Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Berechtigungen für Open-Table-Speicherformate in Lake Formation einrichten
AWS Lake Formation unterstützt die Verwaltung von Zugriffsberechtigungen für Open Table Formats (OTFs) wie Apache Iceberg
Anmerkung
AWS Analytics-Services unterstützen nicht alle Transaktionstabellenformate. Weitere Informationen finden Sie unter Zusammenarbeit mit anderen AWS Diensten. In diesem Tutorial wird das manuelle Erstellen einer neuen Datenbank und einer Tabelle im Datenkatalog ausschließlich mithilfe von AWS Glue Jobs behandelt.
Dieses Tutorial enthält eine AWS CloudFormation Vorlage für die schnelle Einrichtung. Sie können es überprüfen und an Ihre Bedürfnisse anpassen.
Themen
Zielgruppe
Dieses Tutorial richtet sich an IAM-Administratoren, Data Lake-Administratoren und Geschäftsanalysten. In der folgenden Tabelle sind die Rollen aufgeführt, die in diesem Tutorial zum Erstellen einer gesteuerten Tabelle mit Lake Formation verwendet werden.
| Rolle | Beschreibung |
|---|---|
| IAM-Administrator | Ein Benutzer, der IAM-Benutzer und -Rollen sowie Amazon S3 S3-Buckets erstellen kann. Hat die AdministratorAccess AWS verwaltete Richtlinie. |
| Data Lake-Administrator | Ein Benutzer, der auf den Datenkatalog zugreifen, Datenbanken erstellen und anderen Benutzern Lake Formation Formation-Berechtigungen gewähren kann. Hat weniger IAM-Berechtigungen als der IAM-Administrator, reicht aber aus, um den Data Lake zu verwalten. |
| Geschäftsanalyst | Ein Benutzer, der Abfragen für den Data Lake ausführen kann. Hat Berechtigungen zum Ausführen von Abfragen. |
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen, benötigen Sie eine AWS-Konto , mit der Sie sich als Benutzer mit den richtigen Berechtigungen anmelden können. Weitere Informationen erhalten Sie unter Melde dich an für ein AWS-Konto und Erstellen eines Benutzers mit Administratorzugriff.
In der Anleitung wird davon ausgegangen, dass Sie mit IAM-Rollen und -Richtlinien vertraut sind. Informationen zu IAM finden Sie im IAM-Benutzerhandbuch.
Sie müssen die folgenden AWS Ressourcen einrichten, um dieses Tutorial abschließen zu können:
Data Lake-Administratorbenutzer
Data Lake-Einstellungen für Lake Formation
Amazon Athena Athena-Engine Version 3
Um einen Data Lake-Administrator zu erstellen
-
Melden Sie sich https://console.aws.amazon.com/lakeformation/
als Administratorbenutzer bei der Lake Formation Formation-Konsole an. Für dieses Tutorial werden Sie Ressourcen in der Region USA Ost (Nord-Virginia) erstellen. -
Wählen Sie in der Lake Formation Formation-Konsole im Navigationsbereich unter Berechtigungen die Option Administrative Rollen und Aufgaben aus.
-
Wählen Sie unter Data Lake-Administratoren die Option Administratoren auswählen aus.
-
Wählen Sie im Popup-Fenster Data Lake-Administratoren verwalten unter IAM-Benutzer und -Rollen die Option IAM-Admin-Benutzer aus.
-
Wählen Sie Save (Speichern) aus.
Um die Data Lake-Einstellungen zu aktivieren
-
Öffnen Sie die Lake Formation Formation-Konsole unter https://console.aws.amazon.com/lakeformation/
. Wählen Sie im Navigationsbereich unter Datenkatalog die Option Einstellungen aus. Deaktivieren Sie Folgendes: Verwenden Sie nur die IAM-Zugriffskontrolle für neue Datenbanken.
-
Verwenden Sie nur die IAM-Zugriffskontrolle für neue Tabellen in neuen Datenbanken.
-
Wählen Sie unter Einstellungen für kontenübergreifende Versionen Version Version 3 als kontoübergreifende Version aus.
-
Wählen Sie Save (Speichern) aus.
Um die Amazon Athena Athena-Engine auf Version 3 zu aktualisieren
-
Öffnen Sie die Athena-Konsole unter. https://console.aws.amazon.com/athena/
-
Wählen Sie die Arbeitsgruppe und anschließend die primäre Arbeitsgruppe aus.
-
Stellen Sie sicher, dass für die Arbeitsgruppe mindestens Version 3 installiert ist. Ist dies nicht der Fall, bearbeiten Sie die Arbeitsgruppe, wählen Sie Manuell für die Upgrade-Abfrage-Engine und wählen Sie Version 3.
Wählen Sie Änderungen speichern.
Schritt 1: Stellen Sie Ihre Ressourcen bereit
In diesem Abschnitt erfahren Sie, wie Sie die AWS Ressourcen mithilfe einer AWS CloudFormation Vorlage einrichten.
Um Ihre Ressourcen mithilfe einer AWS CloudFormation Vorlage zu erstellen
Melden Sie sich bei der AWS CloudFormation Konsole unter https://console.aws.amazon.com/cloudformation
als IAM-Administrator in der Region USA Ost (Nord-Virginia) an. Wählen Sie auf dem Bildschirm „Stack erstellen“ die Option „Weiter“.
Geben Sie einen Stack-Namen ein.
Wählen Sie Weiter.
Wählen Sie auf der nächsten Seite Weiter.
Überprüfen Sie die Details auf der letzten Seite und wählen Sie Ich bestätige, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt werden.
Wählen Sie Create (Erstellen) aus.
Die Erstellung des Stacks kann bis zu zwei Minuten dauern.
