Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migration vorhandener Tabellen zu Apache Iceberg
Um Ihre aktuellen Athena- oder AWS Glue Tabellen (auch bekannt als Hive-Tabellen) in das Iceberg-Format zu migrieren, können Sie entweder die direkte oder die vollständige Datenmigration verwenden:
-
Bei der direkten Migration werden die Metadatendateien von Iceberg zusätzlich zu den vorhandenen Datendateien generiert.
-
Bei der vollständigen Datenmigration wird die Iceberg-Metadatenebene erstellt und außerdem vorhandene Datendateien aus der Originaltabelle in die neue Iceberg-Tabelle umgeschrieben.
Die folgenden Abschnitte bieten einen Überblick über die für die Migration APIs verfügbaren Tabellen sowie Anleitungen zur Auswahl einer Migrationsstrategie. Weitere Informationen zu diesen beiden Strategien finden Sie im Abschnitt Tabellenmigration
Direkte Migration
Durch die direkte Migration entfällt die Notwendigkeit, alle Datendateien neu zu schreiben. Stattdessen werden Iceberg-Metadatendateien generiert und mit Ihren vorhandenen Datendateien verknüpft. Iceberg bietet drei Optionen für die Implementierung einer In-Place-Migration:
-
Verwenden Sie das
snapshotVerfahren, wie in den Abschnitten Snapshot-Tabelle und Spark-Verfahren: Snapshotin der Iceberg-Dokumentation beschrieben. -
