AWS IoT Greengrass Version 1 trat am 30. Juni 2023 in die erweiterte Lebensphase ein. Weitere Informationen finden Sie in der AWS IoT Greengrass V1 Wartungsrichtlinie. Nach diesem Datum AWS IoT Greengrass V1 werden keine Updates mehr veröffentlicht, die Funktionen, Verbesserungen, Bugfixes oder Sicherheitspatches bieten. Geräte, die auf laufen, werden AWS IoT Greengrass V1 nicht gestört und funktionieren weiterhin und stellen eine Verbindung zur Cloud her. Wir empfehlen Ihnen dringend, zu migrieren AWS IoT Greengrass Version 2, da dies wichtige neue Funktionen und Unterstützung für zusätzliche Plattformen bietet.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfigurationen für unterstützte AWS Cloud Ziele exportieren
Benutzerdefinierte Lambda-Funktionen, die StreamManagerClient im AWS IoT Greengrass Core SDK verwendet werden, um mit dem Stream-Manager zu interagieren. Wenn eine Lambda-Funktion einen Stream erstellt oder einen Stream aktualisiert, übergibt sie ein MessageStreamDefinition Objekt, das Stream-Eigenschaften darstellt, einschließlich der Exportdefinition. Das ExportDefinition Objekt enthält die für den Stream definierten Exportkonfigurationen. Stream Manager verwendet diese Exportkonfigurationen, um zu bestimmen, wo und wie der Stream exportiert werden soll.
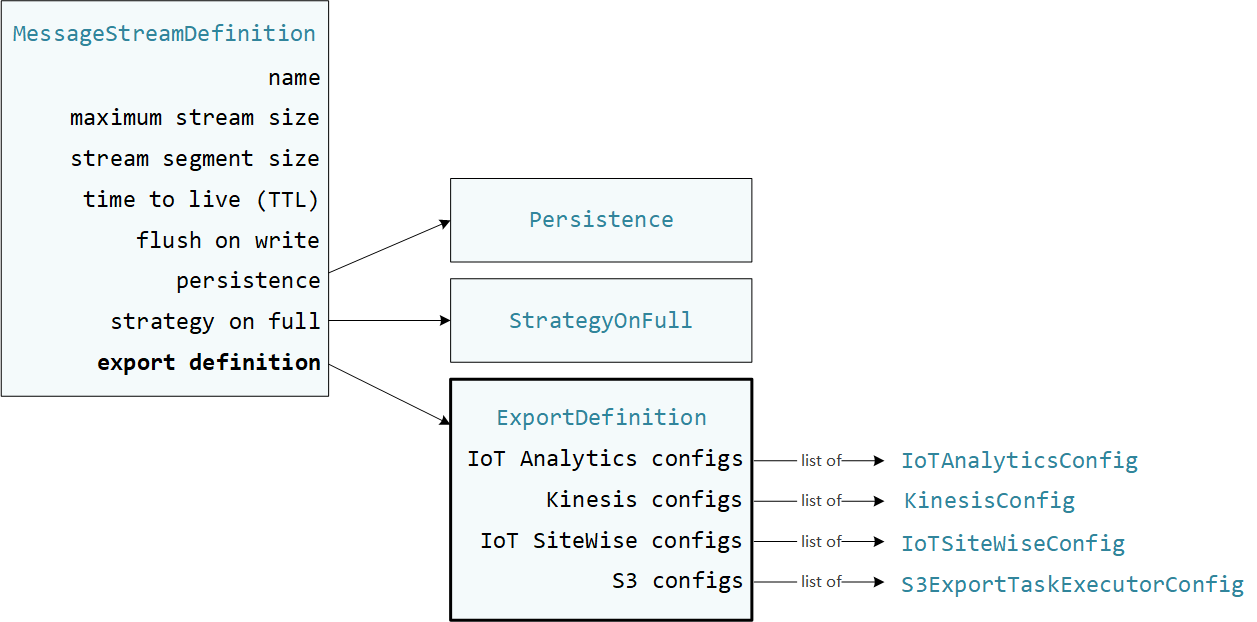
Sie können keine oder mehr Exportkonfigurationen für einen Stream definieren, einschließlich mehrerer Exportkonfigurationen für einen einzelnen Zieltyp. Sie können beispielsweise einen Stream in zwei AWS IoT Analytics Kanäle und einen Kinesis-Datenstream exportieren.
