Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anwendungsfall: Prognose von Behandlungsergebnissen und Wiederaufnahmequoten
KI-gestützte prädiktive Analysen bieten weitere Vorteile, da sie Patientenergebnisse prognostizieren und personalisierte Behandlungspläne ermöglichen. Dies kann die Patientenzufriedenheit und die Gesundheitsergebnisse verbessern. Durch die Integration dieser KI-Funktionen mit Amazon Bedrock und anderen Technologien können Gesundheitsdienstleister erhebliche Produktivitätssteigerungen erzielen, Kosten senken und die Gesamtqualität der Patientenversorgung verbessern.
Sie können medizinische Daten wie Krankengeschichten, klinische Notizen, Medikamente und Behandlungen in einem Wissensdiagramm speichern.
Mit dieser Lösung können Sie die Wahrscheinlichkeit einer erneuten Zulassung vorhersagen. Diese Prognosen können die Behandlungsergebnisse verbessern und die Gesundheitskosten senken. Diese Lösung kann auch Krankenhausärzten und -verwaltern helfen, sich auf Patienten zu konzentrieren, bei denen ein höheres Risiko einer erneuten Aufnahme besteht. Sie hilft ihnen auch dabei, proaktive Interventionen für diese Patienten durch Warnmeldungen, Self-Service und datengestützte Maßnahmen einzuleiten.
Übersicht über die Lösung
Diese Lösung verwendet ein RAG-Framework (Multi-Retriever Retrieval Augmented Generation) zur Analyse von Patientendaten. Es prognostiziert die Wahrscheinlichkeit einer erneuten Aufnahme in ein Krankenhaus für einzelne Patienten und hilft Ihnen bei der Berechnung eines Punkts für die Wahrscheinlichkeit einer Wiedereinweisung in ein Krankenhaus. Diese Lösung integriert die folgenden Funktionen:
-
Wissensdiagramm — Speichert strukturierte, chronologische Patientendaten wie Krankenhausbesuche, frühere Wiedereinweisungen, Symptome, Laborergebnisse, verschriebene Behandlungen und die Historie der Medikamenteneinnahme
-
Vektordatenbank — Speichert unstrukturierte klinische Daten wie Zusammenfassungen von Entlassungen, Arztnotizen und Aufzeichnungen über verpasste Termine oder gemeldete Arzneimittelnebenwirkungen
-
Fein abgestimmtes LLM — Nutzt sowohl strukturierte Daten aus dem Wissensgraphen als auch unstrukturierte Daten aus der Vektordatenbank, um Rückschlüsse auf das Verhalten eines Patienten, die Therapietreue und die Wahrscheinlichkeit einer erneuten Aufnahme zu ziehen
Die Risikoeinstufungsmodelle quantifizieren die Schlussfolgerungen aus dem LLM in numerischen Werten. Sie können die Punktzahlen zu einer Bewertung der Wiedereinweisungsneigung auf Krankenhausebene zusammenfassen. Dieser Wert definiert die Risikoexposition jedes Patienten, und Sie können ihn regelmäßig oder nach Bedarf berechnen. Alle Schlussfolgerungen und Risikobewertungen werden indexiert und in Amazon OpenSearch Service gespeichert, sodass Pflegemanager und Kliniker sie abrufen können. Durch die Integration eines dialogorientierten KI-Agenten in diese Vektordatenbank können Ärzte und Pflegemanager nahtlos Erkenntnisse für einzelne Patienten, für die gesamte Einrichtung oder für einzelne medizinische Fachgebiete gewinnen. Sie können auch automatische Warnmeldungen auf der Grundlage von Risikobewertungen einrichten, was proaktive Interventionen fördert.
