Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Integration in AWS Glue Schema Registry
In diesen Abschnitten werden Integrationen mit beschrieben AWS Glue Schemaregistrierung. Die Beispiele in diesem Abschnitt zeigen ein Schema mit AVRO-Datenformat. Weitere Beispiele, einschließlich Schemas mit dem JSON-Datenformat, finden Sie in den Integrationstests und ReadMe Informationen im AWS Glue Open-Source-Repository
Themen
Anwendungsfall: Verbinden der Schema Registry mit Amazon MSK oder Apache Kafka
Nehmen wir an, Sie schreiben Daten in ein Apache-Kafka-Thema, und Sie können diese Schritte ausführen, um loszulegen.
Erstellen Sie einen Amazon Managed Streaming for Apache Kafka (Amazon MSK) oder Apache Kafka-Cluster mit mindestens einem Thema. Wenn Sie einen Amazon-MSK-Cluster erstellen, können Sie die AWS Management Console verwenden. Folgen Sie den Anweisungen unter Erste Schritte mit Amazon MSK im Entwicklerhandbuch für Amazon Managed Streaming for Apache Kafka.
Folgen Sie dem Schritt SerDe Bibliotheken installieren oben.
Um Schemaregistrierungen, Schemata oder Schemaversionen zu erstellen, befolgen Sie die Anweisungen im Abschnitt Erste Schritte mit der Schemaregistrierung dieses Dokuments.
Motivieren Sie Ihre Produzenten und Verbraucher, die Schema Registry zu verwenden, um Datensätze in Amazon-MSK- oder Apache-Kafka-Themen zu schreiben und daraus zu lesen. Ein Beispiel für Produzenten- und Consumer-Code finden Sie in der ReadMe Datei aus den
Serde-Bibliotheken. Die Schema-Registry-Bibliothek des Produzenten serialisiert den Datensatz automatisch und versieht den Datensatz mit einer Schemaversions-ID. Wenn das Schema dieses Datensatzes eingegeben wurde oder die automatische Registrierung aktiviert ist, ist das Schema in der Schema Registry registriert.
Der Verbraucher liest aus dem Amazon MSK- oder Apache Kafka-Thema und verwendet dabei den AWS Glue Die Schema Registry-Bibliothek sucht das Schema automatisch in der Schema Registry.
Anwendungsfall: Integration von Amazon Kinesis Data Streams mit AWS Glue Schema Registry
Diese Integration erfordert, dass Sie einen vorhandenen Amazon Kinesis Data Stream haben. Weitere Informationen finden Sie unter Erste Schritte mit Amazon Kinesis Data Streams im Entwicklerhandbuch für Amazon Kinesis Data Streams.
Es gibt zwei Möglichkeiten, mit Daten in einem Kinesis-Datenstrom zu interagieren.
Über die Bibliotheken Kinesis Producer Library (KPL) und Kinesis Client Library (KCL) in Java. Mehrsprachige Unterstützung wird nicht bereitgestellt.
Durch die
PutRecords,PutRecord, undGetRecordsKinesis Data Streams, die in der APIs AWS SDK für Java verfügbar sind.
Wenn Sie derzeit die KPL/KCL-Bibliotheken verwenden, empfehlen wir, diese Methode weiterhin zu verwenden. Es gibt aktualisierte KCL- und KPL-Versionen mit integrierter Schema Registry, wie in den Beispielen gezeigt. Andernfalls können Sie den Beispielcode verwenden, um Folgendes zu nutzen AWS Glue Schemaregistrierung, wenn Sie das KDS APIs direkt verwenden.
Die Integration der Schema Registry ist mit KPL v0.14.2 oder höher und mit KCL v2.3 oder höher verfügbar. Die Integration der Schema Registry mit dem JSON-Datenformat ist mit KPL v0.14.8 oder höher und mit KCL v2.3.6 oder höher verfügbar.
Interaktion mit Daten mit Kinesis SDK V2
In diesem Abschnitt wird die Interaktion mit Kinesis mithilfe des Kinesis SDK V2 beschrieben
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
Interaktion mit Daten mithilfe der KPL/KCL-Bibliotheken
In diesem Abschnitt wird die Integration von Kinesis Data Streams mit Schema Registry mithilfe von beschriebenKPL/KCL libraries. For more information on using KPL/KCL, siehe Developing Producer Using the Amazon Kinesis Producer Library im Amazon Kinesis Data Streams Developer Guide.
