Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anwendungsfall: Verwaltung und Weiterbildung Ihres Gesundheitspersonals
Die Umsetzung von Strategien zur Transformation und Weiterbildung von Talenten hilft den Mitarbeitern, neue Technologien und Praktiken im medizinischen Bereich und im Gesundheitswesen weiterhin kompetent einzusetzen. Proaktive Weiterbildungsinitiativen stellen sicher, dass medizinisches Fachpersonal eine qualitativ hochwertige Patientenversorgung bieten, die betriebliche Effizienz optimieren und die gesetzlichen Standards einhalten kann. Darüber hinaus fördert die Transformation von Talenten eine Kultur des kontinuierlichen Lernens. Dies ist entscheidend für die Anpassung an die sich verändernde Gesundheitslandschaft und die Bewältigung neuer Herausforderungen im Bereich der öffentlichen Gesundheit. Traditionelle Schulungsansätze wie Präsenzunterricht und statische Lernmodule bieten einheitliche Inhalte für ein breites Publikum. Ihnen mangelt es oft an personalisierten Lernwegen, die entscheidend sind, um auf die spezifischen Bedürfnisse und das Qualifikationsniveau der einzelnen Praktiker einzugehen. Diese one-size-fits-all Strategie kann zu mangelndem Engagement und einer suboptimalen Wissenserhaltung führen.
Folglich müssen Gesundheitsorganisationen innovative, skalierbare und technologiegestützte Lösungen einsetzen, mit denen sich die Unterschiede für jeden ihrer Mitarbeiter in ihrem aktuellen Zustand und in ihrem potenziellen future Zustand ermitteln lassen. Diese Lösungen sollten hyperpersonalisierte Lernpfade und die richtigen Lerninhalte empfehlen. Dies bereitet die Belegschaft effektiv auf die future des Gesundheitswesens vor.
In der Gesundheitsbranche können Sie generative KI einsetzen, um Ihre Belegschaft besser zu verstehen und weiterzubilden. Durch die Verbindung von großen Sprachmodellen (LLMs) und fortgeschrittenen Retrievern können Unternehmen verstehen, über welche Fähigkeiten sie derzeit verfügen, und Schlüsselkompetenzen identifizieren, die in future erforderlich sein könnten. Diese Informationen helfen Ihnen, diese Lücke zu schließen, indem Sie neue Mitarbeiter einstellen und die aktuelle Belegschaft weiterbilden. Mithilfe von Amazon Bedrock und Knowledge Graphs können Organisationen im Gesundheitswesen domänenspezifische Anwendungen entwickeln, die kontinuierliches Lernen und die Weiterentwicklung von Fähigkeiten ermöglichen.
Das durch diese Lösung bereitgestellte Wissen hilft Ihnen dabei, Talente effektiv zu verwalten, die Leistung Ihrer Belegschaft zu optimieren, den Unternehmenserfolg zu fördern, vorhandene Fähigkeiten zu identifizieren und eine Talentstrategie zu entwickeln. Diese Lösung kann Ihnen helfen, diese Aufgaben innerhalb von Wochen statt Monaten zu erledigen.
Übersicht über die Lösung
Bei dieser Lösung handelt es sich um ein Framework zur Transformation von Talenten im Gesundheitswesen, das aus den folgenden Komponenten besteht:
-
Intelligenter Lebenslauf-Parser — Diese Komponente kann den Lebenslauf eines Kandidaten lesen und Kandidateninformationen, einschließlich Fähigkeiten, präzise extrahieren. Intelligente Lösung zur Informationsextraktion, die auf dem fein abgestimmten Llama 2-Modell in Amazon Bedrock basiert und auf einem firmeneigenen Schulungsdatensatz basiert, der Lebensläufe und Talentprofile aus mehr als 19 Branchen umfasst. Dieser LLM-basierte Prozess spart Hunderte von Stunden, da er die manuelle Überprüfung von Lebensläufen und die Zuordnung von Top-Kandidaten zu offenen Stellen automatisiert.