Bei fehlgeschlagenen Exportversuchen versucht Stream Manager kontinuierlich, Daten in Intervallen von bis zu fünf Minuten zu exportieren. AWS Cloud Für die Anzahl der Wiederholungsversuche gibt es keine Obergrenze.
Anmerkung
StreamManagerClientbietet auch ein Zielziel, mit dem Sie Streams auf einen HTTP-Server exportieren können. Dieses Ziel dient nur zu Testzwecken. Es ist weder stabil noch wird es für die Verwendung in Produktionsumgebungen unterstützt.
Unterstützte AWS Cloud Ziele
Sie sind für die Wartung dieser AWS Cloud Ressourcen verantwortlich.
AWS IoT Analytics Kanäle
Stream Manager unterstützt automatische Exporte nach AWS IoT Analytics. AWS IoT Analytics ermöglicht es Ihnen, erweiterte Analysen Ihrer Daten durchzuführen, um Geschäftsentscheidungen zu treffen und Modelle für maschinelles Lernen zu verbessern. Weitere Informationen finden Sie unter Was ist AWS IoT Analytics? im AWS IoT Analytics Benutzerhandbuch.
Im AWS IoT Greengrass Core SDK verwenden Ihre Lambda-Funktionen die, IoTAnalyticsConfig um die Exportkonfiguration für diesen Zieltyp zu definieren. Weitere Informationen finden Sie in der SDK-Referenz für Ihre Zielsprache:
-
Io TAnalytics Config
im Python-SDK -
Io TAnalytics Config
im Java SDK -
Io TAnalytics Config
im SDK Node.js
Voraussetzungen
Für dieses Exportziel gelten die folgenden Anforderungen:
-
Die Zielkanäle in AWS IoT Analytics müssen sich in derselben AWS-Konto und AWS-Region wie die Greengrass-Gruppe befinden.
-
Sie Greengrass-Gruppenrolle. müssen die
iotanalytics:BatchPutMessageErlaubnis erteilen, Kanäle gezielt anzusprechen. Zum Beispiel:{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iotanalytics:BatchPutMessage" ], "Resource": [ "arn:aws:iotanalytics:region:account-id:channel/channel_1_name", "arn:aws:iotanalytics:region:account-id:channel/channel_2_name" ] } ] }Sie können detaillierten oder bedingten Zugriff auf Ressourcen gewähren, indem Sie beispielsweise ein
*Platzhalter-Benennungsschema verwenden. Weitere Informationen finden Sie im IAM-Benutzerhandbuch unter Hinzufügen und Entfernen von IAM-Richtlinien.
Exportieren nach AWS IoT Analytics
Um einen Stream zu erstellen, in den exportiert wird AWS IoT Analytics, erstellen Ihre Lambda-Funktionen einen Stream mit einer Exportdefinition, die ein oder mehrere IoTAnalyticsConfig Objekte enthält. Dieses Objekt definiert Exporteinstellungen wie den Zielkanal, die Batchgröße, das Batch-Intervall und die Priorität.
Wenn Ihre Lambda-Funktionen Daten von Geräten empfangen, hängen sie Nachrichten, die einen Datenblock enthalten, an den Zielstream an.
Anschließend exportiert der Stream Manager die Daten auf der Grundlage der Batch-Einstellungen und der Priorität, die in den Exportkonfigurationen des Streams definiert sind.
Amazon Kinesis Kinesis-Datenströme
Stream Manager unterstützt automatische Exporte nach Amazon Kinesis Data Streams. Kinesis Data Streams wird häufig verwendet, um große Datenmengen zu aggregieren und sie in ein Data Warehouse oder einen Map-Reduce-Cluster zu laden. Weitere Informationen finden Sie unter Was ist Amazon Kinesis Data Streams? im Amazon Kinesis Developer Guide.
Im AWS IoT Greengrass Core SDK verwenden Ihre Lambda-Funktionen die, KinesisConfig um die Exportkonfiguration für diesen Zieltyp zu definieren. Weitere Informationen finden Sie in der SDK-Referenz für Ihre Zielsprache:
-
KinesisConfig
im Python-SDK -
KinesisConfig
im Java-SDK -
KinesisConfig
im SDK von Node.js
Voraussetzungen
Für dieses Exportziel gelten die folgenden Anforderungen:
-
Ziel-Streams in Kinesis Data Streams müssen sich in derselben AWS-Konto und AWS-Region wie die Greengrass-Gruppe befinden.