Verwenden Sie das
add_filesVerfahren, wie in den Abschnitten Dateien hinzufügenund Spark-Verfahren: add_files in der Iceberg-Dokumentation beschrieben. -
Verwenden Sie das
migrateVerfahren, wie in den Abschnitten Tabelle migrierenund Spark-Verfahren: Migrieren in der Iceberg-Dokumentation beschrieben.
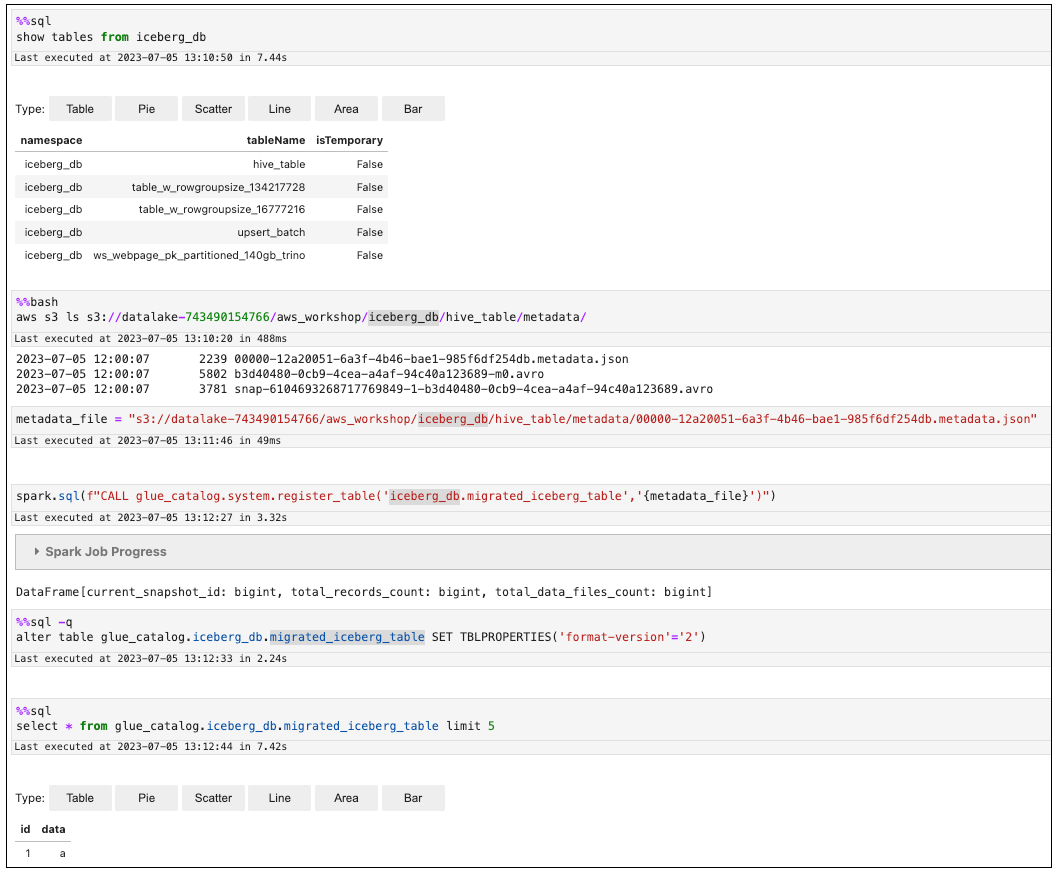
Derzeit funktioniert das Migrationsverfahren nicht direkt mit dem AWS Glue Data Catalog— es funktioniert nur mit dem Hive-Metastore. Wenn Sie das migrate Verfahren anstelle von snapshot oder verwenden möchtenadd_files, können Sie einen temporären Amazon EMR-Cluster mit dem Hive Metastore (HMS) verwenden. Für diesen Ansatz ist Iceberg Version 1.2 oder höher erforderlich.
Nehmen wir an, Sie möchten die folgende Hive-Tabelle erstellen:
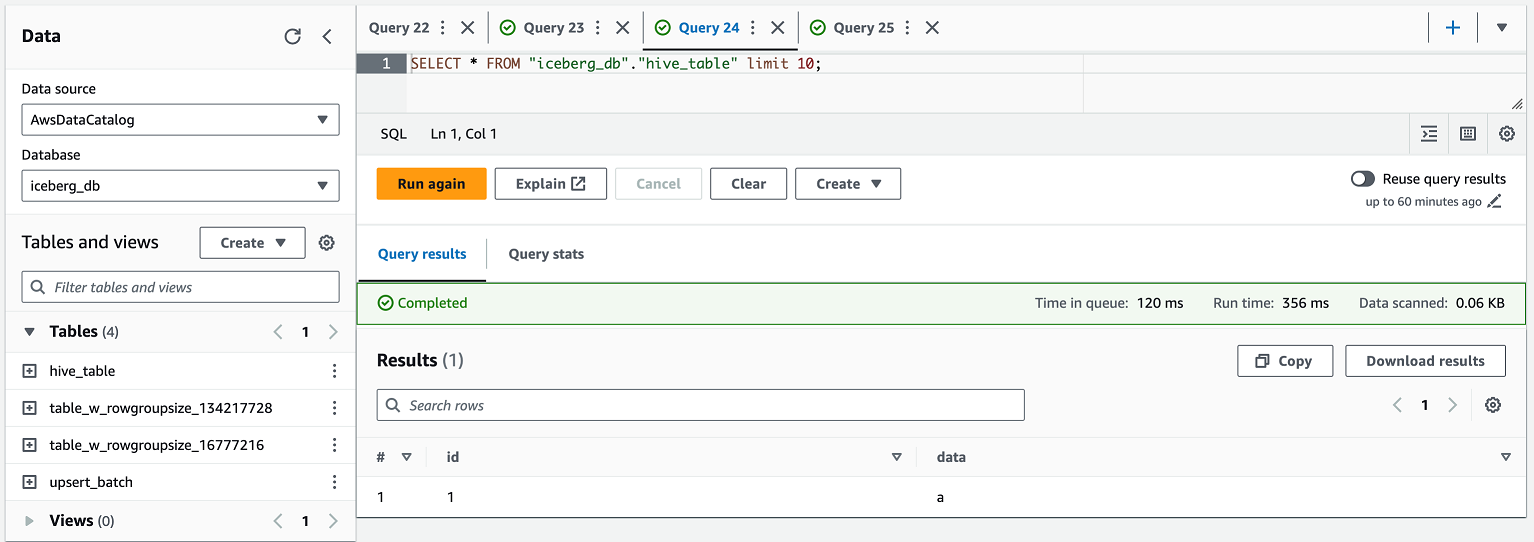
Sie können diese Hive-Tabelle erstellen, indem Sie diesen Code in der Athena-Konsole ausführen:
CREATE EXTERNAL TABLE 'hive_table'( 'id' bigint, 'data' string) USING parquet LOCATION 's3://datalake-xxxx/aws_workshop/iceberg_db/hive_table' INSERT INTO iceberg_db.hive_table VALUES (1, 'a')
Wenn Ihre Hive-Tabelle partitioniert ist, fügen Sie die Partitionsanweisung hinzu und fügen Sie die Partitionen gemäß den Hive-Anforderungen hinzu.