Einrichten der Schema Registry in KPL
Definieren Sie die Schemadefinition für die Daten, das Datenformat und den Schemanamen, wie sie in der AWS Glue Schemaregistrierung.
Konfigurieren Sie optional das
GlueSchemaRegistryConfiguration-Objekt.Übergeben Sie das Schemaobjekt an die
addUserRecord API.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Einrichten der Kinesis Client-Bibliothek
Sie entwickeln Ihre Kinesis Client Library-Verbraucher in Java. Weitere Informationen finden Sie unter Entwickeln eines Kinesis Client Library-Verbrauchers in Java im Entwicklerhandbuch zu Amazon Kinesis Data Streams.
Erstellen Sie eine Instance von
GlueSchemaRegistryDeserializerdurch Übergeben einesGlueSchemaRegistryConfiguration-Objekts.Übergeben Sie den
GlueSchemaRegistryDeserializeranretrievalConfig.glueSchemaRegistryDeserializer.Greifen Sie auf das Schema eingehender Nachrichten zu, indem Sie
kinesisClientRecord.getSchema()aufrufen.GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Interaktion mit Daten mithilfe der Kinesis Data Streams APIs
In diesem Abschnitt wird die Integration von Kinesis Data Streams mit Schema Registry mithilfe der Kinesis Data Streams beschrieben. APIs
Aktualisieren Sie diese Maven-Abhängigkeiten:
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>Fügen Sie im Produzenten Schema-Header-Informationen mithilfe der
PutRecords- oderPutRecord-API in Kinesis Data Streams hinzu.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);Verwenden Sie im Produzenten die
PutRecords- oderPutRecord-API, um den Datensatz in den Datenstrom einzufügen.Entfernen Sie im Verbraucher den Schemadatensatz aus dem Header und serialisieren Sie einen Avro-Schemadatensatz.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Interaktion mit Daten mithilfe der Kinesis Data Streams APIs
Im Folgenden finden Sie einen Beispielcode für die Verwendung von PutRecords und GetRecords APIs.
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Anwendungsfall: Amazon Managed Service für Apache Flink
Apache Flink ist ein beliebtes Open-Source-Framework und eine verteilte Verarbeitungs-Engine für statusbehaftete Berechnungen über unbegrenzte und begrenzte Datenströme. Amazon Managed Service für Apache Flink ist ein vollständig verwalteter AWS Service, mit dem Sie Apache Flink-Anwendungen zur Verarbeitung von Streaming-Daten erstellen und verwalten können.
Open Source Apache Flink bietet eine Reihe von Quellen und Senken. Vordefinierte Datenquellen umfassen beispielsweise das Lesen von Dateien, Verzeichnissen und Sockets sowie das Aufnehmen von Daten aus Sammlungen und Iteratoren. Apache Flink DataStream Connectors bieten Code für Apache Flink als Schnittstelle zu verschiedenen Systemen von Drittanbietern wie Apache Kafka oder Kinesis als Quellen und/oder Senken.
Weitere Informationen finden Sie im Amazon Kinesis Data Analytics-Entwicklerhandbuch.
