Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Mit Athena auf Amazon DynamoDB-Tabellen zugreifen, diese abfragen und verbinden
Moinul Al-Mamun, Amazon Web Services
Übersicht
Dieses Muster zeigt Ihnen, wie Sie mithilfe des Amazon Athena DynamoDB-Connectors eine Verbindung zwischen Amazon Athena und Amazon DynamoDB einrichten. Der Connector verwendet eine AWS-Lambda-Funktion, um die Daten in DynamoDB abzufragen. Sie müssen keinen Code schreiben, um die Verbindung einzurichten. Nachdem die Verbindung hergestellt wurde, können Sie schnell auf DynamoDB-Tabellen zugreifen und diese analysieren, indem Sie Athena Federated Query verwenden, um SQL-Befehle von Athena auszuführen. Sie können auch eine oder mehrere DynamoDB-Tabellen miteinander oder mit anderen Datenquellen wie Amazon Redshift oder Amazon Aurora verbinden.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto mit Berechtigungen zur Verwaltung von DynamoDB-Tabellen, Athena-Datenquellen, Lambda und AWS Identity and Access Management (IAM) -Rollen
Ein Amazon Simple Storage Service (Amazon S3) -Bucket, in dem Athena Abfrageergebnisse speichern kann
Ein S3-Bucket, in dem der Athena DynamoDB Connector die Daten kurzfristig speichern kann
Eine AWS-Region, die Athena Engine Version 2 unterstützt
IAM-Berechtigungen für den Zugriff auf Athena und die erforderlichen S3-Buckets
Amazon Athena DynamoDB Connector
, installiert
Einschränkungen
Das Abfragen von DynamoDB-Tabellen ist kostenpflichtig. Tabellengrößen, die einige Gigabyte (GBs) überschreiten, können hohe Kosten verursachen. Wir empfehlen, dass Sie die Kosten berücksichtigen, bevor Sie einen vollständigen Tabellen-SCAN-Vorgang durchführen. Weitere Informationen finden Sie unter Amazon DynamoDB – PreiseSELECT * FROM table1 LIMIT 10). Bevor Sie eine JOIN- oder GROUP BY-Abfrage in einer Produktionsumgebung ausführen, sollten Sie außerdem die Größe Ihrer Tabellen berücksichtigen. Wenn Ihre Tabellen zu groß sind, ziehen Sie alternative Optionen in Betracht, z. B. die Migration der Tabelle zu Amazon S3
Architektur
Das folgende Diagramm zeigt, wie ein Benutzer eine SQL-Abfrage für eine DynamoDB-Tabelle von Athena aus ausführen kann.
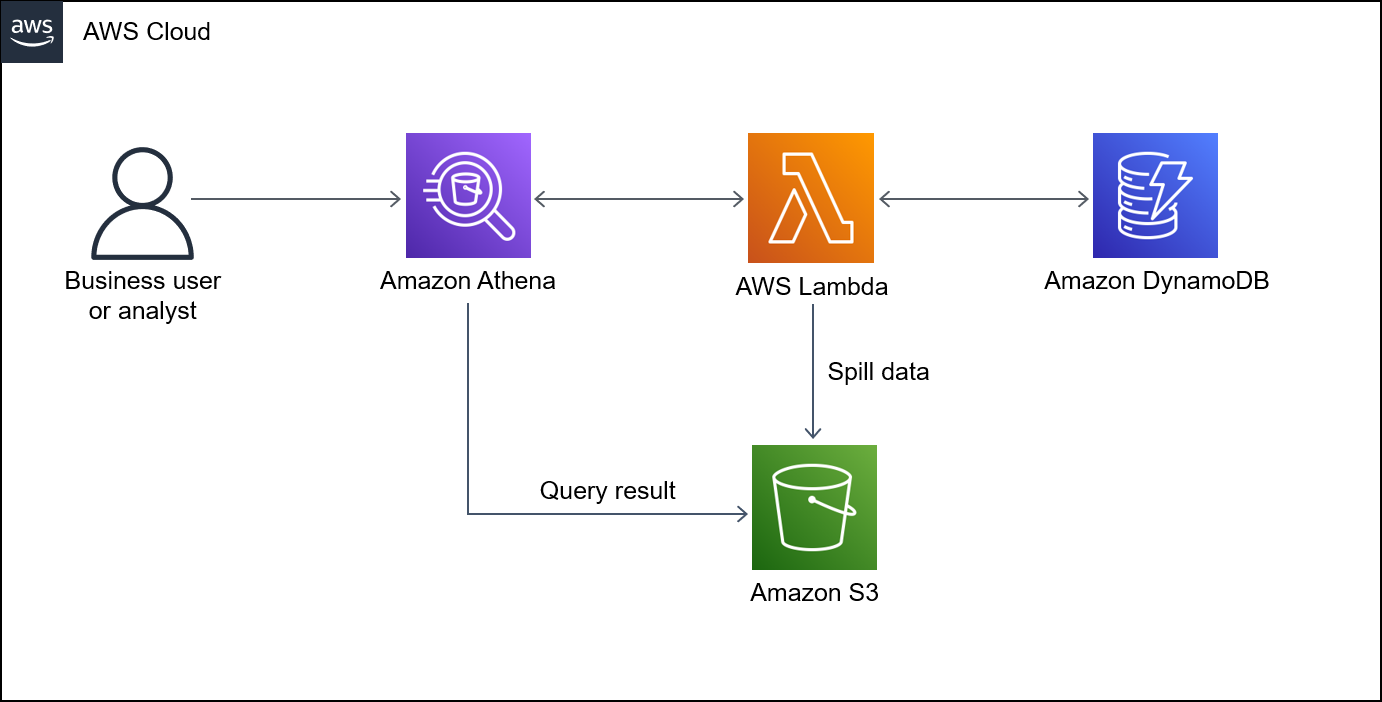
Das Diagramm zeigt den folgenden Workflow:
Um eine DynamoDB-Tabelle abzufragen, führt ein Benutzer eine SQL-Abfrage von Athena aus.