-
Knowledge Graph — Ein Wissensgraph, der auf Amazon Neptune basiert, einer vereinheitlichten Sammlung von Talentinformationen, einschließlich der Rollen- und Qualifikationstaxonomie des Unternehmens sowie der Branche. Er erfasst die Semantik von Talenten im Gesundheitswesen anhand von Definitionen von Fähigkeiten, Rollen und deren Eigenschaften, Beziehungen und logischen Einschränkungen.
-
Qualifikationsontologie — Die Entdeckung von Qualifikationsnähe zwischen den Fähigkeiten der Kandidaten und den Fähigkeiten im Idealzustand oder in der future (abgerufen mithilfe eines Wissensgraphen) wird durch Ontologiealgorithmen erreicht, die die semantische Ähnlichkeit zwischen Kandidatenkompetenzen und Fähigkeiten im Zielstatus messen.
-
Lernweg und Lerninhalte — Bei dieser Komponente handelt es sich um eine Engine für Lernempfehlungen, die auf Grundlage der identifizierten Qualifikationslücken die richtigen Lerninhalte aus einem Katalog von Lernmaterialien beliebiger Anbieter empfehlen kann. Identifizierung der optimalen Weiterbildungswege für jeden Kandidaten durch Analyse der Qualifikationslücken und Empfehlung priorisierter Lerninhalte, um jedem Kandidaten eine reibungslose und kontinuierliche berufliche Entwicklung während des Übergangs zu einer neuen Rolle zu ermöglichen.
