Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Learning to Rank für Amazon OpenSearch Service
OpenSearch verwendet ein probabilistisches Ranking-Framework namens BM-25, um Relevanzbewertungen zu berechnen. Wenn ein markantes Schlüsselwort häufiger in einem Dokument erscheint, weist BM-25 diesem Dokument eine höhere Relevanzbewertung zu. Dieses Framework berücksichtigt jedoch Benutzerverhalten wie Click-Through-Daten nicht, was die Relevanz weiter verbessern könnte.
Learning to Rank ist ein Open-Source-Plug-In, mit dem Sie mittels Machine Learning und Verhaltensdaten die Relevanz von Dokumenten optimieren können. Es verwendet Modelle aus den XGBoost und Ranklib-Bibliotheken, um die Suchergebnisse erneut zu bewerten. Das Elasticsearch-LTR-Plugin
Für Learning to Rank ist Elasticsearch 7.7 oder höher erforderlich OpenSearch . Um das Plug-In „Learning to Rank“ verwenden zu können, benötigen Sie volle Administratorberechtigungen. Weitere Informationen hierzu finden Sie unter Hauptbenutzer ändern.
Anmerkung
Diese Dokumentation bietet einen allgemeinen Überblick über das Learning to Rank-Plugin und hilft Ihnen bei den ersten Schritten. Die vollständige Dokumentation, einschließlich detaillierter Schritte und API-Beschreibungen, finden Sie in der Dokumentation Learning to Rank
Erste Schritte mit Learning to Rank
Sie müssen eine Urteilsliste bereitstellen, einen Schulungsdatensatz vorbereiten und das Modell außerhalb von Amazon OpenSearch Service trainieren. Die blauen Teile kommen außerhalb von OpenSearch Service vor:
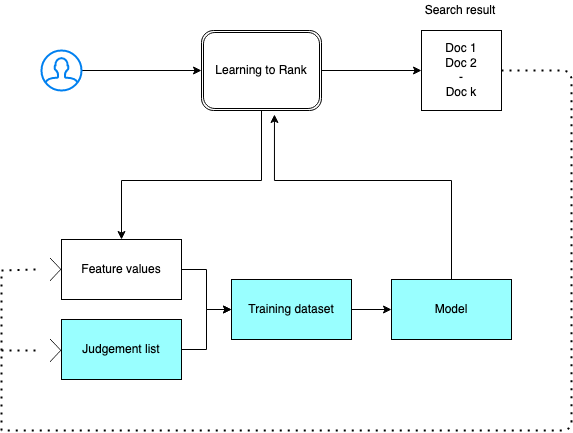
Schritt 1: Initialisieren des Plug-Ins
Um das Learning-to-Rank-Plug-In zu initialisieren, senden Sie die folgende Anfrage an Ihre OpenSearch Service-Domäne:
PUT _ltr
{ "acknowledged" : true, "shards_acknowledged" : true, "index" : ".ltrstore" }
Mit diesem Befehl wird ein ausgeblendeter .ltrstore-Index erstellt, in dem Metadateninformationen wie Funktions-Sets und Modelle gespeichert werden.
Schritt 2: Erstellen einer Urteilliste
Anmerkung
Sie müssen diesen Schritt außerhalb von OpenSearch Service ausführen.
Eine Urteilsliste ist eine Sammlung von Beispielen, von denen ein Machine-Learning-Modell lernt. Ihre Urteilsliste sollte Schlüsselwörter enthalten, die für Sie wichtig sind und eine Reihe von bewerteten Dokumenten für jedes Schlüsselwort.