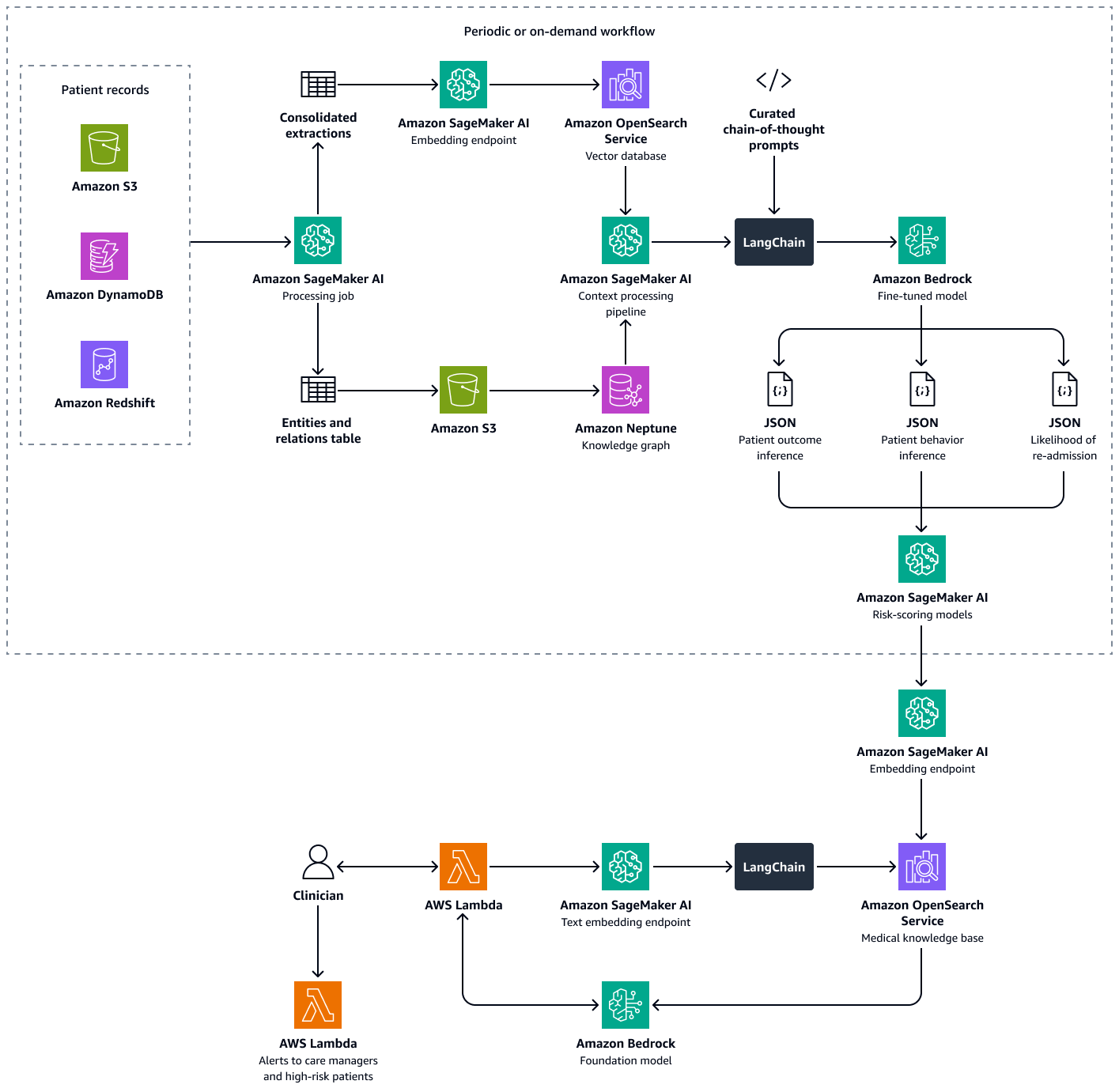
Der Aufbau dieser Lösung besteht aus den folgenden Schritten:
Schritt 1: Vorhersage der Behandlungsergebnisse mithilfe eines medizinischen Wissensgraphen
In Amazon Neptune können Sie einen Wissensgraphen verwenden, um zeitliches Wissen über Patientenbesuche und Behandlungsergebnisse im Zeitverlauf zu speichern. Die effektivste Methode, einen Wissensgraphen zu erstellen und zu speichern, ist die Verwendung eines Graphmodells und einer Graphdatenbank. Graphdatenbanken wurden speziell zum Speichern und Navigieren in Beziehungen entwickelt. Graphdatenbanken erleichtern die Modellierung und Verwaltung stark vernetzter Daten und verfügen über flexible Schemas.
