Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Resilienz in MES
Resilienz ist die Fähigkeit eines MES-Systems, sich nach Infrastruktur- oder Serviceunterbrechungen zu erholen, Rechenressourcen dynamisch zu erwerben, um den Bedarf zu decken, und Störungen wie Fehlkonfigurationen oder vorübergehende Netzwerkprobleme zu minimieren. Resilienz ist der Hauptfaktor, von dem die Zuverlässigkeitssäule des AWS Well-Architected Framework abhängt
Resilienz kann in zwei Hauptfaktoren unterteilt werden: Verfügbarkeit und Notfallwiederherstellung. Beide Bereiche basieren auf einigen der gleichen bewährten Methoden, wie z. B. der Überwachung von Ausfällen, der Bereitstellung an mehreren Standorten und dem automatischen Failover. Die Verfügbarkeit konzentriert sich jedoch auf Komponenten von MES-Mikroservices, wohingegen sich Disaster Recovery auf einzelne Kopien des gesamten Microservices oder sogar des gesamten MES-Systems konzentriert.
Verfügbarkeit
Wir definieren Verfügbarkeit als den Prozentsatz der Zeit, in der ein Microservice zur Nutzung verfügbar ist, wie in der folgenden Formel dargestellt. Dieser Prozentsatz wird über einen bestimmten Zeitraum berechnet, z. B. über einen Monat, ein Jahr oder die letzten drei Jahre.
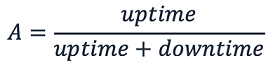
Diese Formel erfordert das Verständnis von drei Kennzahlen, die in der Fertigung und Anlagenwartung üblich sind:
-
Mittlere Betriebsdauer zwischen Ausfällen (MTBF): Die durchschnittliche Zeit zwischen dem Beginn des regulären Betriebs eines Microservices und seinem nachfolgenden Ausfall.
-
Mittlere Erkennungszeit (MTTD): Die durchschnittliche Zeit zwischen dem Auftreten eines Fehlers und dem Beginn der Reparaturvorgänge.
-
Mittlere Reparaturzeit (MTTR): Die durchschnittliche Zeit zwischen der Nichtverfügbarkeit eines Microservices aufgrund eines ausgefallenen Subsystems und seiner Reparatur oder Wiederinbetriebnahme. MTTD ist eine Teilmenge von MTTR.
Das folgende Diagramm veranschaulicht diese Verfügbarkeitsmetriken.
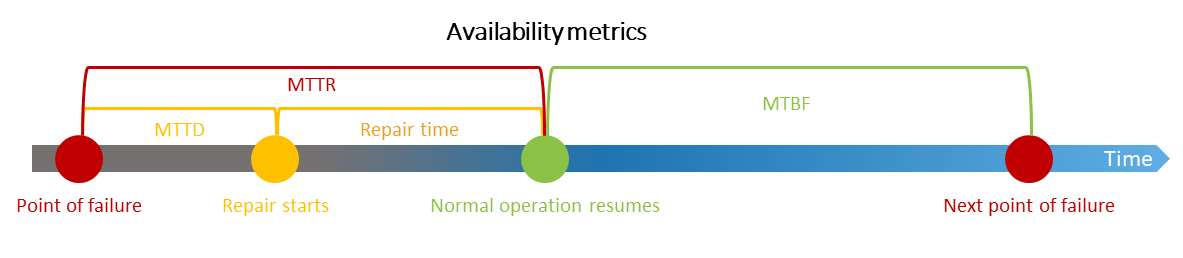
Ein robustes, hochverfügbares MES zielt darauf ab, MTTR und MTTD zu reduzieren und die MTBF zu erhöhen. Ein ideales Design würde zwar Ausfälle verhindern, ist aber nicht realistisch. Die herkömmlichen, monolithischen MES-Fehler waren schwer zu erkennen und die Reparatur dauerte länger. Modernes, cloudnatives MES ermöglicht eine schnellere Erkennung, schnelle Reparaturen und Geschäftskontinuität durch Multi-AZ-Bereitstellungen. Bewährte Verfahren für hochverfügbare moderne Systeme mit entsprechenden AWS Diensten finden Sie im Whitepaper Availability and Beyond: Understanding and Improving the Resilience of Distributed Systems on AWS.