In diesem Beispiel haben wir eine Urteilsliste für einen Film-Datensatz. Eine Bewertung von 4 weist auf eine perfekte Übereinstimmung hin. Eine Bewertung von 0 gibt die schlechteste Übereinstimmung an.
| Bewertung | Stichwort | Dokument-ID | Filmname |
|---|---|---|---|
| 4 | rambo | 7555 | Rambo |
| 3 | rambo | 1370 | Rambo III |
| 3 | rambo | 1369 | Rambo: First Blood Teil II |
| 3 | rambo | 1368 | First Blood |
Erstellen Sie Ihre Urteilsliste im folgenden Format:
4 qid:1 # 7555 Rambo 3 qid:1 # 1370 Rambo III 3 qid:1 # 1369 Rambo: First Blood Part II 3 qid:1 # 1368 First Blood where qid:1 represents "rambo"
Ein umfassendes Beispiel für eine Urteilliste finden Sie unter Film-Urteile
Sie können diese Urteilsliste manuell mit Hilfe von menschlichen Kommentatoren erstellen oder sie programmgesteuert aus Analysedaten ableiten.
Schritt 3: Erstellen eines Funktionssets
Eine Funktion ist ein Feld, das der Relevanz eines Dokuments entspricht, z. B. title, overview, popularity score (Anzahl der Ansichten) usw.
Erstellen Sie für jede Funktion einen Funktionssatz mit einer Mustache-Vorlage. Weitere Informationen zu Funktionen finden Sie unter Arbeiten mit Funktionen
In diesem Beispiel erstellen wir einen movie_features-Funktionssatz mit den Feldern title undoverview:
POST _ltr/_featureset/movie_features { "featureset" : { "name" : "movie_features", "features" : [ { "name" : "1", "params" : [ "keywords" ], "template_language" : "mustache", "template" : { "match" : { "title" : "{{keywords}}" } } }, { "name" : "2", "params" : [ "keywords" ], "template_language" : "mustache", "template" : { "match" : { "overview" : "{{keywords}}" } } } ] } }
Wenn Sie den ursprünglichen .ltrstore-Index verwenden, erhalten Sie Ihren Funktionsatz zurück:
GET _ltr/_featureset
Schritt 4: Protokollieren der Funktionswerte
Die Funktionswerte sind die Relevanzwerte, die von BM-25 für jede Funktion berechnet werden.
Kombinieren Sie den Funktionsatz und die Beurteilungsliste, um die Funktionswerte zu protokollieren. Weitere Informationen zur Protokollierung finden Sie unter Protokollieren von Funktionssätzen
In diesem Beispiel ruft die bool-Abfrage die bewerteten Dokumente mit dem Filter ab und wählt dann den Funktionssatz mit der sltr-Abfrage aus. Die ltr_log-Abfrage kombiniert die Dokumente und die Funktionen, um die entsprechenden Funktionswerte zu protokollieren:
POST tmdb/_search { "_source": { "includes": [ "title", "overview" ] }, "query": { "bool": { "filter": [ { "terms": { "_id": [ "7555", "1370", "1369", "1368" ] } }, { "sltr": { "_name": "logged_featureset", "featureset": "movie_features", "params": { "keywords": "rambo" } } } ] } }, "ext": { "ltr_log": { "log_specs": { "name": "log_entry1", "named_query": "logged_featureset" } } } }
Eine Beispielantwort kann wie folgt aussehen:
{ "took" : 7, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : 0.0, "hits" : [ { "_index" : "tmdb", "_type" : "movie", "_id" : "1368", "_score" : 0.0, "_source" : { "overview" : "When former Green Beret John Rambo is harassed by local law enforcement and arrested for vagrancy, the Vietnam vet snaps, runs for the hills and rat-a-tat-tats his way into the action-movie hall of fame. Hounded by a relentless sheriff, Rambo employs heavy-handed guerilla tactics to shake the cops off his tail.", "title" : "First Blood" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1" }, { "name" : "2", "value" : 