Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Was ist Amazon Data Firehose?
Amazon Data Firehose ist ein vollständig verwalteter Service für die Bereitstellung von Echtzeit-Streaming-Daten
Weitere Informationen zu AWS Big-Data-Lösungen finden Sie unter Big Data auf AWS
Lernen Sie die wichtigsten Konzepte kennen
Wenn Sie mit Amazon Data Firehose beginnen, können Sie davon profitieren, die folgenden Konzepte zu verstehen.
- Firehose-Stream
-
Die zugrunde liegende Einheit von Amazon Data Firehose. Sie verwenden Amazon Data Firehose, indem Sie einen Firehose-Stream erstellen und dann Daten an ihn senden. Weitere Informationen erhalten Sie unter Tutorial: Einen Firehose-Stream von der Konsole aus erstellen und Daten an einen Firehose-Stream senden.
- Aufzeichnen
-
Die interessanten Daten, die Ihr Datenproduzent an einen Firehose-Stream sendet. Ein Datensatz kann bis zu 1000 KB groß sein.
- Datenproduzent
-
Produzenten senden Platten an Firehose-Streams. Beispielsweise ist ein Webserver, der Protokolldaten an einen Firehose-Stream sendet, ein Datenproduzent. Sie können Ihren Firehose-Stream auch so konfigurieren, dass er automatisch Daten aus einem vorhandenen Kinesis-Datenstream liest und in Ziele lädt. Weitere Informationen finden Sie unter Daten an einen Firehose-Stream senden.
- Puffergröße und Pufferintervall
-
Amazon Data Firehose puffert eingehende Streaming-Daten auf eine bestimmte Größe oder für einen bestimmten Zeitraum, bevor sie an Ziele gesendet werden. Buffer Sizeist drin MBs und Buffer Interval ist in Sekunden.
Den Datenfluss in Amazon Data Firehose verstehen
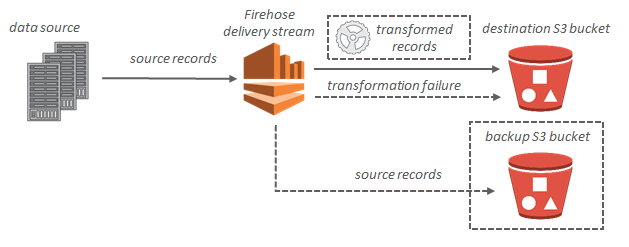
Für Amazon-S3-Ziele werden die Streaming-Daten in Ihren S3-Bucket geleitet. Wenn die Datentransformation aktiviert ist, können Sie optional Quelldaten in einem anderen Amazon-S3-Bucket sichern.
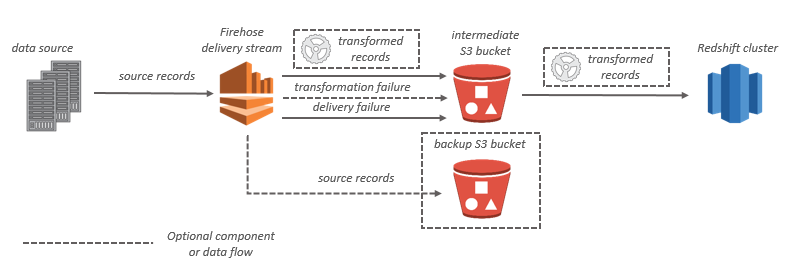
Für Amazon-Redshift-Ziele werden die Streaming-Daten zuerst in Ihren S3-Bucket geleitet. Amazon Data Firehose gibt dann einen Amazon Redshift COPY Redshift-Befehl aus, um Daten aus Ihrem S3-Bucket in Ihren Amazon Redshift Redshift-Cluster zu laden. Wenn die Datentransformation aktiviert ist, können Sie optional Quelldaten in einem anderen Amazon-S3-Bucket sichern.
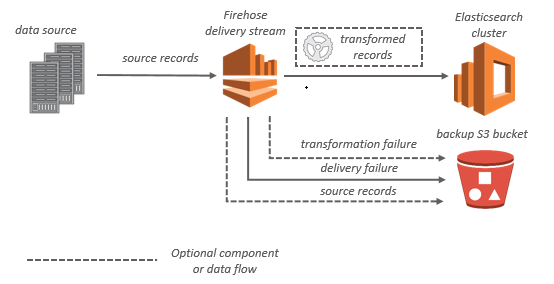
Bei OpenSearch Servicezielen werden Streaming-Daten an Ihren OpenSearch Service-Cluster übermittelt und können optional gleichzeitig in Ihrem S3-Bucket gesichert werden.
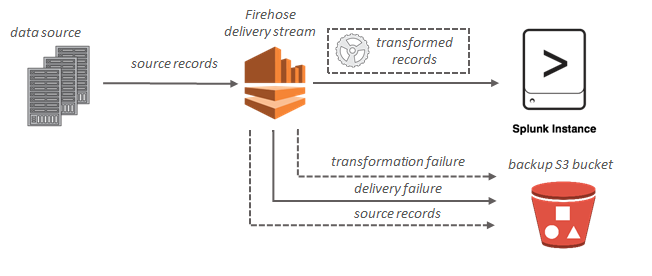
Für Splunk-Ziele werden die Streaming-Daten an Splunk gesendet und können gleichzeitig optional in Ihrem S3-Bucket gesichert werden.