Apache Flink Kafka Connector
Apache Flink bietet einen Apache-Kafka-Datenstrom-Konnektor für das Lesen von Daten aus Kafka-Themen und das Schreiben von Daten in Kafka-Themen mit Genau-Einmal-Garantie. Der Kafka-Verbraucher von Fink, FlinkKafkaConsumer, bietet Zugriff auf das Lesen aus einem oder mehreren Kafka-Themen. Der Apache-Flink-Kafka-Produzent FlinkKafkaProducer ermöglicht das Schreiben eines Streams von Datensätzen zu einem oder mehreren Kafka-Themen. Weitere Informationen finden Sie unter Kinesis Kafka Konnektor
Apache Flink Kinesis Streams Connector
Der Kinesis Data Stream Connector bietet Zugriff auf Amazon Kinesis Data Streams. Die FlinkKinesisConsumer ist eine exakt einmal parallel Streaming-Datenquelle, die mehrere Kinesis-Streams innerhalb derselben AWS Serviceregion abonniert und das Re-Sharding von Streams transparent handhaben kann, während der Job ausgeführt wird. Jede Unteraufgabe des Verbrauchers ist für das Abrufen von Datensätzen aus mehreren Kinesis-Shards verantwortlich. Die Anzahl der Shards, die von jeder Unteraufgabe abgerufen werden, ändert sich, wenn Shards geschlossen und von Kinesis erstellt werden. Der FlinkKinesisProducer verwendet die Kinesis Producer Library (KPL), um Daten aus einem Apache-Flink-Stream in einen Kinesis-Stream zu übertragen. Weitere Informationen finden Sie unter Amazon Kinesis Streams Connector
Weitere Informationen finden Sie hier: AWS Glue
Integration mit Apache Flink
Die mit Schema Registry bereitgestellte SerDes Bibliothek ist in Apache Flink integriert. Um mit Apache Flink zu arbeiten, müssen Sie die Schnittstellen SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema und GlueSchemaRegistryAvroDeserializationSchema implementieren, die Sie in Apache-Flink-Konnektoren einbinden können.
Hinzufügen eines AWS Glue Abhängigkeit von der Schemaregistrierung zur Apache Flink-Anwendung
Um die Integrationsabhängigkeiten einzurichten für AWS Glue Schemaregistrierung in der Apache Flink-Anwendung:
Fügen Sie die Abhängigkeit zur
pom.xml-Datei hinzu.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Integration von Kafka oder Amazon MSK mit Apache Flink
Sie können Managed Service für Apache Flink für Apache Flink mit Kafka als Quelle oder Kafka als Senke verwenden.
Kafka als Quelle
Das folgende Diagramm zeigt die Integration von Kinesis Data Streams mit Managed Service für Apache Flink für Apache Flink, mit Kafka als Quelle.
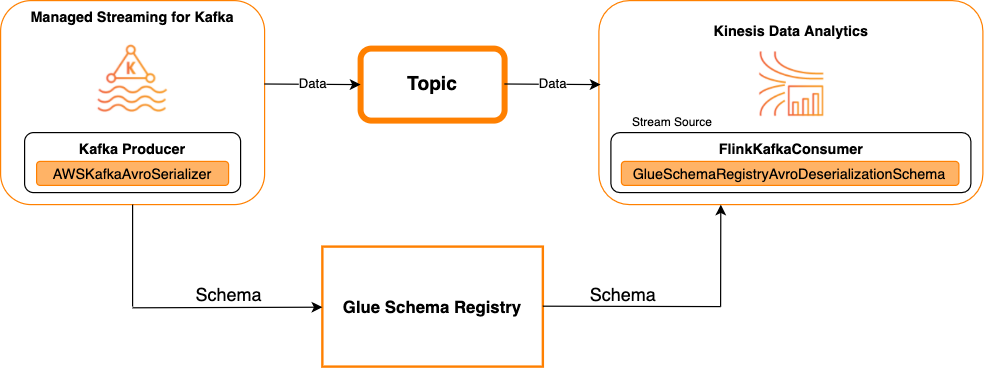
Kafka als Senke
Das folgende Diagramm zeigt die Integration von Kinesis Data Streams mit Managed Service für Apache Flink für Apache Flink, mit Kafka als Senke.