10.558305 } ] } ] }, "matched_queries" : [ "logged_featureset" ] }, { "_index" : "tmdb", "_type" : "movie", "_id" : "7555", "_score" : 0.0, "_source" : { "overview" : "When governments fail to act on behalf of captive missionaries, ex-Green Beret John James Rambo sets aside his peaceful existence along the Salween River in a war-torn region of Thailand to take action. Although he's still haunted by violent memories of his time as a U.S. soldier during the Vietnam War, Rambo can hardly turn his back on the aid workers who so desperately need his help.", "title" : "Rambo" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1", "value" : 11.2569065 }, { "name" : "2", "value" : 9.936821 } ] } ] }, "matched_queries" : [ "logged_featureset" ] }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1369", "_score" : 0.0, "_source" : { "overview" : "Col. Troutman recruits ex-Green Beret John Rambo for a highly secret and dangerous mission. Teamed with Co Bao, Rambo goes deep into Vietnam to rescue POWs. Deserted by his own team, he's left in a hostile jungle to fight for his life, avenge the death of a woman and bring corrupt officials to justice.", "title" : "Rambo: First Blood Part II" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1", "value" : 6.334839 }, { "name" : "2", "value" : 10.558305 } ] } ] }, "matched_queries" : [ "logged_featureset" ] }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1370", "_score" : 0.0, "_source" : { "overview" : "Combat has taken its toll on Rambo, but he's finally begun to find inner peace in a monastery. When Rambo's friend and mentor Col. Trautman asks for his help on a top secret mission to Afghanistan, Rambo declines but must reconsider when Trautman is captured.", "title" : "Rambo III" }, "fields" : { "_ltrlog" : [ { "log_entry1" : [ { "name" : "1", "value" : 9.425955 }, { "name" : "2", "value" : 11.262714 } ] } ] }, "matched_queries" : [ "logged_featureset" ] } ] } }
Im vorherigen Beispiel hat die erste Funktion keinen Funktionswert, da das Schlüsselwort „rambo“ nicht im Titelfeld des Dokuments mit einer ID 1368 angezeigt wird. Dies ist ein fehlender Funktionswert in den Trainingsdaten.
Schritt 5: Erstellen eines Trainingdatensatzes
Anmerkung
Sie müssen diesen Schritt außerhalb von OpenSearch Service ausführen.
Der nächste Schritt besteht darin, die Beurteilungsliste und die Funktionswerte zu kombinieren, um einen Trainingsdatensatz zu erstellen. Wenn Ihre ursprüngliche Urteilsliste wie folgt aussieht:
4 qid:1 # 7555 Rambo 3 qid:1 # 1370 Rambo III 3 qid:1 # 1369 Rambo: First Blood Part II 3 qid:1 # 1368 First Blood
Konvertieren Sie sie in den abschließenden Trainingsdatensatz, der wie folgt aussieht:
4 qid:1 1:12.318474 2:10.573917 # 7555 rambo 3 qid:1 1:10.357875 2:11.950391 # 1370 rambo 3 qid:1 1:7.010513 2:11.220095 # 1369 rambo 3 qid:1 1:0.0 2:11.220095 # 1368 rambo
Sie können diesen Schritt manuell ausführen oder ein Programm schreiben, um es zu automatisieren.
Schritt 6: Einen Algorithmus auswählen und das Modell erstellen
Anmerkung
Sie müssen diesen Schritt außerhalb von OpenSearch Service ausführen.
Wenn der Trainingsdatensatz vorhanden ist, besteht der nächste Schritt darin, Ranklib-Bibliotheken zum Erstellen eines Modells zu verwenden XGBoost . XGBoost Mit Ranklib-Bibliotheken können Sie beliebte Modelle wie LambdaMart, Random Forest usw. erstellen.