Der Wissensgraph hilft Ihnen bei der Durchführung von Zeitreihenanalysen. Im Folgenden sind die wichtigsten Elemente der Graphdatenbank aufgeführt, die für die zeitliche Vorhersage von Behandlungsergebnissen verwendet werden:
-
Historische Daten — Frühere Diagnosen, fortgesetzte Medikamente, zuvor verwendete Medikamente und Laborergebnisse für den Patienten
-
Patientenbesuche (chronologisch) — Besuchstermine, Symptome, beobachtete Allergien, klinische Notizen, Diagnosen, Verfahren, Behandlungen, verschriebene Medikamente und Laborergebnisse
-
Symptome und klinische Parameter — Klinische und symptombasierte Informationen, einschließlich Schweregrad, Verlaufsmuster und Reaktion des Patienten auf das Medikament
Sie können die Erkenntnisse aus dem Medical Knowledge Graph nutzen, um ein LLM in Amazon Bedrock, wie Llama 3, zu optimieren. Sie optimieren das LLM anhand sequentieller Patientendaten über die Reaktion des Patienten auf eine Reihe von Medikamenten oder Behandlungen im Laufe der Zeit. Verwenden Sie einen beschrifteten Datensatz, der eine Reihe von Medikamenten oder Behandlungen sowie Daten zur Interaktion zwischen Patient und Klinik in vordefinierte Kategorien unterteilt, die den Gesundheitszustand eines Patienten angeben. Beispiele für diese Kategorien sind Verschlechterung des Gesundheitszustands, Verbesserung oder stabiler Fortschritt. Wenn der Arzt einen neuen Kontext über den Patienten und seine Symptome eingibt, kann das fein abgestimmte LLM die Muster aus dem Trainingsdatensatz verwenden, um das mögliche Behandlungsergebnis vorherzusagen.
Die folgende Abbildung zeigt die aufeinanderfolgenden Schritte, die zur Feinabstimmung eines LLM in Amazon Bedrock mithilfe eines gesundheitsspezifischen Trainingsdatensatzes erforderlich sind. Diese Daten können den Gesundheitszustand der Patienten und die Reaktionen auf Behandlungen im Laufe der Zeit beinhalten. Dieser Trainingsdatensatz würde dem Modell helfen, allgemeine Vorhersagen über die Behandlungsergebnisse zu treffen.
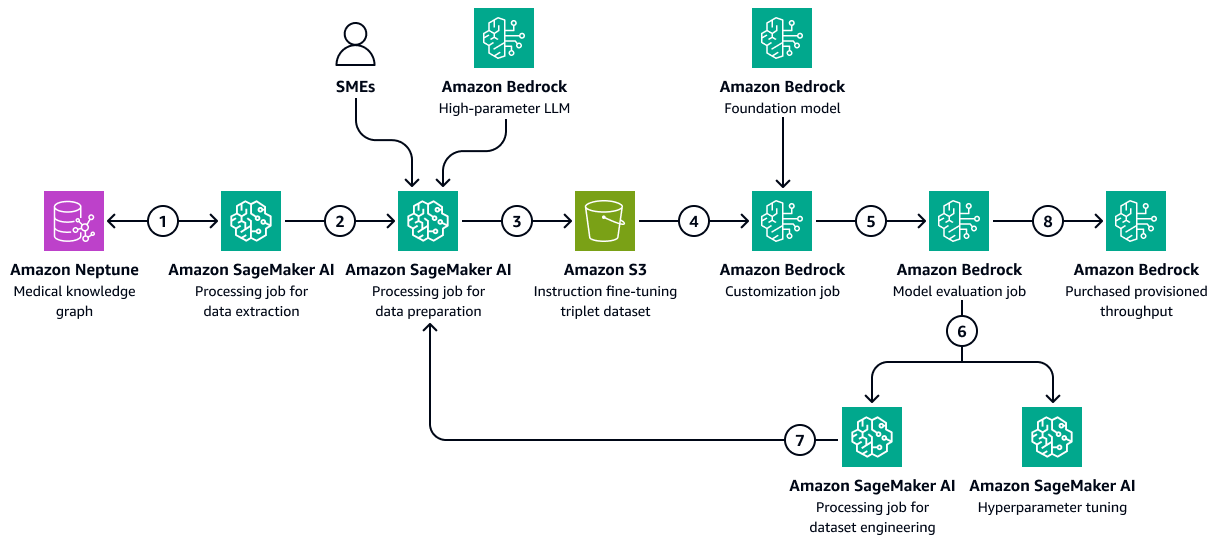
Das Diagramm zeigt den folgenden Workflow:
-
Der Amazon SageMaker KI-Datenextraktionsjob fragt den Wissensgraphen ab, um chronologische Daten über die Reaktionen verschiedener Patienten auf eine Reihe von Medikamenten oder Behandlungen im Laufe der Zeit abzurufen.