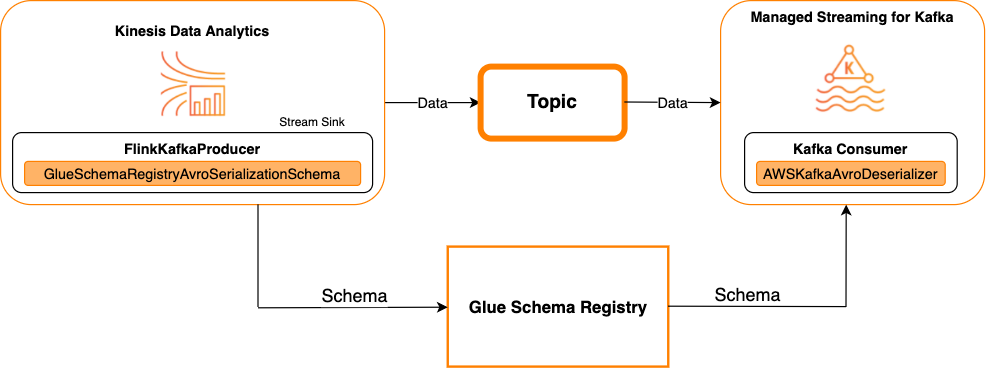
Um Kafka (oder Amazon MSK) in Managed Service für Apache Flink für Apache Flink zu integrieren, mit Kafka als Quelle oder Kafka als Senke, nehmen Sie die folgenden Codeänderungen vor. Fügen Sie in den entsprechenden Abschnitten die fett formatierten Codeblöcke zu Ihrem jeweiligen Code hinzu.
Wenn Kafka die Quelle ist, verwenden Sie den Deserialisierer-Code (Block 2). Wenn Kafka die Senke ist, verwenden Sie den Serialisierer-Code (Block 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Integrieren von Kinesis Data Streams in Apache Flink
Sie können Managed Service für Apache Flink für Apache Flink mit Kinesis Data Streams als Quelle oder Senke verwenden.
Kinesis Data Streams als Quelle
Das folgende Diagramm zeigt die Integration von Kinesis Data Streams mit Managed Service für Apache Flink für Apache Flink, mit Kinesis Data Streams als Quelle.
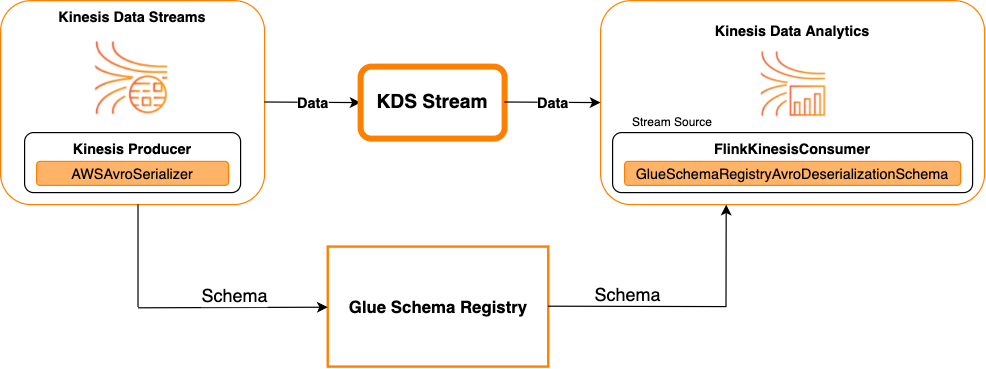
Kinesis Data Streams als Senke
Das folgende Diagramm zeigt die Integration von Kinesis Data Streams mit Managed Service für Apache Flink für Apache Flink, mit Kinesis Data Streams als Senke.
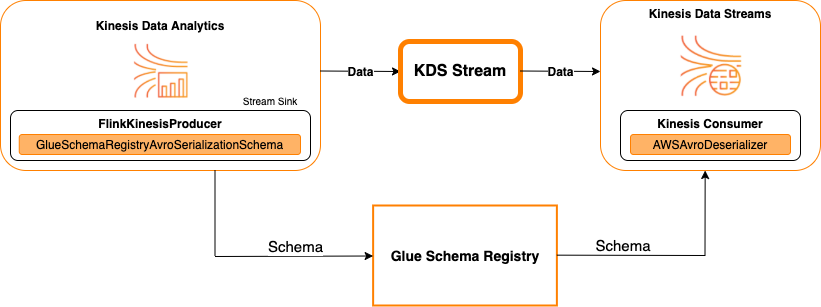
Um Kinesis Data Streams mit Managed Service für Apache Flink für Apache Flink zu integrieren, mit Kinesis Data Streams als Quelle oder Kinesis Data Streams als Senke, nehmen Sie die folgenden Codeänderungen vor. Fügen Sie in den entsprechenden Abschnitten die fett formatierten Codeblöcke zu Ihrem jeweiligen Code hinzu.
