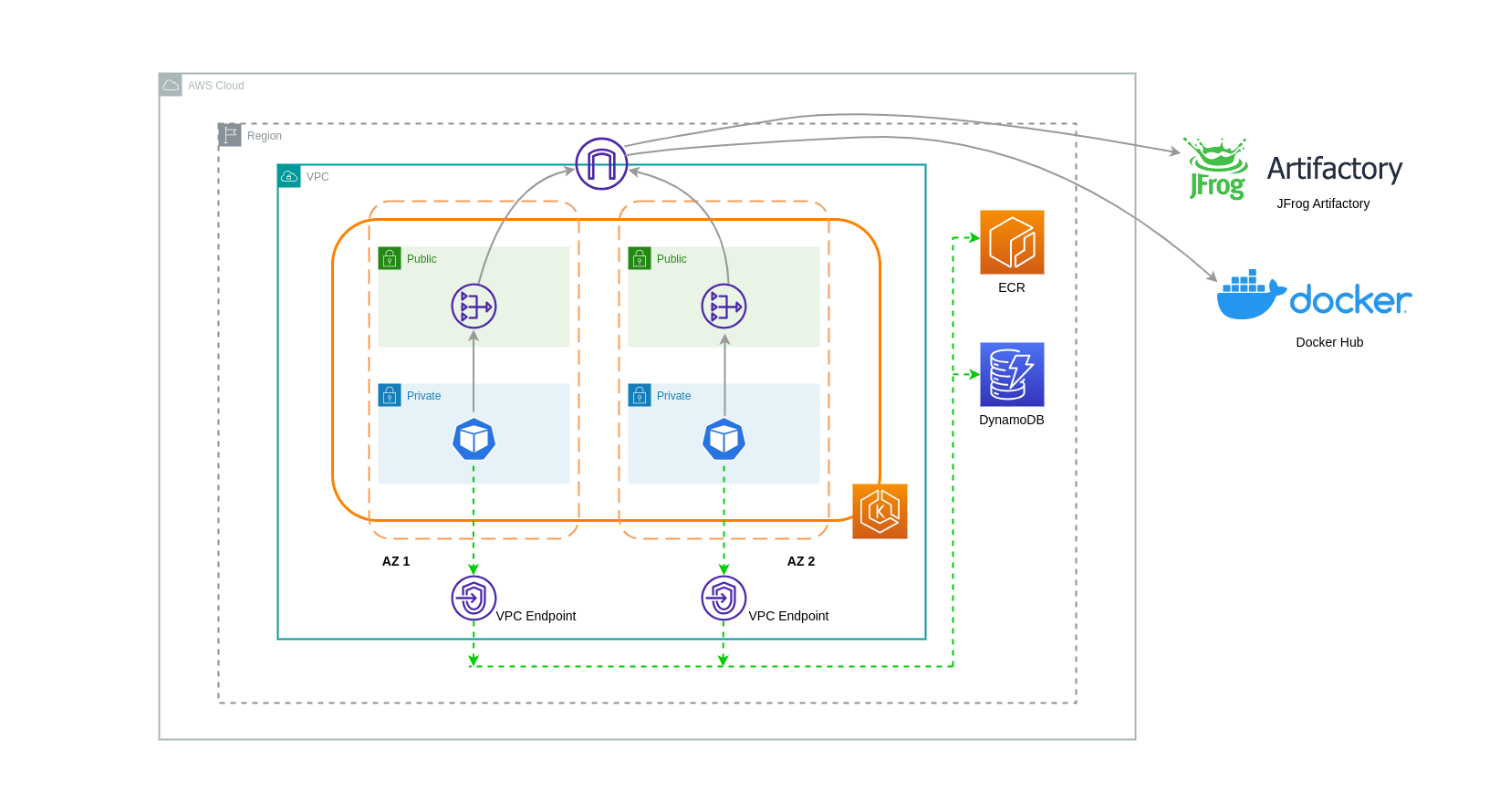
Um die Kosten in solchen Architekturen weiter zu senken, sollten Sie VPC-Endpunkte verwenden, um Konnektivität zwischen Ihren Workloads und AWS-Services herzustellen. Mit VPC-Endpunkten können Sie von einer VPC aus auf AWS-Services zugreifen, ohne dass data/network Pakete das Internet durchqueren. Der gesamte Datenverkehr ist intern und verbleibt innerhalb des AWS-Netzwerks. Es gibt zwei Arten von VPC-Endpunkten: Interface-VPC-Endpunkte (von vielen AWS-Services unterstützt) und Gateway-VPC-Endpunkte (nur von S3 und DynamoDB unterstützt).
Gateway-VPC-Endpunkte
Im Zusammenhang mit Gateway-VPC-Endpunkten fallen keine Stunden- oder Datenübertragungskosten an. Bei der Verwendung von Gateway-VPC-Endpunkten ist zu beachten, dass sie nicht über VPC-Grenzen hinweg erweiterbar sind. Sie können nicht für VPC-Peering, VPN-Netzwerke oder über Direct Connect verwendet werden.
Schnittstelle VPC-Endpunkte
Für VPC-Endpunkte fällt eine stündliche Gebühr
Das folgende Diagramm zeigt Pods, die über VPC-Endpunkte mit AWS-Services kommunizieren.