Durch das Starten des Cloud-Formation-Stacks werden die folgenden Ressourcen erstellt:
-
lf-otf-datalake-123456789012 — Amazon S3 S3-Bucket zum Speichern von Daten
Anmerkung
Die Konto-ID, die an den Amazon S3 S3-Bucket-Namen angehängt wird, wird durch Ihre Konto-ID ersetzt.
-
lf-otf-tutorial-123456789012 — Amazon S3 S3-Bucket zum Speichern von Abfrageergebnissen und Jobskripten AWS Glue
AWS Glue lficebergdb — Eisberg-Datenbank
lfhudidb — AWS Glue Hudi-Datenbank
-
lfdeltadb — AWS Glue Delta-Datenbank
native-iceberg-create — AWS Glue Job, der eine Iceberg-Tabelle im Datenkatalog erstellt
native-hudi-create — AWS Glue Job, der eine Hudi-Tabelle im Datenkatalog erstellt
-
native-delta-create — AWS Glue Job, der eine Delta-Tabelle im Datenkatalog erstellt
LF-OTF-GlueServiceRole — IAM-Rolle, an die Sie übergeben, AWS Glue um die Jobs auszuführen. Dieser Rolle sind die erforderlichen Richtlinien für den Zugriff auf Ressourcen wie Data Catalog, Amazon S3 S3-Bucket usw. zugeordnet.
LF-OTF-RegisterRole — IAM-Rolle zur Registrierung des Amazon S3 S3-Standorts bei Lake Formation. Diese Rolle wurde mit
LF-Data-Lake-Storage-Policyder Rolle verknüpft.lf-consumer-analystuser — IAM-Benutzer zur Abfrage der Daten mit Athena
-
lf-consumer-analystuser-credentials — Passwort für den Data Analyst-Benutzer, gespeichert in AWS Secrets Manager
Nachdem die Stack-Erstellung abgeschlossen ist, navigieren Sie zur Registerkarte „Ausgabe“ und notieren Sie sich die Werte für:
AthenaQueryResultLocation — Amazon S3 S3-Standort für die Athena-Abfrageausgabe
BusinessAnalystUserCredentials — Passwort für den Data Analyst-Benutzer
Um den Passwortwert abzurufen:
Wählen Sie den
