Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Vorbereitung auf Vorfälle im Incident Manager
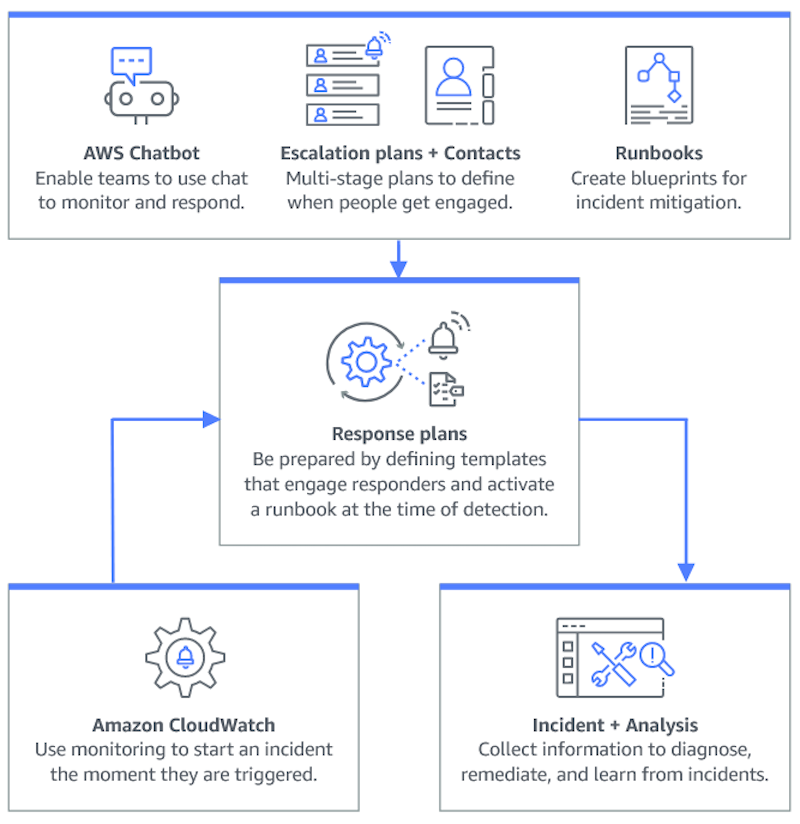
Die Planung eines Vorfalls beginnt lange vor dem Incident-Lebenszyklus. Wie die folgende Abbildung zeigt, bereiten Sie sich darauf vor, auf Vorfälle zu reagieren, indem Sie Chat-Kanäle einrichten, Eskalationspläne erstellen, Kontakte angeben und die Automatisierungs-Runbooks für die Reaktion auf Vorfälle festlegen. Verwenden Sie dann einen Reaktionsplan, der festlegt, wie die Überwachung erfolgt und ob die Reaktionen automatisiert werden. Nach Abschluss der Behebung können Sie den Vorfall und die Reaktion auf den Vorfall analysieren, um Ihren Reaktionsplan für future Vorfälle weiter zu verfeinern.
Themen
Konfiguration von Replikationssätzen und Ergebnissen in Incident Manager
Verwaltung von Responder-Rotationen mit Bereitschaftszeitplänen in Incident Manager
Erstellung eines Eskalationsplans für die Einbindung von Einsatzkräften in Incident Manager
Chat-Kanäle für Einsatzkräfte in Incident Manager erstellen und integrieren
Integration von Systems Manager Automation-Runbooks in Incident Manager zur Behebung von Vorfällen
Reaktionspläne in Incident Manager erstellen und konfigurieren
Überwachen
Die Überwachung des Zustands Ihrer AWS gehosteten Anwendungen ist entscheidend, um die Verfügbarkeit und Leistung Ihrer Anwendungen sicherzustellen. Beachten Sie bei der Auswahl von Überwachungslösungen Folgendes:
-
Kritikalität der Funktion — Wenn das System ausfallen sollte, wie gravierend wären die Auswirkungen auf nachgeschaltete Anwender?
-
Gemeinsamkeit von Ausfällen — Wie häufig fällt ein System aus? Systeme, bei denen häufig eingegriffen werden muss, sollten engmaschig überwacht werden.
-
Höhere Latenz — Um wie viel Zeit bis zur Erledigung einer Aufgabe benötigt wird.
-
Clientseitige und serverseitige Metriken — Wenn es eine Diskrepanz zwischen verwandten Metriken auf dem Client und dem Server gibt.
-
Fehler bei Abhängigkeiten — Fehler, auf die sich Ihr Team vorbereiten kann und sollte.
Nachdem Sie Reaktionspläne erstellt haben, können Sie mithilfe Ihrer Überwachungslösungen Vorfälle automatisch verfolgen, sobald sie in Ihrer Umgebung auftreten. Weitere Informationen zur Nachverfolgung und Erstellung von Vorfällen finden Sie unterVorfalldetails in der Incident Manager-Konsole anzeigen.