-
Sie Greengrass-Gruppenrolle. müssen die
kinesis:PutRecordsErlaubnis erteilen, Datenstreams als Ziel zu verwenden. Zum Beispiel:{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kinesis:PutRecords" ], "Resource": [ "arn:aws:kinesis:region:account-id:stream/stream_1_name", "arn:aws:kinesis:region:account-id:stream/stream_2_name" ] } ] }Sie können detaillierten oder bedingten Zugriff auf Ressourcen gewähren, indem Sie beispielsweise ein
*Platzhalter-Benennungsschema verwenden. Weitere Informationen finden Sie im IAM-Benutzerhandbuch unter Hinzufügen und Entfernen von IAM-Richtlinien.
In Kinesis Data Streams exportieren
Um einen Stream zu erstellen, der in Kinesis Data Streams exportiert wird, erstellen Ihre Lambda-Funktionen einen Stream mit einer Exportdefinition, die ein oder mehrere KinesisConfig Objekte enthält. Dieses Objekt definiert Exporteinstellungen wie den Zieldatenstream, die Batchgröße, das Batch-Intervall und die Priorität.
Wenn Ihre Lambda-Funktionen Daten von Geräten empfangen, hängen sie Nachrichten, die einen Datenblock enthalten, an den Zielstream an. Anschließend exportiert der Stream Manager die Daten auf der Grundlage der Batch-Einstellungen und der Priorität, die in den Exportkonfigurationen des Streams definiert sind.
Stream Manager generiert eine eindeutige, zufällige UUID als Partitionsschlüssel für jeden Datensatz, der auf Amazon Kinesis hochgeladen wird.
AWS IoT SiteWise Eigenschaften von Vermögenswerten
Stream Manager unterstützt automatische Exporte nach AWS IoT SiteWise. AWS IoT SiteWise ermöglicht das Sammeln, Organisieren und Analysieren von Daten aus Industrieanlagen in großem Maßstab. Weitere Informationen finden Sie unter Was ist AWS IoT SiteWise? im AWS IoT SiteWise Benutzerhandbuch.
Im AWS IoT Greengrass Core SDK verwenden Ihre Lambda-Funktionen die, IoTSiteWiseConfig um die Exportkonfiguration für diesen Zieltyp zu definieren. Weitere Informationen finden Sie in der SDK-Referenz für Ihre Zielsprache:
-
Io TSite WiseConfig
im Python-SDK -
Io TSite WiseConfig
im Java-SDK -
Io TSite WiseConfig
im SDK von Node.js
Anmerkung
AWS bietet auch die SiteWise IoT-Anschluss, bei der es sich um eine vorgefertigte Lösung handelt, die Sie mit OPC-UA-Quellen verwenden können.
Voraussetzungen
Für dieses Exportziel gelten die folgenden Anforderungen:
-
Die Immobilien des AWS IoT SiteWise Zielobjekts in müssen sich in derselben AWS-Konto und AWS-Region wie die Greengrass-Gruppe befinden.
Anmerkung
Eine Liste der Regionen, die AWS IoT SiteWise unterstützt werden, finden Sie in der AWS allgemeinen AWS IoT SiteWise Referenz unter Endpunkte und Kontingente.
-
Sie Greengrass-Gruppenrolle. müssen die
iotsitewise:BatchPutAssetPropertyValueErlaubnis erteilen, auf Objekteigenschaften zu zielen. In der folgenden Beispielrichtlinie wird deriotsitewise:assetHierarchyPathBedingungsschlüssel verwendet, um Zugriff auf ein Zielstamm-Asset und dessen untergeordnete Objekte zu gewähren. Sie können dasConditionaus der Richtlinie entfernen, um Zugriff auf alle Ihre AWS IoT SiteWise Ressourcen zu gewähren oder einzelne Ressourcen anzugeben ARNs .{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iotsitewise:BatchPutAssetPropertyValue", "Resource": "*", "Condition": { "StringLike": { "iotsitewise:assetHierarchyPath": [ "/root node asset ID", "/root node asset ID/*" ] } } } ] }Sie können detaillierten oder bedingten Zugriff auf Ressourcen gewähren, indem Sie beispielsweise ein
*Platzhalter-Benennungsschema verwenden. Weitere Informationen finden Sie im IAM-Benutzerhandbuch unter Hinzufügen und Entfernen von IAM-Richtlinien.Wichtige Sicherheitsinformationen finden Sie im AWS IoT SiteWise Benutzerhandbuch unter BatchPutAssetPropertyValue Autorisierung.