Wenn Kinesis Data Streams die Quelle ist, verwenden Sie den Deserialisierer-Code (Block 2). Wenn Kinesis Data Streams die Senke ist, verwenden Sie den Serialisierer-Code (Block 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Anwendungsfall: Integration mit AWS Lambda
Um eine AWS Lambda Funktion als Apache Kafka/Amazon MSK-Consumer zu verwenden und AVRO-kodierte Nachrichten zu deserialisieren mit AWS Glue Schema Registry finden Sie auf der MSK Labs-Seite.
Anwendungsfall: AWS Glue Data Catalog
AWS Glue Tabellen unterstützen Schemas, die Sie manuell oder durch Verweis auf Folgendes angeben können AWS Glue Schemaregistrierung. Die Schemaregistrierung ist in den Datenkatalog integriert, sodass Sie bei der Erstellung oder Aktualisierung optional in der Schemaregistry gespeicherte Schemas verwenden können AWS Glue Tabellen oder Partitionen im Datenkatalog. Um eine Schemadefinition in der Schema Registry zu identifizieren, müssen Sie mindestens den ARN des Schemas kennen, zu dem diese gehört. Eine Schemaversion eines Schemas, die eine Schemadefinition enthält, kann durch seine UUID oder Versionsnummer referenziert werden. Es gibt immer eine Schemaversion, die „neueste“ Version, die nachgeschlagen werden kann, ohne die Versionsnummer oder UUID zu kennen.
Bei Aufrufen der CreateTable- oder UpdateTable-Operationen übergeben Sie eine TableInput-Struktur mit einem StorageDescriptor, der unter Umständen eine SchemaReference auf ein vorhandenes Schema in der Schema Registry hat. In ähnlicher Weise kann die Antwort beim Aufrufen von GetTable oder GetPartition APIs das Schema und das enthaltenSchemaReference. Wenn eine Tabelle oder Partition mit Schemareferenzen erstellt wurde, versucht der Data Catalog, das Schema für diese Schemareferenz abzurufen. Falls er das Schema in der Schema Registry nicht findet, wird ein leeres Schema in der GetTable-Antwort zurückgegeben. Andernfalls enthält die Antwort sowohl das Schema als auch die Schemareferenz.
Sie können die Aktionen auch von der AWS Glue console.
Um diese Vorgänge durchzuführen und die Schemainformationen zu erstellen, zu aktualisieren oder anzuzeigen, müssen Sie dem aufrufenden Benutzer eine IAM-Rolle zuweisen, die Berechtigungen für die GetSchemaVersion-API bereitstellt.
Hinzufügen einer Tabelle oder Aktualisieren des Schemas für eine Tabelle
Das Hinzufügen einer neuen Tabelle aus einem vorhandenen Schema bindet die Tabelle an eine bestimmte Schemaversion. Sobald neue Schemaversionen registriert wurden, können Sie diese Tabellendefinition auf der Seite Tabelle anzeigen im AWS Glue Konsole oder mithilfe der UpdateTable Aktion (Python: update_table) API.
Hinzufügen einer Tabelle aus einem vorhandenen Schema
Sie können eine erstellen AWS Glue Tabelle aus einer Schemaversion in der Registrierung mit dem AWS Glue Konsole oder CreateTable API.
AWS Glue API
Bei Aufrufen der CreateTable-API übergeben Sie eine TableInput mit einem StorageDescriptor und einer SchemaReference zu einem vorhandenen Schema in der Schema Registry.
AWS Glue Konsole
Um eine Tabelle aus dem zu erstellen AWS Glue Konsole:
-
Melden Sie sich an AWS Management Console und öffnen Sie das AWS Glue Konsole bei https://console.aws.amazon.com/glue/
. Wählen Sie im Navigationsbereich unter Data Catalog die Option Tables (Tabellen).
Wählen Sie im Menü Add Tables (Tabellen hinzufügen) die Option Add table from existing schema (Tabelle aus vorhandenem Schema hinzufügen).