Anweisungen zur Verwendung XGBoost von Ranklib zum Erstellen des Modells finden Sie in der jeweiligen Dokumentation. XGBoostRankLib
Schritt 7: Bereitstellen des Modells
Nachdem Sie das Modell erstellt haben, stellen Sie es im Plug-In „Learning to Rank“ bereit. Weitere Informationen zur Bereitstellung eines Modells finden Sie unter Hochladen eines trainierten Modells
In diesem Beispiel erstellen wir ein my_ranklib_model-Modell mit der Ranklib-Bibliothek:
POST _ltr/_featureset/movie_features/_createmodel?pretty { "model": { "name": "my_ranklib_model", "model": { "type": "model/ranklib", "definition": """## LambdaMART ## No. of trees = 10 ## No. of leaves = 10 ## No. of threshold candidates = 256 ## Learning rate = 0.1 ## Stop early = 100 <ensemble> <tree id="1" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-2.0</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-2.0</output> </split> <split pos="right"> <output>-2.0</output> </split> </split> </split> <split pos="right"> <output>2.0</output> </split> </split> </tree> <tree id="2" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.67031991481781</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-1.67031991481781</output> </split> <split pos="right"> <output>-1.6703200340270996</output> </split> </split> </split> <split pos="right"> <output>1.6703201532363892</output> </split> </split> </tree> <tree id="3" weight="0.1"> <split> <feature>2</feature> <threshold>10.573917</threshold> <split pos="left"> <output>1.479954481124878</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.4799546003341675</output> </split> <split pos="right"> <output>-1.479954481124878</output> </split> </split> <split pos="right"> <output>-1.479954481124878</output> </split> </split> </split> </tree> <tree id="4" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.3569872379302979</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-1.3569872379302979</output> </split> <split pos="right"> <output>-1.3569872379302979</output> </split> </split> </split> <split pos="right"> <output>1.3569873571395874</output> </split> </split> </tree> <tree id="5" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.2721362113952637</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <output>-1.2721363306045532</output> </split> <split pos="right"> <output>-1.2721363306045532</output> </split> </split> </split> <split pos="right"> <output>1.2721362113952637</output> </split> </split> </tree> <tree id="6" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.2110036611557007</output> </split> <split pos="right"> <output>-1.2110036611557007</output> </split> </split> <split pos="right"> <output>-1.2110037803649902</output> </split> </split> <split pos="right"> <output>1.2110037803649902</output> </split> </split> </tree> <tree id="7" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.165616512298584</output> </split> <split pos="right"> <output>-1.165616512298584</output> </split> </split> <split pos="right"> <output>-1.165616512298584</output> </split> </split> <split pos="right"> <output>1.165616512298584</output> </split> </split> </tree> <tree id="8" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.131177544593811</output> </split> <split pos="right"> <output>-1.131177544593811</output> </split> </split> <split pos="right"> <output>-1.131177544593811</output> </split> </split> <split pos="right"> <output>1.131177544593811</output> </split> </split> </tree> <tree id="9" weight="0.1"> <split> <feature>2</feature> <threshold>10.573917</threshold> <split pos="left"> <output>1.1046180725097656</output> </split> <split pos="right"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.1046180725097656</output> </split> <split pos="right"> <output>-1.1046180725097656</output> </split> </split> <split pos="right"> <output>-1.1046180725097656</output> </split> </split> </split> </tree> <tree id="10" weight="0.1"> <split> <feature>1</feature> <threshold>10.357875</threshold> <split pos="left"> <feature>1</feature> <threshold>7.010513</threshold> <split pos="left"> <feature>1</feature> <threshold>0.0</threshold> <split pos="left"> <output>-1.0838804244995117</output> </split> <split pos="right"> <output>-1.0838804244995117</output> </split> </split> <split pos="right"> <output>-1.0838804244995117</output> </split> </split> <split pos="right"> <output>1.0838804244995117</output> </split> </split> </tree> </ensemble> """ } } }
Um das Modell zu sehen, senden Sie die folgende Anfrage:
GET _ltr/_model/my_ranklib_model
Schritt 8: Suchen mit Learning to Rank
Nach der Bereitstellung des Modells können Sie suchen.
