Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen Sie eine serverlose Architektur mit mehreren Mandanten in Amazon Service OpenSearch
Tabby Ward und Nisha Gambhir, Amazon Web Services
Übersicht
Amazon OpenSearch Service ist ein verwalteter Service, der die Bereitstellung, den Betrieb und die Skalierung von Elasticsearch, einer beliebten Open-Source-Such- und Analyse-Engine, vereinfacht. OpenSearch Der Service bietet eine Freitextsuche sowie die Erfassung und das Dashboarding von Streaming-Daten wie Logs und Metriken nahezu in Echtzeit.
Anbieter von Software as a Service (SaaS) nutzen OpenSearch Service häufig, um eine Vielzahl von Anwendungsfällen abzudecken, z. B. um Kundeninformationen auf skalierbare und sichere Weise zu gewinnen und gleichzeitig Komplexität und Ausfallzeiten zu reduzieren.
Die Verwendung von OpenSearch Service in einer Umgebung mit mehreren Mandanten bringt eine Reihe von Überlegungen mit sich, die sich auf die Partitionierung, Isolierung, Bereitstellung und Verwaltung Ihrer SaaS-Lösung auswirken. SaaS-Anbieter müssen überlegen, wie sie ihre Elasticsearch-Cluster bei sich ständig ändernden Workloads effektiv skalieren können. Sie müssen auch berücksichtigen, wie sich Stufenbildung und laute Nachbarschaftsbedingungen auf ihr Partitionierungsmodell auswirken könnten.
In diesem Muster werden die Modelle untersucht, die zur Darstellung und Isolierung von Mandantendaten mit Elasticsearch-Konstrukten verwendet werden. Darüber hinaus konzentriert sich das Muster auf eine einfache serverlose Referenzarchitektur als Beispiel, um die Indizierung und Suche mithilfe von OpenSearch Service in einer Umgebung mit mehreren Mandanten zu demonstrieren. Es implementiert das Pool-Datenpartitionierungsmodell, das denselben Index für alle Mandanten verwendet und gleichzeitig die Datenisolierung eines Mandanten gewährleistet. Dieses Muster verwendet die folgenden AWS Dienste: Amazon API Gateway AWS Lambda, Amazon Simple Storage Service (Amazon S3) und OpenSearch Service.
Weitere Informationen zum Poolmodell und anderen Datenpartitionierungsmodellen finden Sie im Abschnitt Zusätzliche Informationen.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktiver AWS-Konto
AWS Command Line Interface (AWS CLI) Version 2.x, installiert und konfiguriert auf macOS, Linux oder Windows
pip3
— Der Python-Quellcode wird als ZIP-Datei bereitgestellt, die in einer Lambda-Funktion bereitgestellt wird. Wenn Sie den Code lokal verwenden oder anpassen möchten, gehen Sie wie folgt vor, um den Quellcode zu entwickeln und neu zu kompilieren: Generieren Sie die
requirements.txtDatei, indem Sie den folgenden Befehl im selben Verzeichnis wie die Python-Skripte ausführen:pip3 freeze > requirements.txtInstallieren Sie die Abhängigkeiten:
pip3 install -r requirements.txt
Einschränkungen
Dieser Code läuft in Python und unterstützt derzeit keine anderen Programmiersprachen.
Die Beispielanwendung bietet keine AWS regionsübergreifende Unterstützung oder Unterstützung für Disaster Recovery (DR).
Dieses Muster dient nur zu Demonstrationszwecken. Es ist nicht für die Verwendung in einer Produktionsumgebung vorgesehen.
Architektur
Das folgende Diagramm veranschaulicht die allgemeine Architektur dieses Musters. Die Architektur umfasst Folgendes:
Lambda zum Indizieren und Abfragen des Inhalts
OpenSearch Dienst zur Durchführung der Suche
API Gateway zur Bereitstellung einer API-Interaktion mit dem Benutzer
Amazon S3 zum Speichern von Rohdaten (nicht indexiert)
Amazon CloudWatch zur Überwachung von Protokollen
AWS Identity and Access Management (IAM), um Mandantenrollen und Richtlinien zu erstellen

Automatisierung und Skalierung
Der Einfachheit halber wird das Muster für AWS CLI die Bereitstellung der Infrastruktur und für die Bereitstellung des Beispielcodes verwendet. Sie können eine AWS CloudFormation Vorlage oder AWS Cloud Development Kit (AWS CDK) Skripts erstellen, um das Muster zu automatisieren.