lf-consumer-analystuser-credentialsWert aus, indem Sie zur Secrets Manager Manager-Konsole navigieren.Wählen Sie im Bereich Secret value (Secret-Wert) die Option Retrieve secret value (Secret-Wert abrufen).
Notieren Sie sich den geheimen Wert für das Passwort.
Schritt 2: Richten Sie Berechtigungen für eine Iceberg-Tabelle ein
In diesem Abschnitt erfahren Sie, wie Sie eine Iceberg-Tabelle in Amazon Athena erstellen AWS Glue Data Catalog, Datenberechtigungen einrichten und Daten mit Amazon Athena abfragen. AWS Lake Formation
Um eine Iceberg-Tabelle zu erstellen
In diesem Schritt führen Sie einen AWS Glue Job aus, der eine Iceberg-Transaktionstabelle im Datenkatalog erstellt.
-
Öffnen Sie AWS Glue Konsole https://console.aws.amazon.com/glue/
in der Region USA Ost (Nord-Virginia) als Data Lake-Administratorbenutzer. -
Wählen Sie im linken Navigationsbereich Jobs aus.
-
Wählen Sie
native-iceberg-create.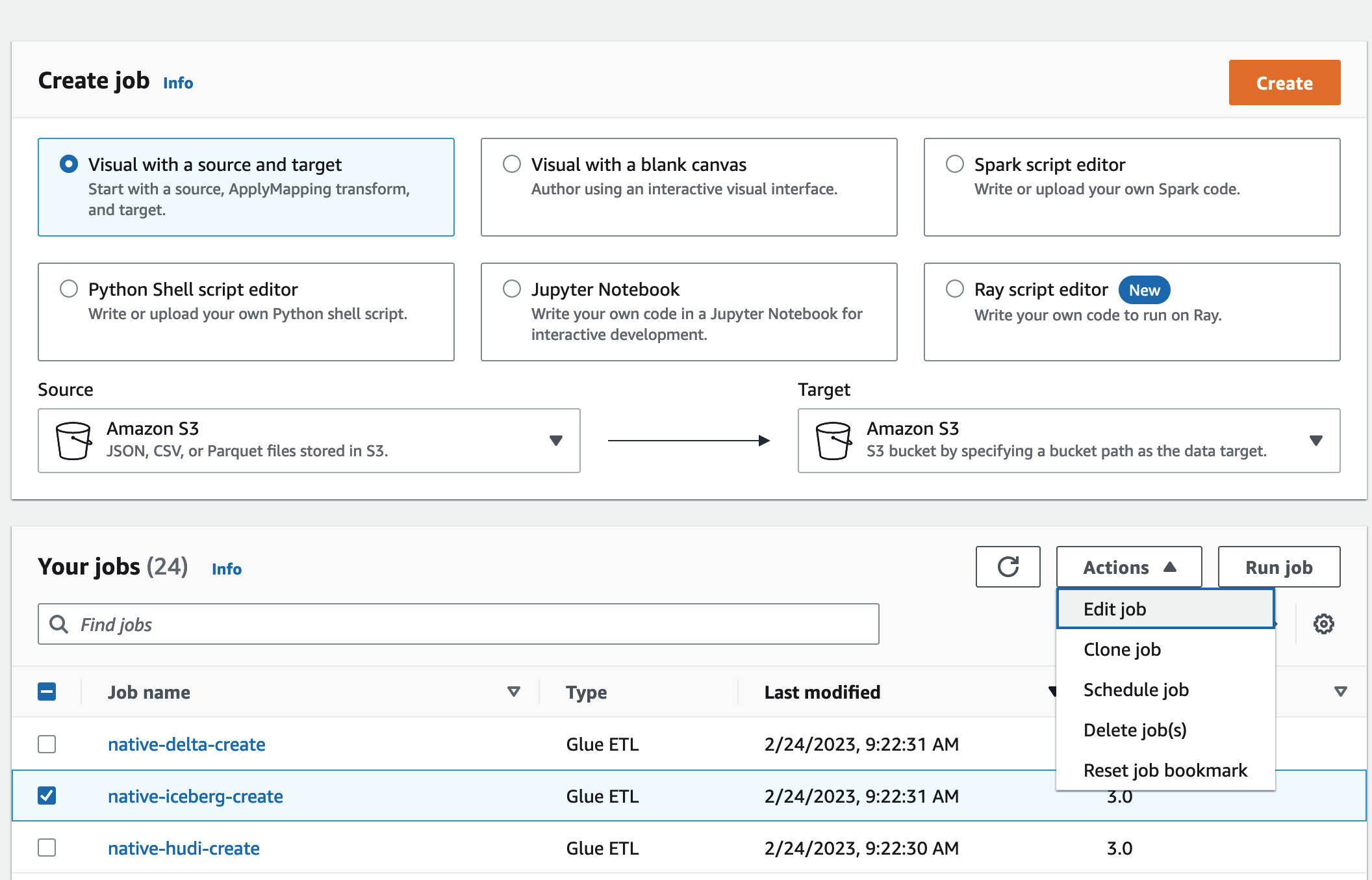
-
Wählen Sie unter Aktionen die Option Job bearbeiten aus.
-
Erweitern Sie unter Jobdetails die Option Erweiterte Eigenschaften und aktivieren Sie das Kästchen neben Als Hive-Metastore verwenden AWS Glue Data Catalog , um die Tabellenmetadaten in der hinzuzufügen. AWS Glue Data Catalog Dies wird AWS Glue Data Catalog als Metastore für die im Job verwendeten Datenkatalogressourcen angegeben und ermöglicht, dass Lake Formation Formation-Berechtigungen später auf die Katalogressourcen angewendet werden.
Wählen Sie Save (Speichern) aus.
-
Wählen Sie Ausführen aus. Sie können den Status des Jobs anzeigen, während er ausgeführt wird.
Weitere Informationen zu AWS Glue Jobs finden Sie im AWS Glue Developer Guide unter Arbeiten mit Jobs auf der AWS Glue Konsole.
Dieser Job erstellt eine