Führen Sie die sltr-Abfrage mit den verwendeten Funktionen und dem Namen des Modells aus, das Sie ausführen möchten:
POST tmdb/_search { "_source": { "includes": ["title", "overview"] }, "query": { "multi_match": { "query": "rambo", "fields": ["title", "overview"] } }, "rescore": { "query": { "rescore_query": { "sltr": { "params": { "keywords": "rambo" }, "model": "my_ranklib_model" } } } } }
Mit „Learning to Ranking“ sehen Sie „Rambo“ als erstes Ergebnis, da wir ihm die höchste Bewertung in der Urteilsliste zugewiesen haben:
{ "took" : 12, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 7, "relation" : "eq" }, "max_score" : 13.096414, "hits" : [ { "_index" : "tmdb", "_type" : "movie", "_id" : "7555", "_score" : 13.096414, "_source" : { "overview" : "When governments fail to act on behalf of captive missionaries, ex-Green Beret John James Rambo sets aside his peaceful existence along the Salween River in a war-torn region of Thailand to take action. Although he's still haunted by violent memories of his time as a U.S. soldier during the Vietnam War, Rambo can hardly turn his back on the aid workers who so desperately need his help.", "title" : "Rambo" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1370", "_score" : 11.17245, "_source" : { "overview" : "Combat has taken its toll on Rambo, but he's finally begun to find inner peace in a monastery. When Rambo's friend and mentor Col. Trautman asks for his help on a top secret mission to Afghanistan, Rambo declines but must reconsider when Trautman is captured.", "title" : "Rambo III" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1368", "_score" : 10.442155, "_source" : { "overview" : "When former Green Beret John Rambo is harassed by local law enforcement and arrested for vagrancy, the Vietnam vet snaps, runs for the hills and rat-a-tat-tats his way into the action-movie hall of fame. Hounded by a relentless sheriff, Rambo employs heavy-handed guerilla tactics to shake the cops off his tail.", "title" : "First Blood" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1369", "_score" : 10.442155, "_source" : { "overview" : "Col. Troutman recruits ex-Green Beret John Rambo for a highly secret and dangerous mission. Teamed with Co Bao, Rambo goes deep into Vietnam to rescue POWs. Deserted by his own team, he's left in a hostile jungle to fight for his life, avenge the death of a woman and bring corrupt officials to justice.", "title" : "Rambo: First Blood Part II" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "31362", "_score" : 7.424202, "_source" : { "overview" : "It is 1985, and a small, tranquil Florida town is being rocked by a wave of vicious serial murders and bank robberies. Particularly sickening to the authorities is the gratuitous use of violence by two “Rambo” like killers who dress themselves in military garb. Based on actual events taken from FBI files, the movie depicts the Bureau’s efforts to track down these renegades.", "title" : "In the Line of Duty: The F.B.I. Murders" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "13258", "_score" : 6.43182, "_source" : { "overview" : """Will Proudfoot (Bill Milner) is looking for an escape from his family's stifling home life when he encounters Lee Carter (Will Poulter), the school bully. Armed with a video camera and a copy of "Rambo: First Blood", Lee plans to make cinematic history by filming his own action-packed video epic. Together, these two newfound friends-turned-budding-filmmakers quickly discover that their imaginative ― and sometimes mishap-filled ― cinematic adventure has begun to take on a life of its own!""", "title" : "Son of Rambow" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "61410", "_score" : 3.9719706, "_source" : { "overview" : "It's South Africa 1990. Two major events are about to happen: The release of Nelson Mandela and, more importantly, it's Spud Milton's first year at an elite boys only private boarding school. John Milton is a boy from an ordinary background who wins a scholarship to a private school in Kwazulu-Natal, South Africa. Surrounded by boys with nicknames like Gecko, Rambo, Rain Man and Mad Dog, Spud has his hands full trying to adapt to his new home. Along the way Spud takes his first tentative steps along the path to manhood. (The path it seems could be a rather long road). Spud is an only child. He is cursed with parents from well beyond the lunatic fringe and a senile granny. His dad is a fervent anti-communist who is paranoid that the family domestic worker is running a shebeen from her room at the back of the family home. His mom is a free spirit and a teenager's worst nightmare, whether it's shopping for Spud's underwear in the local supermarket", "title" : "Spud" } } ] } }
