Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Retriever für RAG-Workflows
In diesem Abschnitt wird erklärt, wie Sie einen Retriever erstellen. Sie können eine vollständig verwaltete semantische Suchlösung wie Amazon Kendra verwenden oder mithilfe einer Vektordatenbank eine benutzerdefinierte semantische Suche erstellen. AWS
Bevor Sie sich mit den Retrieveroptionen befassen, stellen Sie sicher, dass Sie die drei Schritte des Vektorsuchprozesses verstanden haben:
-
Sie teilen die Dokumente, die indexiert werden müssen, in kleinere Teile auf. Dies wird als Chunking bezeichnet.
-
Sie verwenden einen Prozess namens Einbetten
, um jeden Chunk in einen mathematischen Vektor umzuwandeln. Anschließend indizieren Sie jeden Vektor in einer Vektordatenbank. Der Ansatz, mit dem Sie die Dokumente indizieren, beeinflusst die Geschwindigkeit und Genauigkeit der Suche. Der Indizierungsansatz hängt von der Vektordatenbank und den von ihr bereitgestellten Konfigurationsoptionen ab. -
Sie konvertieren die Benutzerabfrage mit demselben Verfahren in einen Vektor. Der Retriever durchsucht die Vektordatenbank nach Vektoren, die dem Abfragevektor des Benutzers ähnlich sind. Die Ähnlichkeit
wird anhand von Metriken wie der euklidischen Distanz, der Kosinusdistanz oder dem Punktprodukt berechnet.
In diesem Handbuch wird beschrieben, wie Sie mit den folgenden Diensten AWS-Services oder Diensten von Drittanbietern eine benutzerdefinierte Abruf-Ebene erstellen können: AWS
Amazon Kendra
Amazon Kendra ist ein vollständig verwalteter, intelligenter Suchservice, der natürliche Sprachverarbeitung und fortschrittliche Algorithmen für maschinelles Lernen verwendet, um spezifische Antworten auf Suchfragen aus Ihren Daten zurückzugeben. Amazon Kendra hilft Ihnen dabei, Dokumente aus mehreren Quellen direkt aufzunehmen und die Dokumente abzufragen, nachdem sie erfolgreich synchronisiert wurden. Durch den Synchronisierungsprozess wird die erforderliche Infrastruktur geschaffen, um eine Vektorsuche im aufgenommenen Dokument zu erstellen. Daher benötigt Amazon Kendra nicht die traditionellen drei Schritte des Vektorsuchprozesses. Nach der ersten Synchronisierung können Sie einen definierten Zeitplan verwenden, um die laufende Datenaufnahme zu handhaben.
Im Folgenden sind die Vorteile der Verwendung von Amazon Kendra for RAG aufgeführt:
-
Sie müssen keine Vektordatenbank verwalten, da Amazon Kendra den gesamten Vektorsuchprozess abwickelt.
-
Amazon Kendra enthält vorgefertigte Konnektoren für beliebte Datenquellen wie Datenbanken, Website-Crawler, Amazon S3 S3-Buckets, Microsoft SharePoint Instances und Instances. Atlassian Confluence Von AWS Partnern entwickelte Konnektoren sind verfügbar, z. B. Konnektoren für und. Box GitLab
-
Amazon Kendra bietet eine ACL-Filterung (Access Control List), die nur Dokumente zurückgibt, auf die der Endbenutzer Zugriff hat.
-
Amazon Kendra kann Antworten auf der Grundlage von Metadaten wie Datum oder Quell-Repository beschleunigen.
