Using Amazon Aurora Global Database
With the Amazon Aurora Global Database feature, you set up multiple Aurora DB clusters that span multiple AWS Regions. Aurora automatically synchronizes all changes made in the primary DB cluster to one or more secondary clusters. An Aurora global database has a primary DB cluster in one Region, and up to 10 secondary DB clusters in different Regions. This multi-Region configuration provides fast recovery from the rare outage that might affect an entire AWS Region. Having a full copy of all your data in multiple geographic locations also enables low-latency read operations for applications that connect from widely separated locations around the world.
Topics
Overview of Amazon Aurora Global Database
By using the Amazon Aurora Global Database feature, you can run your globally distributed applications using a single Aurora database that spans multiple AWS Regions.
An Aurora global database consists of one primary AWS Region where your data is written, and up to 10 read-only secondary AWS Regions. You issue write operations to the primary DB cluster in the primary AWS Region. The most convenient way to do so is to connect to the Aurora Global Database writer endpoint, which always points to the primary DB cluster, even after a switchover or failover to a different AWS Region. After any write operation, Aurora replicates data to the secondary AWS Regions using dedicated infrastructure, with latency typically under a second.
In the following diagram, you can find an example Aurora global database that spans two AWS Regions.
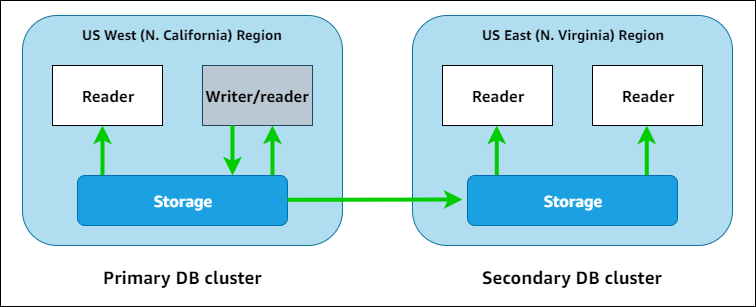
You can scale up each secondary cluster independently, by adding one or more Aurora reader instances to serve read-only workloads. You can use Aurora Serverless v2 for the reader instances for even more granular and flexible scaling.
Only the primary cluster performs write operations. Clients that perform write operations connect to the Aurora Global Database writer endpoint, which always points to the writer DB instance of the primary cluster. As shown in the diagram, Aurora uses the cluster storage volume and not the database engine for fast, low-overhead replication. To learn more, see Overview of Amazon Aurora storage.
Aurora Global Database is designed for applications with a worldwide footprint. The read-only secondary DB clusters in multiple AWS Regions help to optimize read operations closer to application users. By using the write forwarding feature, you can also configure your global database so that secondary clusters send write requests to the primary. For more information, see Using write forwarding in an Amazon Aurora global database.
Aurora Global Database supports two different operations for changing the Region of your primary DB cluster, depending on the scenario: Aurora Global Database switchover and Aurora Global Database failover.
-
For planned operational procedures such as Regional rotation, use the switchover mechanism (previously called "managed planned failover"). With this feature, you can relocate the primary cluster of a healthy Aurora Global Database to one of its secondary Regions with no data loss. To learn more, see Performing switchovers for Amazon Aurora global databases.
-
To recover your Aurora Global Database after an outage in the primary Region, use the failover mechanism. With this feature, you perform a failover from your primary DB cluster to another Region (cross-Region failover). To learn more, see Performing managed failovers for Aurora global databases.
Advantages of Amazon Aurora Global Database
By using Aurora Global Database, you can get the following advantages:
Global reads with local latency – If you have offices around the world, you can use Aurora Global Database to keep your main sources of information updated in the primary AWS Region. Offices in your other Regions can access the information in their own Region, with local latency.
Scalable secondary Aurora DB clusters – You can scale your secondary clusters by adding more read-only instances to a secondary AWS Region. The secondary cluster is read-only, so it can support up to 16 read-only DB instances rather than the usual limit of 15 for a single Aurora cluster.
Fast replication from primary to secondary Aurora DB clusters – The replication performed by Aurora Global Database has little performance impact on the primary DB cluster. The resources of the DB instances are fully devoted to serve application read and write workloads.
Recovery from Region-wide outages – The secondary clusters allow you to make an Aurora Global Database available in a new primary AWS Region more quickly (lower RTO) and with less data loss (lower RPO) than traditional replication solutions.
Region and version availability
Feature availability and support vary across specific versions of each Aurora database engine, and across AWS Regions. For more information on version and Region availability with Aurora Global Database, see Supported Regions and DB engines for Aurora global databases.