Konfigurieren Sie die Tabelleneigenschaften und den Datenspeicher gemäß AWS Glue Entwicklerhandbuch.
Wählen Sie auf der Seite Choose a Glue schema (Glue-Schema wählen) die Registry, in dem sich das Schema befindet.
Wählen Sie den Schema name (Schemaname) und wählen Sie die Version des anzuwendenden Schemas.
Überprüfen Sie die Schemavorschau und klicken Sie auf Next (Weiter).
Überprüfen und erstellen Sie die Tabelle.
Das Schema und die Version, die auf die Tabelle angewendet werden, werden in der Spalte Glue-Schema in der Liste der Tabellen angezeigt. Sie können die Tabelle anzeigen, um weitere Details zu sehen.
Aktualisieren des Schemas für eine Tabelle
Wenn eine neue Schemaversion verfügbar ist, möchten Sie möglicherweise das Schema einer Tabelle mithilfe der UpdateTable Aktion (Python: update_table) API oder der aktualisieren AWS Glue console.
Wichtig
Wenn Sie das Schema für eine vorhandene Tabelle aktualisieren, die über AWS Glue Das manuell angegebene Schema ist möglicherweise nicht kompatibel mit dem neuen Schema, auf das in der Schemaregistrierung verwiesen wird. Dies kann dazu führen, dass Ihre Aufträge fehlschlagen.
AWS Glue API
Bei Aufrufen der UpdateTable-API übergeben Sie eine TableInput mit einem StorageDescriptor und einer SchemaReference zu einem vorhandenen Schema in der Schema Registry.
AWS Glue Konsole
Um das Schema für eine Tabelle aus dem zu aktualisieren AWS Glue Konsole:
-
Melden Sie sich an AWS Management Console und öffnen Sie das AWS Glue Konsole bei https://console.aws.amazon.com/glue/
. Wählen Sie im Navigationsbereich unter Data Catalog die Option Tables (Tabellen).
Zeigen Sie die Tabelle aus der Liste der Tabellen an.
Klicken Sie auf Update schema (Schema aktualisieren) in dem Feld, das Sie über die neue Version informiert.
Überprüfen Sie die Unterschiede zwischen dem aktuellen und dem neuen Schema.
Klicken Sie auf Show all schema differences (Alle Schemaunterschiede anzeigen), um weitere Details zu sehen.
Klicken Sie auf Save table (Tabelle speichern), um die neue Version zu akzeptieren.
Anwendungsfall: AWS Glue Streamen
AWS Glue Beim Streaming werden Daten aus Streaming-Quellen verbraucht und ETL-Operationen ausgeführt, bevor sie in eine Ausgabesenke geschrieben werden. Die Eingabe-Streaming-Quelle kann mit einer Datentabelle oder direkt durch Angabe der Quellkonfiguration angegeben werden.
AWS Glue Streaming unterstützt eine Datenkatalogtabelle für die Streaming-Quelle, die mit dem Schema erstellt wurde, das in AWS Glue Schemaregistrierung. Sie können ein Schema erstellen in AWS Glue Schemaregistrierung und erstellen Sie ein AWS Glue Tabelle mit einer Streaming-Quelle, die dieses Schema verwendet. Dieser AWS Glue Tabelle kann als Eingabe für eine verwendet werden AWS Glue Streaming-Job zum Deserialisieren von Daten im Eingabestream.
Ein Punkt, der hier zu beachten ist, ist, wenn das Schema in der AWS Glue Wenn sich die Schemaregistrierung ändert, müssen Sie das neu starten AWS Glue Der Streaming-Job muss die Änderungen im Schema widerspiegeln.
Anwendungsfall: Apache Kafka Streams
Die Apache Kafka Streams API ist eine Client-Bibliothek zur Verarbeitung und Analyse von Daten, die in Apache Kafka gespeichert sind. Dieser Abschnitt beschreibt die Integration von Apache Kafka Streams mit AWS Glue Schema Registry, mit der Sie Schemas in Ihren Datenstreaming-Anwendungen verwalten und durchsetzen können. Weitere Informationen zu Apache Kafka Streams finden Sie unter Apache Kafka Streams
Integration mit den Bibliotheken SerDes
Es gibt eine GlueSchemaRegistryKafkaStreamsSerde-Klasse, mit der Sie eine Streams-Anwendung konfigurieren können.
