Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwaltung von Berechtigungen für Datensätze, die externe Metastores verwenden
Mit dem AWS Glue Data Catalog Metadatenverbund (Data Catalog Federation) können Sie den Datenkatalog mit externen Metastores verbinden, die Metadaten für Ihre Amazon S3 S3-Daten speichern, und Datenzugriffsberechtigungen mithilfe von AWS Lake Formation sicher verwalten. Sie müssen die Metadaten nicht aus dem externen Metastore in den Datenkatalog migrieren.
Der Datenkatalog bietet ein zentrales Metadaten-Repository, das die Verwaltung und Erkennung von Daten in unterschiedlichen Systemen erleichtert. Wenn Ihre Organisation Daten im Datenkatalog verwaltet, können Sie AWS Lake Formation damit den Zugriff auf Ihre Datensätze in Amazon S3 kontrollieren.
Anmerkung
Derzeit unterstützen wir nur den Apache Hive-Metastore-Verbund (Version 3 und höher).
Um den Datenkatalogverbund einzurichten, stellen wir eine AWS Serverless Application Model (AWS SAM) -Anwendung namens GlueDataCatalogFederation- HiveMetastore
Die Referenzimplementierung wird GitHub als Open-Source-Projekt bei AWS Glue Data Catalog Federation — Hive Metastore
Die AWS SAM Anwendung erstellt und stellt die folgenden Ressourcen bereit, die für die Verbindung des Datenkatalogs mit dem Hive-Metastore erforderlich sind:
Eine AWS Lambda Funktion — Hostet die Implementierung des Verbunddienstes, der zwischen dem Datenkatalog und dem Hive-Metastore kommuniziert. AWS Glue ruft diese Lambda-Funktion auf, um Metadatenobjekte aus dem Hive-Metastore abzurufen.
Amazon API Gateway— Der Verbindungsendpunkt für Ihren Hive-Metastore, der als Proxy fungiert, um alle Aufrufe an die Lambda-Funktion weiterzuleiten.
Eine IAM-Rolle — Eine Rolle mit den erforderlichen Berechtigungen, um die Verbindung zwischen dem Datenkatalog und dem Hive-Metastore herzustellen.
AWS Glue Verbindung — Ein Amazon API Gateway AWS Glue Verbindungstyp, der den Amazon API Gateway Endpunkt und eine IAM-Rolle zum Aufrufen des Endpunkts speichert.
Wenn Sie Tabellen abfragen, ruft der AWS Glue Dienst zur Laufzeit den Hive-Metastore auf und ruft die Metadaten ab. Die Lambda-Funktion fungiert als Übersetzer zwischen dem Hive-Metastore und dem Datenkatalog.
Nachdem Sie die Verbindung hergestellt haben, müssen Sie, um die Metadaten im Hive-Metastore mit dem Datenkatalog zu synchronisieren, eine föderierte Datenbank im Datenkatalog mithilfe der Hive-Metastore-Verbindungsdetails erstellen und diese Datenbank der Hive-Datenbank zuordnen. Eine Datenbank wird als föderierte Datenbank bezeichnet, wenn sie auf eine Entität außerhalb des Datenkatalogs verweist.
Sie können Lake Formation Formation-Berechtigungen mithilfe der tagbasierten Zugriffskontrolle und der Methode der benannten Ressource auf die Verbunddatenbank anwenden und sie für mehrere AWS-Konten AWS Organizations, und Organisationseinheiten () OUs gemeinsam nutzen. Sie können die Verbunddatenbank auch direkt für IAM-Prinzipale von einem anderen Konto aus freigeben.
Mithilfe von Lake Formation Formation-Datenfiltern für die externen Hive-Tabellen können Sie detaillierte Berechtigungen auf Spalten-, Zeilen- und Zellenebene definieren. Sie können Amazon Athena, Amazon Redshift oder Amazon EMR verwenden, um die von Lake Formation verwalteten externen Hive-Tabellen abzufragen.
Weitere Informationen zum kontoübergreifenden Datenaustausch und zur Datenfilterung finden Sie unter:
Allgemeine Schritte zum Zusammenführen von Metadaten im Datenkatalog
-
Sie erstellen IAM-Benutzer und -Rollen, die über die entsprechenden Berechtigungen verfügen, um die AWS SAM Anwendung bereitzustellen und Verbunddatenbanken zu erstellen.
-
Sie registrieren den Amazon S3 S3-Datenstandort bei Lake Formation, indem Sie die
Enable Data Catalog federationOption für Datensätze auswählen, die einen externen Hive-Metastore verwenden. Sie konfigurieren die AWS SAM Anwendungseinstellungen (AWS Glue Verbindungsname, URL zum Hive-Metastore und Lambda-Funktionsparameter) und stellen die Anwendung bereit. AWS SAM
-
Die AWS SAM Anwendung stellt die Ressourcen bereit, die erforderlich sind, um den externen Hive-Metastore mit dem Datenkatalog zu verbinden.