Wenn Sie suchen, ohne das Plug-In „Learning to Rank“ zu verwenden, werden verschiedene Ergebnisse OpenSearch zurückgegeben:
POST tmdb/_search { "_source": { "includes": ["title", "overview"] }, "query": { "multi_match": { "query": "Rambo", "fields": ["title", "overview"] } } }
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : 11.262714, "hits" : [ { "_index" : "tmdb", "_type" : "movie", "_id" : "1370", "_score" : 11.262714, "_source" : { "overview" : "Combat has taken its toll on Rambo, but he's finally begun to find inner peace in a monastery. When Rambo's friend and mentor Col. Trautman asks for his help on a top secret mission to Afghanistan, Rambo declines but must reconsider when Trautman is captured.", "title" : "Rambo III" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "7555", "_score" : 11.2569065, "_source" : { "overview" : "When governments fail to act on behalf of captive missionaries, ex-Green Beret John James Rambo sets aside his peaceful existence along the Salween River in a war-torn region of Thailand to take action. Although he's still haunted by violent memories of his time as a U.S. soldier during the Vietnam War, Rambo can hardly turn his back on the aid workers who so desperately need his help.", "title" : "Rambo" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1368", "_score" : 10.558305, "_source" : { "overview" : "When former Green Beret John Rambo is harassed by local law enforcement and arrested for vagrancy, the Vietnam vet snaps, runs for the hills and rat-a-tat-tats his way into the action-movie hall of fame. Hounded by a relentless sheriff, Rambo employs heavy-handed guerilla tactics to shake the cops off his tail.", "title" : "First Blood" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "1369", "_score" : 10.558305, "_source" : { "overview" : "Col. Troutman recruits ex-Green Beret John Rambo for a highly secret and dangerous mission. Teamed with Co Bao, Rambo goes deep into Vietnam to rescue POWs. Deserted by his own team, he's left in a hostile jungle to fight for his life, avenge the death of a woman and bring corrupt officials to justice.", "title" : "Rambo: First Blood Part II" } }, { "_index" : "tmdb", "_type" : "movie", "_id" : "13258", "_score" : 6.4600153, "_source" : { "overview" : """Will Proudfoot (Bill Milner) is looking for an escape from his family's stifling home life when he encounters Lee Carter (Will Poulter), the school bully. Armed with a video camera and a copy of "Rambo: First Blood", Lee plans to make cinematic history by filming his own action-packed video epic. Together, these two newfound friends-turned-budding-filmmakers quickly discover that their imaginative ― and sometimes mishap-filled ― cinematic adventure has begun to take on a life of its own!""", "title" : "Son of Rambow" } } ] } }
Passen Sie die Beurteilungsliste und die Funktionen an, je nachdem, wie gut das Modell Ihrer Meinung nach funktioniert. Wiederholen Sie anschließend die Schritte 2 bis 8, um die Ranglistenergebnisse im Laufe der Zeit zu verbessern.
Learning-to-Rank-API
Verwenden Sie die Operationen „Learning to Rank“, um programmgesteuert mit Funktionssätzen und Modellen zu arbeiten.
Shop erstellen
Es wird ein ausgeblendeter .ltrstore-Index erstellt, in dem Metadateninformationen wie Funktionssätze und Modelle gespeichert werden.
PUT _ltr
Shop löschen
Löscht den versteckten .ltrstore-Index und setzt das Plug-In zurück.
DELETE _ltr
Erstellen eines Funktionssatzes
Erstellt einen Funktionssatz.
POST _ltr/_featureset/<name_of_features>
Löschen eines Funktionssatzes
Löscht einen Funktionssatz.
DELETE _ltr/_featureset/<name_of_feature_set>
Abrufen eines Funktionssatzes
Ruft einen Funktionssatz ab.
GET _ltr/_featureset/<name_of_feature_set>
Erstellen eines Modells
Erstellt ein Modell.
POST _ltr/_featureset/<name_of_feature_set>/_createmodel
Löschen eines Modells
Löscht ein Modell.
DELETE _ltr/_model/<name_of_model>
Abrufen eines Modells
Ruft ein Modell ab.
GET _ltr/_model/<name_of_model>
Statistiken abrufen
Enthält Informationen darüber, wie sich das Plug-In verhält.