ALTER TABLE default.placeholder_table_for_migration ADD PARTITION (date = '2023-10-10')
Schritte:
-
Erstellen Sie einen Amazon EMR-Cluster, ohne die AWS Glue Data Catalog Integration zu aktivieren — aktivieren Sie also nicht die Kontrollkästchen für Hive- oder Spark-Tabellenmetadaten. Das liegt daran, dass Sie für diese Problemumgehung den nativen Hive Metastore (HMS) verwenden werden, der im Cluster verfügbar ist.
-
Konfigurieren Sie die Spark-Sitzung so, dass sie die Iceberg Hive-Katalogimplementierung verwendet.
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", "spark.sql.catalog.spark_catalog": "org.apache.iceberg.spark.SparkSessionCatalog", "spark.sql.catalog.spark_catalog.type": "hive", -
Stellen Sie sicher, dass Ihr Amazon EMR-Cluster nicht mit dem verbunden ist, AWS Glue Data Catalog indem Sie
show databasesodershow tablesausführen.
-
Registrieren Sie die Hive-Tabelle im Hive-Metastore Ihres Amazon EMR-Clusters und verwenden Sie dann das Iceberg-Verfahren.
migrate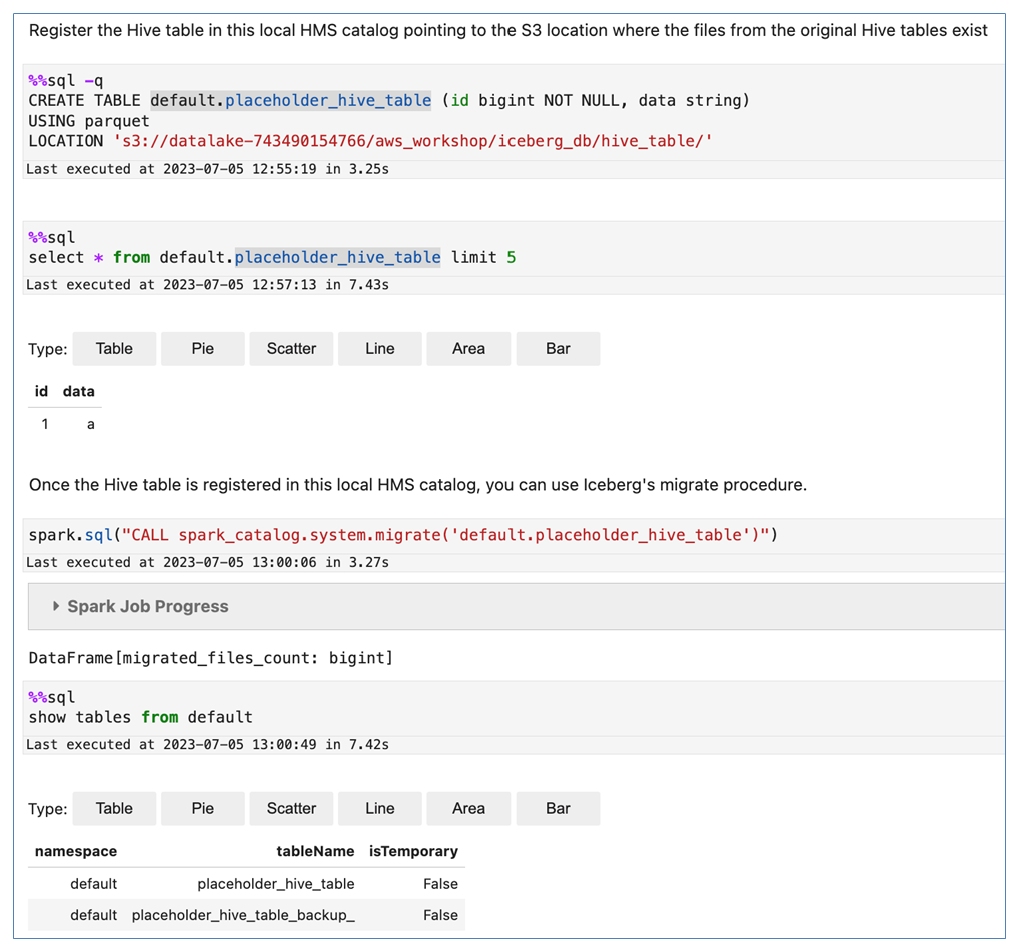
Bei diesem Verfahren werden die Iceberg-Metadatendateien am selben Speicherort wie die Hive-Tabelle erstellt.
-
Registrieren Sie die migrierte Iceberg-Tabelle in der. AWS Glue Data Catalog
-
Wechseln Sie zurück zu einem Amazon EMR-Cluster, für den die AWS Glue Data Catalog Integration aktiviert ist.
-
Verwenden Sie die folgende Iceberg-Konfiguration in der Spark-Sitzung.
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", "spark.sql.catalog.glue_catalog": "org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.glue_catalog.warehouse": "s3://datalake-xxxx/aws_workshop", "spark.sql.catalog.glue_catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog", "spark.sql.catalog.glue_catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO"