Datenübertragung zwischen VPCs
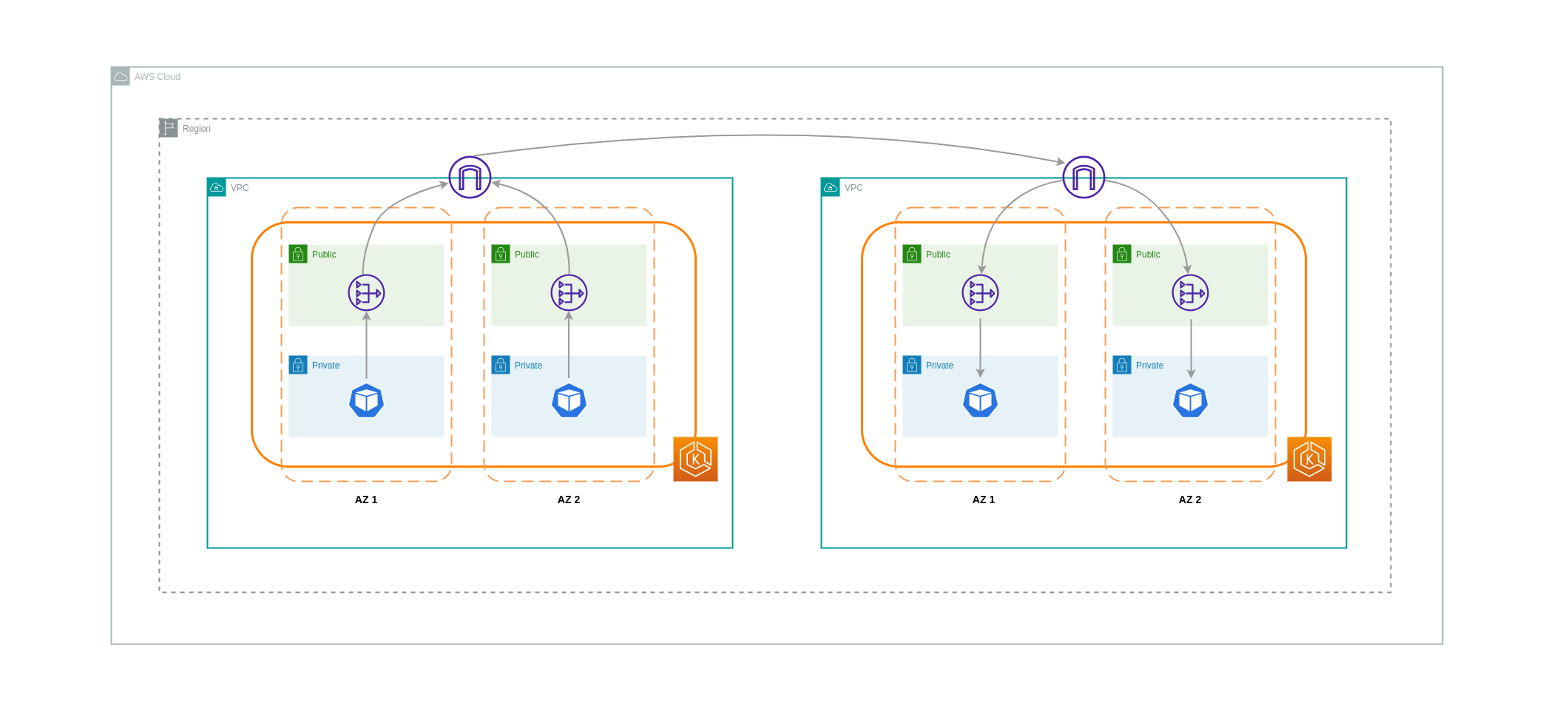
In einigen Fällen haben Sie möglicherweise unterschiedliche Workloads VPCs (innerhalb derselben AWS-Region), die miteinander kommunizieren müssen. Dies kann erreicht werden, indem der Datenverkehr über Internet-Gateways, die an die jeweiligen Geräte angeschlossen sind, das öffentliche Internet durchqueren kann. VPCs Eine solche Kommunikation kann durch den Einsatz von Infrastrukturkomponenten wie EC2 Instances, NAT-Gateways oder NAT-Instances in öffentlichen Subnetzen ermöglicht werden. Bei einem Setup, das diese Komponenten enthält, fallen jedoch Gebühren für den ein- und ausgehenden processing/transferring Datenverkehr an. VPCs Wenn der Verkehr zu und von der separaten VPCs Anlage übertragen wird AZs, fällt für die Datenübertragung eine zusätzliche Gebühr an. Das folgende Diagramm zeigt ein Setup, das NAT-Gateways und Internet-Gateways verwendet, um die Kommunikation zwischen Workloads in unterschiedlichen Umgebungen herzustellen. VPCs
VPC-Peering-Verbindungen
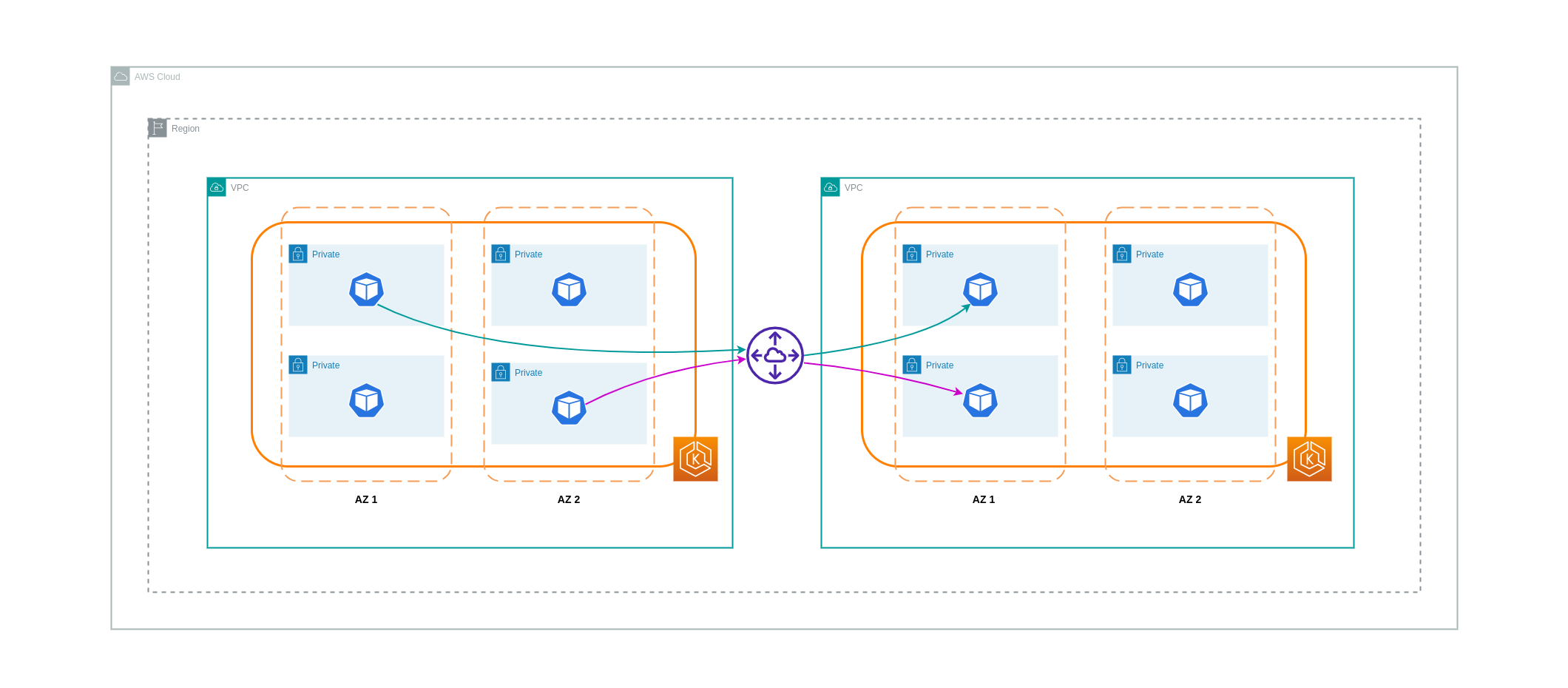
