Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Automatisches Extrahieren von Inhalten aus PDF-Dateien mit Amazon Textract
Tianxia Jia, Amazon Web Services
Übersicht
Viele Unternehmen müssen Informationen aus PDF-Dateien extrahieren, die in ihre Geschäftsanwendungen hochgeladen werden. Beispielsweise könnte eine Organisation Informationen aus steuerlichen oder medizinischen PDF-Dateien für die Steueranalyse oder die Bearbeitung von medizinischen Ansprüchen präzise extrahieren müssen.
In der Amazon Web Services (AWS) Cloud extrahiert Amazon Textract automatisch Informationen (z. B. gedruckten Text, Formulare und Tabellen) aus PDF-Dateien und erstellt eine Datei im JSON-Format, die Informationen aus der ursprünglichen PDF-Datei enthält. Sie können Amazon Textract in der AWS-Managementkonsole oder durch Implementierung von API-Aufrufen verwenden. Wir empfehlen, programmatische API-Aufrufe
Wenn Amazon Textract eine Datei verarbeitet, erstellt es die folgende Block Objektliste: Seiten, Textzeilen und Wörter, Formulare (Schlüssel-Wert-Paare), Tabellen und Zellen sowie Auswahlelemente. Andere Objektinformationen sind ebenfalls enthalten, z. B. Begrenzungsrahmen, Konfidenzintervalle und Beziehungen. IDs Amazon Textract extrahiert die Inhaltsinformationen als Zeichenketten. Korrekt identifizierte und transformierte Datenwerte sind erforderlich, da sie von Ihren nachgelagerten Anwendungen einfacher verwendet werden können.
Dieses Muster beschreibt einen step-by-step Arbeitsablauf für die Verwendung von Amazon Textract, um automatisch Inhalte aus PDF-Dateien zu extrahieren und zu einer sauberen Ausgabe zu verarbeiten. Das Muster verwendet ein Verfahren zum Abgleich von Vorlagen, um das erforderliche Feld, den Schlüsselnamen und die Tabellen korrekt zu identifizieren, und wendet dann die Nachbearbeitungskorrekturen auf jeden Datentyp an. Sie können dieses Muster verwenden, um verschiedene Arten von PDF-Dateien zu verarbeiten. Anschließend können Sie diesen Workflow skalieren und automatisieren, um PDF-Dateien mit identischem Format zu verarbeiten.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto.
Ein vorhandener Amazon Simple Storage Service (Amazon S3) -Bucket zum Speichern der PDF-Dateien, nachdem sie zur Verarbeitung durch Amazon Textract in das JPEG-Format konvertiert wurden. Weitere Informationen zu S3-Buckets finden Sie unter Buckets-Übersicht in der Amazon S3 S3-Dokumentation.
Das
Textract_PostProcessing.ipynbJupyter-Notebook (angeschlossen), installiert und konfiguriert. Weitere Informationen zu Jupyter-Notebooks finden Sie unter Erstellen eines Jupyter-Notizbuchs in der Amazon-Dokumentation. SageMakerBestehende PDF-Dateien, die ein identisches Format haben.
Ein Verständnis von Python.
Einschränkungen
Ihre PDF-Dateien müssen von guter Qualität und gut lesbar sein. Systemeigene PDF-Dateien werden empfohlen, aber Sie können gescannte Dokumente verwenden, die in ein PDF-Format konvertiert wurden, wenn alle einzelnen Wörter klar sind. Weitere Informationen dazu finden Sie unter Vorverarbeitung von PDF-Dokumenten mit Amazon Textract: Erkennung und Entfernung von Grafiken
im AWS Machine Learning Learning-Blog. Für mehrseitige Dateien können Sie einen asynchronen Vorgang verwenden oder die PDF-Dateien in eine einzelne Seite aufteilen und einen synchronen Vorgang verwenden. Weitere Informationen zu diesen beiden Optionen finden Sie unter Erkennen und Analysieren von Text in mehrseitigen Dokumenten und Erkennen und Analysieren von Text in einseitigen Dokumenten in der Amazon Textract Textract-Dokumentation.
Architektur
Der Workflow dieses Musters führt Amazon Textract zunächst für eine Beispiel-PDF-Datei aus (Erstausführung) und führt ihn dann für PDF-Dateien aus, die ein identisches Format wie das erste PDF haben (Wiederholungslauf). Das folgende Diagramm zeigt den kombinierten Arbeitsablauf beim ersten Ausführen und beim wiederholten Ausführen, der automatisch und wiederholt Inhalte aus PDF-Dateien mit identischen Formaten extrahiert.
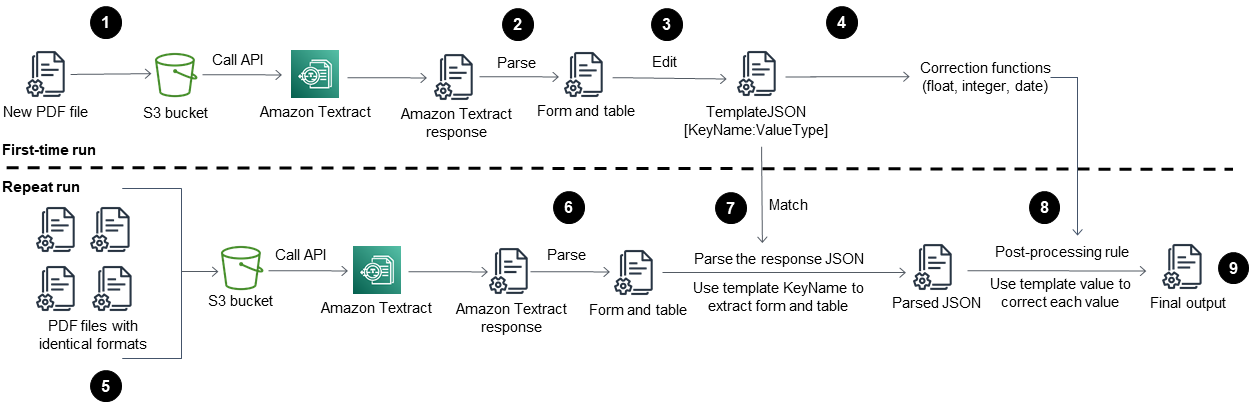
Das Diagramm zeigt den folgenden Arbeitsablauf für dieses Muster:
Konvertiert eine PDF-Datei in das JPEG-Format und speichert sie in einem S3-Bucket.