Exportieren nach AWS IoT SiteWise
Um einen Stream zu erstellen, in den exportiert wird AWS IoT SiteWise, erstellen Ihre Lambda-Funktionen einen Stream mit einer Exportdefinition, die ein oder mehrere IoTSiteWiseConfig Objekte enthält. Dieses Objekt definiert Exporteinstellungen wie Batchgröße, Batch-Intervall und Priorität.
Wenn Ihre Lambda-Funktionen Asset-Eigenschaftsdaten von Geräten empfangen, hängen sie Nachrichten, die die Daten enthalten, an den Zielstream an. Nachrichten sind JSON-serialisierte PutAssetPropertyValueEntry Objekte, die Eigenschaftswerte für eine oder mehrere Asset-Eigenschaften enthalten. Weitere Informationen finden Sie unter Nachricht für Exportziele anhängen. AWS IoT SiteWise
Anmerkung
Wenn Sie Daten an senden AWS IoT SiteWise, müssen Ihre Daten die Anforderungen der BatchPutAssetPropertyValue Aktion erfüllen. Weitere Informationen finden Sie unter BatchPutAssetPropertyValue in der AWS IoT SiteWise -API-Referenz.
Anschließend exportiert Stream Manager die Daten auf der Grundlage der Batch-Einstellungen und der Priorität, die in den Exportkonfigurationen des Streams definiert sind.
Sie können Ihre Stream-Manager-Einstellungen und die Lambda-Funktionslogik anpassen, um Ihre Exportstrategie zu entwerfen. Zum Beispiel:
-
Für Exporte fast in Echtzeit sollten Sie niedrige Einstellungen für Batchgröße und Intervalle festlegen und die Daten an den Stream anhängen, wenn sie empfangen werden.
-
Um die Batchverarbeitung zu optimieren, Bandbreitenbeschränkungen zu verringern oder Kosten zu minimieren, können Ihre Lambda-Funktionen die für eine einzelne Anlageneigenschaft empfangenen timestamp-quality-value (TQV-) Datenpunkte bündeln, bevor sie an den Stream angehängt werden. Eine Strategie besteht darin, Einträge für bis zu 10 verschiedene Kombinationen von Eigenschaften und Vermögenswerten oder Eigenschaftsaliasnamen in einer Nachricht zu bündeln, anstatt mehr als einen Eintrag für dieselbe Immobilie zu senden. Dies hilft dem Streammanager, die Kontingente einzuhalten.AWS IoT SiteWise
Amazon-S3-Objekte
Stream Manager unterstützt automatische Exporte nach Amazon S3. Sie können Amazon S3 verwenden, um große Datenmengen zu speichern und abzurufen. Weitere Informationen finden Sie unter Was ist Amazon S3? im Amazon Simple Storage Service Developer Guide.
Im AWS IoT Greengrass Core SDK verwenden Ihre Lambda-Funktionen die, S3ExportTaskExecutorConfig um die Exportkonfiguration für diesen Zieltyp zu definieren. Weitere Informationen finden Sie in der SDK-Referenz für Ihre Zielsprache:
-
S3 ExportTaskExecutorConfig
im Python-SDK -
S3 ExportTaskExecutorConfig
im Java-SDK -
S3 ExportTaskExecutorConfig
im SDK von Node.js
Voraussetzungen
Für dieses Exportziel gelten die folgenden Anforderungen:
-
Die Amazon S3 S3-Ziel-Buckets müssen sich in derselben Gruppe AWS-Konto wie die Greengrass-Gruppe befinden.
-
Wenn die Standardcontainerisierung für die Greengrass-Gruppe Greengrass-Container ist, müssen Sie den Parameter STREAM_MANAGER_READ_ONLY_DIRS so einstellen, dass ein Eingabedateiverzeichnis verwendet wird, das sich unter oder außerhalb des Root-Dateisystems befindet.
