Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Architekturkomponenten eines Amazon Redshift Data Warehouse
Wir empfehlen Ihnen, ein grundlegendes Verständnis der Kernarchitekturkomponenten in einem Amazon Redshift Data Warehouse zu haben. Dieses Wissen kann Ihnen helfen, besser zu verstehen, wie Sie Ihre Abfragen und Tabellen für eine optimale Leistung entwerfen können.
Ein Data Warehouse in Amazon Redshift besteht aus den folgenden Kernarchitekturkomponenten:
-
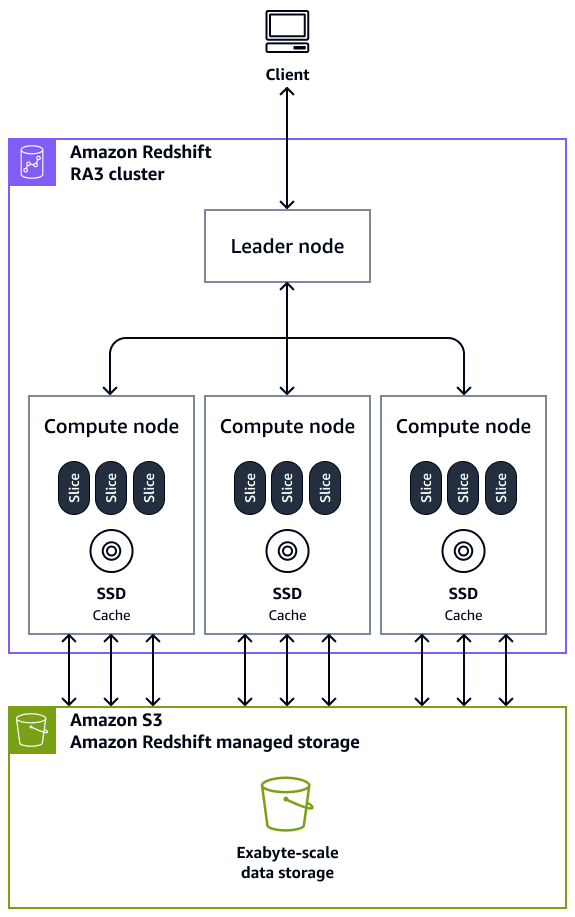
Cluster — Ein Cluster, der aus einem oder mehreren Rechenknoten besteht, ist die zentrale Infrastrukturkomponente eines Amazon Redshift Data Warehouse. Rechenknoten sind für externe Anwendungen transparent, aber Ihre Client-Anwendung interagiert nur direkt mit dem Leader-Knoten. Ein typischer Cluster hat zwei oder mehr Rechenknoten. Die Rechenknoten werden über den Leader-Knoten koordiniert.
-
Leader-Node — Ein Leader-Node verwaltet die Kommunikation für Client-Programme und alle Rechenknoten. Ein Leader-Node bereitet auch die Pläne für die Ausführung einer Abfrage vor, wann immer eine Anfrage an einen Cluster gesendet wird. Sobald die Pläne fertig sind, kompiliert der Leader-Knoten den Code, verteilt den kompilierten Code an die Rechenknoten und weist dann jedem Rechenknoten Datensegmente zu, um die Abfrageergebnisse zu verarbeiten.
-
Rechenknoten — Ein Rechenknoten führt eine Abfrage aus. Der Leader-Knoten kompiliert Code für einzelne Elemente des Plans zur Ausführung der Abfrage und weist den Code einzelnen Rechenknoten zu. Die Datenverarbeitungsknoten führen den kompilierten Code aus und senden Zwischenergebnisse zur endgültigen Aggregation an den Führungsknoten zurück. Jeder Rechenknoten hat seine eigene dedizierte CPU, seinen eigenen Arbeitsspeicher und seinen eigenen Festplattenspeicher. Bei zunehmendem Workload können Sie die Rechenkapazität und Speicherkapazität eines Clusters steigern, indem sie die Anzahl der Knoten erhöhen, ein Upgrade des Knotentyps ausführen oder beides.
-
Node Slice — Ein Rechenknoten ist in Einheiten unterteilt, die als Slices bezeichnet werden. Jedem Slice in einem Rechenknoten wird ein Teil des Arbeitsspeicher- und Festplattenspeichers des Knotens zugewiesen, wo er einen Teil der dem Knoten zugewiesenen Arbeitslast verarbeitet. Die Slices arbeiten dann parallel, um die Operation abzuschließen. Die Daten werden auf der Grundlage des Verteilungsstils und des Verteilungsschlüssels einer bestimmten Tabelle auf die Bereiche verteilt. Eine gleichmäßige Verteilung der Daten ermöglicht es Amazon Redshift, Workloads gleichmäßig Slices zuzuweisen und die Vorteile der Parallelverarbeitung zu maximieren. Die Anzahl der Slices pro Rechenknoten wird auf der Grundlage des Knotentyps festgelegt. Weitere Informationen finden Sie unter Cluster und Knoten in Amazon Redshift in der Amazon Redshift Redshift-Dokumentation.
-
Massive Parallelverarbeitung (MPP) — Amazon Redshift verwendet die MPP-Architektur, um Daten schnell zu verarbeiten, selbst komplexe Abfragen und riesige Datenmengen. Mehrere Rechenknoten führen denselben Abfragecode für Teile von Daten aus, um die Parallelverarbeitung zu maximieren.
-
Client-Anwendung — Amazon Redshift lässt sich in verschiedene Tools zum Extrahieren, Transformieren und Laden (ETL), Business Intelligence (BI), Data Mining und Analytik integrieren. Alle Client-Anwendungen kommunizieren nur über den Leader-Knoten mit dem Cluster.
Das folgende Diagramm zeigt, wie die Architekturkomponenten eines Amazon Redshift Data Warehouse zusammenarbeiten, um Abfragen zu beschleunigen.