Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erste Schritte mit Amazon EMR auf EKS
Dieses Thema hilft Ihnen bei den ersten Schritten mit Amazon EMR in EKS, indem Sie eine Spark-Anwendung auf einem virtuellen Cluster bereitstellen. Es umfasst Schritte zum Einrichten der richtigen Berechtigungen und zum Starten eines Jobs. Bevor Sie beginnen, sollten Sie sicherstellen, dass Sie die in Einrichten von Amazon EMR in EKS beschriebenen Schritte ausgeführt haben. Auf diese Weise erhalten Sie Tools wie das AWS CLI Setup vor der Erstellung Ihres virtuellen Clusters. Weitere Vorlagen, die Ihnen den Einstieg erleichtern können, finden Sie in unserem EMR Containers Best Practices Guide
Sie benötigen die folgenden Informationen aus den Einrichtungsschritten:
-
Virtuelle Cluster-ID für den Amazon-EKS-Cluster und den Kubernetes-Namespace, die bei Amazon EMR registriert sind
Wichtig
Achten Sie beim Erstellen eines EKS-Clusters darauf, m5.xlarge als Instance-Typ oder einen anderen Instance-Typ mit einer höheren CPU und einem höheren Arbeitsspeicher zu verwenden. Die Verwendung eines Instance-Typs mit weniger CPU oder Arbeitsspeicher als m5.xlarge kann aufgrund unzureichender verfügbarer Ressourcen im Cluster zu einem Auftragsfehler führen.
-
Name der IAM-Rolle, die für die Auftragsausführung verwendet wird
-
Release-Label für die Amazon-EMR-Version (z. B.
emr-6.4.0-latest) -
Zielziele für die Protokollierung und Überwachung:
-
CloudWatch Amazon-Protokollgruppenname und Logstream-Präfix
-
Amazon-S3-Standort zum Speichern von Ereignis- und Containerprotokollen
-
Wichtig
Amazon EMR on EKS-Jobs verwenden Amazon CloudWatch und Amazon S3 als Zielziele für die Überwachung und Protokollierung. Sie können den Aufgabenfortschritt überwachen und Fehler beheben, indem Sie sich die an diese Ziele gesendeten Aufgabenprotokolle ansehen. Um die Protokollierung zu aktivieren, muss die IAM-Richtlinie, die der IAM-Rolle für die Aufgabenausführung zugeordnet ist, über die erforderlichen Berechtigungen für den Zugriff auf die Zielressourcen verfügen. Wenn die IAM-Richtlinie nicht über die erforderlichen Berechtigungen verfügt, müssen Sie die unter Konfiguration einer Auftragsausführung zur Verwendung von Amazon S3 S3-Protokollen und Konfiguration einer Auftragsausführung zur Verwendung von CloudWatch Protokollen beschriebenen Schritte ausführen, bevor Sie diesen Beispielauftrag ausführen. Die Vertrauensrichtlinie der Auftragsausführungsrolle aktualisieren
Eine Spark-Anwendung ausführen
Führen Sie die folgenden Schritte aus, um eine einfache Spark-Anwendung bei Amazon EMR in EKS auszuführen. Die entryPoint-Anwendungsdatei für eine Spark-Python-Anwendung befindet sich unter s3://. Das REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.pyREGION ist die Region, in der sich Ihr virtueller Amazon EMR on EKS-Cluster befindet, z. B. us-east-1
-
Aktualisieren Sie die IAM-Richtlinie für die Auftragausführungsrolle mit den erforderlichen Berechtigungen, wie die folgenden Richtlinienerklärungen zeigen.
-
Die erste Anweisung
ReadFromLoggingAndInputScriptBucketsin dieser Richtlinie gewährtListBucketundGetObjectsZugriff auf die folgenden Amazon-S3-Buckets:-
REGION.elasticmapreduceentryPointAnwendungsdatei befindet. -
amzn-s3-demo-destination-bucket‐ ein Bucket, das Sie für Ihre Ausgabedaten definieren. -
amzn-s3-demo-logging-bucket‐ ein Bucket, das Sie für Ihre Logging-Daten definieren.
-
-
Die zweite Anweisung
WriteToLoggingAndOutputDataBucketsin dieser Richtlinie erteilt dem Auftrag die Erlaubnis, Daten in Ihre Ausgabe- bzw. Protokollierungs-Buckets zu schreiben. -
Die dritte Anweisung
DescribeAndCreateCloudwatchLogStreamerteilt dem Job die Erlaubnis, Amazon CloudWatch Logs zu beschreiben und zu erstellen. -
Die vierte Anweisung
WriteToCloudwatchLogsgewährt Berechtigungen zum Schreiben von Protokollen in eine CloudWatch Amazon-Protokollgruppe, diemy_log_group_namemy_log_stream_prefix
-
-
Verwenden Sie den folgenden Befehl, um eine Spark-Python-Anwendung auszuführen. Ersetzen Sie alle ersetzbaren
red italicizedWerte durch entsprechende Werte. DasREGIONist die Region, in der sich Ihr virtueller Amazon EMR on EKS-Cluster befindet, z. B.us-east-1aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.4.0-latest\ --job-driver '{ "sparkSubmitJobDriver": { "entryPoint": "s3://REGION.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.py", "entryPointArguments": ["s3://amzn-s3-demo-destination-bucket/wordcount_output"], "sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'Die Ausgabedaten dieses Aufträge sind unter
s3://verfügbar.amzn-s3-demo-destination-bucket/wordcount_outputSie können auch eine JSON-Datei mit bestimmten Parametern für Ihre Auftragsausführung erstellen. Führen Sie dann den
start-job-run-Befehl mit dem Pfad zur JSON-Datei aus. Weitere Informationen finden Sie unter Reichen Sie einen Auftrag ein, der ausgeführt wird mit StartJobRun. Weitere Informationen zur Konfiguration von Auftrag-Ausführungsparametern finden Sie unter Optionen für die Konfiguration einer Aufgabenausführung. -
Verwenden Sie den folgenden Befehl, um eine Spark-SQL-Anwendung auszuführen. Ersetzen Sie alle
red italicizedWerte durch entsprechende Werte. DasREGIONist die Region, in der sich Ihr virtueller Amazon EMR on EKS-Cluster befindet, z. B.us-east-1aws emr-containers start-job-run \ --virtual-cluster-idcluster_id\ --namesample-job-name\ --execution-role-arnexecution-role-arn\ --release-labelemr-6.7.0-latest\ --job-driver '{ "sparkSqlJobDriver": { "entryPoint": "s3://query-file.sql", "sparkSqlParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=2G --conf spark.executor.cores=2 --conf spark.driver.cores=1" } }' \ --configuration-overrides '{ "monitoringConfiguration": { "cloudWatchMonitoringConfiguration": { "logGroupName": "my_log_group_name", "logStreamNamePrefix": "my_log_stream_prefix" }, "s3MonitoringConfiguration": { "logUri": "s3://amzn-s3-demo-logging-bucket" } } }'Eine Beispiel-SQL-Abfragedatei ist unten dargestellt. Sie benötigen einen externen Dateispeicher wie S3, in dem die Daten für die Tabellen gespeichert werden.