GET _ltr/_stats
Sie können auch Filter verwenden, um eine einzelne Statistik abzurufen:
GET _ltr/_stats/<stat>
Darüber hinaus können Sie die Informationen auf einen einzelnen Knoten im Cluster beschränken:
GET _ltr/_stats/<stat>/nodes/<nodeId> { "_nodes" : { "total" : 1, "successful" : 1, "failed" : 0 }, "cluster_name" : "873043598401:ltr-77", "stores" : { ".ltrstore" : { "model_count" : 1, "featureset_count" : 1, "feature_count" : 2, "status" : "green" } }, "status" : "green", "nodes" : { "DjelK-_ZSfyzstO5dhGGQA" : { "cache" : { "feature" : { "eviction_count" : 0, "miss_count" : 0, "entry_count" : 0, "memory_usage_in_bytes" : 0, "hit_count" : 0 }, "featureset" : { "eviction_count" : 2, "miss_count" : 2, "entry_count" : 0, "memory_usage_in_bytes" : 0, "hit_count" : 0 }, "model" : { "eviction_count" : 2, "miss_count" : 3, "entry_count" : 1, "memory_usage_in_bytes" : 3204, "hit_count" : 1 } }, "request_total_count" : 6, "request_error_count" : 0 } } }
Die Statistiken werden auf zwei Ebenen, Knoten und Cluster, bereitgestellt, wie in den folgenden Tabellen angegeben:
| Feldname | Beschreibung |
|---|---|
| request_total_count | Gesamtzahl der Ranking-Anforderungen. |
| request_error_count | Gesamtzahl der fehlgeschlagenen Anforderungen. |
| Cache | Statistiken über alle Caches hinweg (Funktionen, Funktionssätze, Modelle). Ein Cache-Treffer tritt auf, wenn ein Benutzer das Plug-In abfragt und das Modell bereits in den Speicher geladen ist. |
| cache.eviction_count | Anzahl der Cache-Bereinigungen. |
| cache.hit_count | Anzahl der Cache-Treffer. |
| cache.miss_count | Anzahl der Cache-Fehler. Ein Cache-Fehler tritt auf, wenn ein Benutzer das Plug-In abfragt und das Modell noch nicht in den Speicher geladen ist. |
| cache.entry_count | Anzahl der Einträge im Cache. |
| cache.memory_usage_in_bytes | Gesamtspeicher, der in Bytes verwendet wird. |
| cache.cache_capacity_reached | Gibt an, ob das Cache-Limit erreicht ist. |
| Feldname | Beschreibung |
|---|---|
| stores | Gibt an, wo die Funktionssätze und Modellmetadaten gespeichert werden. (Der Standardwert ist „.ltrstore“. Andernfalls wird „.ltrstore_“ mit einem vom Benutzer angegebenen Namen vorangestellt). |
| stores.status | Der Indexstatus. |
| stores.feature_sets | Anzahl der Funktionssätze. |
| stores.features_count | Anzahl der Funktionen. |
| stores.model_count | Anzahl der Modelle. |
| Status | Der Plug-In-Status basierend auf dem Status der Funktionsspeicher-Indizes (rot, gelb oder grün) und des Leistungsschalterstatus (offen oder geschlossen). |
| cache.cache_capacity_reached | Gibt an, ob das Cache-Limit erreicht ist. |
Cache-Statistiken abrufen
Gibt Statistiken über den Cache und die Speichernutzung zurück.
GET _ltr/_cachestats { "_nodes": { "total": 2, "successful": 2, "failed": 0 }, "cluster_name": "opensearch-cluster", "all": { "total": { "ram": 612, "count": 1 }, "features": { "ram": 0, "count": 0 }, "featuresets": { "ram": 612, "count": 1 }, "models": { "ram": 0, "count": 0 } }, "stores": { ".ltrstore": { "total": { "ram": 612, "count": 1 }, "features": { "ram": 0, "count": 0 }, "featuresets": { "ram": 612, "count": 1 }, "models": { "ram": 0, "count": 0 } } }, "nodes": { "ejF6uutERF20wOFNOXB61A": { "name": "opensearch1", "hostname": "172.18.0.4", "stats": { "total": { "ram": 612, "count": 1 }, "features": { "ram": 0, "count": 0 }, "featuresets": { "ram": 612, "count": 1 }, "models": { "ram": 0, "count": 0 } } }, "Z2RZNWRLSveVcz2c6lHf5A": { "name": "opensearch2", "hostname": "172.18.0.2", "stats": { ... } } } }
Löschen des Cache
Löscht den Plug-In-Cache. Verwenden Sie diese Option, um das Modell zu aktualisieren.
POST _ltr/_clearcache