-
Der Job zur SageMaker KI-Datenvorbereitung beinhaltet ein Amazon Bedrock LLM und Beiträge von Fachexperten ()SMEs. Der Job unterteilt die aus dem Knowledge Graph abgerufenen Daten in vordefinierte Kategorien (z. B. Verschlechterung des Gesundheitszustands, Verbesserung oder stabiler Verlauf), die den Gesundheitszustand jedes Patienten angeben.
-
Bei der Aufgabe wird ein Datensatz zur Feinabstimmung erstellt, der die aus dem Wissensgraphen extrahierten Informationen, die chain-of-thought Eingabeaufforderungen und die Kategorie der Behandlungsergebnisse enthält. Es lädt diesen Trainingsdatensatz in einen Amazon S3 S3-Bucket hoch.
-
Ein Amazon Bedrock-Anpassungsjob verwendet diesen Trainingsdatensatz zur Feinabstimmung eines LLM.
-
Der Amazon Bedrock-Anpassungsjob integriert das Amazon Bedrock-Basismodell der Wahl in die Schulungsumgebung. Er startet den Feinabstimmungsjob und verwendet den Trainingsdatensatz und die von Ihnen konfigurierten Trainingshyperparameter.
-
Ein Amazon Bedrock-Evaluierungsjob bewertet das fein abgestimmte Modell mithilfe eines vorgefertigten Frameworks für die Modellbewertung.
-
Wenn das Modell verbessert werden muss, wird der Trainingsjob nach sorgfältiger Prüfung des Trainingsdatensatzes erneut mit mehr Daten ausgeführt. Wenn das Modell keine inkrementelle Leistungsverbesserung zeigt, sollten Sie auch eine Änderung der Trainingshyperparameter in Betracht ziehen.
-
Nachdem die Modellevaluierung die von den Geschäftsbeteiligten definierten Standards erfüllt hat, hosten Sie das fein abgestimmte Modell für den von Amazon Bedrock bereitgestellten Durchsatz.
Schritt 2: Vorhersage des Verhaltens von Patienten gegenüber verschriebenen Medikamenten oder Behandlungen
LLMs Fine-Tune kann klinische Notizen, Entlassungszusammenfassungen und andere patientenspezifische Dokumente aus dem temporalen medizinischen Wissensdiagramm verarbeiten. Sie können beurteilen, ob der Patient wahrscheinlich verschriebene Medikamente oder Behandlungen einhält.
In diesem Schritt wird der in erstellte Wissensgraph verwendetSchritt 1: Vorhersage der Behandlungsergebnisse mithilfe eines medizinischen Wissensgraphen. Der Wissensgraph enthält Daten aus dem Patientenprofil, einschließlich der bisherigen Adhärenz des Patienten als Knoten. Als Merkmale solcher Knoten werden auch Fälle von Nichteinhaltung von Medikamenten oder Behandlungen, Nebenwirkungen von Medikamenten, mangelndem Zugang zu Medikamenten oder Kostenbarrieren oder komplexe Dosierungsschemata berücksichtigt.
Fine-tuned LLMs kann frühere Daten zur Verschreibungserfüllung aus dem Medical Knowledge Graph und beschreibende Zusammenfassungen der klinischen Notizen aus einer Amazon OpenSearch Service-Vektordatenbank nutzen. In diesen klinischen Notizen können häufig versäumte Termine oder die Nichteinhaltung von Behandlungen erwähnt werden. Das LLM kann diese Hinweise verwenden, um die Wahrscheinlichkeit einer future Nichteinhaltung vorherzusagen.
-
Bereiten Sie die Eingabedaten wie folgt vor:
-
Strukturierte Daten — Extrahieren Sie aktuelle Patientendaten, z. B. die letzten drei Besuche und die Laborergebnisse, aus dem medizinischen Wissensdiagramm.
-
Unstrukturierte Daten — Rufen Sie die neuesten klinischen Notizen aus der Amazon OpenSearch Service-Vektordatenbank ab.