Um die Kosten für solche Anwendungsfälle zu senken, können Sie VPC Peering verwenden. Bei einer VPC-Peering-Verbindung fallen keine Datenübertragungsgebühren für Netzwerkverkehr an, der innerhalb derselben AZ bleibt. Wenn sich der Verkehr kreuzt AZs, fallen Kosten an. Dennoch wird der VPC-Peering-Ansatz für eine kostengünstige Kommunikation zwischen separaten Workloads VPCs innerhalb derselben AWS-Region empfohlen. Es ist jedoch wichtig zu beachten, dass VPC-Peering in erster Linie für 1:1 VPC-Konnektivität wirksam ist, da es keine transitiven Netzwerke ermöglicht.
Das folgende Diagramm zeigt eine allgemeine Darstellung der Workload-Kommunikation über eine VPC-Peering-Verbindung.
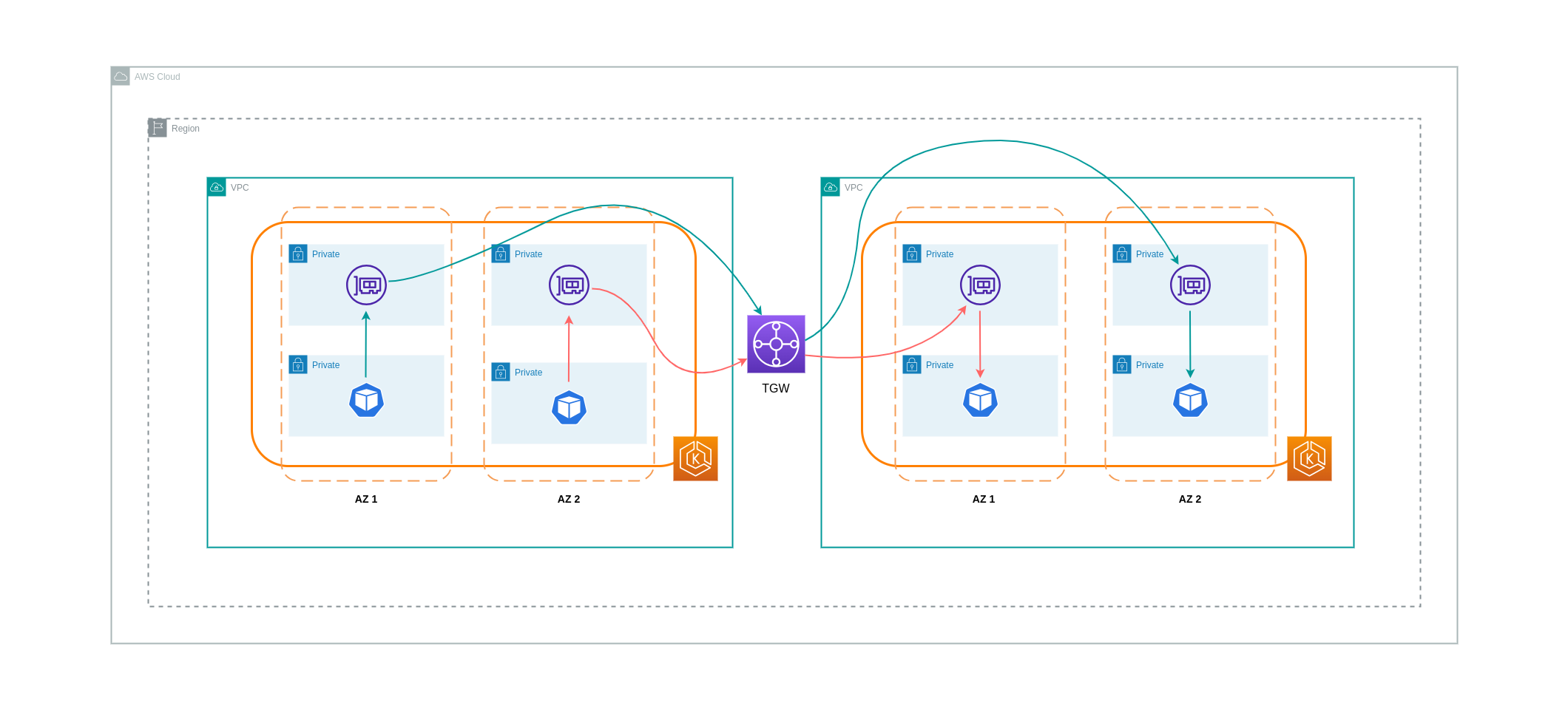
Transitive Netzwerkverbindungen
Wie im vorherigen Abschnitt erwähnt, ermöglichen VPC-Peering-Verbindungen keine transitive Netzwerkkonnektivität. Wenn Sie 3 oder mehr Verbindungen VPCs mit transitiven Netzwerkanforderungen herstellen möchten, sollten Sie ein Transit Gateway (TGW) verwenden. Auf diese Weise können Sie die Grenzen des VPC-Peerings oder jeglichen betrieblichen Mehraufwand überwinden, der mit mehreren VPC-Peering-Verbindungen zwischen mehreren verbunden ist. VPCs Die an das TGW gesendeten Daten werden Ihnen auf Stundenbasis in Rechnung gestellt
Das folgende Diagramm zeigt den Inter-AZ-Verkehr, der über ein TGW zwischen Workloads in verschiedenen, VPCs aber innerhalb derselben AWS-Region fließt.