Tools
AWS-Services
AWS CLI
ist ein einheitliches Tool zur Verwaltung AWS-Services von Ressourcen mithilfe von Befehlen in Ihrer Befehlszeilen-Shell. Lambda
ist ein Rechendienst, mit dem Sie Code ausführen können, ohne Server bereitzustellen oder zu verwalten. Lambda führt Ihren Code nur bei Bedarf aus und skaliert automatisch – von einigen Anforderungen pro Tag bis zu Tausenden pro Sekunde. API Gateway
dient AWS-Service zum Erstellen, Veröffentlichen, Verwalten, Überwachen und Sichern von REST, HTTP und WebSocket APIs in jeder Größenordnung. Amazon S3
ist ein Objektspeicherservice, mit dem Sie jederzeit und von überall im Internet eine beliebige Menge an Informationen speichern und abrufen können. OpenSearch Service
ist ein vollständig verwalteter Service, der es Ihnen leicht macht, Elasticsearch kostengünstig und skalierbar bereitzustellen, zu sichern und auszuführen.
Code
Der Anhang enthält Beispieldateien für dieses Muster. Dazu zählen:
index_lambda_package.zip— Die Lambda-Funktion für die Indizierung von Daten im OpenSearch Service mithilfe des Poolmodells.search_lambda_package.zip— Die Lambda-Funktion für die Suche nach Daten im OpenSearch Service.Tenant-1-data— Beispiel für Rohdaten (nicht indexiert) für Tenant-1.Tenant-2-data— Stichprobe von Rohdaten (nicht indexiert) für Tenant-2.
Wichtig
Die Geschichten in diesem Muster enthalten AWS CLI Befehlsbeispiele, die für Unix, Linux und macOS formatiert sind. Ersetzen Sie unter Windows den umgekehrten Schrägstrich (\), das Unix-Fortsetzungszeichen, am Ende jeder Zeile durch ein Caret-Zeichen oder Zirkumflex (^).
Anmerkung
Ersetzen Sie in AWS CLI Befehlen alle Werte in den spitzen Klammern (<>) durch korrekte Werte.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie einen S3-Bucket. | Erstellen Sie einen S3-Bucket in Ihrem AWS-Region. Dieser Bucket enthält die nicht indizierten Mandantendaten für die Beispielanwendung. Stellen Sie sicher, dass der Name des S3-Buckets global eindeutig ist, da der Namespace von allen gemeinsam genutzt wird. AWS-Konten Um einen S3-Bucket zu erstellen, können Sie den Befehl AWS CLI create-bucket
wo | Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie eine OpenSearch Dienstdomäne. | Führen Sie den AWS CLI create-elasticsearch-domain
Die Anzahl der Instanzen ist auf 1 gesetzt, da die Domäne zu Testzwecken dient. Sie müssen mithilfe des Dieser Befehl erstellt einen Master-Benutzernamen ( Da die Domain Teil einer Virtual Private Cloud (VPC) ist, müssen Sie sicherstellen, dass Sie die Elasticsearch-Instanz erreichen können, indem Sie die zu verwendende Zugriffsrichtlinie angeben. Weitere Informationen finden Sie in der AWS Dokumentation unter Starten Ihrer Amazon OpenSearch Service-Domains innerhalb einer VPC. | Cloud-Architekt, Cloud-Administrator |
Richten Sie einen Bastion-Host ein. | Richten Sie eine Amazon Elastic Compute Cloud (Amazon EC2) Windows-Instance als Bastion-Host für den Zugriff auf die Kibana-Konsole ein. Die Elasticsearch-Sicherheitsgruppe muss Datenverkehr von der EC2 Amazon-Sicherheitsgruppe zulassen. Eine Anleitung finden Sie im Blogbeitrag Controlling Network Access to EC2 Instances Using a Bastion Server. Wenn der Bastion-Host eingerichtet wurde und Sie die Sicherheitsgruppe, die der Instance zugeordnet ist, verfügbar haben, verwenden Sie den AWS CLI authorize-security-group-ingress
| Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie die Lambda-Ausführungsrolle. | Führen Sie den Befehl AWS CLI create-role
wo
| Cloud-Architekt, Cloud-Administrator |
Hängen Sie verwaltete Richtlinien an die Lambda-Rolle an. | Führen Sie den AWS CLI attach-role-policy
| Cloud-Architekt, Cloud-Administrator |
Erstellen Sie eine Richtlinie, um der Lambda-Indexfunktion die Berechtigung zum Lesen der S3-Objekte zu erteilen. | Führen Sie den Befehl AWS CLI create-policy
Bei der Datei
| Cloud-Architekt, Cloud-Administrator |