Diese cloudbasierte, automatisierte Lösung basiert auf Diensten für maschinelles Lernen LLMs, Wissensgraphen und Retrieval Augmented Generation (RAG). Es kann skaliert werden, um Zehntausende von Lebensläufen in kürzester Zeit zu verarbeiten, sofortige Kandidatenprofile zu erstellen, Lücken in ihrem aktuellen oder potenziellen future Status zu identifizieren und dann effizient die richtigen Lerninhalte zu empfehlen, um diese Lücken zu schließen.
Die folgende Abbildung zeigt den end-to-end Ablauf des Frameworks. Die Lösung basiert auf der Feinabstimmung LLMs in Amazon Bedrock. Diese LLMs rufen Daten aus der Wissensdatenbank für Talente im Gesundheitswesen in Amazon Neptune ab. Datengestützte Algorithmen geben Empfehlungen für optimale Lernwege für jeden Kandidaten.
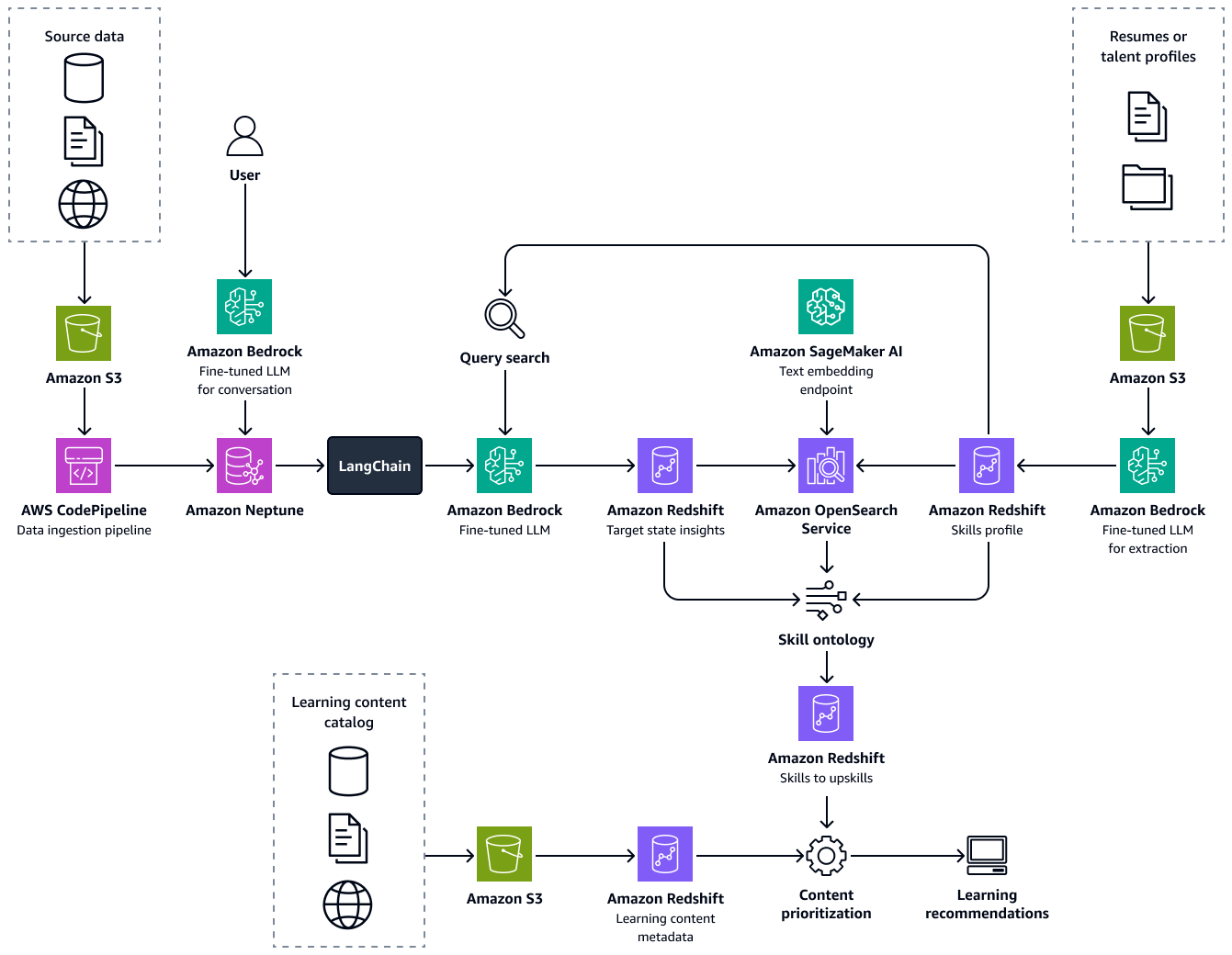
Der Aufbau dieser Lösung besteht aus den folgenden Schritten:
Schritt 1: Extraktion von Talentinformationen und Erstellung eines Kompetenzprofils
Zunächst optimieren Sie ein umfangreiches Sprachmodell wie Llama 2 in Amazon Bedrock mit einem benutzerdefinierten Datensatz. Dadurch wird das LLM an den Anwendungsfall angepasst. Während der Schulung extrahieren Sie präzise und konsistent wichtige Talentattribute aus Lebensläufen von Kandidaten oder ähnlichen Talentprofilen. Zu diesen Talentattributen gehören Fähigkeiten, aktuelle Berufsbezeichnung, Berufsbezeichnungen mit Zeiträumen, Ausbildung und Zertifizierungen. Weitere Informationen finden Sie in der Amazon Bedrock-Dokumentation unter Passen Sie Ihr Modell an, um seine Leistung für Ihren Anwendungsfall zu verbessern.