-
-
Erstellen Sie eine Eingabeaufforderung, die die Krankengeschichte und den aktuellen Kontext enthält. Im Folgenden finden Sie ein Beispiel für eine Eingabeaufforderung:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Übergeben Sie die Aufforderung an das fein abgestimmte LLM. Das LLM verarbeitet die Aufforderung und prognostiziert das Ergebnis. Im Folgenden finden Sie ein Beispiel für eine Antwort des LLM:
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
Analysieren Sie die Antwort des Modells, um die Kategorie der prognostizierten Ergebnisse zu extrahieren. Bei der Kategorie für die Beispielantwort im vorherigen Schritt könnte es sich beispielsweise um eine hohe Wahrscheinlichkeit einer Nichteinhaltung handeln.
-
(Optional) Verwenden Sie Modelllogits oder zusätzliche Methoden, um Konfidenzwerte zuzuweisen. Logits sind die nicht normalisierten Wahrscheinlichkeiten, dass das Objekt zu einer bestimmten Klasse oder Kategorie gehört.
Schritt 3: Vorhersage der Wahrscheinlichkeit einer erneuten Aufnahme von Patienten
Wiedereinweisungen in Krankenhäuser sind aufgrund der hohen Kosten der Gesundheitsverwaltung und ihrer Auswirkungen auf das Wohlbefinden der Patienten ein großes Problem. Die Berechnung der Wiedereinweisungsraten in Krankenhäuser ist eine Möglichkeit, die Qualität der Patientenversorgung und die Leistung eines Gesundheitsdienstleisters zu messen.
Um die Wiederaufnahmequote zu berechnen, haben Sie einen Indikator definiert, z. B. eine Wiederaufnahmequote von 7 Tagen. Dieser Indikator gibt den Prozentsatz der aufgenommenen Patienten an, die innerhalb von sieben Tagen nach der Entlassung zu einem ungeplanten Besuch ins Krankenhaus zurückkehren. Um die Wahrscheinlichkeit einer erneuten Aufnahme eines Patienten vorherzusagen, kann ein fein abgestimmtes LLM Zeitdaten aus dem medizinischen Wissensdiagramm verwenden, das Sie in erstellt haben. Schritt 1: Vorhersage der Behandlungsergebnisse mithilfe eines medizinischen Wissensgraphen In diesem Wissensdiagramm werden chronologische Aufzeichnungen über Begegnungen, Behandlungen, Medikamente und Symptome mit Patienten geführt. Diese Datensätze enthalten Folgendes:
-
Dauer seit der letzten Entlassung des Patienten
-
Reaktion des Patienten auf frühere Behandlungen und Medikamente
-
Das Fortschreiten von Symptomen oder Zuständen im Laufe der Zeit
Sie können diese Zeitreihenereignisse verarbeiten, um anhand einer kuratierten Systemaufforderung die Wahrscheinlichkeit einer erneuten Aufnahme eines Patienten vorherzusagen. Die Aufforderung gibt die Prognoselogik an das fein abgestimmte LLM weiter.
-
Bereiten Sie die Eingabedaten wie folgt vor:
-
Verlauf der Therapietreue — Extrahieren Sie Daten zur Medikamentenabholung, Häufigkeit der Medikamentennachfüllung, Diagnose- und Medikamentendetails, chronologische Krankengeschichte und andere Informationen aus der medizinischen Wissensgrafik.
-
Verhaltensindikatoren — Rufen Sie klinische Notizen zu verpassten Terminen und von Patienten gemeldeten Nebenwirkungen ab und fügen Sie sie hinzu.
-
-
Erstellen Sie eine Eingabeaufforderung, die den Verlauf der Einhaltung und die Verhaltensindikatoren enthält. Im Folgenden finden Sie ein Beispiel für eine Eingabeaufforderung:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Übergeben Sie die Aufforderung an das fein abgestimmte LLM. Das LLM bearbeitet die Aufforderung und prognostiziert die Wahrscheinlichkeit einer erneuten Zulassung sowie die Gründe dafür. Im Folgenden finden Sie ein Beispiel für eine Antwort des LLM:
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
Ordnen Sie die Vorhersage in eine standardisierte Skala ein, z. B. niedrig, mittel oder hoch.