-
Um Lake Formation Formation-Berechtigungen auf die Hive-Datenbank und -Tabellen anzuwenden, erstellen Sie mithilfe der Hive-Metastore-Verbindungsdetails eine Datenbank im Datenkatalog und ordnen diese Datenbank der Hive-Datenbank zu.
Gewähren Sie Principals in Ihrem Konto oder in einem anderen Konto Berechtigungen für die Verbunddatenbanken.
Anmerkung
Sie können den Datenkatalog mit einem externen Hive-Mestastore verbinden, Verbunddatenbanken erstellen und Abfragen und ETL-Skripts für Hive-Datenbanken und -Tabellen ausführen, ohne Lake Formation Formation-Berechtigungen anzuwenden. Für Quelldaten in Amazon S3, die nicht bei Lake Formation registriert sind, wird der Zugriff durch IAM-Berechtigungsrichtlinien für Amazon S3 und AWS Glue Aktionen bestimmt.
Einschränkungen finden Sie unter Überlegungen und Einschränkungen beim Datenaustausch im Hive-Metadatenspeicher.
Themen
Workflow
Das folgende Diagramm zeigt den Arbeitsablauf für die AWS Glue Data Catalog Verbindung mit einem externen Hive-Metastore.
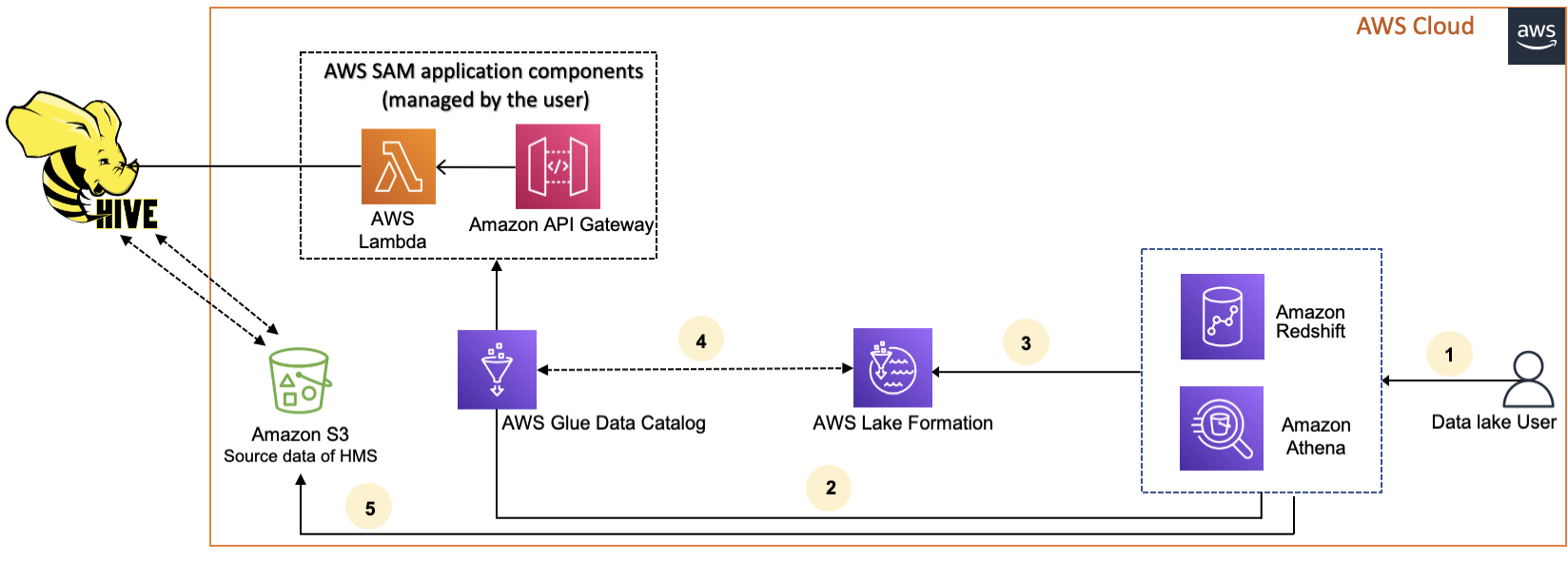
-
Ein Principal sendet eine Anfrage mithilfe eines integrierten Dienstes wie Athena oder Redshift Spectrum.
Der integrierte Dienst ruft den Datenkatalog für die Metadaten auf, der wiederum den dahinter verfügbaren Hive-Metastore-Endpunkt aufruft und Antworten auf Amazon API Gateway Metadatenanfragen erhält.
-
Der integrierte Dienst sendet die Anfrage an Lake Formation, um die Tabelleninformationen und Anmeldeinformationen für den Zugriff auf die Tabelle zu überprüfen.
-
Lake Formation autorisiert die Anfrage und sendet temporäre Anmeldeinformationen an die integrierte Anwendung, die den Datenzugriff ermöglicht.
Unter Verwendung der temporären Anmeldeinformationen, die er von Lake Formation erhalten hat, liest der integrierte Service die Daten aus Amazon S3 und gibt die Ergebnisse an den Principal weiter.
