Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellung produktionsreifer ML-Pipelines auf AWS
Josiah Davis, Verdi March, Yin Song, Baichuan Sun, Chen Wu und Wei Yih Yap, Amazon Web Services ()AWS
Januar 2021 (Geschichte der Dokumente)
Projekte für maschinelles Lernen (ML) erfordern einen erheblichen, mehrstufigen Aufwand, der Modellierung, Implementierung und Produktion umfasst, um einen Mehrwert für das Unternehmen zu erzielen und reale Probleme zu lösen. In jedem Schritt stehen zahlreiche Alternativen und Anpassungsoptionen zur Verfügung. Dadurch wird es immer schwieriger, ein ML-Modell für die Produktion innerhalb der Grenzen Ihrer Ressourcen und Ihres Budgets vorzubereiten. In den letzten Jahren hat unser Data Science-Team bei Amazon Web Services (AWS) mit verschiedenen Branchen an ML-Initiativen gearbeitet. Wir haben Probleme identifiziert, die viele AWS Kunden gemeinsam haben und die sowohl auf organisatorische Probleme als auch auf technische Herausforderungen zurückzuführen sind, und wir haben einen optimalen Ansatz für die Bereitstellung produktionsreifer ML-Lösungen entwickelt.
Dieser Leitfaden richtet sich an Datenwissenschaftler und ML-Ingenieure, die an ML-Pipeline-Implementierungen beteiligt sind. Er beschreibt unseren Ansatz zur Bereitstellung produktionsreifer ML-Pipelines. In diesem Leitfaden wird erläutert, wie Sie von der interaktiven Ausführung von ML-Modellen (während der Entwicklung) zur Bereitstellung als Teil einer Pipeline (während der Produktion) für Ihren ML-Anwendungsfall übergehen können. Zu diesem Zweck haben wir auch eine Reihe von Beispielvorlagen entwickelt (siehe das ML Max-Projektprojekt
Übersicht
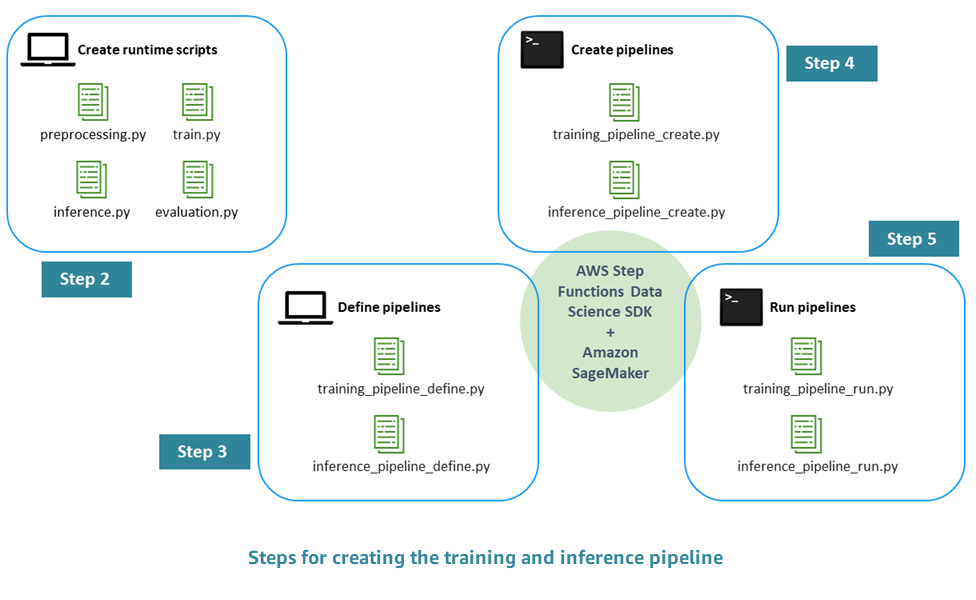
Der Prozess zur Erstellung einer produktionsbereiten ML-Pipeline besteht aus den folgenden Schritten:
-
Schritt 1. EDA durchführen und das erste Modell entwickeln — Datenwissenschaftler stellen Rohdaten in Amazon Simple Storage Service (Amazon S3) zur Verfügung, führen explorative Datenanalysen (EDA) durch, entwickeln das erste ML-Modell und bewerten dessen Inferenzleistung. Sie können diese Aktivitäten interaktiv über Jupyter-Notebooks durchführen.
-
Schritt 2. Erstellen Sie die Runtime-Skripten — Sie integrieren das Modell in Runtime-Python-Skripten, sodass es von einem ML-Framework (in unserem Fall Amazon SageMaker AI) verwaltet und bereitgestellt werden kann. Dies ist der erste Schritt, um von der interaktiven Entwicklung eines eigenständigen Modells zur Produktion überzugehen. Insbesondere definieren Sie die Logik für die Vorverarbeitung, Bewertung, Schulung und Inferenz separat.
-
Schritt 3. Definieren Sie die Pipeline — Sie definieren die Eingabe- und Ausgabe-Platzhalter für jeden Schritt der Pipeline. Konkrete Werte für diese werden später, während der Laufzeit, bereitgestellt (Schritt 5). Sie konzentrieren sich auf Pipelines für Training, Inferenz, Kreuzvalidierung und Backtesting.
-
Schritt 4. Pipeline erstellen — Sie erstellen die zugrunde liegende Infrastruktur, einschließlich der AWS Step Functions State Machine-Instanz, automatisiert (fast mit einem Klick), indem AWS CloudFormation Sie
-
Schritt 5. Pipeline ausführen — Sie führen die in Schritt 4 definierte Pipeline aus. Außerdem bereiten Sie Metadaten und Daten oder Datenspeicherorte vor, um konkrete Werte für die Eingabe-/Ausgabe-Platzhalter einzugeben, die Sie in Schritt 3 definiert haben. Dazu gehören die in Schritt 2 definierten Runtime-Skripten sowie Modell-Hyperparameter.
-
Schritt 6. Erweiterung der Pipeline — Sie implementieren CI/CD-Prozesse (Continuous Integration und Continuous Deployment), automatisierte Umschulungen, geplante Inferenzen und ähnliche Erweiterungen der Pipeline.
Das folgende Diagramm veranschaulicht die wichtigsten Schritte dieses Prozesses.