Limitations of Amazon Aurora Global Database
The following limitations currently apply to Aurora Global Database:
Aurora Global Database is available in certain AWS Regions and for specific Aurora MySQL and Aurora PostgreSQL versions. For more information, see Supported Regions and DB engines for Aurora global databases.
Aurora Global Database has specific configuration requirements for supported Aurora DB instance classes, maximum number of AWS Regions, and so on. For more information, see Configuration requirements of an Amazon Aurora global database.
For Aurora MySQL with MySQL 5.7 compatibility, Aurora Global Database switchovers require version 2.09.1 or a higher minor version.
-
You can perform managed cross-Region switchovers or failovers with Aurora Global Database only if the primary and secondary DB clusters have the same major and minor engine versions. Depending on the engine and engine versions, the patch levels might need to be identical or the patch levels can be different. For a list of engines and engine versions that allow these operations between primary and secondary clusters with different patch levels, see Patch level compatibility for managed cross-Region switchovers and failovers. If your engine versions require identical patch levels, you can perform the failover manually by following the steps in Performing manual failovers for Aurora global databases.
Aurora Global Database currently doesn't support the following Aurora features:
-
Aurora Serverless v1
-
Backtracking in Aurora
-
For limitations with using the RDS Proxy feature with Aurora Global Database, see Limitations for RDS Proxy with global databases.
Automatic minor version upgrade doesn't apply to Aurora MySQL and Aurora PostgreSQL clusters that are part of a global database. Note that you can specify this setting for a DB instance that is part of a global database cluster, but the setting has no effect.
Aurora Global Database currently doesn't support Aurora Auto Scaling for secondary DB clusters.
To use Database Activity Streams (DAS) on Aurora Global Database running Aurora MySQL 5.7, the engine version must be version 2.08 or higher. For information about DAS, see Monitoring Amazon Aurora with Database Activity Streams.
-
The following limitations currently apply to upgrading Aurora Global Database:
You can't apply a custom parameter group to the global database cluster while you're performing a major version upgrade of that Aurora global database. You create your custom parameter groups in each Region of the global cluster and you apply them manually to the Regional clusters after the upgrade.
-
With an Aurora global database based on Aurora MySQL, you can't perform an in-place upgrade from Aurora MySQL version 2 to version 3 if the
lower_case_table_namesparameter is turned on. For more information on the methods that you can use, see Major version upgrades. With Aurora Global Database, you can't perform a major version upgrade of the Aurora PostgreSQL DB engine if the recovery point objective (RPO) feature is turned on. For information about the RPO feature, see Managing RPOs for Aurora PostgreSQL–based global databases.
With an Aurora Global Database, you can't perform a minor version upgrade from Aurora MySQL version 3.01 or 3.02 to 3.03 or higher by using the standard process. For details about the process to use, see Upgrading Aurora MySQL by modifying the engine version.
For information about upgrading Aurora Global Database, see Upgrading an Amazon Aurora global database.
You can't stop or start the Aurora DB clusters in your global database individually. To learn more, see Stopping and starting an Amazon Aurora DB cluster.
Aurora reader DB instances attached to the secondary Aurora DB cluster can restart under certain circumstances. If the primary AWS Region's writer DB instance undergoes a restart or failover, reader DB instances in secondary Regions also restart. The secondary cluster is then unavailable until all reader DB instances are back in sync with the primary DB cluster's writer instance. The behavior of the primary cluster when rebooting or during a failover is the same as for a singular, nonglobal DB cluster. For more information, see Replication with Amazon Aurora.
Be sure that you understand the impacts to your global database before making changes to your primary DB cluster. To learn more, see Recovering an Amazon Aurora global database from an unplanned outage.
Aurora Global Database currently doesn't support the
inaccessible-encryption-credentials-recoverablestatus when Amazon Aurora loses access to the AWS KMS key for the DB cluster. In these cases, the encrypted DB cluster goes directly into the terminalinaccessible-encryption-credentialsstate. For more information about these states, see Viewing DB cluster status.-
Secrets Manager doesn't support Aurora Global Database. When you add a Region to a global database, you must first turn off Secrets Manager integration for the DB instance.
-
Aurora PostgreSQL–based DB clusters that use Aurora Global Database have the following limitations:
Cluster cache management isn't supported for Aurora PostgreSQL secondary DB clusters that are part of Aurora global databases.
-
If the primary DB cluster of your global database is based on a replica of an Amazon RDS PostgreSQL instance, you can't create a secondary cluster. Don't attempt to create a secondary from that cluster using the AWS Management Console, the AWS CLI, or the
CreateDBClusterAPI operation. Attempts to do so time out, and the secondary cluster isn't created.
We recommend that you create secondary DB clusters for your global databases by using the same version of the Aurora DB engine as the primary. For more information, see Creating an Amazon Aurora global database.