Hängen Sie die Amazon S3 S3-Berechtigungsrichtlinie an die Lambda-Ausführungsrolle an. | Führen Sie den AWS CLI attach-role-policy
wo | Cloud-Architekt, Cloud-Administrator |
Erstellen Sie die Lambda-Index-Funktion. | Führen Sie den Befehl AWS CLI create-function
| Cloud-Architekt, Cloud-Administrator |
Erlauben Sie Amazon S3, die Lambda-Index-Funktion aufzurufen. | Führen Sie den Befehl AWS CLI add-permission
| Cloud-Architekt, Cloud-Administrator |
Fügen Sie einen Lambda-Trigger für das Amazon S3 S3-Ereignis hinzu. | Führen Sie den AWS CLI put-bucket-notification-configuration
Die Datei | Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie die Lambda-Ausführungsrolle. | Führen Sie den Befehl AWS CLI create-role
wo
| Cloud-Architekt, Cloud-Administrator |
Hängen Sie verwaltete Richtlinien an die Lambda-Rolle an. | Führen Sie den AWS CLI attach-role-policy
| Cloud-Architekt, Cloud-Administrator |
Erstellen Sie die Lambda-Suchfunktion. | Führen Sie den Befehl AWS CLI create-function
| Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie Mandanten-IAM-Rollen. | Führen Sie den Befehl AWS CLI create-role
Die Datei
| Cloud-Architekt, Cloud-Administrator |
Erstellen Sie eine IAM-Richtlinie für Mandanten. | Führen Sie den Befehl AWS CLI create-policy
Die Datei
| Cloud-Architekt, Cloud-Administrator |
Hängen Sie die Mandanten-IAM-Richtlinie an die Mandantenrollen an. | Führen Sie den AWS CLI attach-role-policy
Der Richtlinien-ARN stammt aus der Ausgabe des vorherigen Schritts. | Cloud-Architekt, Cloud-Administrator |
Erstellen Sie eine IAM-Richtlinie, um Lambda Berechtigungen zur Übernahme einer Rolle zu erteilen. | Führen Sie den Befehl AWS CLI create-policy
Die Datei
Denn Sie können ein Platzhalterzeichen verwenden | Cloud-Architekt, Cloud-Administrator |
Erstellen Sie eine IAM-Richtlinie, um der Lambda-Indexrolle Zugriff auf Amazon S3 zu gewähren. | Führen Sie den Befehl AWS CLI create-policy
Bei der Datei
| Cloud-Architekt, Cloud-Administrator |
Hängen Sie die Richtlinie an die Lambda-Ausführungsrolle an. | Führen Sie den AWS CLI attach-role-policy
Der Richtlinien-ARN stammt aus der Ausgabe des vorherigen Schritts. | Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie eine REST-API in API Gateway. | Führen Sie den AWS CLI create-rest-api
Für den Endpunkt-Konfigurationstyp können Sie angeben, Notieren Sie sich den Wert des | Cloud-Architekt, Cloud-Administrator |
Erstellen Sie eine Ressource für die Such-API. | Die Such-API-Ressource startet die Lambda-Suchfunktion mit dem Ressourcennamen
| Cloud-Architekt, Cloud-Administrator |
Erstellen Sie eine GET-Methode für die Such-API. | Führen Sie den Befehl AWS CLI put-method
Geben Sie für | Cloud-Architekt, Cloud-Administrator |
Erstellen Sie eine Methodenantwort für die Such-API. | Führen Sie den AWS CLI put-method-response
Geben Sie für | Cloud-Architekt, Cloud-Administrator |
Richten Sie eine Proxy-Lambda-Integration für die Such-API ein. | Führen Sie den Befehl AWS CLI put-integration
Geben Sie für | Cloud-Architekt, Cloud-Administrator |
Erteilen Sie API Gateway die Erlaubnis, die Lambda-Suchfunktion aufzurufen. | Führen Sie den Befehl AWS CLI add-permission
Ändern Sie den | Cloud-Architekt, Cloud-Administrator |
Stellen Sie die Such-API bereit. | Führen Sie den Befehl AWS CLI create-deployment
Wenn Sie die API aktualisieren, können Sie sie mit demselben AWS CLI Befehl erneut in derselben Phase bereitstellen. | Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Loggen Sie sich in die Kibana-Konsole ein. |
| Cloud-Architekt, Cloud-Administrator |
Erstellen und konfigurieren Sie Kibana-Rollen. | Um Daten zu isolieren und sicherzustellen, dass ein Mandant die Daten eines anderen Mandanten nicht abrufen kann, müssen Sie Document Security verwenden, sodass Mandanten nur auf Dokumente zugreifen können, die ihre Mandanten-ID enthalten.
