Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: Schreiben eines ETL-Skripts in AWS Glue für Ray
Mit Ray können Sie verteilte Aufgaben nativ in Python schreiben und skalieren. AWS Glue für Ray bietet Serverless Ray-Umgebungen, auf die Sie sowohl über Aufträge als auch über interaktive Sitzungen zugreifen können (interaktive Ray-Sitzungen befinden sich in der Vorversion). Das AWS Glue-Auftragssystem bietet eine einheitliche Möglichkeit, Ihre Aufgaben zu verwalten und auszuführen – nach einem Zeitplan, über einen Auslöser oder über die AWS Glue-Konsole.
Durch die Kombination dieser AWS Glue-Tools entsteht eine leistungsstarke Toolchain, die Sie zum Extract, Transform, Load (ETL) von Workloads verwenden können, einem beliebten Anwendungsfall für AWS Glue. In diesem Tutorial lernen Sie die Grundlagen für die Zusammenstellung dieser Lösung.
Wir unterstützen auch die Verwendung von AWS Glue für Spark für Ihre ETL-Workloads. Eine Anleitung zum Schreiben eines AWS Glue für Spark-Skripts finden Sie unter Tutorial: Ein AWS Glue for Spark-Skript schreiben. Weitere Informationen zu verfügbaren Engines finden Sie unter AWS Glue für Spark und AWS Glue für Ray. Ray ist in der Lage, viele verschiedene Aufgaben in den Bereichen Analytik, Machine Learning (ML) und Anwendungsentwicklung zu bewältigen.
In diesem Tutorial extrahieren, transformieren und laden Sie einen CSV-Datensatz, der in Amazon Simple Storage Service (Amazon S3) gehostet wird. Sie beginnen mit dem Datensatz zu Reiseaufzeichnungsdaten der New York City Taxi and Limousine Commission (TLC), der in einem öffentlichen Amazon-S3-Bucket gespeichert ist. Weitere Informationen zu diesem Datensatz finden Sie im Registry der offenen Daten in AWS
Sie transformieren Ihre Daten mit vordefinierten Transformationen, die in der Ray Data-Bibliothek verfügbar sind. Ray Data ist eine von Ray entwickelte Bibliothek zur Datensatzvorbereitung, die standardmäßig in AWS Glue-für-Ray-Umgebungen enthalten ist. Weitere Informationen zu den standardmäßig enthaltenen Bibliotheken finden Sie unter Mit Ray-Aufträgen bereitgestellte Module. Anschließend schreiben Sie Ihre transformierten Daten in einen von Ihnen kontrollierten Amazon-S3-Bucket.
Voraussetzungen – Für dieses Tutorial benötigen Sie ein AWS-Konto mit Zugriff auf AWS Glue und Amazon S3.
Schritt 1: Erstellen eines Buckets in Amazon S3 zur Speicherung Ihrer Ausgabedaten
Sie benötigen einen Amazon-S3-Bucket, den Sie steuern und der als Senke für die in diesem Tutorial erstellten Daten dient. Sie können diesen Bucket mit dem folgenden Verfahren erstellen.
Anmerkung
Wenn Sie Ihre Daten in einen vorhandenen, von Ihnen kontrollierten Bucket schreiben möchten, können Sie diesen Schritt überspringen. Notieren Sie sich yourBucketName, den Namen des vorhandenen Buckets, um ihn in späteren Schritten zu verwenden.
So erstellen Sie einen Bucket für die Ausgabe Ihres Ray-Auftrags
-
Erstellen Sie einen Bucket, indem Sie die Schritte unter Erstellen eines Buckets im Amazon-S3-Benutzerhandbuch befolgen.
-
Notieren Sie sich bei der Auswahl eines Bucket-Namens
YourBucketName, auf den Sie sich in späteren Schritten beziehen werden. -
Für andere Konfigurationen sollten die in der Amazon-S3-Konsole vorgeschlagenen Einstellungen in diesem Tutorial gut funktionieren.
Beispielsweise könnte das Dialogfeld zur Bucket-Erstellung in der Amazon-S3-Konsole so aussehen.
