Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Emulieren Sie Oracle DR mithilfe einer PostgreSQL-kompatiblen globalen Aurora-Datenbank
HariKrishna Boorgadda, Amazon Web Services
Übersicht
Bewährte Methoden für Disaster Recovery (DR) in Unternehmen bestehen im Wesentlichen darin, fehlertolerante Hardware- und Softwaresysteme zu entwickeln und zu implementieren, die einen Notfall überstehen (Geschäftskontinuität) und den normalen Betrieb wieder aufnehmen können (Wiederaufnahme des Geschäftsbetriebs), und zwar mit minimalen Eingriffen und idealerweise ohne Datenverlust. Der Aufbau fehlertoleranter Umgebungen zur Erfüllung der DR-Ziele von Unternehmen kann teuer und zeitaufwändig sein und erfordert ein starkes Engagement des Unternehmens.
Oracle Database bietet drei verschiedene Ansätze für DR, die im Vergleich zu anderen Ansätzen zum Schutz von Oracle-Daten das höchste Maß an Datenschutz und Verfügbarkeit bieten.
Oracle Zero Data Loss Recovery Appliance
Oracle Active Data Guard
Oracle GoldenGate
Dieses Muster bietet eine Möglichkeit, Oracle GoldenGate DR mithilfe einer globalen Amazon Aurora Aurora-Datenbank zu emulieren. Die Referenzarchitektur verwendet Oracle GoldenGate für DR in drei AWS-Regionen. Das Muster führt durch die Umstellung der Quellarchitektur auf die Cloud-native globale Aurora-Datenbank, die auf der Amazon Aurora PostgreSQL-Compatible Edition basiert.
Die globalen Aurora-Datenbanken sind für Anwendungen mit globaler Präsenz konzipiert. Eine einzelne Aurora-Datenbank umfasst mehrere AWS-Regionen mit bis zu fünf sekundären Regionen. Die globalen Aurora-Datenbanken bieten die folgenden Funktionen:
Replizierung auf physischer Speicherebene
Globale Lesevorgänge mit geringer Latenz
Schnelle Notfallwiederherstellung nach Ausfällen in der gesamten Region
Schnelle regionsübergreifende Migrationen
Geringe Replikationsverzögerung zwischen Regionen
Little-to-no Auswirkung auf die Leistung Ihrer Datenbank
Weitere Informationen zu den Funktionen und Vorteilen der globalen Aurora-Datenbank finden Sie unter Verwenden globaler Amazon Aurora Aurora-Datenbanken. Weitere Informationen zu ungeplanten und verwalteten Failovers finden Sie unter Verwenden von Failover in einer globalen Amazon Aurora Aurora-Datenbank.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto
Ein Java Database Connectivity (JDBC) PostgreSQL-Treiber für Anwendungskonnektivität
Eine globale Aurora-Datenbank, die auf der Amazon Aurora PostgreSQL-kompatiblen Edition basiert
Eine Oracle Real Application Clusters (RAC) -Datenbank wurde auf die globale Aurora-Datenbank migriert, die auf Aurora PostgreSQL-kompatibel ist
Einschränkungen der globalen Aurora-Datenbanken
Die globalen Aurora-Datenbanken sind nicht in allen AWS-Regionen verfügbar. Eine Liste der unterstützten Regionen finden Sie unter Globale Aurora-Datenbanken mit Aurora PostgreSQL.
Informationen zu Funktionen, die nicht unterstützt werden, und zu anderen Einschränkungen der globalen Aurora-Datenbanken finden Sie unter Einschränkungen der globalen Amazon Aurora Aurora-Datenbanken.
Produktversionen
Amazon Aurora PostgreSQL — Compatible Edition Version 10.14 oder höher
Architektur
Quelltechnologie-Stack
Oracle RAC-Datenbank mit vier Knoten