Verwenden eines Service Mesh
Service Meshes bieten leistungsstarke Netzwerkfunktionen, mit denen Sie die Netzwerkkosten in Ihren EKS-Cluster-Umgebungen senken können. Sie sollten jedoch die betrieblichen Aufgaben und die Komplexität, die ein Service Mesh für Ihre Umgebung mit sich bringen wird, sorgfältig abwägen, wenn Sie eines einführen.
Beschränkung des Datenverkehrs auf Availability Zones
Verwendung der nach Lokalität gewichteten Verteilung von Istio
Mit Istio können Sie Netzwerkrichtlinien auf den Datenverkehr anwenden, nachdem das Routing erfolgt ist. Dies erfolgt mithilfe von Zielregeln
Anmerkung
Bevor Sie die nach Lokalität gewichtete Verteilung implementieren, sollten Sie zunächst Ihre Netzwerkverkehrsmuster und die Auswirkungen verstehen, die die Zielregelrichtlinie auf das Verhalten Ihrer Anwendung haben kann. Daher ist es wichtig, verteilte Verfolgungsmechanismen mit Tools wie AWS X-Ray
Die oben aufgeführten Istio-Zielregeln können auch zur Verwaltung des Datenverkehrs von einem Load Balancer zu Pods in Ihrem EKS-Cluster angewendet werden. Lokalitätsgewichtete Verteilungsregeln können auf einen Dienst angewendet werden, der Datenverkehr von einem hochverfügbaren Load Balancer (insbesondere dem Ingress Gateway) empfängt. Mit diesen Regeln können Sie anhand seines zonalen Ursprungs — in diesem Fall dem Load Balancer — steuern, wie viel Verkehr wohin fließt. Bei korrekter Konfiguration fällt weniger ausgehender zonenübergreifender Datenverkehr an als bei einem Load Balancer, der den Datenverkehr gleichmäßig oder zufällig auf Pod-Replikate in unterschiedlichen Pod-Replikaten verteilt. AZs
Im Folgenden finden Sie ein Codeblock-Beispiel für eine Zielregelressource in Istio. Wie unten zu sehen ist, spezifiziert diese Ressource gewichtete Konfigurationen für eingehenden Verkehr aus 3 verschiedenen Quellen AZs in der eu-west-1 Region. Diese Konfigurationen legen fest, dass ein Großteil des eingehenden Datenverkehrs (in diesem Fall 70%) von einer bestimmten AZ an ein Ziel in derselben AZ weitergeleitet werden sollte, von der er stammt.
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
Anmerkung
Das Mindestgewicht, das an ein Ziel verteilt werden kann, beträgt 1%. Der Grund dafür ist die Beibehaltung von Failover-Regionen und -Zonen für den Fall, dass die Endpunkte im Hauptziel fehlerhaft oder nicht verfügbar sind.