-
Schritt 2: Erstellen einer IAM-Rolle und -Richtlinie für Ihren Ray-Auftrag
Für Ihren Auftrag benötigen Sie eine AWS Identity and Access Management (IAM)-Rolle mit den folgenden Anforderungen:
-
Durch die
AWSGlueServiceRole-verwalteten Richtlinie gewährte Berechtigungen. Dies sind die grundlegenden Berechtigungen, die zum Ausführen eines AWS Glue-Auftrags erforderlich sind. -
Read-Zugriffsebenenberechtigungen für dienyc-tlc/*-Amazon-S3-Ressource. -
Write-Zugriffsebenenberechtigungen für dieyourBucketName/* -
Eine Vertrauensbeziehung, die es dem
glue.amazonaws.com-Prinzipal ermöglicht, die Rolle zu übernehmen.
Sie können diese Rolle mit dem folgenden Verfahren erstellen.
So erstellen Sie eine IAM-Rolle für Ihren AWS Glue-für-Ray-Auftrag
Anmerkung
Sie können eine IAM-Rolle erstellen, indem Sie viele verschiedene Verfahren befolgen. Weitere Informationen oder Optionen zum Bereitstellen von IAM-Ressourcen finden Sie in der AWS Identity and Access Management-Dokumentation.
-
Erstellen Sie eine Richtlinie, die die zuvor beschriebenen Amazon S3-Berechtigungen definiert, indem Sie die Schritte unter Erstellen von IAM-Richtlinien (Konsole) mit dem visuellen Editor im IAM-Benutzerhandbuch ausführen.
-
Wählen Sie bei der Auswahl eines Services Amazon S3.
-
Fügen Sie bei der Auswahl von Berechtigungen für Ihre Richtlinie die folgenden Aktionssätze für die folgenden Ressourcen hinzu (zuvor erwähnt):
-
Lesezugriffsebenenberechtigungen für die
nyc-tlc/*-Amazon-S3-Ressource. -
Schreibzugriffsebenenberechtigungen für die
yourBucketName/*
-
-
Notieren Sie sich bei der Auswahl des Richtliniennamens
YourPolicyName, auf den Sie sich in einem späteren Schritt beziehen werden.
-
-
Erstellen Sie eine Rolle für Ihren AWS Glue-für-Ray-Auftrag, indem Sie die Schritte unter Erstellen einer Rolle für einen AWS-Service (Konsole) im IAM-Benutzerhandbuch befolgen.
-
Wählen Sie bei der Auswahl einer vertrauenswürdigen AWS-Service-Entität
Glueaus. Dadurch wird automatisch die für Ihren Auftrag erforderliche Vertrauensbeziehung ausgefüllt. -
Fügen Sie bei der Auswahl von Richtlinien für die Berechtigungsrichtlinie die folgenden Richtlinien hinzu:
-
AWSGlueServiceRole -
YourPolicyName
-
-
Notieren Sie sich bei der Auswahl des Rollennamens
YourRoleName, auf den Sie sich in späteren Schritten beziehen werden.
-
Schritt 3: Erstellen und Ausführen eines AWS Glue-für-Ray-Auftrags
In diesem Schritt erstellen Sie einen AWS Glue-Auftrag mithilfe der AWS Management Console, stellen ihm ein Beispielskript zur Verfügung und führen den Auftrag aus. Wenn Sie einen Auftrag erstellen, wird in der Konsole ein Ort angelegt, an dem Sie Ihr Ray-Skript speichern, konfigurieren und bearbeiten können. Informationen zum Erstellen von Aufgaben finden Sie unter Anmeldung in AWS Glue Konsole.
In diesem Tutorial befassen wir uns mit dem folgenden ETL-Szenario: Sie möchten die Einträge von Januar 2022 des Datensatzes zu Reiseaufzeichnungen der New York City TLC lesen. Sie fügen dem Datensatz eine neue Spalte (tip_rate) hinzu, indem Sie Daten in vorhandenen Spalten kombinieren, entfernen dann eine Reihe von Spalten, die für Ihre aktuelle Analyse nicht relevant sind, und möchten dann die Ergebnisse in yourBucketName schreiben. Das folgende Ray-Skript führt diese Schritte aus:
import ray import pandas from ray import data ray.init('auto') ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv") # Add the given new column to the dataset and show the sample record after adding a new column ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"]) # Dropping few columns from the underlying Dataset ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"]) ds.write_parquet("s3://yourBucketName/ray/tutorial/output/")
So erstellen und führen Sie einen AWS Glue-für-Ray-Auftrag aus
-
Navigieren Sie in der AWS Management Console zur Startseite von AWS Glue.
