Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Behebung von Konfigurationsproblemen in Lambda
Ihre Einstellungen für die Funktionskonfiguration können sich auf die Gesamtleistung und das Verhalten Ihrer Lambda-Funktion auswirken. Diese führen möglicherweise nicht zu tatsächlichen Funktionsfehlern, können jedoch zu unerwarteten Timeouts und Ergebnissen führen.
Die folgenden Themen enthalten Hinweise zur Fehlerbehebung bei häufig auftretenden Problemen im Zusammenhang mit den Einstellungen der Lambda-Funktionskonfiguration.
Themen
Arbeitsspeicherkonfigurationen
Sie können eine Lambda-Funktion so konfigurieren, dass sie zwischen 128 MB und 10.240 MB Speicher verwendet. Standardmäßig wird jeder in der Konsole erstellten Funktion die kleinste Speichermenge zugewiesen. Viele Lambda-Funktionen sind bei dieser niedrigsten Einstellung performant. Wenn Sie jedoch große Codebibliotheken importieren oder speicherintensive Aufgaben ausführen, reichen 128 MB nicht aus.
Wenn Ihre Funktionen viel langsamer als erwartet ausgeführt werden, besteht der erste Schritt darin, die Speichereinstellung zu erhöhen. So können Sie die Funktion Ihres Handlers nutzen, um die Leistung Ihrer Funktion zu verbessern.
CPU-gebundene Konfigurationen
Wenn Ihre Funktion bei rechenintensiven Vorgängen slower-than-expected leistungsfähig ist, kann dies daran liegen, dass Ihre Funktion CPU-gebunden ist. In diesem Fall kann die Berechnungskapazität der Funktion nicht mit der Arbeit Schritt halten.
Lambda erlaubt Ihnen zwar nicht, die CPU-Konfiguration direkt zu ändern, aber die CPU wird indirekt über die Speichereinstellungen gesteuert. Der Lambda-Dienst weist proportional mehr virtuelle CPU zu, wenn Sie mehr Arbeitsspeicher zuweisen. Bei 1,8 GB Arbeitsspeicher ist einer Lambda-Funktion eine gesamte vCPU zugewiesen, und ab dieser Stufe hat sie Zugriff auf mehr als einen vCPU-Kern. Bei einer Größe von 10.240 MB stehen 6 V zur Verfügung. CPUs Mit anderen Worten, Sie können die Leistung verbessern, indem Sie die Speicherzuweisung erhöhen, auch wenn die Funktion nicht den gesamten Speicher verwendet.
Timeouts
Timeouts für Lambda-Funktionen können zwischen 1 und 900 Sekunden (15 Minuten) eingestellt werden. Standardmäßig legt die Lambda-Konsole diesen Wert auf 3 Sekunden fest. Der Timeout-Wert ist ein Sicherheitsventil, das sicherstellt, dass Funktionen nicht unbegrenzt ausgeführt werden. Nachdem der Timeout-Wert erreicht ist, stoppt Lambda den Funktionsaufruf.
Wenn ein Timeout-Wert nahe der durchschnittlichen Dauer einer Funktion festgelegt wird, erhöht sich das Risiko, dass die Funktion unerwartet abbricht. Die Dauer einer Funktion kann je nach Umfang der Datenübertragung und -verarbeitung sowie der Latenz aller Dienste, mit denen die Funktion interagiert, variieren. Zu den häufigsten Ursachen für Timeouts gehören:
-
Beim Herunterladen von Daten aus S3-Buckets oder anderen Datenspeichern ist der Download größer oder dauert länger als im Durchschnitt.
-
Eine Funktion sendet eine Anfrage an einen anderen Service, dessen Beantwortung länger dauert.
-
Die einer Funktion zur Verfügung gestellten Parameter erfordern eine höhere Rechenkomplexität in der Funktion, wodurch der Aufruf länger dauert.
Stellen Sie beim Testen Ihrer Anwendung sicher, dass Ihre Tests die Größe und Menge der Daten sowie realistische Parameterwerte genau wiedergeben. Wichtig ist, dass Sie Datensätze verwenden, die sich an der Obergrenze dessen befinden, was für Ihre Arbeitslast vernünftigerweise zu erwarten ist.