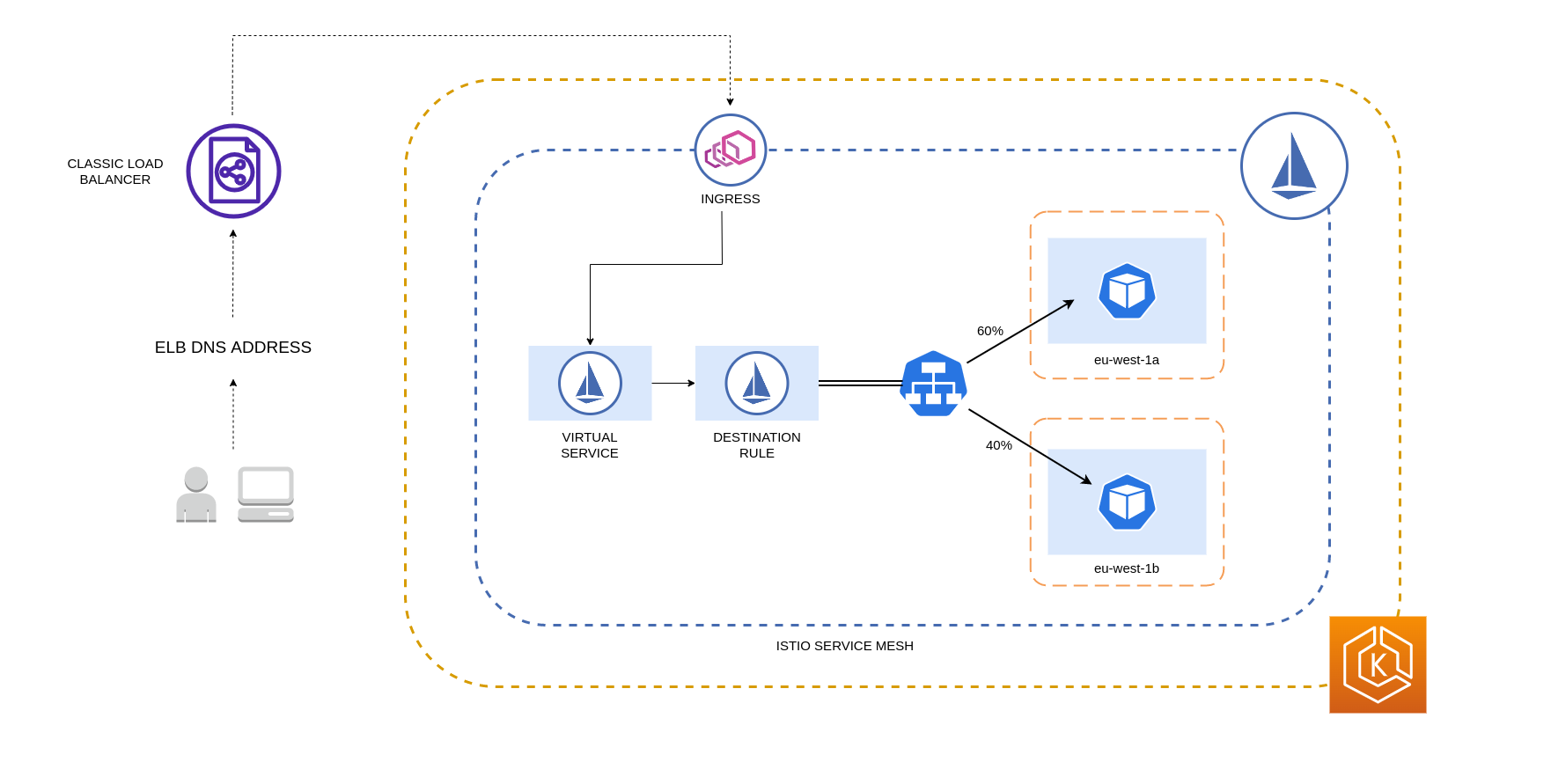
Das folgende Diagramm zeigt ein Szenario, in dem in der Region EU-West-1 ein hochverfügbarer Load-Balancer vorhanden ist und eine nach der Lokalität gewichtete Verteilung angewendet wird. Die Zielregelrichtlinie für dieses Diagramm ist so konfiguriert, dass 60% des Datenverkehrs von eu-west-1a an Pods in derselben AZ weitergeleitet werden, wohingegen 40% des Datenverkehrs von eu-west-1a an Pods in eu-west-1b gehen sollten.
Beschränkung des Datenverkehrs auf Availability Zones und Nodes
Verwenden der internen Verkehrsrichtlinie des Dienstes mit Istio
Um die Netzwerkkosten im Zusammenhang mit eingehendem externem Datenverkehr und internem Verkehr zwischen Pods zu senken, können Sie die Zielregeln von Istio und die interne Verkehrsrichtlinie des Kubernetes-Service kombinieren. Die Art und Weise, wie die Zielregeln von Istio mit der internen Verkehrsrichtlinie des Dienstes kombiniert werden können, hängt weitgehend von drei Faktoren ab:
-
Die Rolle der Microservices
-
Muster des Netzwerkverkehrs zwischen den Microservices
-
Wie sollten die Microservices in der gesamten Kubernetes-Cluster-Topologie bereitgestellt werden
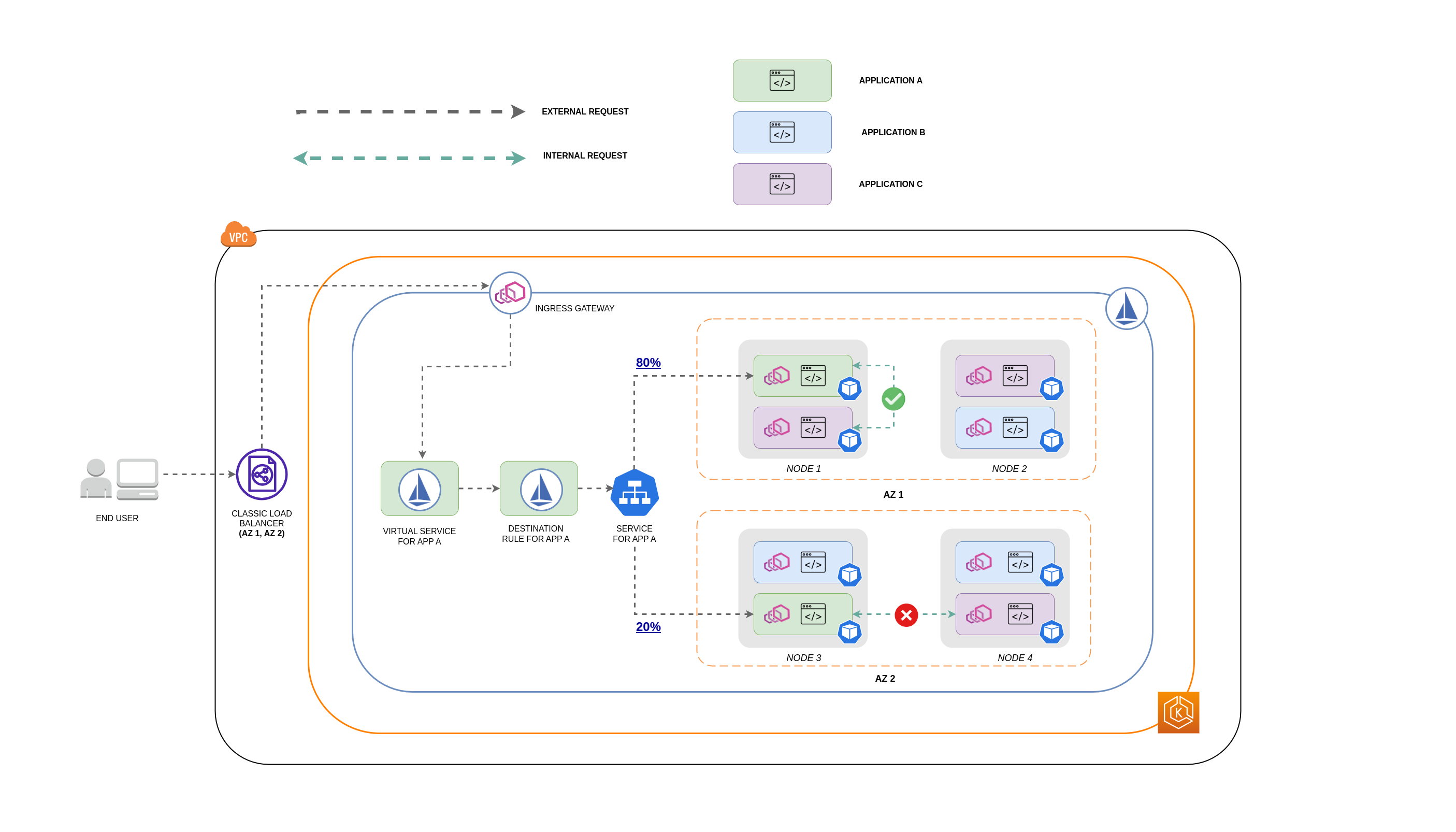
Das folgende Diagramm zeigt, wie der Netzwerkfluss im Fall einer verschachtelten Anfrage aussehen würde und wie die oben genannten Richtlinien den Datenverkehr steuern würden.