Notfallwiederherstellung
Disaster Recovery bezieht sich auf den Prozess der Vorbereitung auf einen technologiebedingten Notfall, wie z. B. einen größeren Hardware- oder Softwareausfall, und der Wiederherstellung nach einem solchen Ereignis. Ein Ereignis, das einen Microservice (MES) daran hindert, seine Geschäftsziele an seinem primären Einsatzort zu erreichen, wird als Katastrophe betrachtet. Disaster Recovery unterscheidet sich von Verfügbarkeit und wird anhand dieser beiden Kennzahlen gemessen:
-
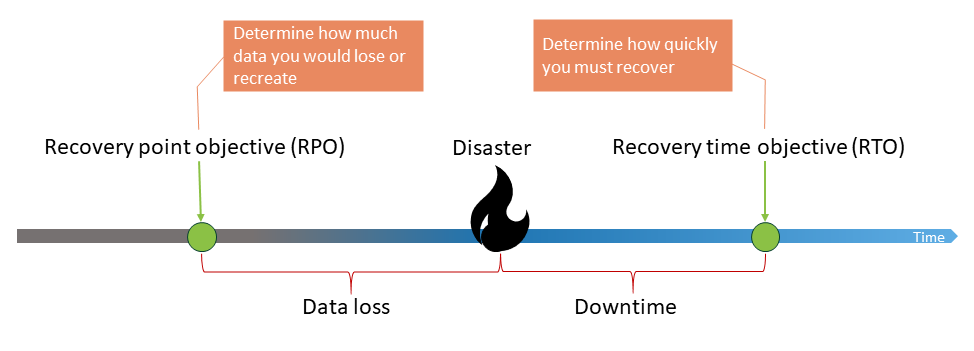
Recovery Time Objective (RTO): Die akzeptable Verzögerung zwischen einer Microservice-Unterbrechung und einer Microservice-Wiederherstellung. RTO bestimmt, welches Zeitfenster als akzeptables Zeitfenster angesehen wird, wenn der Dienst nicht verfügbar ist.
-
Recovery Point Objective (RPO): Die maximal zulässige Zeitspanne seit dem letzten Datenwiederherstellungspunkt. RPO bestimmt, was als akzeptabler Datenverlust zwischen dem letzten Recovery Point und der Unterbrechung von Microservices angesehen wird.
Das folgende Diagramm veranschaulicht diese Kennzahlen zur Notfallwiederherstellung.
Das folgende Diagramm zeigt verschiedene Strategien für die Notfallwiederherstellung.
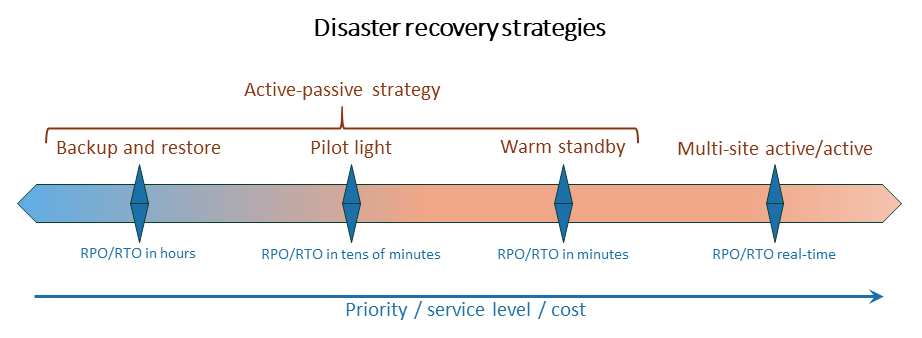
Ausführliche Anleitungen zur Implementierung dieser Strategien finden Sie im AWS Well-Architected Framework-Leitfaden Disaster Recovery of Workloads unter AWS: Recovery in the Cloud.