| Cloud-Architekt, Cloud-Administrator |
Ordnen Sie Benutzer Rollen zu. |
Wir empfehlen Ihnen, die Erstellung der Mandanten- und Kibana-Rollen beim Onboarding des Mandanten zu automatisieren. | Cloud-Architekt, Cloud-Administrator |
Erstellen Sie den Mieterdatenindex. | Wählen Sie im Navigationsbereich unter Verwaltung die Option Dev Tools aus, und führen Sie dann den folgenden Befehl aus. Mit diesem Befehl wird der
| Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie einen VPC-Endpunkt für Amazon S3. | Führen Sie den AWS CLI create-vpc-endpoint
Geben Sie für | Cloud-Architekt, Cloud-Administrator |
Erstellen Sie einen VPC-Endpunkt für AWS STS. | Führen Sie den AWS CLI create-vpc-endpoint
Geben Sie für | Cloud-Architekt, Cloud-Administrator |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Aktualisieren Sie die Python-Dateien für die Index- und Suchfunktionen. |
Sie können den Elasticsearch-Endpunkt auf der Registerkarte „Übersicht“ der OpenSearch Service-Konsole abrufen. Er hat das Format | Cloud-Architekt, App-Entwickler |
Aktualisieren Sie den Lambda-Code. | Verwenden Sie den AWS CLI update-function-code
| Cloud-Architekt, App-Entwickler |
Laden Sie Rohdaten in den S3-Bucket hoch. | Verwenden Sie den Befehl AWS CLI cp
Der S3-Bucket ist so eingerichtet, dass er die Lambda-Indexfunktion jedes Mal ausführt, wenn Daten hochgeladen werden, sodass das Dokument in Elasticsearch indexiert wird. | Cloud-Architekt, Cloud-Administrator |
Suchen Sie Daten von der Kibana-Konsole aus. | Führen Sie auf der Kibana-Konsole die folgende Abfrage aus:
Diese Abfrage zeigt alle in Elasticsearch indexierten Dokumente an. In diesem Fall sollten Sie zwei separate Dokumente für Tenant-1 und Tenant-2 sehen. | Cloud-Architekt, Cloud-Administrator |
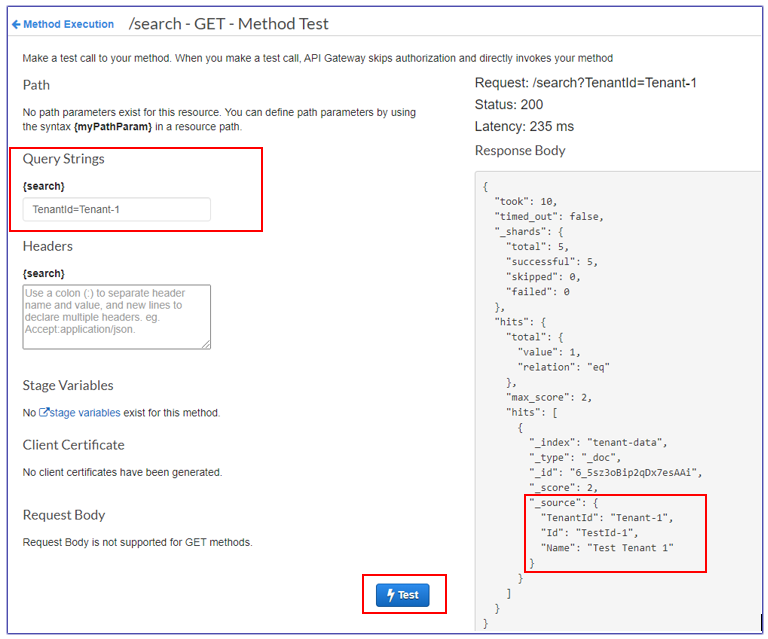
Testen Sie die Such-API von API Gateway aus. |
Bildschirmdarstellungen finden Sie im Abschnitt Zusätzliche Informationen. | Cloud-Architekt, App-Entwickler |
Bereinigen von Ressourcen. | Bereinigen Sie alle Ressourcen, die Sie erstellt haben, um zusätzliche Gebühren für Ihr Konto zu vermeiden. | AWS DevOps, Cloud-Architekt, Cloud-Administrator |
Zugehörige Ressourcen
Zusätzliche Informationen
Modelle zur Datenpartitionierung
Es gibt drei gängige Datenpartitionierungsmodelle, die in Systemen mit mehreren Mandanten verwendet werden: Silo, Pool und Hybrid. Welches Modell Sie wählen, hängt von den Anforderungen Ihrer Umgebung in Bezug auf Compliance, Noisy Neighbor, Betrieb und Isolierung ab.
