Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfiguration von Flink in Amazon EMR
Konfigurieren Sie Flink mit Hive Metastore und Glue Catalog
Amazon EMR-Versionen 6.9.0 und höher unterstützen sowohl Hive Metastore als auch AWS Glue Catalog mit dem Apache Flink-Connector zu Hive. In diesem Abschnitt werden die Schritte beschrieben, die zur Konfiguration von AWS Glue Catalog und Hive Metastore mit Flink erforderlich sind.
Verwenden Sie den Hive Metastore
-
Erstellen Sie einen EMR-Cluster mit Version 6.9.0 oder höher und mindestens zwei Anwendungen: Hive und Flink.
-
Verwenden Sie Script Runner, um das folgende Skript als Schrittfunktion auszuführen:
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar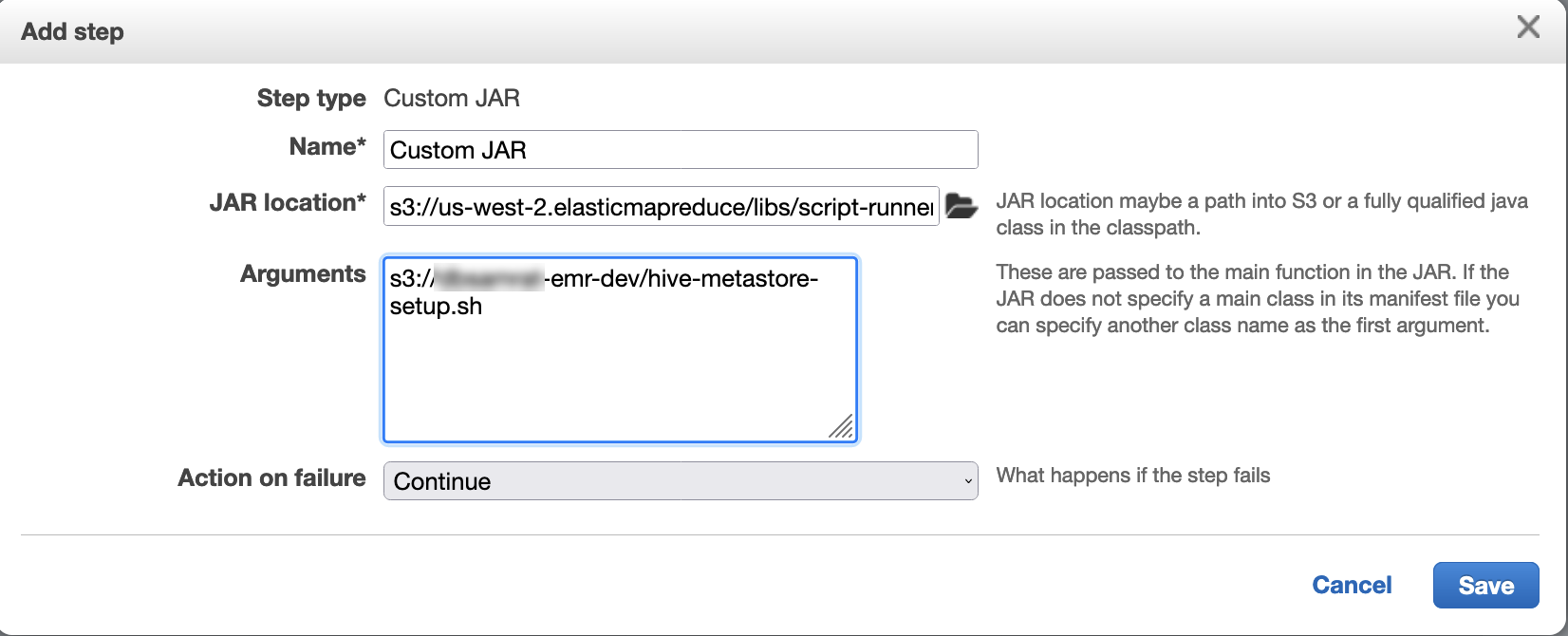
Verwenden Sie den AWS Glue-Datenkatalog
-
Erstellen Sie einen EMR-Cluster mit Version 6.9.0 oder höher und mindestens zwei Anwendungen: Hive und Flink.