Beispielcode für die Kafka-Streams-Anwendung
Um das AWS Glue Schemaregistrierung innerhalb einer Apache Kafka Streams-Anwendung:
Konfigurieren Sie die Kafka-Streams-Anwendung.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());Erstellen Sie einen Stream aus dem Thema avro-input.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");Verarbeiten Sie die Datensätze (das Beispiel filtert die Datensätze heraus, deren Wert favorite_color pink ist oder bei denen der Wert von „amount“ 15 ist).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));Schreiben Sie die Ergebnisse zurück in das Thema avro-output.
result.to("avro-output");Starten Sie die Apache-Kafka-Streams-Anwendung.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
Ergebnisse der Implementierung
Diese Ergebnisse zeigen den Filtervorgang von Datensätzen, die in Schritt 3 als favorite_color mit „pink“ oder „15.0“ herausgefiltert wurden.
Datensätze vor dem Filtern:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
Datensätze nach dem Filtern:
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
Anwendungsfall: Apache Kafka Connect
Die Integration von Apache Kafka Connect mit dem AWS Glue Mit Schema Registry können Sie Schemainformationen von Konnektoren abrufen. Die Apache-Kafka-Konverter geben das Format der Daten in Apache Kafka an, und wie diese in Apache-Kafka-Connect-Daten übersetzt werden. Jeder Apache-Kafka-Connect-Benutzer muss diese Konverter basierend auf dem Format konfigurieren, in dem seine Daten geladen oder in Apache Kafka gespeichert werden sollen. Auf diese Weise können Sie Ihre eigenen Konverter definieren, um Apache Kafka Connect-Daten in den Typ zu übersetzen, der in der AWS Glue Schema Registry (zum Beispiel: Avro) und unseren Serializer verwenden, um das Schema zu registrieren und die Serialisierung durchzuführen. Dann können Konverter auch unseren Deserializer verwenden, um die von Apache Kafka empfangenen Daten zu deserialisieren und wieder in Apache-Kafka-Connect-Daten zu konvertieren. Ein Beispiel für ein Workflow-Diagramm ist unten angegeben.
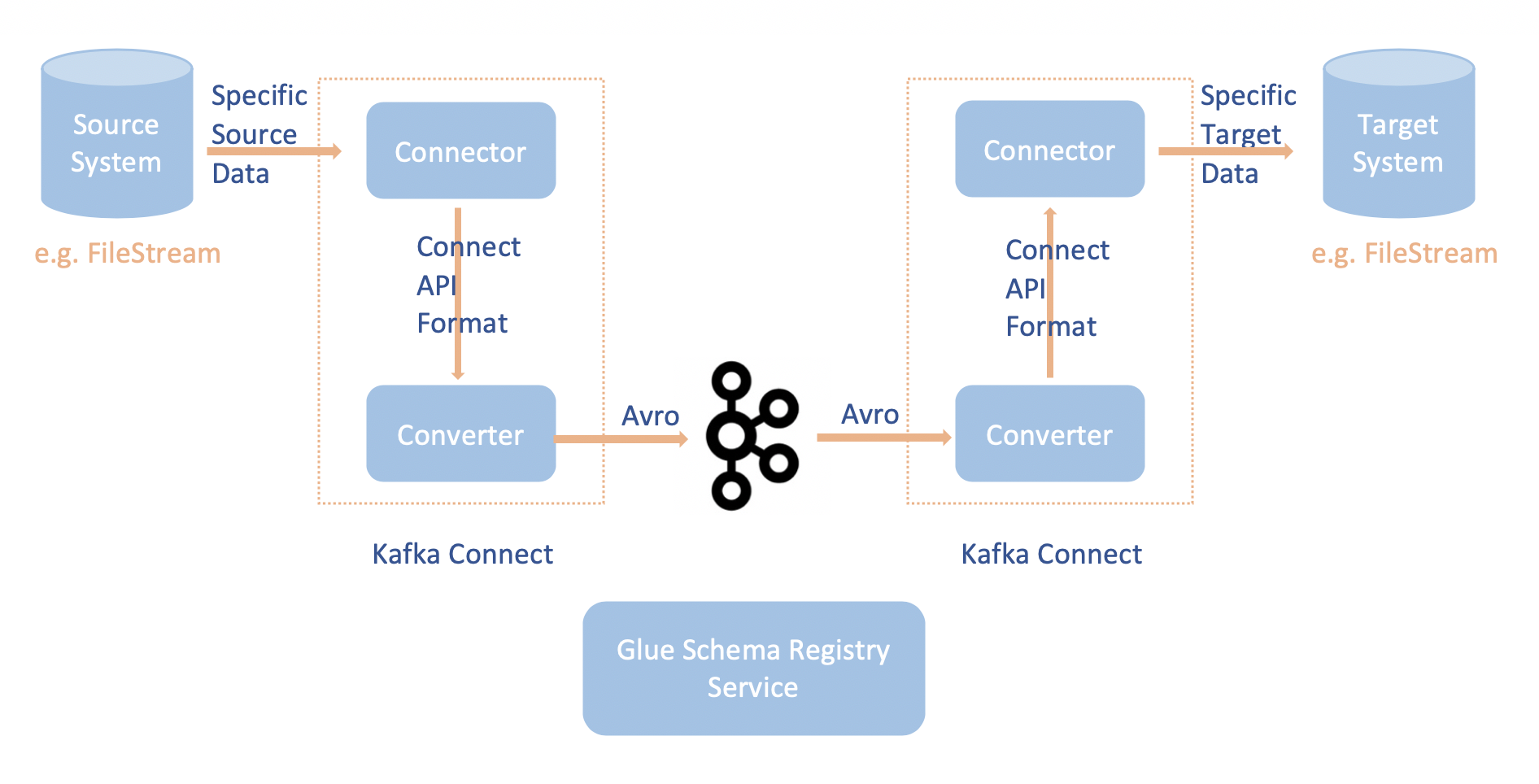
Installieren Sie das