productin derlficebergdbDatenbank benannte Iceberg-Tabelle. Überprüfen Sie die Produkttabelle in der Lake Formation Formation-Konsole.
Um den Datenstandort bei Lake Formation zu registrieren
Als Nächstes registrieren Sie den Amazon S3 S3-Pfad als Standort Ihres Data Lakes.
-
Öffnen Sie die Lake Formation Formation-Konsole unter https://console.aws.amazon.com/lakeformation/
als Data Lake-Administratorbenutzer. Wählen Sie im Navigationsbereich unter Registrieren und aufnehmen die Option Datenspeicherort aus.
Wählen Sie oben rechts in der Konsole die Option Speicherort registrieren aus.
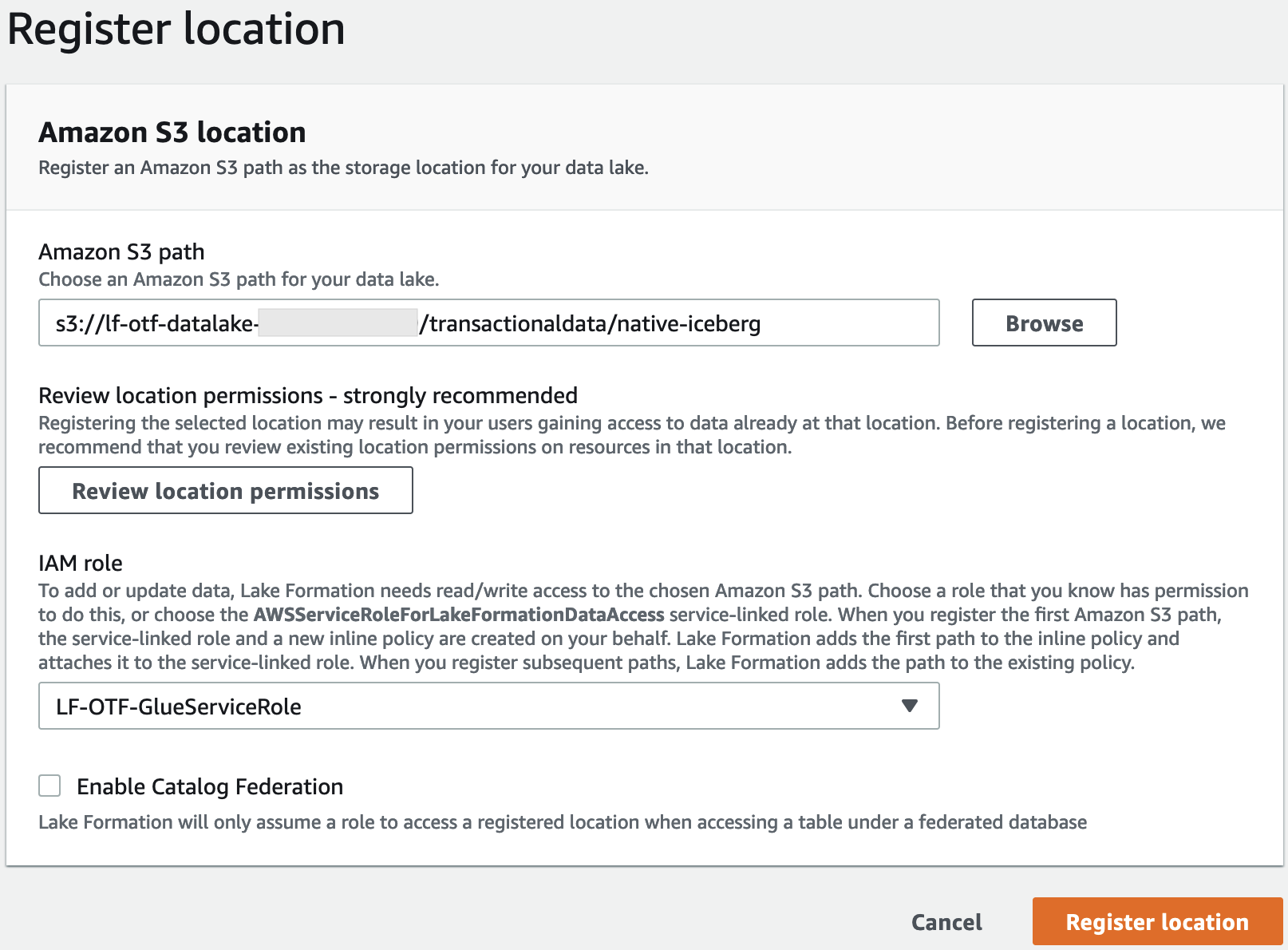
Geben Sie auf der Seite Speicherort registrieren Folgendes ein:
-
Amazon S3 S3-Pfad — Wählen Sie Durchsuchen und wählen Sie aus
lf-otf-datalake-123456789012. Klicken Sie auf den Rechtspfeil (>) neben dem Amazon S3 S3-Stammverzeichnis, um zums3/buckets/lf-otf-datalake-123456789012/transactionaldata/native-icebergSpeicherort zu navigieren. -
IAM-Rolle — Wählen Sie
LF-OTF-RegisterRoleals IAM-Rolle aus. Wählen Sie Standort registrieren.
Weitere Informationen zur Registrierung eines Datenstandorts bei Lake Formation finden Sie unterHinzufügen eines Amazon S3 S3-Standorts zu Ihrem Data Lake.
-
Um Lake Formation Formation-Berechtigungen für die Iceberg-Tabelle zu erteilen
In diesem Schritt erteilen wir dem Business Analyst-Benutzer Data Lake-Berechtigungen.
Wählen Sie unter Data Lake-Berechtigungen die Option Grant aus.
Wählen Sie auf dem Bildschirm Datenberechtigungen gewähren die Option IAM-Benutzer und -Rollen aus.
-
Wählen Sie
lf-consumer-analystuseraus dem Drop-down-Menü aus.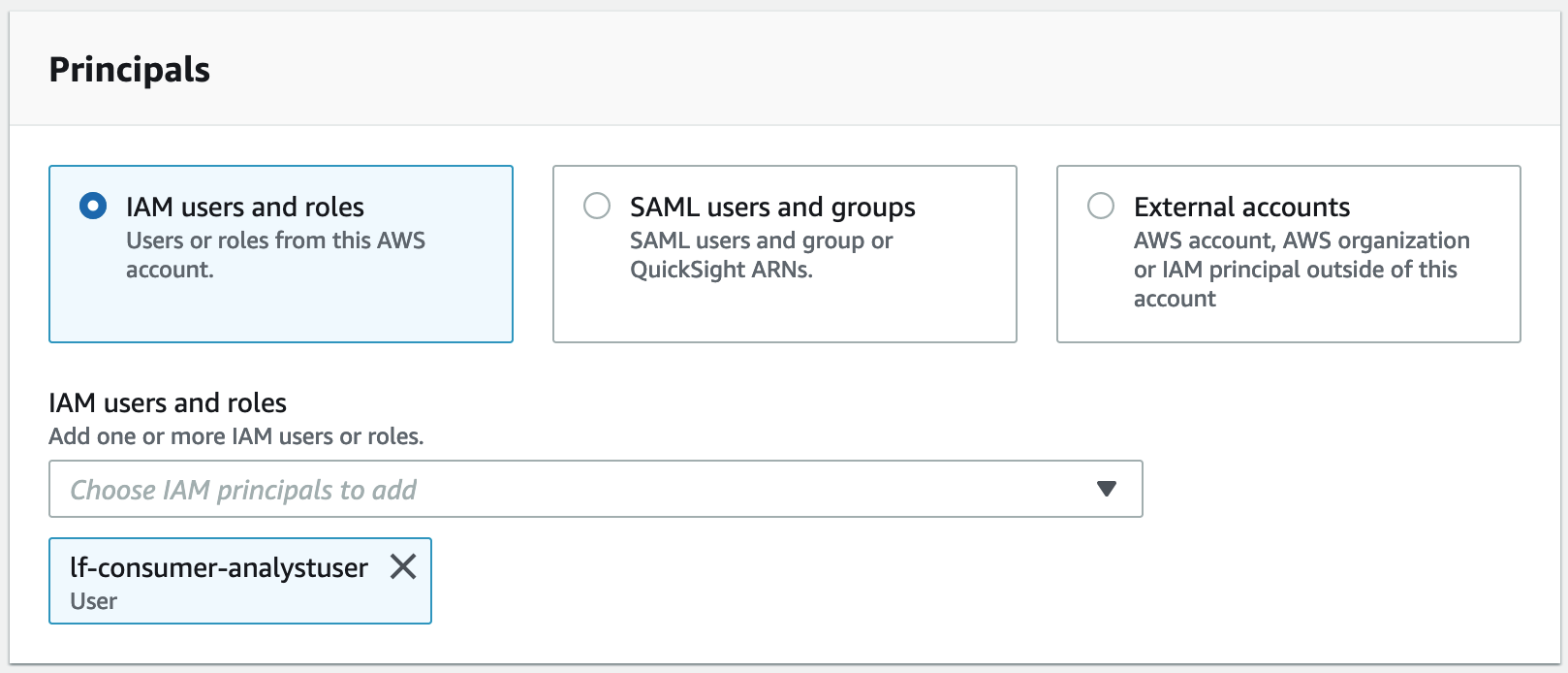
Wählen Sie Benannte Datenkatalogressource aus.