Implementieren Sie außerdem, wo immer dies praktikabel ist, Obergrenzen für Ihren Workload. In diesem Beispiel könnte die Anwendung für jeden Dateityp eine maximale Größenbeschränkung verwenden. Anschließend können Sie die Leistung Ihrer Anwendung für eine Reihe erwarteter Dateigrößen bis einschließlich der Höchstgrenzen testen.
Speicherlecks zwischen Aufrufen
Globale Variablen und Objekte, die in der INIT-Phase eines Lambda-Aufrufs gespeichert sind, behalten ihren Status zwischen warmen Aufrufen bei. Sie werden erst vollständig zurückgesetzt, wenn die Ausführungsumgebung zum ersten Mal ausgeführt wird (auch als „Kaltstart“ bezeichnet). Alle im Handler gespeicherten Variablen werden zerstört, wenn der Handler beendet wird. Die INIT-Phase wird am besten zum Einrichten von Datenbankverbindungen, Laden von Bibliotheken, Erstellen von Caches und Laden unveränderlicher Assets verwendet.
Wenn Sie Bibliotheken von Drittanbietern für mehrere Aufrufe in derselben Ausführungsumgebung verwenden, überprüfen Sie deren Dokumentation zur Verwendung in einer serverlosen Computerumgebung. Einige Bibliotheken für Datenbankverbindungen und Protokollierung speichern möglicherweise Zwischenaufrufergebnisse und andere Daten. Dies führt dazu, dass der Speicherverbrauch dieser Bibliotheken mit nachfolgenden Warmaufrufen zunimmt. Wenn dies der Fall ist, stellen Sie möglicherweise fest, dass der Lambda-Funktion nicht genügend Speicher zur Verfügung steht, auch wenn Ihr benutzerdefinierter Code Variablen korrekt entsorgt.
Dieses Problem betrifft Aufrufe, die in warmen Ausführungsumgebungen auftreten. Der folgende Code erzeugt beispielsweise ein Speicherleck zwischen Aufrufen. Die Lambda-Funktion verbraucht bei jedem Aufruf zusätzlichen Speicher, indem sie die Größe eines globalen Arrays erhöht:
let a = []
exports.handler = async (event) => {
a.push(Array(100000).fill(1))
}
Bei Konfiguration mit 128 MB Arbeitsspeicher werden auf der Registerkarte Überwachung der Lambda-Funktion nach 1000-maligem Aufruf die typischen Änderungen der Aufrufe, der Dauer und der Fehleranzahl angezeigt, wenn ein Speicherleck auftritt:

-
Aufrufe — Eine konstante Transaktionsrate wird regelmäßig unterbrochen, da die Aufrufe länger dauern. Im eingeschwungenen Zustand verbraucht das Speicherleck nicht den gesamten der Funktion zugewiesenen Speicher. Wenn die Leistung abnimmt, paginiert das Betriebssystem den lokalen Speicher, um den wachsenden Speicherbedarf der Funktion zu decken, was dazu führt, dass weniger Transaktionen abgeschlossen werden.
-
Dauer — Bevor der Funktion der Speicherplatz ausgeht, beendet sie Aufrufe mit einer konstanten zweistelligen Millisekundenrate. Wenn ein Paging stattfindet, verlängert sich die Dauer um eine Größenordnung.
-
Anzahl der Fehler — Wenn der Speicherverlust den zugewiesenen Speicher übersteigt, kommt es irgendwann zu Funktionsfehlern, die darauf zurückzuführen sind, dass die Berechnung das Timeout überschreitet, oder die Ausführungsumgebung stoppt die Funktion.