-
Wählen Sie im seitlichen Navigationsbereich ETL-Aufträge aus.
-
Wählen Sie unter Auftrag erstellen die Option Ray-Skripteditor und dann Erstellen aus, wie in der folgenden Abbildung dargestellt.
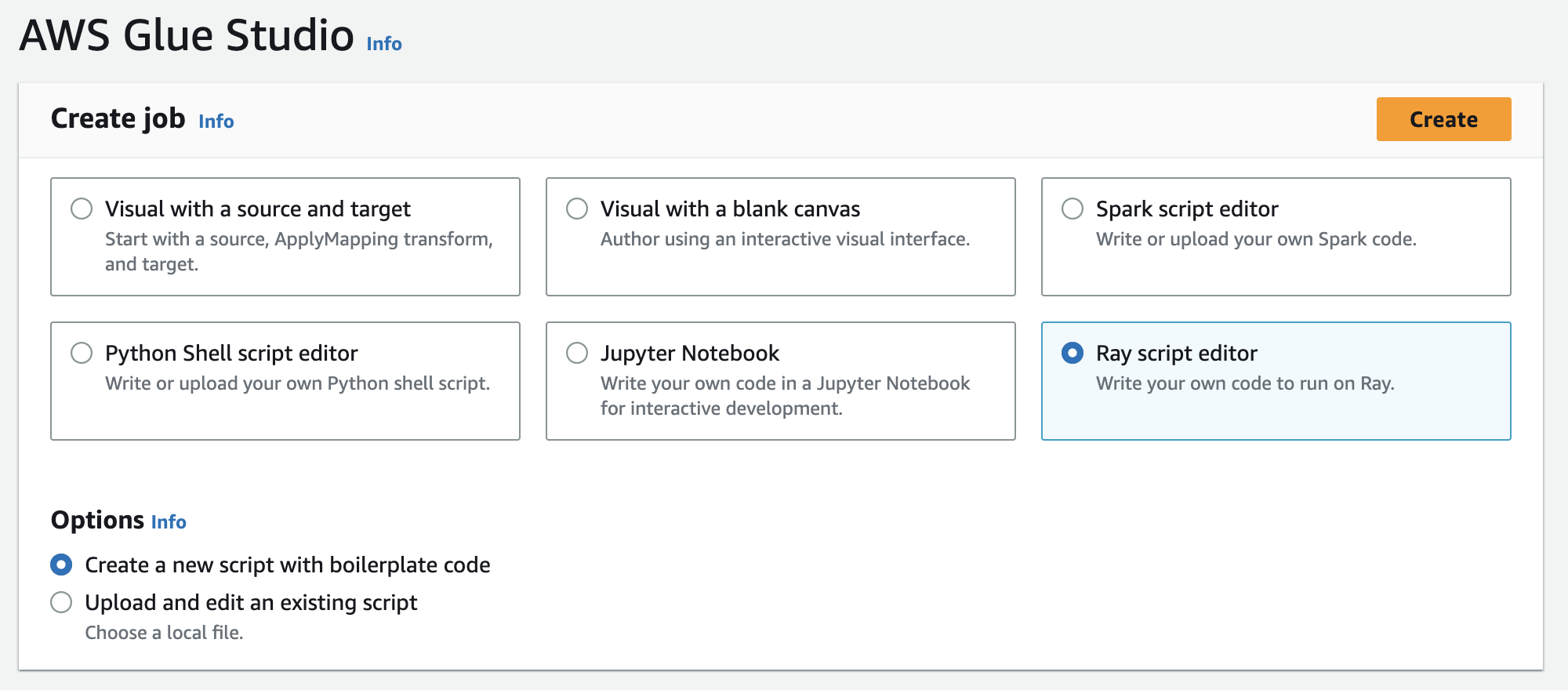
-
Fügen Sie den vollständigen Text des Skripts in den Bereich Skript ein und ersetzen Sie den vorhandenen Text.
-
Navigieren Sie zu Auftragsdetails und legen Sie die Eigenschaft IAM-Rolle auf
YourRoleNamefest. -
Wählen Sie Speichern und dann Ausführen aus.
Schritt 4: Überprüfen Ihrer Ausgabe
Nach der Ausführung Ihres AWS Glue-Auftrags sollten Sie überprüfen, ob die Ausgabe den Erwartungen dieses Szenarios entspricht. Sie können dies mit dem folgenden Verfahren tun.