-
Der Endbenutzer stellt eine Anfrage an APP A, die wiederum eine verschachtelte Anfrage an APP C sendet. Diese Anfrage wird zunächst an einen hochverfügbaren Load Balancer gesendet, der über Instanzen in AZ 1 und AZ 2 verfügt, wie das obige Diagramm zeigt.
-
Die externe eingehende Anfrage wird dann vom Istio Virtual Service an das richtige Ziel weitergeleitet.
-
Nachdem die Anfrage weitergeleitet wurde, steuert die Istio-Zielregel, wie viel Verkehr an das jeweilige Objekt weitergeleitet wird, AZs je nachdem, woher er stammt (AZ 1 oder AZ 2).
-
Der Datenverkehr geht dann an den Service für APP A und wird dann per Proxy an die jeweiligen Pod-Endpunkte weitergeleitet. Wie im Diagramm dargestellt, werden 80% des eingehenden Datenverkehrs an Pod-Endpunkte in AZ 1 und 20% des eingehenden Datenverkehrs an AZ 2 gesendet.
-
APP A stellt dann eine interne Anfrage an APP C. Für den Dienst von APP C ist eine interne Verkehrsrichtlinie aktiviert (
internalTrafficPolicy`: Lokal`). -
Die interne Anfrage von APP A (auf KNOTEN 1) an APP C ist erfolgreich, da der knotenlokale Endpunkt für APP C verfügbar ist.
-
Die interne Anfrage von APP A (auf KNOTEN 3) an APP C schlägt fehl, da keine knotenlokalen Endpunkte für APP C verfügbar sind. Wie das Diagramm zeigt, hat APP C keine Replikate auf NODE 3. *