Silo-Modell
Im Silomodell werden die Daten jedes Mandanten in einem eigenen Speicherbereich gespeichert, in dem es nicht zu einer Vermischung von Mandantendaten kommt. Sie können zwei Ansätze verwenden, um das Silomodell mit OpenSearch Service zu implementieren: Domäne pro Mandant und Index pro Mandant.
Domain pro Mandant — Sie können pro Mandant eine separate OpenSearch Service-Domain (gleichbedeutend mit einem Elasticsearch-Cluster) verwenden. Die Platzierung jedes Mandanten in einer eigenen Domain bietet alle Vorteile, die mit der Speicherung von Daten in einem eigenständigen Konstrukt verbunden sind. Dieser Ansatz bringt jedoch Herausforderungen in Bezug auf Management und Agilität mit sich. Aufgrund seines dezentralen Charakters ist es schwieriger, den betrieblichen Zustand und die Aktivität der Mieter zu aggregieren und zu bewerten. Dies ist eine kostspielige Option, bei der jede OpenSearch Dienstdomäne mindestens über drei Masterknoten und zwei Datenknoten für Produktionsworkloads verfügen muss.

Index pro Mandant — Sie können Mandantendaten in separaten Indizes innerhalb eines Serviceclusters platzieren. OpenSearch Bei diesem Ansatz verwenden Sie bei der Erstellung und Benennung des Indexes eine Mandanten-ID, indem Sie die Mandanten-ID dem Indexnamen voranstellen. Der Ansatz „Index pro Mandant“ hilft Ihnen dabei, Ihre Siloziele zu erreichen, ohne für jeden Mandanten einen komplett separaten Cluster einzuführen. Es kann jedoch zu Speicherauslastung kommen, wenn die Anzahl der Indizes zunimmt, da für diesen Ansatz mehr Shards erforderlich sind und der Master-Knoten für mehr Zuweisung und Neuverteilung zuständig sein muss.

Isolierung im Silomodell — Im Silomodell verwenden Sie IAM-Richtlinien, um die Domänen oder Indizes zu isolieren, die die Daten der einzelnen Mandanten enthalten. Diese Richtlinien verhindern, dass ein Mandant auf die Daten eines anderen Mandanten zugreift. Um Ihr Silo-Isolationsmodell zu implementieren, können Sie eine ressourcenbasierte Richtlinie erstellen, die den Zugriff auf Ihre Mandantenressource steuert. Dabei handelt es sich häufig um eine Domain-Zugriffsrichtlinie, die festlegt, welche Aktionen ein Principal an den Unterressourcen der Domain durchführen kann, einschließlich Elasticsearch-Indizes und. APIs Mit identitätsbasierten IAM-Richtlinien können Sie zulässige oder verweigerte Aktionen für die Domain, Indizes oder innerhalb von Service angeben. APIs OpenSearch Das Action Element einer IAM-Richtlinie beschreibt die spezifischen Aktionen, die durch die Richtlinie zugelassen oder verweigert werden, und das Principal Element gibt die betroffenen Konten, Benutzer oder Rollen an.