/tmp -
Wenn eine Lambda-Funktion, die im Greengrass-Container-Modus ausgeführt wird, Eingabedateien in das Eingabedateiverzeichnis schreibt, müssen Sie eine lokale Volume-Ressource für das Verzeichnis erstellen und das Verzeichnis mit Schreibberechtigungen in den Container einbinden. Dadurch wird sichergestellt, dass die Dateien in das Root-Dateisystem geschrieben und außerhalb des Containers sichtbar sind. Weitere Informationen finden Sie unter Greifen Sie mit Lambda-Funktionen und Konnektoren auf lokale Ressourcen zu.
-
Sie Greengrass-Gruppenrolle. müssen die folgenden Berechtigungen für die Ziel-Buckets gewähren. Zum Beispiel:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::bucket-1-name/*", "arn:aws:s3:::bucket-2-name/*" ] } ] }Sie können detaillierten oder bedingten Zugriff auf Ressourcen gewähren, indem Sie beispielsweise ein
*Platzhalter-Benennungsschema verwenden. Weitere Informationen finden Sie im IAM-Benutzerhandbuch unter Hinzufügen und Entfernen von IAM-Richtlinien.
Exportieren nach Amazon S3
Um einen Stream zu erstellen, der nach Amazon S3 exportiert, verwenden Ihre Lambda-Funktionen das S3ExportTaskExecutorConfig Objekt, um die Exportrichtlinie zu konfigurieren. Die Richtlinie definiert Exporteinstellungen, wie z. B. den Schwellenwert und die Priorität für mehrteilige Uploads. Für Amazon S3 S3-Exporte lädt der Stream Manager Daten hoch, die er aus lokalen Dateien auf dem Kerngerät liest. Um einen Upload zu initiieren, hängen Ihre Lambda-Funktionen eine Exportaufgabe an den Zielstream an. Die Exportaufgabe enthält Informationen über die Eingabedatei und das Amazon S3 S3-Zielobjekt. Stream Manager führt Aufgaben in der Reihenfolge aus, in der sie an den Stream angehängt werden.
Anmerkung
Der Ziel-Bucket muss bereits in Ihrem vorhanden sein. AWS-Konto Wenn ein Objekt für den angegebenen Schlüssel nicht existiert, erstellt Stream Manager das Objekt für Sie.
Dieser allgemeine Arbeitsablauf ist in der folgenden Abbildung dargestellt.
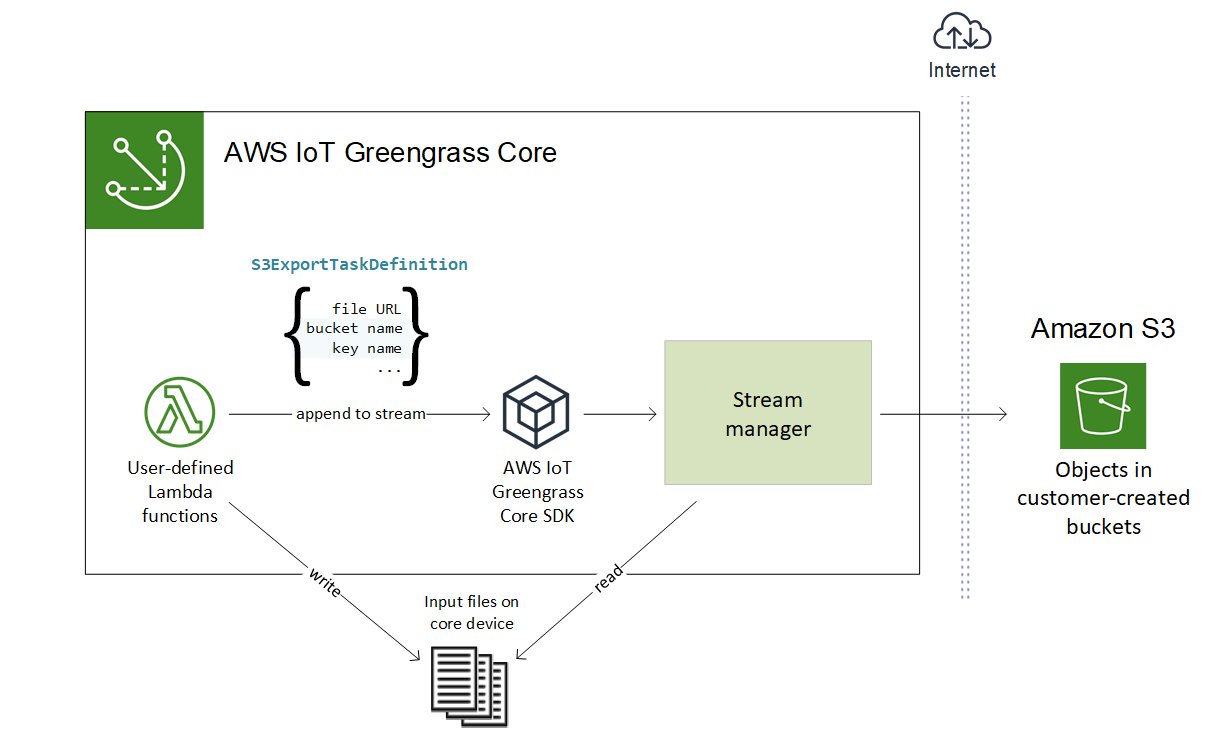
Stream Manager verwendet die Eigenschaft „Schwellenwert für mehrteilige Uploads“, die Einstellung für die Mindestgröße von Teilen und die Größe der Eingabedatei, um zu bestimmen, wie Daten hochgeladen werden. Der Schwellenwert für mehrteilige Uploads muss größer oder gleich der Mindestgröße für Teile sein. Wenn Sie Daten parallel hochladen möchten, können Sie mehrere Streams erstellen.