Rufen Sie die Amazon Textract Textract-API auf und analysieren Sie die Amazon Textract Textract-Antwort-JSON-Datei.
Bearbeiten Sie die JSON-Datei, indem Sie das richtige
KeyName:DataTypePaar für jedes erforderliche Feld hinzufügen. Erstellen Sie eineTemplateJSONDatei für die Phase „Ausführung wiederholen“.Definieren Sie die Korrekturfunktionen für die Nachbearbeitung für jeden Datentyp (z. B. Float, Integer und Date).
Bereiten Sie die PDF-Dateien vor, die ein identisches Format wie Ihre erste PDF-Datei haben.
Rufen Sie die Amazon Textract Textract-API auf und analysieren Sie die Amazon Textract Textract-Antwort-JSON.
Ordnen Sie die geparste JSON-Datei der Datei zu.
TemplateJSONImplementieren Sie Korrekturen nach der Bearbeitung.
Die endgültige JSON-Ausgabedatei enthält das richtige KeyName und Value für jedes erforderliche Feld.
Zieltechnologie-Stack
Amazon SageMaker
Amazon S3
Amazon Textract
Automatisierung und Skalierung
Sie können den Repeat Run-Workflow automatisieren, indem Sie eine AWS Lambda Lambda-Funktion verwenden, die Amazon Textract initiiert, wenn eine neue PDF-Datei zu Amazon S3 hinzugefügt wird. Amazon Textract führt dann die Verarbeitungsskripten aus und die endgültige Ausgabe kann an einem Speicherort gespeichert werden. Weitere Informationen dazu finden Sie in der Lambda-Dokumentation unter Verwenden eines Amazon S3 S3-Triggers zum Aufrufen einer Lambda-Funktion.
Tools
Amazon SageMaker ist ein vollständig verwalteter ML-Service, mit dem Sie schnell und einfach ML-Modelle erstellen und trainieren und sie dann direkt in einer produktionsbereiten gehosteten Umgebung bereitstellen können.
Amazon Simple Storage Service (Amazon S3) ist ein cloudbasierter Objektspeicherservice, der Sie beim Speichern, Schützen und Abrufen beliebiger Datenmengen unterstützt.
Amazon Textract macht es einfach, Ihren Anwendungen die Erkennung und Analyse von Dokumententext hinzuzufügen.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Konvertiert die PDF-Datei. | Bereiten Sie die PDF-Datei für Ihre erste Ausführung vor, indem Sie sie in eine einzelne Seite aufteilen und sie für den synchronen Vorgang von Amazon Textract in das JPEG-Format konvertieren (). AnmerkungSie können die asynchrone Amazon Textract Textract-Operation ( | Datenwissenschaftler, Entwickler |
Analysieren Sie die JSON der Amazon Textract Textract-Antwort. | Öffnen Sie das
Analysieren Sie den Antwort-JSON mithilfe des folgenden Codes in ein Formular und eine Tabelle:
| Datenwissenschaftler, Entwickler |
Bearbeiten Sie die TemplateJSON-Datei. | Bearbeiten Sie den analysierten JSON-Code für jeden Diese Vorlage wird für jeden einzelnen PDF-Dateityp verwendet, was bedeutet, dass die Vorlage für PDF-Dateien mit identischem Format wiederverwendet werden kann. | Datenwissenschaftler, Entwickler |
Definieren Sie die Korrekturfunktionen für die Nachbearbeitung. | Die Werte in der Antwort von Amazon Textract für die Korrigieren Sie jeden Datentyp entsprechend der
| Datenwissenschaftler, Entwickler |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Bereiten Sie die PDF-Dateien vor. | Bereiten Sie die PDF-Dateien vor, indem Sie sie auf eine einzelne Seite aufteilen und sie für den synchronen Vorgang von Amazon Textract in das JPEG-Format konvertieren (). AnmerkungSie können die asynchrone Amazon Textract Textract-Operation ( | Datenwissenschaftler, Entwickler |
Rufen Sie die Amazon Textract Textract-API auf. | Rufen Sie die Amazon Textract Textract-API mit dem folgenden Code auf:
| Datenwissenschaftler, Entwickler |
Analysieren Sie die JSON der Amazon Textract Textract-Antwort. | Analysieren Sie die Antwort-JSON mithilfe des folgenden Codes in ein Formular und eine Tabelle:
| Datenwissenschaftler, Entwickler |
Laden Sie die TemplateJSON-Datei und ordnen Sie sie der analysierten JSON-Datei zu. | Verwenden Sie die
| Datenwissenschaftler, Entwickler |
Korrekturen nach der Bearbeitung. | Verwenden Sie
| Datenwissenschaftler, Entwickler |
Zugehörige Ressourcen
Anlagen