Die folgende Beispielrichtlinie gewährt Tenant-1 vollen Zugriff (wie von angegebenes:*) nur auf die Unterressourcen in der Domäne. tenant-1 Das nachstehende /* Resource Element weist darauf hin, dass diese Richtlinie für die Unterressourcen der Domain gilt, nicht für die Domain selbst. Wenn diese Richtlinie in Kraft ist, dürfen Mandanten keine neue Domäne erstellen oder Einstellungen für eine bestehende Domäne ändern.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id>:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:<Region>:<account-id>:domain/tenant-1/*" } ] }
Um das Silo-Modell „Mandant pro Index“ zu implementieren, müssten Sie diese Beispielrichtlinie ändern, um Tenant-1 weiter auf den angegebenen Index oder die angegebenen Indizes zu beschränken, indem Sie den Indexnamen angeben. Die folgende Beispielrichtlinie beschränkt Tenant-1 auf den Index. tenant-index-1
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:<Region>:<account-id>:domain/test-domain/tenant-index-1/*" } ] }
Pool-Modell
Im Poolmodell werden alle Mandantendaten in einem Index innerhalb derselben Domäne gespeichert. Die Mandanten-ID ist in den Daten (Dokument) enthalten und wird als Partitionsschlüssel verwendet, sodass Sie bestimmen können, welche Daten zu welchem Mandanten gehören. Dieses Modell reduziert den Verwaltungsaufwand. Der Betrieb und die Verwaltung des gepoolten Indexes sind einfacher und effizienter als die Verwaltung mehrerer Indizes. Da Mandantendaten jedoch innerhalb desselben Index zusammengefasst sind, verlieren Sie die natürliche Mandantenisolierung, die das Silomodell bietet. Dieser Ansatz kann aufgrund des Noisy-Neighbor-Effekts auch zu Leistungseinbußen führen.

Mandantenisolierung im Poolmodell — Im Allgemeinen ist es schwierig, die Mandantenisolierung im Poolmodell zu implementieren. Der im Silomodell verwendete IAM-Mechanismus ermöglicht es Ihnen nicht, die Isolierung anhand der in Ihrem Dokument gespeicherten Mandanten-ID zu beschreiben.
Ein alternativer Ansatz besteht darin, die FGAC-Unterstützung (Fine-Grained Access Control) zu verwenden, die von der Open Distro for Elasticsearch bereitgestellt wird. Mit FGAC können Sie Berechtigungen auf Index-, Dokument- oder Feldebene steuern. Bei jeder Anfrage wertet FGAC die Benutzeranmeldedaten aus und authentifiziert den Benutzer entweder oder verweigert den Zugriff. Wenn FGAC den Benutzer authentifiziert, ruft es alle Rollen ab, die diesem Benutzer zugeordnet sind, und verwendet den vollständigen Satz von Berechtigungen, um zu bestimmen, wie die Anfrage behandelt werden soll.
Um die erforderliche Isolierung im Poolmodell zu erreichen, können Sie die Sicherheit auf Dokumentebene
{ "bool": { "must": { "match": { "tenantId": "Tenant-1" } } } }
Hybrides Modell
Das Hybridmodell verwendet eine Kombination der Silo- und Poolmodelle in derselben Umgebung, um jedem Mieter (z. B. kostenlose Tarife, Standard- und Premium-Tarife) einzigartige Erlebnisse zu bieten. Jede Stufe folgt demselben Sicherheitsprofil, das im Poolmodell verwendet wurde.

Mandantenisolierung im Hybridmodell — Im Hybridmodell verwenden Sie dasselbe Sicherheitsprofil wie im Poolmodell, wo die Verwendung des FGAC-Sicherheitsmodells auf Dokumentenebene die Mandantenisolierung ermöglichte. Diese Strategie vereinfacht zwar die Clusterverwaltung und bietet Flexibilität, verkompliziert aber andere Aspekte der Architektur. Ihr Code erfordert beispielsweise zusätzliche Komplexität, um zu bestimmen, welches Modell jedem Mandanten zugeordnet ist. Sie müssen außerdem sicherstellen, dass Abfragen für einzelne Mandanten nicht die gesamte Domäne überlasten und die Benutzererfahrung für andere Mandanten beeinträchtigen.
Testen im API Gateway
Testfenster für Tenant-1-Abfrage
Testfenster für Tenant-2-Abfrage

Anlagen