-
Überprüfen Sie die vom LLM vorgelegten Überlegungen und identifizieren Sie die wichtigsten Faktoren, die zur Vorhersage beitragen.
-
Ordnen Sie die qualitativen Ergebnisse quantitativen Werten zu. Ein sehr hoher Wert könnte beispielsweise einer Wahrscheinlichkeit von 0,9 entsprechen.
-
Verwenden Sie Validierungsdatensätze, um die Modellergebnisse anhand der tatsächlichen Wiederzulassungsraten zu kalibrieren.
Schritt 4: Berechnung des Punkts für die Wahrscheinlichkeit einer Wiedereinweisung ins Krankenhaus
Als Nächstes berechnen Sie einen Wert für die Wahrscheinlichkeit einer erneuten Aufnahme in ein Krankenhaus pro Patient. Dieser Wert spiegelt die Nettoauswirkung der drei Analysen wider, die in den vorherigen Schritten durchgeführt wurden: potenzielle Behandlungsergebnisse, Verhalten der Patienten gegenüber Medikamenten und Behandlungen sowie Wahrscheinlichkeit einer erneuten Aufnahme von Patienten. Indem Sie den Wert der Wiedereinweisungsneigung auf Patientenebene nach Fachgebieten und dann auf Krankenhausebene aggregieren, können Sie Erkenntnisse für Kliniker, Pflegemanager und Administratoren gewinnen. Der Wert für die Wahrscheinlichkeit einer Wiederaufnahme in ein Krankenhaus hilft Ihnen dabei, die Gesamtleistung nach Einrichtung, Fachgebiet oder Erkrankung zu beurteilen. Anschließend können Sie diesen Wert verwenden, um proaktive Maßnahmen zu ergreifen.
-
Weisen Sie jedem der verschiedenen Faktoren Gewichte zu (Prognose des Ergebnisses, Wahrscheinlichkeit der Einhaltung der Vorschriften, Wiederzulassung). Im Folgenden sind Beispielgewichte aufgeführt:
-
Gewicht für die Vorhersage des Ergebnisses: 0,4
-
Gewicht bei der Vorhersage der Einhaltung der Regeln: 0,3
-
Gewicht der Wahrscheinlichkeit einer erneuten Zulassung: 0,3
-
-
Verwenden Sie die folgende Berechnung, um die Gesamtpunktzahl zu berechnen:
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
Stellen Sie sicher, dass sich alle Einzelwerte auf derselben Skala befinden, z. B. 0 bis 1.
-
Definieren Sie die Schwellenwerte für Maßnahmen. Beispielsweise lösen Werte über 0,7 Warnmeldungen aus.
Auf der Grundlage der oben genannten Analysen und der Bewertung der Wiederaufnahmebereitschaft eines Patienten können Ärzte oder Pflegemanager Warnmeldungen einrichten, um ihre einzelnen Patienten auf der Grundlage des berechneten Scores zu überwachen. Liegt der Wert über einem vordefinierten Schwellenwert, werden sie benachrichtigt, wenn dieser Schwellenwert erreicht ist. Dies hilft Pflegemanagern, bei der Erstellung von Entlassungsplänen für ihre Patienten proaktiv und nicht reaktiv vorzugehen. Speichern Sie die Ergebnisse, das Verhalten und die Wahrscheinlichkeit der Wiederaufnahme von Patienten in indexierter Form in einer Amazon OpenSearch Service-Vektordatenbank, sodass das Pflegepersonal sie mithilfe eines Konversations-AI-Agenten problemlos abrufen kann.
Das folgende Diagramm zeigt den Arbeitsablauf eines KI-Konversationsassistenten, den ein Arzt oder Pflegemanager nutzen kann, um Erkenntnisse über die Behandlungsergebnisse, das erwartete Verhalten und die Wahrscheinlichkeit einer erneuten Aufnahme von Patienten abzurufen. Benutzer können Erkenntnisse auf Patienten-, Abteilungs- oder Krankenhausebene abrufen. Der KI-Agent ruft diese Erkenntnisse ab, die in indizierter Form in einer Amazon OpenSearch Service-Vektordatenbank gespeichert werden. Der Mitarbeiter verwendet die Abfrage, um relevante Daten abzurufen, und gibt maßgeschneiderte Antworten, einschließlich Handlungsempfehlungen für Patienten, bei denen ein hohes Risiko besteht, erneut aufgenommen zu werden. Je nach Risikograd kann der Mitarbeiter auch Erinnerungen für Patienten und Pflegepersonal einrichten.