Die folgende Abbildung zeigt eine Beispielarchitektur, die Amazon Kendra als Abruf-Ebene des RAG-Systems verwendet. Weitere Informationen finden Sie unter Schnelles Erstellen hochgenauer generativer KI-Anwendungen auf Unternehmensdaten mithilfe von Amazon Kendra und großen Sprachmodellen
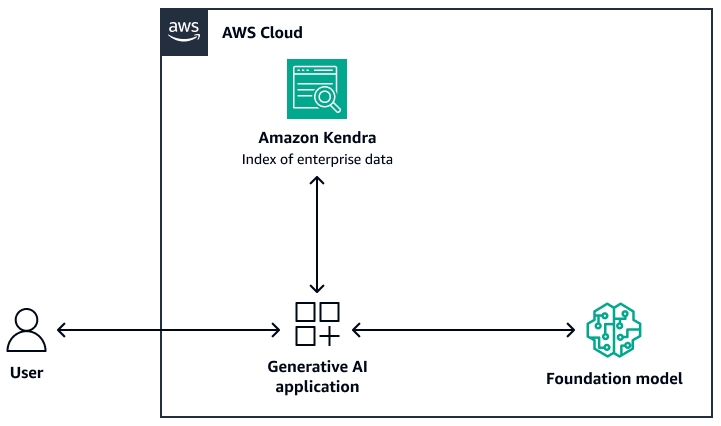
Für das Foundation-Modell können Sie Amazon Bedrock oder ein über Amazon SageMaker AI bereitgestelltes LLM verwenden. JumpStart Sie können AWS Lambda with verwenden LangChain
OpenSearch Amazon-Dienst
Amazon OpenSearch Service bietet integrierte ML-Algorithmen für die Suche nach k-Nearest Neighbours (k-NN), um eine Vektorsuche
Im Folgenden sind die Vorteile der Verwendung von OpenSearch Service für die Vektorsuche aufgeführt:
-
Es bietet die vollständige Kontrolle über die Vektordatenbank, einschließlich der Erstellung einer skalierbaren Vektorsuche mithilfe von OpenSearch Serverless.
-
Es bietet die Kontrolle über die Chunking-Strategie.
-
Es verwendet ANN-Algorithmen (Approximate Nearest Neighbor) aus den Bibliotheken Non-Metric Space Library (NMSLIB)
, Faiss und Apache Lucene , um eine k-NN-Suche durchzuführen. Sie können den Algorithmus je nach Anwendungsfall ändern. Weitere Informationen zu den Optionen für die Anpassung der Vektorsuche über OpenSearch Service finden Sie unter Erläuterung der Funktionen der Amazon OpenSearch Service-Vektordatenbank (AWS Blogbeitrag). -
OpenSearch Serverless lässt sich als Vektorindex in die Wissensdatenbanken von Amazon Bedrock integrieren.
Amazon Aurora PostgreSQL und pgvector
Amazon Aurora PostgreSQL-Compatible Edition ist eine vollständig verwaltete relationale Datenbank-Engine, die Sie bei der Einrichtung, dem Betrieb und der Skalierung von PostgreSQL-Bereitstellungen unterstützt. pgvector
Im Folgenden sind die Vorteile der Verwendung von pgvector und Aurora PostgreSQL-kompatibel aufgeführt:
-
Es unterstützt die exakte und ungefähre Suche nach dem nächsten Nachbarn. Es unterstützt auch die folgenden Ähnlichkeitsmetriken: L2-Entfernung, inneres Produkt und Kosinusdistanz.
-
Es unterstützt die Indexierung Inverted File with Flat Compression (IVFFlat)
und Hierarchical Navigable Small Worlds (HNSW). -
Sie können die Vektorsuche mit Abfragen über domänenspezifische Daten kombinieren, die in derselben PostgreSQL-Instanz verfügbar sind.
-
Aurora PostgreSQL-kompatibel ist für mehrstufiges Caching optimiert I/O und bietet dieses. Bei Workloads, die den verfügbaren Instanzspeicher überschreiten, kann pgvector die Abfragen pro Sekunde für die Vektorsuche um das bis zu 8-fache erhöhen.
Amazon Neptune Analytics
Amazon Neptune Analytics ist eine speicheroptimierte Graphdatenbank-Engine für Analysen. Sie unterstützt eine Bibliothek mit optimierten Algorithmen für die Graphanalyse, Grafikabfragen mit geringer Latenz und Vektorsuchfunktionen innerhalb von Graphendurchläufen. Es verfügt auch über eine integrierte Vektorähnlichkeitssuche. Es bietet einen Endpunkt, um ein Diagramm zu erstellen, Daten zu laden, Abfragen aufzurufen und eine Vektorähnlichkeitssuche durchzuführen. Weitere Informationen zum Erstellen eines RAG-basierten Systems, das Neptune Analytics verwendet, finden Sie unter Verwenden von Wissensgraphen zur Erstellung von GraphRag-Anwendungen mit Amazon Bedrock und Amazon Neptune
Im Folgenden sind die Vorteile der Verwendung von Neptune Analytics aufgeführt:
-
Sie können Einbettungen in Grafikabfragen speichern und durchsuchen.