Die folgende Abbildung zeigt den Prozess zur Feinabstimmung eines Modells zur Analyse von Lebensläufen mithilfe von Amazon Bedrock. Sowohl echte als auch synthetisch erstellte Lebensläufe werden an ein LLM weitergeleitet, um wichtige Informationen zu extrahieren. Eine Gruppe von Datenwissenschaftlern validiert die extrahierten Informationen anhand des ursprünglichen Rohtextes. Die extrahierten Informationen werden dann mithilfe von chain-of-thought
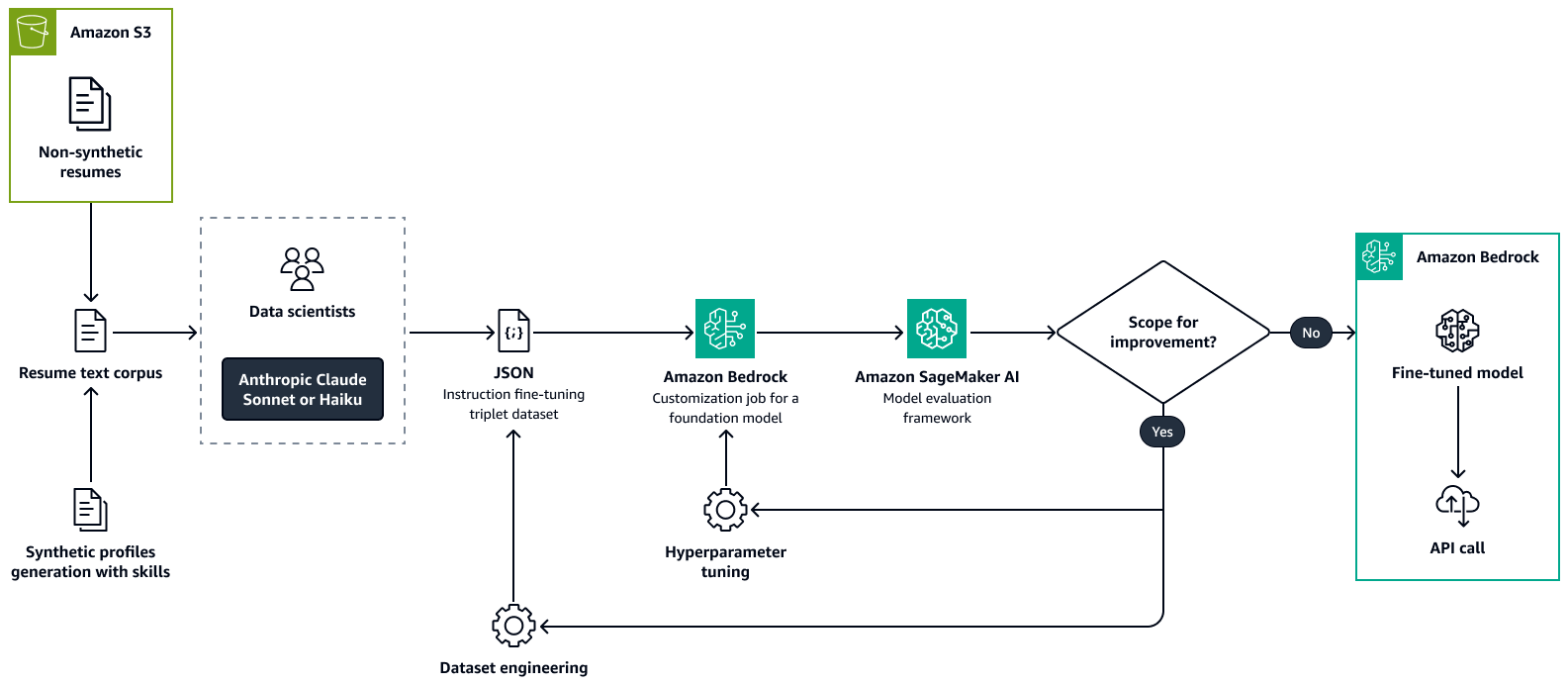
Schritt 2: Anhand eines role-to-skill Wissensgraphen die Relevanz ermitteln
Als Nächstes erstellen Sie ein Wissensdiagramm, das die Fähigkeiten und die Rollentaxonomie Ihrer Organisation und anderer Organisationen in der Gesundheitsbranche zusammenfasst. Diese erweiterte Wissensdatenbank basiert auf aggregierten Talent- und Unternehmensdaten in Amazon Redshift. Sie können Talentdaten von einer Reihe von Anbietern von Arbeitsmarktdaten sowie aus unternehmensspezifischen strukturierten und unstrukturierten Datenquellen wie ERP-Systemen (Enterprise Resource Planning), einem Personalinformationssystem (HRIS), Lebensläufen von Mitarbeitern, Stellenbeschreibungen und Dokumenten zur Talentarchitektur sammeln.