Sie können diese Tabelle jetzt von Amazon EMR oder Athena AWS Glue abfragen.
Vollständige Datenmigration
Bei der vollständigen Datenmigration werden sowohl die Datendateien als auch die Metadaten neu erstellt. Dieser Ansatz dauert länger und erfordert zusätzliche Rechenressourcen im Vergleich zur direkten Migration. Diese Option trägt jedoch zur Verbesserung der Tabellenqualität bei: Sie können die Daten validieren, Schema- und Partitionsänderungen vornehmen, die Daten sortieren usw. Verwenden Sie eine der folgenden Optionen, um eine vollständige Datenmigration zu implementieren:
-
Verwenden Sie die
CREATE TABLE ... AS SELECT(CTAS) -Anweisung in Spark auf Amazon EMR oder AWS Glue Athena. Sie können die Partitionsspezifikation und die Tabelleneigenschaften für die neue Iceberg-Tabelle mithilfe der UND-Klauseln festlegen. PARTITIONED BYTBLPROPERTIESSie können das Schema und die Partitionierung für die neue Tabelle an Ihre Bedürfnisse anpassen, anstatt sie einfach von der Quelltabelle zu erben. -
Lesen Sie aus der Quelltabelle und schreiben Sie die Daten als neue Iceberg-Tabelle, indem Sie Spark auf Amazon EMR verwenden oder AWS Glue (siehe Erstellen einer Tabelle
in der Iceberg-Dokumentation).
Auswahl einer Migrationsstrategie
Beachten Sie bei der Auswahl der besten Migrationsstrategie die Fragen in der folgenden Tabelle.
Frage |
Empfehlung |
|---|---|
Was ist das Datendateiformat (z. B. CSV oder Apache Parquet)? |
|
Möchten Sie das Tabellenschema aktualisieren oder konsolidieren? |
|
Würde die Tabelle von einer Änderung der Partitionsstrategie profitieren? |
|
Würde es für die Tabelle von Vorteil sein, die Strategie für die Sortierreihenfolge hinzuzufügen oder zu ändern? |
|
Enthält die Tabelle viele kleine Dateien? |
|