Wählen Sie für Datenbanken
lficebergdb.Wählen Sie für Tabellen die Option
product.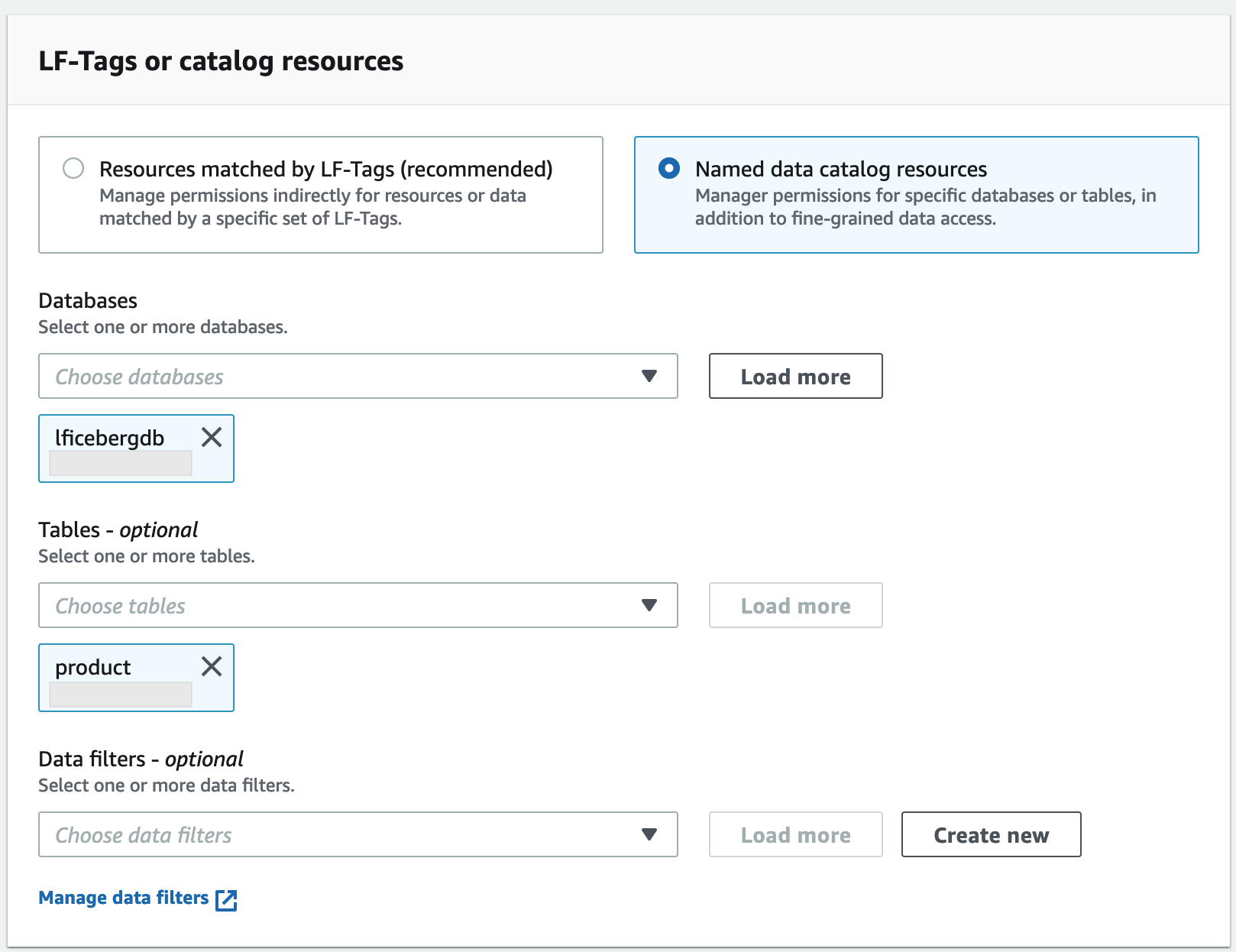
Als Nächstes können Sie spaltenbasierten Zugriff gewähren, indem Sie Spalten angeben.