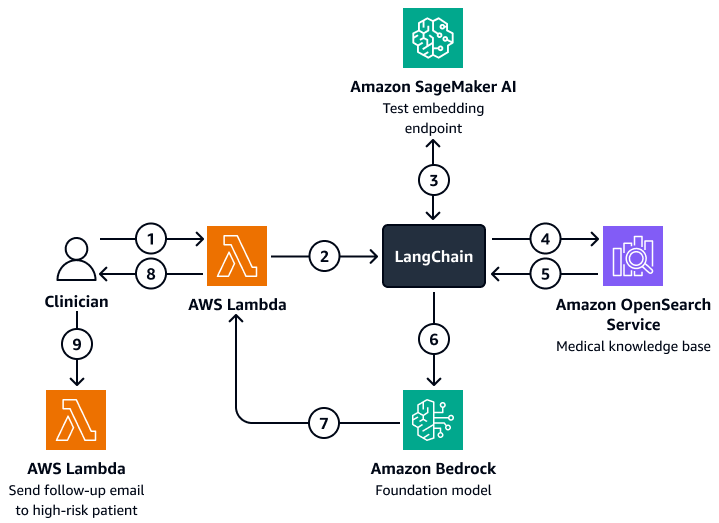
Das Diagramm zeigt den folgenden Workflow:
-
Der Kliniker stellt eine Frage an einen KI-Konversationsagenten, der eine Funktion beherbergt. AWS Lambda
-
Die Lambda-Funktion initiiert eine LangChain Agent.
-
Das Tool LangChain Der Agent sendet die Frage des Benutzers an einen Amazon SageMaker AI-Texteinbettungsendpunkt. Der Endpunkt bettet die Frage ein.
-
Das Tool LangChain Der Mitarbeiter leitet die eingebettete Frage an eine medizinische Wissensdatenbank in Amazon OpenSearch Service weiter.
-
Amazon OpenSearch Service gibt die spezifischen Erkenntnisse, die für die Benutzeranfrage am relevantesten sind, an die LangChain Agent.
-
Das Tool LangChain Agenten senden die Anfrage und den abgerufenen Kontext aus der Wissensdatenbank an ein Amazon Bedrock Foundation-Modell.
-
Das Amazon Bedrock Foundation-Modell generiert eine Antwort und sendet sie an die Lambda-Funktion.
-
Die Lambda-Funktion gibt die Antwort an den Arzt zurück.
-
Der Arzt initiiert eine Lambda-Funktion, die eine Folge-E-Mail an einen Patienten sendet, bei dem ein hohes Risiko einer erneuten Aufnahme besteht.
Ausrichtung auf das AWS Well-Architected Framework
-
Operational Excellence — Bei der Lösung handelt es sich um ein entkoppeltes, automatisiertes System, das Amazon Bedrock verwendet und AWS Lambda Warnmeldungen in Echtzeit ausgibt.
-
Sicherheit — Diese Lösung wurde entwickelt, um Gesundheitsvorschriften wie HIPAA zu erfüllen. Sie können auch Verschlüsselung, detaillierte Zugriffskontrolle und Amazon Bedrock Guardrails implementieren, um Patientendaten zu schützen.
-
Zuverlässigkeit — Die Architektur verwendet fehlertolerante, serverlose Systeme. AWS-Services
-
Leistungseffizienz — Amazon OpenSearch Service und die Feinabstimmung LLMs können schnelle und genaue Prognosen liefern.
-
Kostenoptimierung — Serverlose Technologien und pay-per-inference Modelle tragen zur Kostenminimierung bei. Die Verwendung eines fein abgestimmten LLM kann zwar mit zusätzlichen Kosten verbunden sein, das Modell verwendet jedoch einen RAG-Ansatz, der den Daten- und Rechenaufwand für den Feinabstimmungsprozess reduziert.
-
Nachhaltigkeit — Die Architektur minimiert den Ressourcenverbrauch durch den Einsatz einer serverlosen Infrastruktur. Sie unterstützt auch effiziente, skalierbare Abläufe im Gesundheitswesen.