Die folgenden Screenshots wurden anhand eines Live-Beispiels für diesen Ansatz aufgenommen. Die ersten Screenshots zeigen eine erfolgreiche externe Anfrage an einen graphql und eine erfolgreiche verschachtelte Anfrage von der graphql an ein orders Replikat auf dem Knoten. ip-10-0-0-151.af-south-1.compute.internal
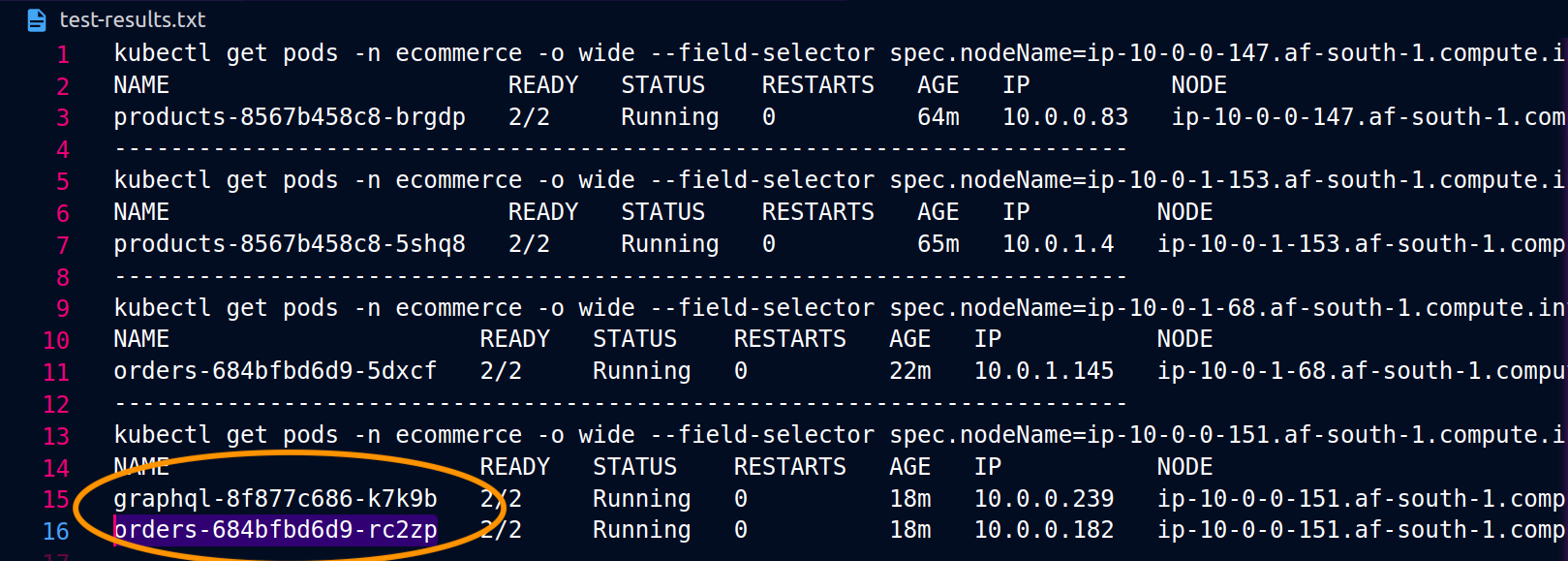
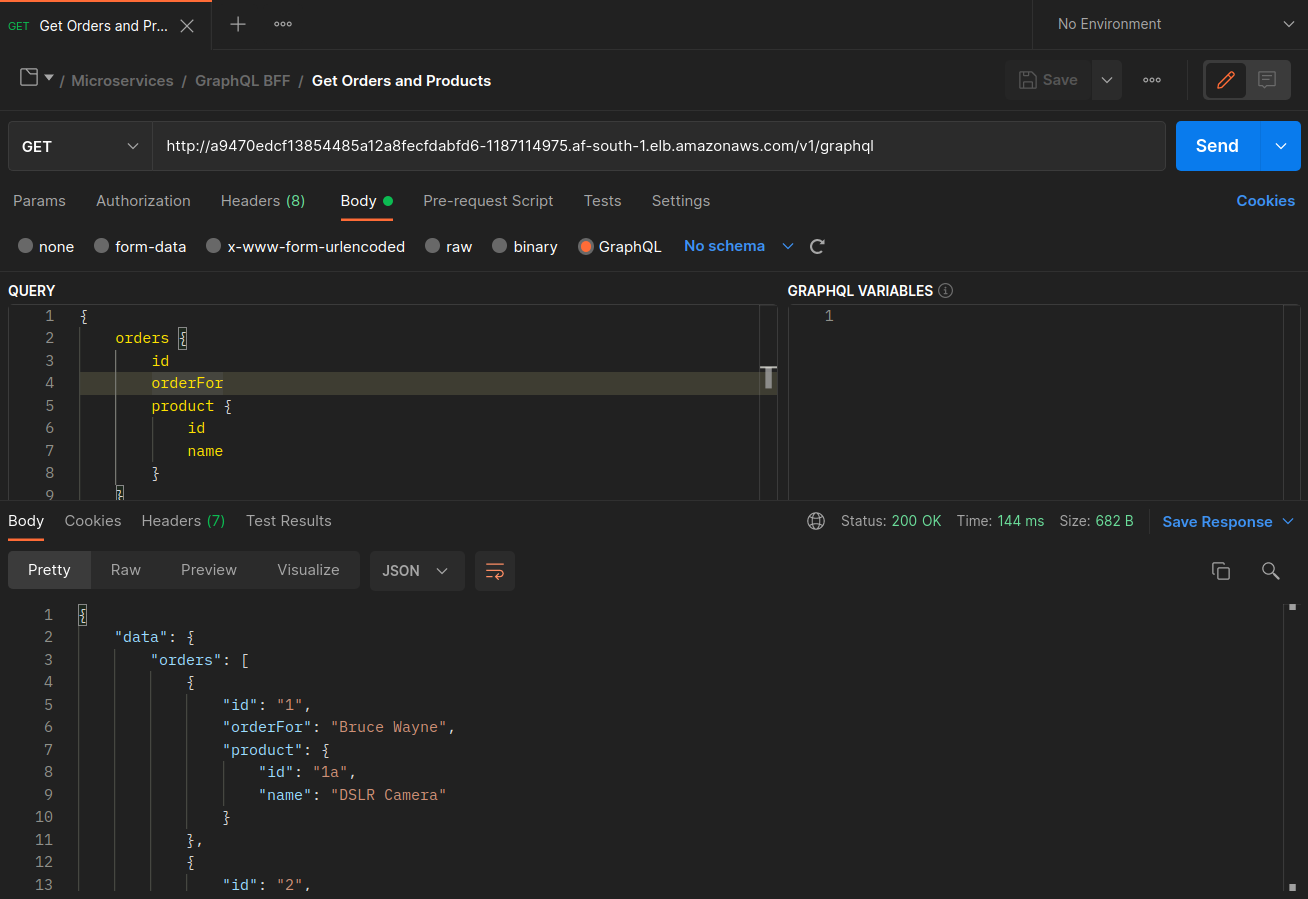
Mit Istio können Sie die Statistiken aller [Upstream-Cluster] überprüfen und exportieren (https://www.envoyproxy. io/docs/envoy/latest/intro/arch_overview/intro/terminologyorders Endpunkte, die dem graphql Proxy bekannt sind, können mit dem folgenden Befehl abgerufen werden:
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
In diesem Fall kennt der graphql Proxy nur den orders Endpunkt für das Replikat, mit dem er sich einen Knoten teilt. Wenn Sie die internalTrafficPolicy: Local Einstellung aus dem Orders Service entfernen und einen Befehl wie den obigen erneut ausführen, geben die Ergebnisse alle Endpunkte der Replikate zurück, die auf die verschiedenen Knoten verteilt sind. Wenn Sie sich die rq_total für die jeweiligen Endpunkte ansehen, werden Sie außerdem feststellen, dass die Netzwerkverteilung relativ gleichmäßig verteilt ist. Wenn die Endpunkte also mit Upstream-Diensten verknüpft sind, die in unterschiedlichen Zonen ausgeführt werden AZs, führt diese Verteilung des Netzwerks auf mehrere Zonen zu höheren Kosten.