Nach dem Fehler startet Lambda die Ausführungsumgebung neu, was erklärt, warum alle drei Diagramme eine Rückkehr zum ursprünglichen Zustand anzeigen. Wenn Sie die CloudWatch Messwerte für die Dauer erweitern, erhalten Sie mehr Details für die Statistiken zur Mindest-, Höchst- und Durchschnittsdauer:

Um die Fehler zu finden, die bei den 1000 Aufrufen generiert wurden, können Sie die CloudWatch Insights-Abfragesprache verwenden. Die folgende Abfrage schließt Informationsprotokolle aus, um nur die Fehler zu melden:
fields @timestamp, @message | sort @timestamp desc | filter @message not like 'EXTENSION' | filter @message not like 'Lambda Insights' | filter @message not like 'INFO' | filter @message not like 'REPORT' | filter @message not like 'END' | filter @message not like 'START'
Ein Abgleich mit der Protokollgruppe für diese Funktion zeigt, dass Zeitüberschreitungen für die periodischen Fehler verantwortlich waren:

Asynchrone Ergebnisse wurden bei einem späteren Aufruf zurückgegeben
Bei Funktionscode, der asynchrone Muster verwendet, ist es möglich, dass die Callback-Ergebnisse eines Aufrufs in einem zukünftigen Aufruf zurückgegeben werden. In diesem Beispiel wird Node.js verwendet, aber dieselbe Logik kann auch auf andere Laufzeiten angewendet werden, die asynchrone Muster verwenden. Die Funktion verwendet die traditionelle Callback-Syntax in. JavaScript Sie ruft eine asynchrone Funktion mit einem inkrementellen Zähler auf, der die Anzahl der Aufrufe verfolgt:
let seqId = 0 exports.handler = async (event, context) => { console.log(`Starting: sequence Id=${++seqId}`) doWork(seqId, function(id) { console.log(`Work done: sequence Id=${id}`) }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }
Wenn sie mehrmals hintereinander aufgerufen werden, treten die Ergebnisse der Callbacks bei nachfolgenden Aufrufen auf:

-
Der Code ruft die
doWorkFunktion auf und stellt eine Callback-Funktion als letzten Parameter bereit. -
Es dauert einige Zeit, bis die
doWorkFunktion abgeschlossen ist, bevor der Callback aufgerufen wird. -
Die Protokollierung der Funktion gibt an, dass der Aufruf beendet wird, bevor die Ausführung der
doWorkFunktion abgeschlossen ist. Darüber hinaus werden nach dem Start einer Iteration Callbacks aus früheren Iterationen verarbeitet, wie in den Protokollen gezeigt.
In JavaScript werden asynchrone Callbacks mit einer Ereignisschleife behandelt.