-
Wählen Sie in den Einstellungen des AWS Glue Data Catalogs die Option Für Hive-Tabellenmetadaten verwenden aus, um den Data Catalog im Cluster zu aktivieren.
-
Verwenden Sie Script-Runner, um das folgende Skript als Schrittfunktion auszuführen: Befehle und Skripts auf einem Amazon-EMR-Cluster ausführen:
glue-catalog-setup.sh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
Konfigurieren Sie Flink mit einer Konfigurationsdatei
Sie können die Amazon-EMR-Konfigurations-API verwenden, um Flink mit einer Konfigurationsdatei zu konfigurieren. Folgende Dateien sind in der API konfigurierbar:
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
Die Hauptkonfigurationsdatei für Flink heißt flink-conf.yaml.
So konfigurieren Sie die Anzahl der Aufgaben-Slots für Flink mithilfe der AWS CLI
-
Erstellen Sie eine Datei,
configurations.json, mit folgendem Inhalt:[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
Im nächsten Schritt erstellen Sie einen Cluster mit der folgenden Konfiguration:
aws emr create-cluster --release-labelemr-7.10.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
Anmerkung
Sie können einige Konfigurationen auch mit der Flink-API ändern. Weitere Informationen finden Sie unter Konzepte
Ab Amazon-EMR-Version 5.21.0 können Sie Cluster-Konfigurationen überschreiben und zusätzliche Konfigurationsklassifikationen für jede Instance-Gruppe in einem ausgeführten Cluster angeben. Dazu verwenden Sie die Amazon EMR-Konsole, das AWS Command Line Interface (AWS CLI) oder das AWS SDK. Weitere Informationen finden Sie unter Angeben einer Konfiguration für eine Instance-Gruppe in einem aktiven Cluster.
Parallelitätsoptionen
Als Eigentümer Ihrer Anwendung wissen Sie am besten, welche Ressourcen Aufgaben innerhalb von Flink zugewiesen werden müssen. Für Beispiele in dieser Dokumentation verwenden Sie die gleiche Anzahl von Aufgaben wie die Aufgaben-Instances, die Sie für die Anwendung nutzen. Wir empfehlen diese Vorgehensweise generell für die anfängliche Parallelität. Sie können jedoch die Granularität der Parallelität mithilfe von Aufgaben-Slots erhöhen. Dabei sollte die Anzahl von virtuellen Cores
Konfigurieren von Flink auf einem EMR-Cluster mit mehreren Primärknoten
Der JobManager von Flink bleibt während des Failover-Prozesses für den primären Knoten in einem Amazon EMR-Cluster mit mehreren Primärknoten verfügbar. Ab Amazon EMR 5.28.0 wird JobManager Hochverfügbarkeit auch automatisch aktiviert. Es ist keine manuelle Konfiguration erforderlich.
Bei Amazon EMR-Versionen 5.27.0 oder früher JobManager handelt es sich um einen einzigen Fehlerpunkt. Wenn der JobManager fehlschlägt, gehen alle Job-Status verloren und die laufenden Jobs werden nicht wieder aufgenommen. Sie können JobManager Hochverfügbarkeit aktivieren, indem Sie die Anzahl der Anwendungsversuche, das Checkpointing und die Aktivierung ZooKeeper als Statusspeicher für Flink konfigurieren, wie das folgende Beispiel zeigt:
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
Sie müssen sowohl die maximalen Anwendungsmasterversuche für YARN als auch die maximalen Anwendungsversuche für Flink konfigurieren. Weitere Informationen finden Sie unter Konfiguration der Hochverfügbarkeit des YARN-Clusters
Konfiguration der Größe des Speicherprozesses
Für Amazon EMR-Versionen, die Flink 1.11.x verwenden, müssen Sie die Gesamtspeicherprozessgröße sowohl für () als auch für JobManager (jobmanager.memory.process.size) in konfigurieren. TaskManager taskmanager.memory.process.size flink-conf.yaml Sie können diese Werte festlegen, indem Sie entweder den Cluster mit der Konfigurations-API konfigurieren oder diese Felder manuell über SSH auskommentieren. Flink bietet die folgenden Standardwerte.