Die Schlüssel, die Ihre Amazon S3 S3-Zielobjekte angeben, können gültige DateTimeFormatterJava-Zeichenfolgen!{timestamp: Platzhaltern enthalten. Sie können diese Zeitstempel-Platzhalter verwenden, um Daten in Amazon S3 auf der Grundlage der Uhrzeit zu partitionieren, zu der die Eingabedateidaten hochgeladen wurden. Der folgende Schlüsselname wird beispielsweise in einen Wert wie aufgelöst. value}my-key/2020/12/31/data.txt
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
Anmerkung
Wenn Sie den Exportstatus für einen Stream überwachen möchten, erstellen Sie zuerst einen Status-Stream und konfigurieren Sie dann den Exportstream so, dass er ihn verwendet. Weitere Informationen finden Sie unter Überwachen Sie die Exportaufgaben.
Eingabedaten verwalten
Sie können Code verfassen, den IoT-Anwendungen verwenden, um den Lebenszyklus der Eingabedaten zu verwalten. Der folgende Beispiel-Workflow zeigt, wie Sie Lambda-Funktionen verwenden können, um diese Daten zu verwalten.
-
Ein lokaler Prozess empfängt Daten von Geräten oder Peripheriegeräten und schreibt die Daten dann in Dateien in einem Verzeichnis auf dem Kerngerät. Dies sind die Eingabedateien für den Stream-Manager.
Anmerkung
Informationen darüber, ob Sie den Zugriff auf das Eingabedateiverzeichnis konfigurieren müssen, finden Sie im Parameter STREAM_MANAGER_READ_ONLY_DIRS.
Der Prozess, in dem Stream Manager ausgeführt wird, erbt alle Dateisystemberechtigungen der Standardzugriffsidentität für die Gruppe. Der Stream-Manager muss über die Zugriffsberechtigung für die Eingabedateien verfügen. Sie können den
chmod(1)Befehl verwenden, um die Berechtigungen der Dateien bei Bedarf zu ändern. -
Eine Lambda-Funktion scannt das Verzeichnis und hängt eine Exportaufgabe an den Zielstream an, wenn eine neue Datei erstellt wird. Die Aufgabe ist ein JSON-serialisiertes
S3ExportTaskDefinitionObjekt, das die URL der Eingabedatei, den Amazon S3 S3-Ziel-Bucket und -Schlüssel sowie optionale Benutzermetadaten angibt. -
Stream Manager liest die Eingabedatei und exportiert die Daten in der Reihenfolge der angehängten Aufgaben nach Amazon S3. Der Ziel-Bucket muss bereits in Ihrem AWS-Konto vorhanden sein. Wenn ein Objekt für den angegebenen Schlüssel nicht existiert, erstellt Stream Manager das Objekt für Sie.