Athena initiiert eine Lambda-Funktion.
Die Lambda-Funktion fragt die angeforderten Daten in der DynamoDB-Tabelle ab.
DynamoDB gibt die angeforderten Daten an die Lambda-Funktion zurück. Anschließend überträgt die Funktion die Abfrageergebnisse über Athena an den Benutzer.
Die Lambda-Funktion speichert Daten im S3-Bucket.
Technologie-Stack
Amazon Athena
Amazon-DynamoDB
Amazon S3
AWS Lambda
Tools
Amazon Athena ist ein interaktiver Abfrageservice, mit dem Sie Daten mithilfe von Standard-SQL direkt in Amazon S3 analysieren können.
Amazon Athena DynamoDB Connector
ist ein AWS-Tool, mit dem Athena mithilfe von SQL-Abfragen eine Verbindung mit DynamoDB herstellen und auf Ihre Tabellen zugreifen kann. Amazon DynamoDB ist ein vollständig verwalteter NoSQL-Datenbank-Service, der schnelle und planbare Leistung mit nahtloser Skalierbarkeit bereitstellt.
AWS Lambda ist ein Rechenservice, mit dem Sie Code ausführen können, ohne Server bereitstellen oder verwalten zu müssen. Er führt Ihren Code nur bei Bedarf aus und skaliert automatisch, sodass Sie nur für die tatsächlich genutzte Rechenzeit zahlen.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie die erste Beispieltabelle. |
| Developer |
Fügen Sie Beispieldaten in die erste Tabelle ein. |
| Developer |
Erstellen Sie die zweite Beispieltabelle. |
| Developer |
Fügen Sie Beispieldaten in die zweite Tabelle ein. |
| Developer |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Richten Sie den Datenquellenkonnektor ein. | Erstellen Sie eine Datenquelle für DynamoDB und anschließend eine Lambda-Funktion, um eine Verbindung zu dieser Datenquelle herzustellen.
| Developer |
Stellen Sie sicher, dass die Lambda-Funktion auf den S3-Spill-Bucket zugreifen kann. |
Wenn Sie auf Fehler stoßen, finden Sie im Abschnitt Zusätzliche Informationen in diesem Muster eine Anleitung. | Developer |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Fragen Sie die DynamoDB-Tabellen ab. |
| Developer |
Verbinden Sie die beiden DynamoDB-Tabellen. | DynamoDB ist ein NoSQL-Datenspeicher und unterstützt den SQL-Join-Vorgang nicht. Folglich müssen Sie einen Join-Vorgang für zwei DynamoDB-Tabellen ausführen:
| Developer |
Zugehörige Ressourcen
Abfragen beliebiger Datenquellen mit der neuen Verbundabfrage von Amazon Athena
(AWS Big Data Blog) Versionsreferenz der Athena-Engine (Athena-Benutzerhandbuch)
Zusätzliche Informationen
Wenn Sie in Athena eine Abfrage mit spill_bucket im {bucket_name}/folder_name/ Format ausführen, erhalten Sie möglicherweise die folgende Fehlermeldung:
"GENERIC_USER_ERROR: Encountered an exception[java.lang.RuntimeException] from your LambdaFunction[arn:aws:lambda:us-east-1:xxxxxx:function:testdynamodb] executed in context[retrieving meta-data] with message[You do NOT own the spill bucket with the name: s3://amzn-s3-demo-bucket/athena_dynamodb_spill_data/] This query ran against the "default" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: [query-id]"
Um diesen Fehler zu beheben, aktualisieren Sie die Umgebungsvariable der Lambda-Funktion spill_bucket auf {bucket_name_only} und aktualisieren Sie dann die folgende Lambda-IAM-Richtlinie für den Bucket-Schreibzugriff:
{ "Action": [ "s3:GetObject", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObjectVersion", "s3:PutObject", "s3:PutObjectAcl", "s3:GetLifecycleConfiguration", "s3:PutLifecycleConfiguration", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::spill_bucket", "arn:aws:s3:::spill_bucket/*" ], "Effect": "Allow" }
Alternativ können Sie den Athena-Datenquellenconnector, den Sie zuvor erstellt haben, entfernen und ihn neu erstellen, indem Sie nur {bucket_name} für verwenden. spill_bucket