Dadurch besteht die Möglichkeit, dass private Daten aus einem früheren Aufruf in einem späteren Aufruf erscheinen. Es gibt zwei Möglichkeiten, die Funktion Ihres Handlers aufzuweisen. JavaScript Stellt zunächst die Schlüsselwörter async und await
let seqId = 0 exports.handler = async (event) => { console.log(`Starting: sequence Id=${++seqId}`) const result = await doWork(seqId) console.log(`Work done: sequence Id=${result}`) } function doWork(id) { return new Promise(resolve => { setTimeout(() => resolve(id), 4000) }) }
Die Verwendung dieser Syntax verhindert, dass der Handler beendet wird, bevor die asynchrone Funktion beendet ist. Wenn in diesem Fall der Callback länger dauert als das Timeout der Lambda-Funktion, gibt die Funktion einen Fehler aus, anstatt das Callback-Ergebnis bei einem späteren Aufruf zurückzugeben:
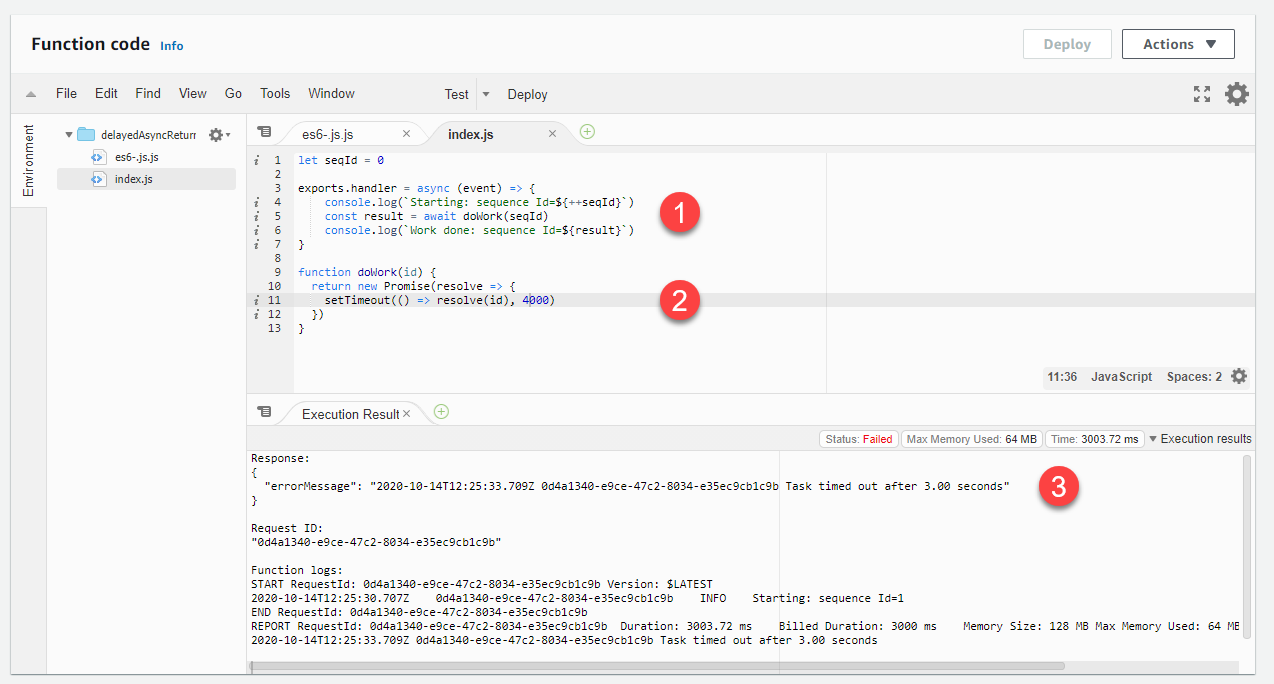
-
Der Code ruft die asynchrone
doWorkFunktion mithilfe des Schlüsselworts await im Handler auf. -
Es dauert einige Zeit, bis die
doWorkFunktion abgeschlossen ist, bevor das Versprechen aufgelöst wird. -
Bei der Funktion kommt es zu einem Timeout, weil es länger
doWorkdauert, als es das Timeout-Limit zulässt, und das Callback-Ergebnis bei einem späteren Aufruf nicht zurückgegeben wird.
Im Allgemeinen sollten Sie sicherstellen, dass alle Hintergrundprozesse oder Rückrufe im Code abgeschlossen sind, bevor der Code beendet wird. Wenn dies in Ihrem Anwendungsfall nicht möglich ist, können Sie einen Bezeichner verwenden, um sicherzustellen, dass der Rückruf zum aktuellen Aufruf gehört. Dazu können Sie das vom Kontext awsRequestIdbereitgestellte Objekt verwenden. Indem Sie diesen Wert an den asynchronen Callback übergeben, können Sie den übergebenen Wert mit dem aktuellen Wert vergleichen, um festzustellen, ob der Callback von einem anderen Aufruf stammt:
let currentContext exports.handler = async (event, context) => { console.log(`Starting: request id=$\{context.awsRequestId}`) currentContext = context doWork(context.awsRequestId, function(id) { if (id != currentContext.awsRequestId) { console.info(`This callback is from another invocation.`) } }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }

-
Der Lambda-Funktionshandler verwendet den Kontextparameter, der Zugriff auf eine eindeutige Aufrufanforderungs-ID ermöglicht.
-
Das
awsRequestIdwird an die DoWork-Funktion übergeben. Im Callback wird die ID mit derawsRequestIddes aktuellen Aufrufs verglichen. Wenn diese Werte unterschiedlich sind, kann der Code entsprechende Maßnahmen ergreifen.