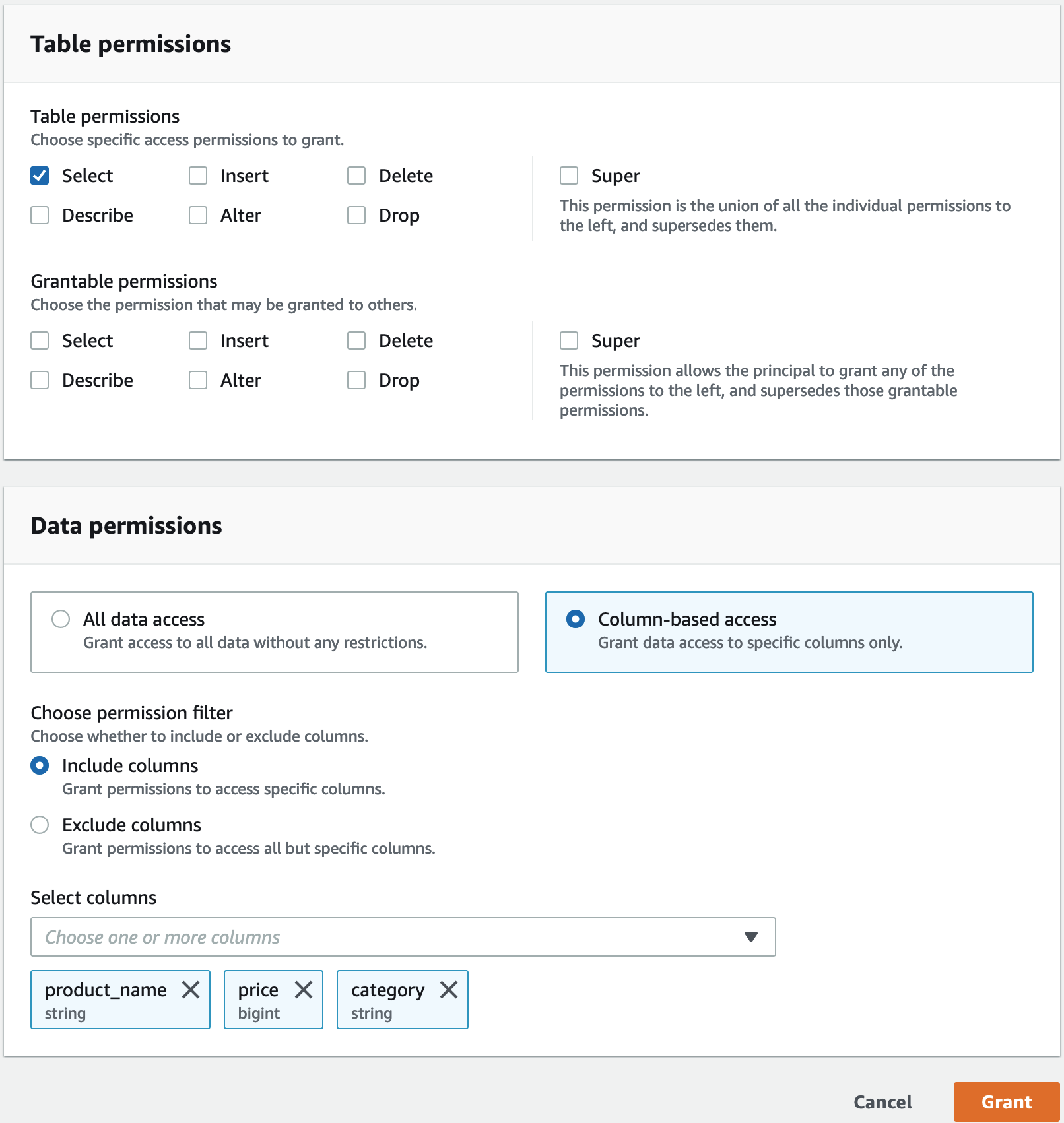
Wählen Sie unter Tabellenberechtigungen die Option Auswählen aus.
Wählen Sie unter Datenberechtigungen die Option Spaltenbasierter Zugriff und dann Spalten einbeziehen aus.
Wählen Sie
product_nameprice, undcategorySpalten aus.Wählen Sie Grant (Erteilen).
Um die Iceberg-Tabelle mit Athena abzufragen
Jetzt können Sie mit der Abfrage der Iceberg-Tabelle beginnen, die Sie mit Athena erstellt haben. Wenn Sie zum ersten Mal Abfragen in Athena ausführen, müssen Sie einen Speicherort für Abfrageergebnisse konfigurieren. Weitere Informationen finden Sie unter Angeben eines Speicherorts für Abfrageergebnisse.
Melden Sie sich als Data Lake-Administratorbenutzer ab und melden Sie sich mit dem zuvor
lf-consumer-analystuserin der AWS CloudFormation Ausgabe angegebenen Kennwort als Benutzer in der Region USA Ost (Nord-Virginia) an.Öffnen Sie die Athena-Konsole unter https://console.aws.amazon.com/athena/
. Wählen Sie Einstellungen und anschließend Verwalten aus.
Geben Sie im Feld Speicherort des Abfrageergebnisses den Pfad zu dem Bucket ein, den Sie in AWS CloudFormation Ausgaben erstellt haben. Kopieren Sie den Wert von
AthenaQueryResultLocation(s3://lf-otf-tutorial-123456789012/athena-results/) und wählen Sie Speichern.Führen Sie die folgende Abfrage aus, um eine Vorschau von 10 in der Iceberg-Tabelle gespeicherten Datensätzen anzuzeigen:
select * from lficebergdb.product limit 10;Weitere Informationen zum Abfragen von Iceberg-Tabellen mit Athena finden Sie unter Abfragen von Iceberg-Tabellen im Amazon Athena Athena-Benutzerhandbuch.
Schritt 3: Richten Sie Berechtigungen für eine Hudi-Tabelle ein
In diesem Abschnitt erfahren Sie, wie Sie eine Hudi-Tabelle in Amazon Athena erstellen AWS Glue Data Catalog, Datenberechtigungen einrichten und Daten mit Amazon Athena abfragen. AWS Lake Formation
Um eine Hudi-Tabelle zu erstellen
In diesem Schritt führen Sie einen AWS Glue Job aus, der eine Hudi-Transaktionstabelle im Datenkatalog erstellt.
-
Melden Sie sich an bei AWS Glue Konsole unter https://console.aws.amazon.com/glue/
in der Region USA Ost (Nord-Virginia) als Data Lake-Administratorbenutzer.