CREATE DATABASE demo; CREATE EXTERNAL TABLE IF NOT EXISTS demo.amazonreview( marketplace string, customer_id string, review_id string, product_id string, product_parent string, product_title string, star_rating integer, helpful_votes integer, total_votes integer, vine string, verified_purchase string, review_headline string, review_body string, review_date date, year integer) STORED AS PARQUET LOCATION 's3://URI to parquet files'; SELECT count(*) FROM demo.amazonreview; SELECT count(*) FROM demo.amazonreview WHERE star_rating = 3;Die Ausgabe für diesen Job ist in den Standardprotokollen des Treibers in S3 oder CloudWatch, je nachdem, was konfiguriert ist, verfügbar.
monitoringConfiguration -
Sie können auch eine JSON-Datei mit bestimmten Parametern für Ihre Auftragsausführung erstellen. Führen Sie dann den start-job-run-Befehl mit dem Pfad zur JSON-Datei aus. Weitere Informationen finden Sie unter Ausführen einer Auftragsausführung. Weitere Informationen zur Konfiguration von Auftrag-Ausführungsparametern finden Sie unter Optionen für die Konfiguration einer Auftragsausführung.
Um den Fortschritt des Jobs zu überwachen oder Fehler zu debuggen, können Sie die in Amazon S3 hochgeladenen CloudWatch Protokolle, Logs oder beides überprüfen. Weitere Informationen zum Protokollpfad in Amazon S3 finden Sie unter Auftragsausführung für die Verwendung von S3-Protokollen konfigurieren und Cloudwatch-Protokolle unter Auftragsausführung für die Verwendung von CloudWatch Protokollen konfigurieren. Folgen Sie den nachstehenden Anweisungen, um CloudWatch Protokolle in Logs zu sehen.
-
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. -
Wählen Sie im Navigationsbereich Protokolle aus. Wählen Sie dann die Protokollgruppen aus.
-
Wählen Sie die Protokollgruppe für Amazon EMR in EKS aus und sehen Sie sich dann die hochgeladenen Protokollereignisse an.
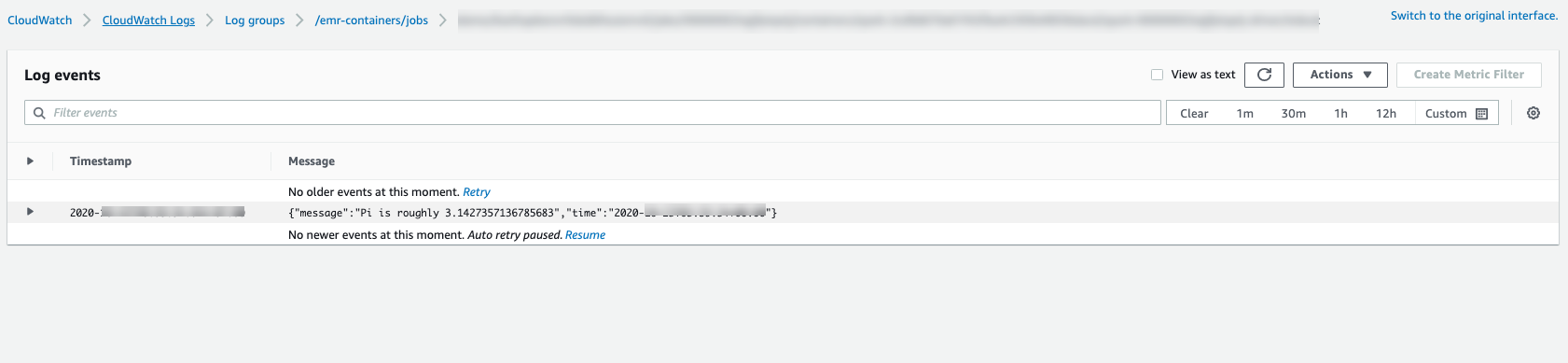
-
Wichtig
Aufträge haben eine Standardkonfigurierte Wiederholungsrichtlinie. Informationen zum Ändern oder Deaktivieren der Konfiguration finden Sie unter Richtlinien zur Aufgabenwiederholung verwenden.