aws-glue-schema-registryProjekt, indem Sie das Github-Repository für klonen AWS Glue Schema-Registrierung. git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesWenn Sie planen, Apache Kafka Connect im Standalone-Modus zu verwenden, aktualisieren Sie die connect-standalone.properties mit der untenstehenden Anleitung für diesen Schritt. Wenn Sie Apache Kafka Connect im verteilten Modus verwenden möchten, aktualisieren Sie connect-avro-distributed.properties mit denselben Anweisungen.
Fügen Sie diese Eigenschaften auch der Apache-Kafka-Connect-Properties-Datei hinzu:
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDFügen Sie den folgenden Befehl zum Abschnitt Startmodus unter kafka-run-class .sh hinzu:
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
Fügen Sie den folgenden Befehl zum Abschnitt Startmodus unter kafka-run-class .sh hinzu
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"Das sollte wie folgt aussehen:
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fiWenn Sie bash verwenden, führen Sie die folgenden Befehle aus, um Ihren CLASSPATH in Ihrem bash_profile einzurichten. Aktualisieren Sie die Umgebung für jede andere Shell entsprechend.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(Optional) Wenn Sie mit einer einfachen Dateiquelle testen möchten, klonen Sie den Dateiquellen-Konnektor.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/Ändern Sie unter der Konfiguration des Quellen-Konnektors das Datenformat auf Avro, den Datei-Reader auf
AvroFileReaderund aktualisieren Sie ein Beispiel-Avro-Objekt aus dem Dateipfad, aus dem Sie lesen. Zum Beispiel:vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderInstallieren Sie den Quellen-Konnektor.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profileAktualisieren Sie die Senkeneigenschaften unter
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Starten Sie den Quellen-Konnektor (in diesem Beispiel handelt es sich um einen Dateiquellen-Konnektor).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesFühren Sie den Quellen-Konnektor aus (in diesem Beispiel handelt es sich um einen Dateiquellen-Konnektor).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesEin Beispiel für die Verwendung von Kafka Connect finden Sie im Skript run-local-tests .sh im Ordner integration-tests im Github-Repository für AWS Glue
Schemaregistrierung.