-
Wenn Sie Neptune Analytics mit integrierenLangChain, unterstützt diese Architektur Graphabfragen in natürlicher Sprache.
-
Diese Architektur speichert große Graphdatensätze im Speicher.
Amazon MemoryDB
Amazon MemoryDB ist ein langlebiger In-Memory-Datenbankservice, der ultraschnelle Leistung bietet. Alle Ihre Daten werden im Speicher gespeichert, der Lesevorgänge im Mikrosekundenbereich, Schreiblatenz im einstelligen Millisekundenbereich und hohen Durchsatz unterstützt. Die Vektorsuche für MemoryDB erweitert die Funktionalität von MemoryDB und kann in Verbindung mit vorhandenen MemoryDB-Funktionen verwendet werden. Weitere Informationen finden Sie unter Fragen beantworten mit
Das folgende Diagramm zeigt eine Beispielarchitektur, die MemoryDB als Vektordatenbank verwendet.

Im Folgenden sind die Vorteile der Verwendung von MemoryDB aufgeführt:
-
Es unterstützt sowohl Flat- als auch HNSW-Indizierungsalgorithmen. Weitere Informationen finden Sie unter Die Vektorsuche für Amazon MemoryDB ist jetzt allgemein im News-Blog verfügbar
AWS -
Es kann auch als Pufferspeicher für das Foundation-Modell dienen. Dies bedeutet, dass zuvor beantwortete Fragen aus dem Puffer abgerufen werden, anstatt den Abruf- und Generierungsprozess erneut zu durchlaufen. Das folgende Diagramm zeigt diesen Prozess.
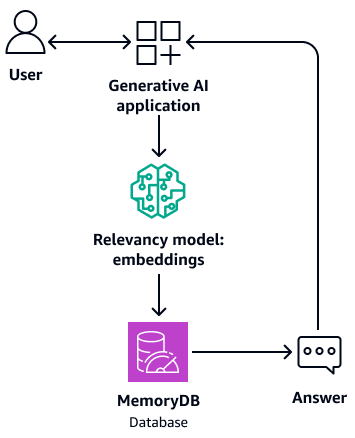
-
Da sie eine In-Memory-Datenbank verwendet, bietet diese Architektur eine Abfragezeit im einstelligen Millisekundenbereich für die semantische Suche.
-
Sie ermöglicht bis zu 33.000 Abfragen pro Sekunde bei einem Erinnerungsvermögen von 95— 99% und 26.500 Abfragen pro Sekunde bei einem Wiedererkennungswert von mehr als 99% Weitere Informationen finden Sie im Video AWS re:Invent 2023 — Vektorsuche mit extrem niedriger Latenz für Amazon MemoryDB
auf. YouTube
Amazon DocumentDB
Amazon DocumentDB (mit MongoDB-Kompatibilität) ist ein schneller, zuverlässiger und vollständig verwalteter Datenbankservice. Er macht es einfach, MongoDB kompatible Datenbanken in der Cloud einzurichten, zu betreiben und zu skalieren. Die Vektorsuche für Amazon DocumentDB kombiniert die Flexibilität und die umfangreichen Abfragefunktionen einer JSON-basierten Dokumentendatenbank mit der Leistungsfähigkeit der Vektorsuche. Weitere Informationen finden Sie unter Fragen beantworten mit dem LLM
Das folgende Diagramm zeigt eine Beispielarchitektur, die Amazon DocumentDB als Vektordatenbank verwendet.