-
jobmanager.memory.process.size: 1 600 m -
taskmanager.memory.process.size: 1 728 m
Um JVM-Metaspace und Overhead auszuschließen, verwenden Sie die gesamte Flink-Speichergröße (taskmanager.memory.flink.size) anstelle von taskmanager.memory.process.size. Der Standardwert von taskmanager.memory.process.size beträgt 1 280 m. Es wird nicht empfohlen, sowohl taskmanager.memory.process.size als auch taskmanager.memory.process.size zu setzen.
Alle Amazon-EMR-Versionen, die Flink 1.12.0 und höher verwenden, haben die im Open-Source-Set für Flink aufgeführten Standardwerte als Standardwerte für Amazon EMR, sodass Sie sie nicht selbst konfigurieren müssen.
Größe der Protokollausgabedatei konfigurieren
Flink-Anwendungscontainer erstellen drei Arten von Protokolldateien und schreiben in sie: .out-Dateien, .log-Dateien und .err-Dateien. Nur .err-Dateien werden komprimiert und aus dem Dateisystem entfernt, während .log- und .out-Protokolldateien im Dateisystem verbleiben. Um sicherzustellen, dass diese Ausgabedateien verwaltbar bleiben und der Cluster stabil bleibt, können Sie die Protokollrotation in log4j.properties so konfigurieren, dass eine maximale Anzahl von Dateien festgelegt und deren Größe begrenzt wird.
Amazon EMR 5.30.0 und höher
Ab Amazon EMR 5.30.0 verwendet Flink das Logging-Framework log4j2 mit dem Namen der Konfigurationsklassifikation flink-log4j.. Die folgende Beispielkonfiguration demonstriert das log4j2-Format.
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon-EMR-Versionen 5.29.0 und früher
Mit den Amazon-EMR-Versionen 5.29.0 und früher verwendet Flink das Logging-Framework log4j. Die folgende Beispielkonfiguration veranschaulicht das log4j Format.
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
Flink für die Ausführung mit Java 11 konfigurieren
Amazon-EMR-Versionen 6.12.0 und höher bieten Java-11-Laufzeitunterstützung für Flink. In den folgenden Abschnitten wird beschrieben, wie der Cluster so konfiguriert wird, dass er Java-11-Laufzeitunterstützung für Flink bereitstellt.
Themen
Konfigurieren Sie Flink für Java 11, wenn Sie einen Cluster erstellen
Führen Sie die folgenden Schritte aus, um einen EMR-Cluster mit Flink und Java-11-Laufzeit zu erstellen. Die Konfigurationsdatei, in der Sie die Java-11-Laufzeitunterstützung hinzufügen, befindet sich. flink-conf.yaml
Flink für Java 11 auf einem laufenden Cluster konfigurieren
Gehen Sie wie folgt vor, um einen laufenden EMR-Cluster mit Flink und Java 11-Laufzeit zu aktualisieren. Die Konfigurationsdatei, in der Sie die Java-11-Laufzeitunterstützung hinzufügen, befindet sich. flink-conf.yaml
Bestätigen Sie die Java-Laufzeit für Flink auf einem laufenden Cluster
Um die Java-Laufzeit für einen laufenden Cluster zu ermitteln, melden Sie sich mit SSH beim Primärknoten an, wie unter Mit SSH mit dem Primärknoten verbinden beschrieben. Führen Sie anschließend den folgenden Befehl aus:
ps -ef | grep flink
Der ps-Befehl mit der -ef-Option listet alle laufenden Prozesse auf dem System auf. Sie können diese Ausgabe mit grep filtern, um Erwähnungen der Zeichenfolge flink zu finden. Überprüfen Sie die Ausgabe für den Java-Laufzeitumgebung (JRE)-Wert, jre-XX. In der folgenden Ausgabe wird jre-11 angegeben, dass Java 11 zur Laufzeit von Flink abgerufen wird.
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
Alternativ können Sie sich mit SSH am Primärknoten anmelden und eine Flink YARN-Sitzung mit dem Befehl flink-yarn-session -d starten. Die Ausgabe zeigt die Java Virtual Machine (JVM) für Flink, java-11-amazon-corretto im folgenden Beispiel:
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64