Wie in einem vorherigen Abschnitt oben erwähnt, können Sie Pods, die häufig kommunizieren, gemeinsam platzieren, indem Sie die Pod-Affinität nutzen.
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
Wenn die orders Replikate graphql und die Replikate nicht gleichzeitig auf demselben Knoten (ip-10-0-0-151.af-south-1.compute.internal) existieren, graphql ist die erste Anfrage an erfolgreich, wie 200 response code im Postman-Screenshot unten angegeben, wohingegen die zweite verschachtelte Anfrage von an mit a fehlschlägt. graphql orders 503 response code
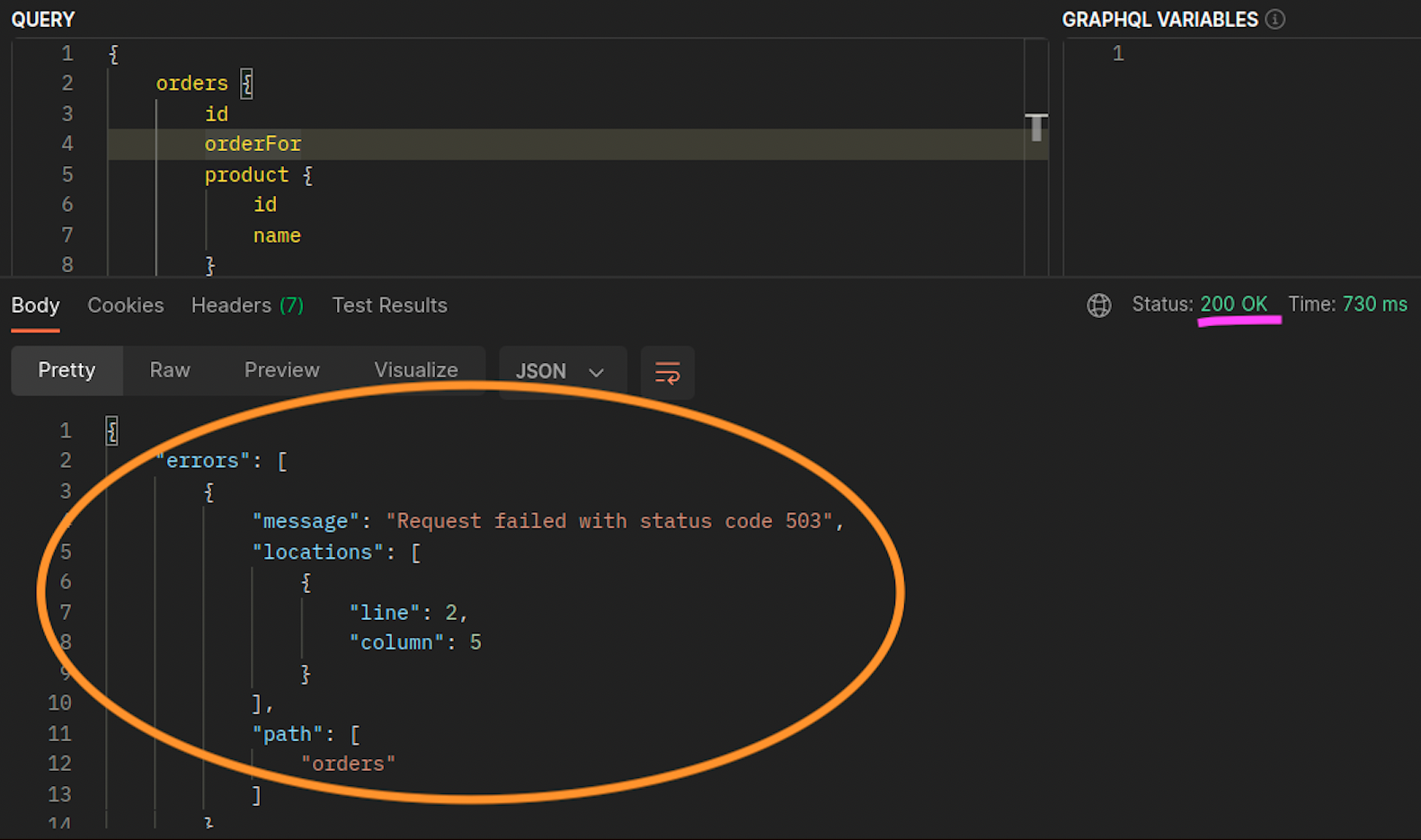
Weitere Ressourcen
-
Behebung von Latenz- und Datenübertragungskosten auf EKS mithilfe von Istio
-
Erhalten Sie Einblick in Ihre AZ-übergreifenden Pod-zu-Pod-Netzwerk-Bytes in Amazon EKS
-
Optimieren Sie den AZ-Verkehr mit topologiebewusstem Routing
-
Optimieren Sie die Kosten und Leistung von Kubernetes mit Istio und Service Internal Traffic Policy
-
Überblick über die Datenübertragungskosten für gängige Architekturen
-
Grundlegendes zu den Datenübertragungskosten für AWS-Container-Services