Oracle GoldenGate
Quellarchitektur
Das folgende Diagramm zeigt drei Cluster mit Oracle RAC mit vier Knoten in verschiedenen AWS-Regionen, die mit Oracle repliziert wurden. GoldenGate

Zieltechnologie-Stack
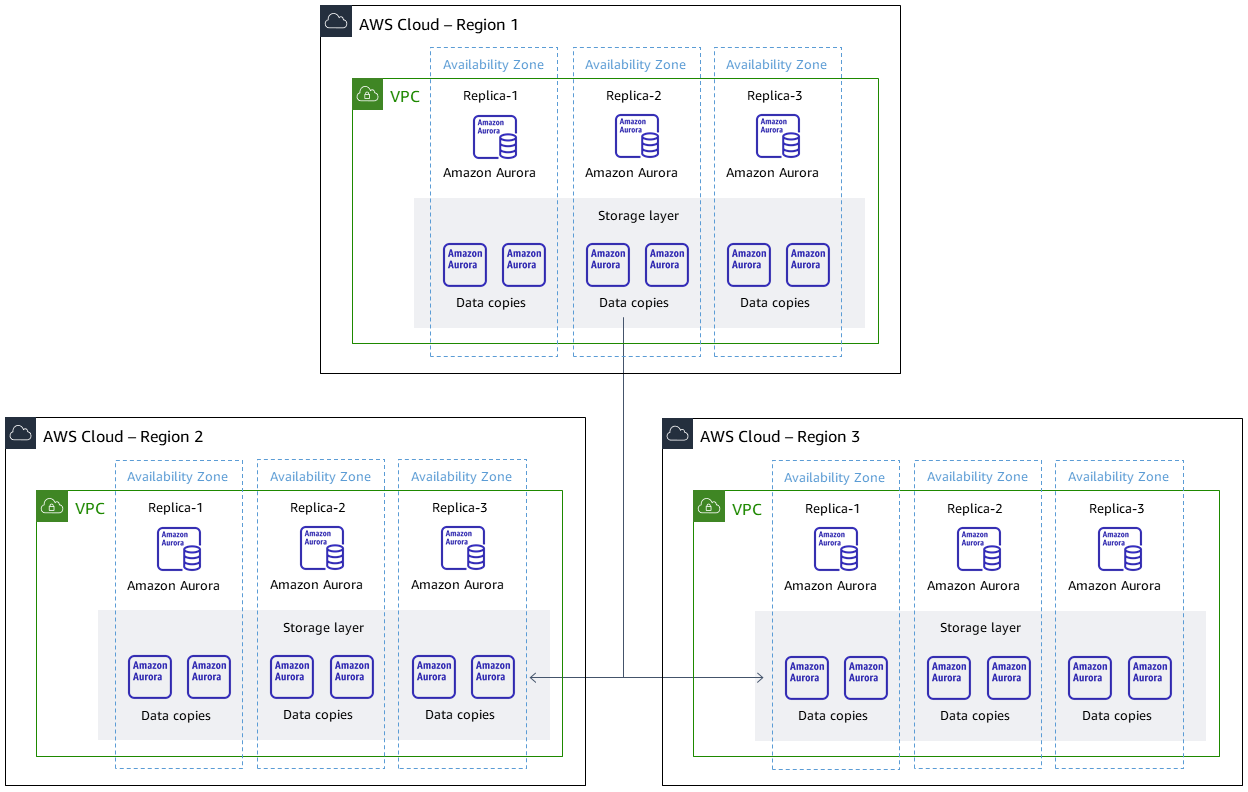
Eine globale Amazon Aurora Aurora-Datenbank mit drei Clustern, die auf Aurora PostgreSQL basiert — kompatibel, mit einem Cluster in der primären Region, zwei Clustern in verschiedenen sekundären Regionen
Zielarchitektur
Tools
AWS-Services
Amazon Aurora PostgreSQL-Compatible Edition ist eine vollständig verwaltete, ACID-konforme relationale Datenbank-Engine, die Sie bei der Einrichtung, dem Betrieb und der Skalierung von PostgreSQL-Bereitstellungen unterstützt.
Die globalen Datenbanken von Amazon Aurora erstrecken sich über mehrere AWS-Regionen und bieten globale Lesevorgänge mit geringer Latenz und eine schnelle Wiederherstellung nach dem seltenen Ausfall, der eine gesamte AWS-Region betreffen kann.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Hängen Sie einen oder mehrere sekundäre Aurora-Cluster an. | Wählen Sie in der AWS-Managementkonsole Amazon Aurora aus. Wählen Sie den primären Cluster aus, wählen Sie Aktionen und dann Region hinzufügen aus der Drop-down-Liste aus. | DBA |
Wählen Sie die Instanzklasse aus. | Sie können die Instanzklasse des sekundären Clusters ändern. Wir empfehlen jedoch, dieselbe wie die Instance-Klasse des primären Clusters beizubehalten. | DBA |
Fügen Sie die dritte Region hinzu. | Wiederhole die Schritte in diesem Epos, um einen Cluster in der dritten Region hinzuzufügen. | DBA |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Entfernen Sie den primären Cluster aus der globalen Aurora-Datenbank. |
| DBA |
Konfigurieren Sie Ihre Anwendung neu, um den Schreibdatenverkehr an den gerade hochgestuften Cluster weiterzuleiten. | Ändern Sie den Endpunkt in der Anwendung mit dem Endpunkt des neu hochgestuften Clusters. | DBA |
Beenden Sie die Ausführung von Schreibvorgängen für den nicht verfügbaren Cluster. | Beenden Sie die Anwendung und jegliche DML-Aktivitäten (Data Manipulation Language) für den Cluster, den Sie entfernt haben. | DBA |
Erstellen Sie eine neue globale Aurora-Datenbank. | Jetzt können Sie eine globale Aurora-Datenbank mit dem neu beworbenen Cluster als primärem Cluster erstellen. | DBA |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Wählen Sie den primären Cluster aus, der aus der globalen Datenbank gestartet werden soll. | Wählen Sie auf der Amazon Aurora Aurora-Konsole im Global Database-Setup den primären Cluster aus. | DBA |
Starten Sie den Cluster. | Wählen Sie in der Dropdownliste Aktionen die Option Start aus. Dieser Vorgang kann einige Zeit in Anspruch nehmen. Aktualisieren Sie den Bildschirm, um den Status zu sehen, oder überprüfen Sie nach Abschluss des Vorgangs in der Spalte Status den aktuellen Status des Clusters. | DBA |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Löschen Sie die verbleibenden sekundären Cluster. | Entfernen Sie nach Abschluss des Failover-Pilotprojekts die sekundären Cluster aus der globalen Datenbank. | DBA |
Löschen Sie den primären Cluster. | Entfernen Sie den Cluster. | DBA |
Zugehörige Ressourcen