So überprüfen Sie, ob Ihr Ray-Auftrag erfolgreich ausgeführt wurde
-
Navigieren Sie auf der Seite mit den Auftragsdetails zu Ausführungen.
-
Nach ein paar Minuten sollte eine Ausführung mit dem Ausführungsstatus Erfolgreich angezeigt werden.
-
Navigieren Sie zur Amazon-S3-Konsole unter https://console.aws.amazon.com/s3/
und überprüfen Sie yourBucketName. Sie sollten Dateien finden, die in Ihren Ausgabe-Bucket geschrieben werden. -
Lesen Sie die Parquet-Dateien und überprüfen Sie deren Inhalt. Sie können dies mit Ihren vorhandenen Tools tun. Wenn Sie keinen Prozess zur Validierung von Parquet-Dateien haben, können Sie dies in der AWS Glue-Konsole mit einer interaktiven Sitzung von AWS Glue tun, indem Sie entweder Spark oder Ray (in der Vorversion) verwenden.
In einer interaktiven Sitzung haben Sie Zugriff auf Ray Data-, Spark- oder Pandas-Bibliotheken, die standardmäßig bereitgestellt werden (basierend auf der von Ihnen gewählten Engine). Um den Inhalt Ihrer Datei zu überprüfen, können Sie gängige Prüfmethoden verwenden, die in diesen Bibliotheken verfügbar sind – Methoden wie
count,schemaundshow. Weitere Informationen zu interaktiven Sitzungen in der Konsole finden Sie unter Verwenden von Notebooks mit AWS Glue-Studio und AWS Glue.Da Sie bestätigt haben, dass Dateien in den Bucket geschrieben wurden, können Sie mit relativer Sicherheit sagen, dass Probleme bei Ihrer Ausgabe nicht mit der IAM-Konfiguration zusammenhängen. Konfigurieren Sie Ihre Sitzung mit
yourRoleName, um Zugriff auf die relevanten Dateien zu haben.
Wenn Sie nicht die erwarteten Ergebnisse sehen, prüfen Sie die Fehlerbehebungsinhalte in diesem Handbuch, um die Fehlerquelle zu ermitteln und zu beheben. Informationen zur Interpretation von Fehlerzuständen bei der Auftragsausführung finden Sie unter AWS Glue-Status von Auftragsausführungen. Den Inhalt zur Fehlerbehebung finden Sie im Fehlerbehebung für AWS Glue-Kapitel. Informationen zu bestimmten Fehlern im Zusammenhang mit Ray-Aufträgen finden Sie unter Fehlerbehebung bei AWS Glue-für-Ray-Fehlern anhand von Protokollen im Kapitel zur Fehlerbehebung.
Nächste Schritte
Sie haben nun einen ETL-Prozess gesehen und durchgeführt, bei dem AWS Glue für Ray vom Anfang bis Ende verwendet wurde. Mithilfe der folgenden Ressourcen können Sie verstehen, welche Tools AWS Glue für Ray für die Transformation und Interpretation Ihrer Daten im großen Maßstab bereitstellt.
-
Weitere Informationen zum Aufgabenmodell von Ray finden Sie unter Verwendung von Ray Core und Ray Data in AWS Glue für Ray. Weitere Erfahrungen mit der Verwendung von Ray-Aufgaben finden Sie in den Beispielen in der Ray-Core-Dokumentation. Lesen Sie Ray Core: Ray-Tutorials und -Beispiele (2.4.0)
in der Ray-Dokumentation. -
Hinweise zu verfügbaren Datenverwaltungsbibliotheken in AWS Glue für Ray finden Sie unter Verbindung zu Daten in Ray-Aufträgen. Weitere Erfahrungen mit Ray Data zum Transformieren und Schreiben von Datensätzen finden Sie in den Beispielen in der Ray-Data-Dokumentation. Lesen Sie Ray Data: Beispiele (2.4.0)
. -
Weitere Informationen zum Konfigurieren von AWS Glue-für-Ray-Aufträge finden Sie unter Arbeiten mit Ray-Aufträgen in AWS Glue.
-
Weitere Informationen zum Schreiben von AWS Glue-für-Ray-Skripten finden Sie in der Dokumentation in diesem Abschnitt.