-
Wählen Sie im linken Navigationsbereich Jobs aus.
-
Wählen Sie
native-hudi-create. -
Wählen Sie unter Aktionen die Option Job bearbeiten aus.
-
Erweitern Sie unter Jobdetails die Option Erweiterte Eigenschaften und aktivieren Sie das Kästchen neben Als Hive-Metastore verwenden AWS Glue Data Catalog , um die Tabellenmetadaten in der hinzuzufügen. AWS Glue Data Catalog Dies wird AWS Glue Data Catalog als Metastore für die im Job verwendeten Datenkatalogressourcen angegeben und ermöglicht, dass Lake Formation Formation-Berechtigungen später auf die Katalogressourcen angewendet werden.
Wählen Sie Save (Speichern) aus.
-
Wählen Sie Ausführen aus. Sie können den Status des Jobs anzeigen, während er ausgeführt wird.
Weitere Informationen zu AWS Glue Jobs finden Sie im AWS Glue Developer Guide unter Arbeiten mit Jobs auf der AWS Glue Konsole.
Dieser Job erstellt eine Hudi-Tabelle (cow) in der Datenbank:lfhudidb. Überprüfen Sie die
productTabelle in der Lake Formation Formation-Konsole.
Um den Datenstandort bei Lake Formation zu registrieren
Als Nächstes registrieren Sie einen Amazon S3 S3-Pfad als Stammverzeichnis Ihres Data Lakes.
-
Melden Sie sich https://console.aws.amazon.com/lakeformation/
als Data Lake-Administratorbenutzer bei der Lake Formation Formation-Konsole an. Wählen Sie im Navigationsbereich unter Registrieren und aufnehmen die Option Datenspeicherort aus.
Wählen Sie oben rechts in der Konsole die Option Speicherort registrieren aus.
Geben Sie auf der Seite Speicherort registrieren Folgendes ein:
-
Amazon S3 S3-Pfad — Wählen Sie Durchsuchen und wählen Sie aus
lf-otf-datalake-123456789012. Klicken Sie auf den Rechtspfeil (>) neben dem Amazon S3 S3-Stammverzeichnis, um zums3/buckets/lf-otf-datalake-123456789012/transactionaldata/native-hudiSpeicherort zu navigieren. -
IAM-Rolle — Wählen Sie
LF-OTF-RegisterRoleals IAM-Rolle aus. Wählen Sie Standort registrieren.
-
Um Data Lake-Berechtigungen für die Hudi-Tabelle zu gewähren
In diesem Schritt gewähren wir dem Business Analyst-Benutzer Data-Lake-Berechtigungen.
Wählen Sie unter Data Lake-Berechtigungen die Option Grant aus.
Wählen Sie auf dem Bildschirm Datenberechtigungen gewähren die Option IAM-Benutzer und -Rollen aus.
-
lf-consumer-analystuseraus dem Drop-down-Menü. Wählen Sie Benannte Datenkatalogressource aus.
Wählen Sie für Datenbanken
lfhudidb.Wählen Sie für Tabellen die Option
product.Als Nächstes können Sie spaltenbasierten Zugriff gewähren, indem Sie Spalten angeben.
Wählen Sie unter Tabellenberechtigungen die Option Auswählen aus.
Wählen Sie unter Datenberechtigungen die Option Spaltenbasierter Zugriff und dann Spalten einbeziehen aus.
Wählen Sie
product_nameprice, undcategorySpalten aus.Wählen Sie Grant (Erteilen).
Um die Hudi-Tabelle mit Athena abzufragen
Beginnen Sie nun mit der Abfrage der Hudi-Tabelle, die Sie mit Athena erstellt haben. Wenn Sie zum ersten Mal Abfragen in Athena ausführen, müssen Sie einen Speicherort für Abfrageergebnisse konfigurieren. Weitere Informationen finden Sie unter Angeben eines Speicherorts für Abfrageergebnisse.
Melden Sie sich als Data Lake-Administratorbenutzer ab und melden Sie sich mit dem zuvor
lf-consumer-analystuserin der AWS CloudFormation Ausgabe angegebenen Kennwort als Benutzer in der Region USA Ost (Nord-Virginia) an.Öffnen Sie die Athena-Konsole unter https://console.aws.amazon.com/athena/
. Wählen Sie Einstellungen und anschließend Verwalten aus.
Geben Sie im Feld Speicherort des Abfrageergebnisses den Pfad zu dem Bucket ein, den Sie in AWS CloudFormation Ausgaben erstellt haben. Kopieren Sie den Wert von
AthenaQueryResultLocation(s3://lf-otf-tutorial-123456789012/athena-results/) und speichern Sie.Führen Sie die folgende Abfrage aus, um eine Vorschau von 10 in der Hudi-Tabelle gespeicherten Datensätzen anzuzeigen:
select * from lfhudidb.product limit 10;Weitere Informationen zum Abfragen von Hudi-Tabellen finden Sie im Abschnitt Abfragen von Hudi-Tabellen im Amazon Athena Athena-Benutzerhandbuch.
Schritt 4: Richten Sie Berechtigungen für eine Delta Lake-Tabelle ein
In diesem Abschnitt erfahren Sie, wie Sie eine Delta Lake-Tabelle mit einer Symlink-Manifestdatei in der erstellen AWS Glue Data Catalog, Datenberechtigungen in Amazon Athena einrichten AWS Lake Formation und Daten mit Amazon Athena abfragen.
So erstellen Sie eine Delta Lake-Tabelle
In diesem Schritt führen Sie einen AWS Glue Job aus, der eine Delta Lake-Transaktionstabelle im Datenkatalog erstellt.