Erstellen Sie den Wissensgraphen auf Amazon Neptune. Knoten stehen für Fähigkeiten und Rollen, und Kanten stehen für die Beziehungen zwischen ihnen. Reichern Sie dieses Diagramm mit Metadaten an, um Details wie den Namen der Organisation, die Branche, die Berufsgruppe, die Art der Qualifikation, den Rollentyp und Branchenkennzeichnungen aufzunehmen.
Als Nächstes entwickeln Sie eine Graph Retrieval Augmented Generation-Anwendung (Graph RAG). Graph RAG ist ein RAG-Ansatz, der Daten aus einer Graphdatenbank abruft. Im Folgenden sind die Komponenten der Graph RAG-Anwendung aufgeführt:
-
Integration mit einem LLM in Amazon Bedrock — Die Anwendung verwendet ein LLM in Amazon Bedrock für das Verständnis natürlicher Sprache und die Generierung von Abfragen. Benutzer können mithilfe natürlicher Sprache mit dem System interagieren. Dadurch ist es auch für technisch nicht versierte Akteure zugänglich.
-
Orchestrierung und Informationsabruf — Verwendung oder LlamaIndex
LangChain Orchestratoren, um die Integration zwischen dem LLM und dem Neptune Knowledge Graph zu erleichtern. Sie verwalten den Prozess der Konvertierung von Abfragen in natürlicher Sprache in OpenCypher-Abfragen. Anschließend führen sie die Abfragen im Knowledge Graph aus. Verwenden Sie Prompt Engineering, um das LLM über bewährte Methoden für die Erstellung von OpenCypher-Abfragen zu informieren. Dies hilft bei der Optimierung der Abfragen, um den entsprechenden Untergraphen abzurufen, der alle relevanten Entitäten und Beziehungen zu den abgefragten Rollen und Fähigkeiten enthält. -
Generierung von Erkenntnissen — Das LLM in Amazon Bedrock verarbeitet die abgerufenen Grafikdaten. Es generiert detaillierte Einblicke in den aktuellen Status und prognostiziert future Zustände für die abgefragte Rolle und die damit verbundenen Fähigkeiten.