-
Die Lambda-Funktion liest Nachrichten aus einem Status-Stream, um den Exportstatus zu überwachen. Nach Abschluss der Exportaufgaben kann die Lambda-Funktion die entsprechenden Eingabedateien löschen. Weitere Informationen finden Sie unter Überwachen Sie die Exportaufgaben.
Überwachen Sie die Exportaufgaben
Sie können Code verfassen, den IoT-Anwendungen verwenden, um den Status Ihrer Amazon S3 S3-Exporte zu überwachen. Ihre Lambda-Funktionen müssen einen Status-Stream erstellen und dann den Export-Stream so konfigurieren, dass Statusaktualisierungen in den Status-Stream geschrieben werden. Ein einziger Status-Stream kann Statusaktualisierungen von mehreren Streams empfangen, die nach Amazon S3 exportiert werden.
Erstellen Sie zunächst einen Stream, der als Status-Stream verwendet werden soll. Sie können die Größe und die Aufbewahrungsrichtlinien für den Stream konfigurieren, um die Lebensdauer der Statusmeldungen zu steuern. Zum Beispiel:
-
Stellen
PersistenceSieMemorydiese Option ein, wenn Sie die Statusmeldungen nicht speichern möchten. -
Auf
StrategyOnFulleinstellen,OverwriteOldestDatadamit neue Statusmeldungen nicht verloren gehen.
Erstellen oder aktualisieren Sie dann den Exportstream, um den Status-Stream zu verwenden. Legen Sie insbesondere die Statuskonfigurationseigenschaft der S3ExportTaskExecutorConfig Exportkonfiguration des Streams fest. Dadurch wird der Stream-Manager angewiesen, Statusmeldungen über die Exportaufgaben in den Status-Stream zu schreiben. Geben Sie im StatusConfig Objekt den Namen des Status-Streams und den Grad der Ausführlichkeit an. Die folgenden unterstützten Werte reichen von der geringsten Ausführlichkeit (ERROR) bis zur höchsten Ausführlichkeit (). TRACE Der Standardwert ist INFO.
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
Der folgende Beispiel-Workflow zeigt, wie Lambda-Funktionen einen Status-Stream verwenden könnten, um den Exportstatus zu überwachen.
-
Wie im vorherigen Workflow beschrieben, hängt eine Lambda-Funktion eine Exportaufgabe an einen Stream an, der so konfiguriert ist, dass Statusmeldungen über Exportaufgaben in einen Status-Stream geschrieben werden. Die Anfügeoperation gibt eine Sequenznummer zurück, die die Aufgaben-ID darstellt.
-
Eine Lambda-Funktion liest Nachrichten sequentiell aus dem Status-Stream und filtert die Nachrichten dann basierend auf dem Streamnamen und der Task-ID oder basierend auf einer Exportaufgabeneigenschaft aus dem Nachrichtenkontext. Die Lambda-Funktion kann beispielsweise nach der Eingabedatei-URL der Exportaufgabe filtern, die durch das
S3ExportTaskDefinitionObjekt im Nachrichtenkontext dargestellt wird.Die folgenden Statuscodes geben an, dass eine Exportaufgabe den Status „Abgeschlossen“ erreicht hat:
-
Success. Der Upload wurde erfolgreich abgeschlossen. -
Failure. Stream Manager ist auf einen Fehler gestoßen, z. B. ist der angegebene Bucket nicht vorhanden. Nachdem Sie das Problem behoben haben, können Sie die Exportaufgabe erneut an den Stream anhängen. -
Canceled. Die Aufgabe wurde abgebrochen, weil die Stream- oder Exportdefinition gelöscht wurde oder der Zeitraum time-to-live (TTL) der Aufgabe abgelaufen ist.
Anmerkung
Die Aufgabe hat möglicherweise auch den Status oder.
InProgressWarningStream Manager gibt Warnungen aus, wenn ein Ereignis einen Fehler zurückgibt, der die Ausführung der Aufgabe nicht beeinträchtigt. Wenn beispielsweise ein abgebrochener teilweiser Upload nicht bereinigt werden kann, wird eine Warnung zurückgegeben. -
-
Nach Abschluss der Exportaufgaben kann die Lambda-Funktion die entsprechenden Eingabedateien löschen.
Das folgende Beispiel zeigt, wie eine Lambda-Funktion Statusmeldungen lesen und verarbeiten könnte.