-
Melden Sie sich an bei AWS Glue Konsole unter https://console.aws.amazon.com/glue/
in der Region USA Ost (Nord-Virginia) als Data Lake-Administratorbenutzer.
-
Wählen Sie im linken Navigationsbereich Jobs aus.
-
Wählen Sie
native-delta-create. -
Wählen Sie unter Aktionen die Option Job bearbeiten aus.
-
Erweitern Sie unter Jobdetails die Option Erweiterte Eigenschaften und aktivieren Sie das Kästchen neben Als Hive-Metastore verwenden AWS Glue Data Catalog , um die Tabellenmetadaten in der hinzuzufügen. AWS Glue Data Catalog Dies wird AWS Glue Data Catalog als Metastore für die im Job verwendeten Datenkatalogressourcen angegeben und ermöglicht, dass Lake Formation Formation-Berechtigungen später auf die Katalogressourcen angewendet werden.
Wählen Sie Save (Speichern) aus.
-
Wählen Sie unter Aktionen die Option Ausführen aus.
Dieser Job erstellt eine Delta Lake-Tabelle mit dem Namen
productin derlfdeltadbDatenbank. Überprüfen Sie dieproductTabelle in der Lake Formation Formation-Konsole.
Um den Datenstandort bei Lake Formation zu registrieren
Als Nächstes registrieren Sie den Amazon S3 S3-Pfad als Stammverzeichnis Ihres Data Lakes.
-
Öffnen Sie die Lake Formation Formation-Konsole https://console.aws.amazon.com/lakeformation/
beim Data Lake-Administratorbenutzer. Wählen Sie im Navigationsbereich unter Registrieren und aufnehmen die Option Datenspeicherort aus.
Wählen Sie oben rechts in der Konsole die Option Speicherort registrieren aus.
Geben Sie auf der Seite Speicherort registrieren Folgendes ein:
-
Amazon S3 S3-Pfad — Wählen Sie Durchsuchen und wählen Sie aus
lf-otf-datalake-123456789012. Klicken Sie auf den Rechtspfeil (>) neben dem Amazon S3 S3-Stammverzeichnis, um zums3/buckets/lf-otf-datalake-123456789012/transactionaldata/native-deltaSpeicherort zu navigieren. -
IAM-Rolle — Wählen Sie
LF-OTF-RegisterRoleals IAM-Rolle aus. Wählen Sie Standort registrieren.
-
Um Data Lake-Berechtigungen für die Delta Lake-Tabelle zu erteilen
In diesem Schritt erteilen wir dem Business Analyst-Benutzer Data-Lake-Berechtigungen.
Wählen Sie unter Data Lake-Berechtigungen die Option Grant aus.
Wählen Sie auf dem Bildschirm Datenberechtigungen gewähren die Option IAM-Benutzer und -Rollen aus.
-
lf-consumer-analystuseraus dem Drop-down-Menü. Wählen Sie Benannte Datenkatalogressource aus.
Wählen Sie für Datenbanken
lfdeltadb.Wählen Sie für Tabellen die Option
product.Als Nächstes können Sie spaltenbasierten Zugriff gewähren, indem Sie Spalten angeben.
Wählen Sie unter Tabellenberechtigungen die Option Auswählen aus.
Wählen Sie unter Datenberechtigungen die Option Spaltenbasierter Zugriff und dann Spalten einbeziehen aus.
Wählen Sie
product_nameprice, undcategorySpalten aus.Wählen Sie Grant (Erteilen).
Um die Delta Lake-Tabelle mit Athena abzufragen
Beginnen Sie nun mit der Abfrage der Delta Lake-Tabelle, die Sie mit Athena erstellt haben. Wenn Sie zum ersten Mal Abfragen in Athena ausführen, müssen Sie einen Speicherort für Abfrageergebnisse konfigurieren. Weitere Informationen finden Sie unter Angeben eines Speicherorts für Abfrageergebnisse.
Melden Sie sich als Data Lake-Administratorbenutzer ab und melden Sie sich mit dem zuvor
BusinessAnalystUserin der AWS CloudFormation Ausgabe angegebenen Kennwort in der Region USA Ost (Nord-Virginia) an.Öffnen Sie die Athena-Konsole unter https://console.aws.amazon.com/athena/
. Wählen Sie Einstellungen und anschließend Verwalten aus.
Geben Sie im Feld Speicherort des Abfrageergebnisses den Pfad zu dem Bucket ein, den Sie in AWS CloudFormation Ausgaben erstellt haben. Kopieren Sie den Wert von
AthenaQueryResultLocation(s3://lf-otf-tutorial-123456789012/athena-results/) und speichern Sie.Führen Sie die folgende Abfrage aus, um eine Vorschau von 10 in der Delta Lake-Tabelle gespeicherten Datensätzen anzuzeigen:
select * from lfdeltadb.product limit 10;Weitere Informationen zur Abfrage von Delta Lake-Tabellen finden Sie im Abschnitt Abfragen von Delta Lake-Tabellen im Amazon Athena Athena-Benutzerhandbuch.
Schritt 5: Ressourcen bereinigen AWS
So bereinigen Sie Ressourcen
Um zu verhindern, dass Ihnen unerwünschte Kosten entstehen AWS-Konto, löschen Sie die AWS Ressourcen, die Sie für dieses Tutorial verwendet haben.
-
Melden Sie sich als AWS CloudFormation IAM-Administrator bei der Konsole unter https://console.aws.amazon.com/cloudformation
an. -
Löschen Sie den Cloud Formation Stack. Die von Ihnen erstellten Tabellen werden automatisch mit dem Stack gelöscht.