Die folgende Abbildung zeigt die Schritte zum Erstellen eines Wissensgraphen aus Quelldaten. Sie übergeben die strukturierten und unstrukturierten Quelldaten an die Datenerfassungspipeline. Die Pipeline extrahiert Informationen und wandelt sie in eine CSV-Bulk-Load-Formation um, die mit Amazon Neptune kompatibel ist. Die Bulk-Loader-API lädt die CSV-Dateien, die in einem Amazon S3 S3-Bucket gespeichert sind, in den Neptune Knowledge Graph hoch. Bei Benutzeranfragen in Bezug auf den future Status von Talenten, relevanten Rollen oder Fähigkeiten interagiert das fein abgestimmte LLM in Amazon Bedrock mit dem Knowledge Graph über eine LangChain Orchestrator. Der Orchestrator ruft den relevanten Kontext aus dem Knowledge Graph ab und überträgt die Antworten in die Insights-Tabelle in Amazon Redshift. Das Tool LangChain Der Orchestrator konvertiert wie Graph QAChain
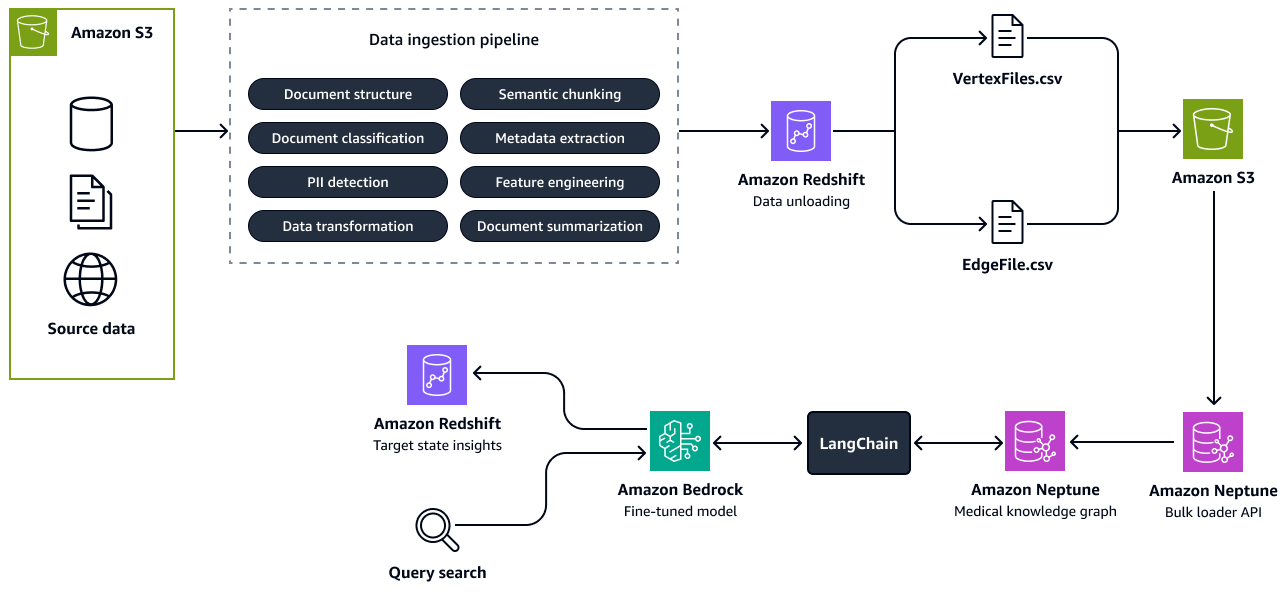
Schritt 3: Identifizierung von Qualifikationslücken und Empfehlung von Schulungen
In diesem Schritt berechnen Sie genau die Nähe zwischen dem aktuellen Status eines medizinischen Fachpersonals und potenziellen future Funktionen in diesem Bundesstaat. Zu diesem Zweck führen Sie eine Qualifikationsaffinitätsanalyse durch, indem Sie die Fähigkeiten der Person mit der beruflichen Rolle vergleichen. In einer Amazon OpenSearch Service-Vektordatenbank speichern Sie Informationen zur Skill-Taxonomie und Skill-Metadaten, wie z. B. die Beschreibung der Fähigkeiten, den Fertigkeitstyp und die Skill-Cluster. Verwenden Sie ein Amazon Bedrock-Einbettungsmodell, z. B. Amazon Titan Text Embeddings-Modelle, um die identifizierte Schlüsselkompetenz in Vektoren einzubetten. Mithilfe einer Vektorsuche rufen Sie die Beschreibungen der Fähigkeiten im aktuellen Status und der Fähigkeiten im Zielstatus ab und führen eine Ontologieanalyse durch. Die Analyse liefert Näherungswerte zwischen den Qualifikationspaaren im aktuellen Bundesstaat und im Zielstaat. Für jedes Paar verwenden Sie die berechneten Ontologiewerte, um die Lücken in den Qualifikationsaffinitäten zu identifizieren. Anschließend empfehlen Sie den optimalen Weiterbildungsweg, den der Kandidat bei Rollenwechseln in Betracht ziehen kann.
Für jede Rolle beinhaltet die Empfehlung der richtigen Lerninhalte für die Weiterbildung oder Umschulung einen systematischen Ansatz, der mit der Erstellung eines umfassenden Katalogs von Lerninhalten beginnt. Dieser Katalog, den Sie in einer Amazon Redshift Redshift-Datenbank speichern, fasst Inhalte verschiedener Anbieter zusammen und enthält Metadaten wie Inhaltsdauer, Schwierigkeitsgrad und Lernmodus. Der nächste Schritt besteht darin, die in den einzelnen Inhalten enthaltenen Schlüsselkompetenzen zu extrahieren und sie dann den individuellen Fähigkeiten zuzuordnen, die für die Zielrolle erforderlich sind. Sie erreichen diese Zuordnung, indem Sie die Reichweite der Inhalte anhand einer Analyse der Nähe zu den Fähigkeiten analysieren. Bei dieser Analyse wird bewertet, inwieweit die im Inhalt vermittelten Fähigkeiten mit den für die Rolle angestrebten Fähigkeiten übereinstimmen. Die Metadaten spielen eine entscheidende Rolle bei der Auswahl der für jede Fähigkeit am besten geeigneten Inhalte und stellen sicher, dass die Lernenden maßgeschneiderte Empfehlungen erhalten, die ihren Lernbedürfnissen entsprechen. Verwenden Sie es LLMs in Amazon Bedrock, um Fähigkeiten aus den Inhaltsmetadaten zu extrahieren, Feature-Engineering durchzuführen und die Inhaltsempfehlungen zu validieren. Dies verbessert die Genauigkeit und Relevanz des Weiterbildungs- oder Umschulungsprozesses.
Ausrichtung auf das AWS Well-Architected Framework
Die Lösung entspricht allen sechs Säulen des AWS Well-Architected Framework
-
Operative Exzellenz — Eine modulare, automatisierte Pipeline verbessert die betriebliche Exzellenz. Die wichtigsten Komponenten der Pipeline sind entkoppelt und automatisiert, was schnellere Modellaktualisierungen und eine einfachere Überwachung ermöglicht. Darüber hinaus unterstützen automatisierte Trainingspipelines eine schnellere Veröffentlichung von fein abgestimmten Modellen.
-
Sicherheit — Diese Lösung verarbeitet sensible und persönlich identifizierbare Informationen (PII), wie z. B. Daten in Lebensläufen und Talentprofilen. Implementieren Sie in AWS Identity and Access Management (IAM) detaillierte Richtlinien zur Zugriffskontrolle und stellen Sie sicher, dass nur autorisiertes Personal Zugriff auf diese Daten hat.
-
Zuverlässigkeit — Die Lösung verwendet Neptune AWS-Services, Amazon Bedrock und OpenSearch Service, die Fehlertoleranz, hohe Verfügbarkeit und ununterbrochenen Zugriff auf Erkenntnisse auch bei hoher Nachfrage bieten.
-
Leistungseffizienz — Die LLMs in Amazon Bedrock und OpenSearch Service fein abgestimmten Vektordatenbanken sind darauf ausgelegt, große Datenmengen schnell und präzise zu verarbeiten, um zeitnahe, personalisierte Lernempfehlungen zu liefern.
-
Kostenoptimierung — Diese Lösung verwendet einen RAG-Ansatz, der den Bedarf an kontinuierlichem Vortraining von Modellen reduziert. Anstatt das gesamte Modell wiederholt zu verfeinern, optimiert das System nur bestimmte Prozesse, wie das Extrahieren von Informationen aus Lebensläufen und die Strukturierung der Ergebnisse. Dies führt zu erheblichen Kosteneinsparungen. Durch die Minimierung der Häufigkeit und des Umfangs ressourcenintensiver Modellschulungen und durch die Nutzung von pay-per-use Cloud-Diensten können Organisationen im Gesundheitswesen ihre Betriebskosten optimieren und gleichzeitig eine hohe Leistung aufrechterhalten.
-
Nachhaltigkeit — Diese Lösung nutzt skalierbare, Cloud-native Dienste, die Rechenressourcen dynamisch zuweisen. Dies reduziert den Energieverbrauch und die Umweltbelastung und unterstützt gleichzeitig groß angelegte, datenintensive Initiativen zur Talenttransformation.