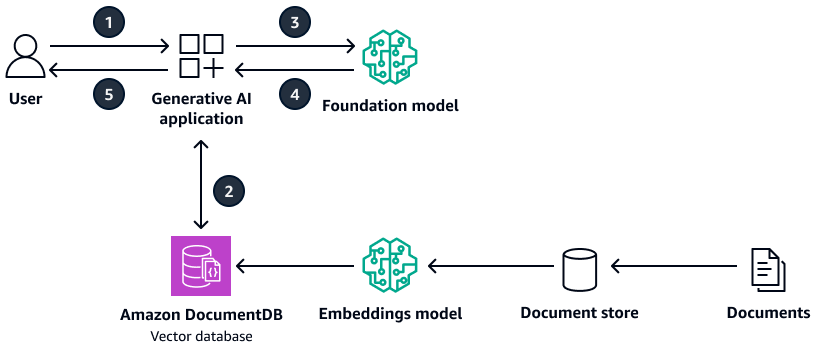
Das Diagramm zeigt den folgenden Workflow:
-
Der Benutzer sendet eine Anfrage an die generative KI-Anwendung.
-
Die generative KI-Anwendung führt eine Ähnlichkeitssuche in der Amazon DocumentDB DocumentDB-Vektordatenbank durch und ruft die entsprechenden Dokumentauszüge ab.
-
Die generative KI-Anwendung aktualisiert die Benutzerabfrage mit dem abgerufenen Kontext und leitet die Aufforderung an das Ziel-Foundation-Modell weiter.
-
Das Foundation-Modell verwendet den Kontext, um eine Antwort auf die Frage des Benutzers zu generieren, und gibt die Antwort zurück.
-
Die generative KI-Anwendung gibt die Antwort an den Benutzer zurück.
Im Folgenden sind die Vorteile der Verwendung von Amazon DocumentDB aufgeführt:
-
Es unterstützt sowohl HNSW- als auch IVFFlat Indexierungsmethoden.
-
Es unterstützt bis zu 2.000 Dimensionen in den Vektordaten und unterstützt die Entfernungsmetriken Euklid, Kosinus und Punktprodukt.
-
Es bietet Reaktionszeiten im Millisekundenbereich.
Pinecone
Pinecone
Das folgende Diagramm zeigt eine Beispielarchitektur, die Pinecone als Vektordatenbank verwendet wird.
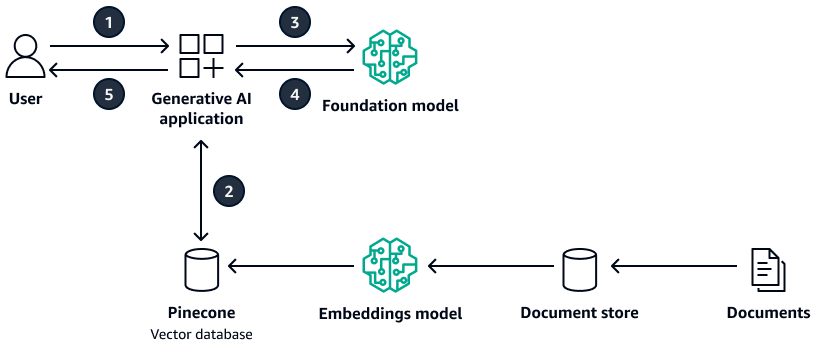
Das Diagramm zeigt den folgenden Workflow:
-
Der Benutzer sendet eine Anfrage an die generative KI-Anwendung.
-
Die generative KI-Anwendung führt eine Ähnlichkeitssuche in der Pinecone Vektordatenbank durch und ruft die entsprechenden Dokumentenauszüge ab.
-
Die generative KI-Anwendung aktualisiert die Benutzerabfrage mit dem abgerufenen Kontext und sendet die Aufforderung an das Ziel-Foundation-Modell.
-
Das Foundation-Modell verwendet den Kontext, um eine Antwort auf die Frage des Benutzers zu generieren, und gibt die Antwort zurück.
-
Die generative KI-Anwendung gibt die Antwort an den Benutzer zurück.
Im Folgenden sind die Vorteile der Verwendung von aufgeführtPinecone:
-
Es handelt sich um eine vollständig verwaltete Vektordatenbank, die Ihnen den Aufwand für die Verwaltung Ihrer eigenen Infrastruktur nimmt.
-
Sie bietet zusätzliche Funktionen wie Filterung, Live-Indexaktualisierungen und Keyword-Boosting (Hybridsuche).
MongoDB Atlas
MongoDB
Atlas
Weitere Informationen zur Verwendung der MongoDB Atlas Vektorsuche für RAG finden Sie unter Retrieval-Augmented Generation withLangChain, Amazon SageMaker AI JumpStart und MongoDB Atlas Semantic Search
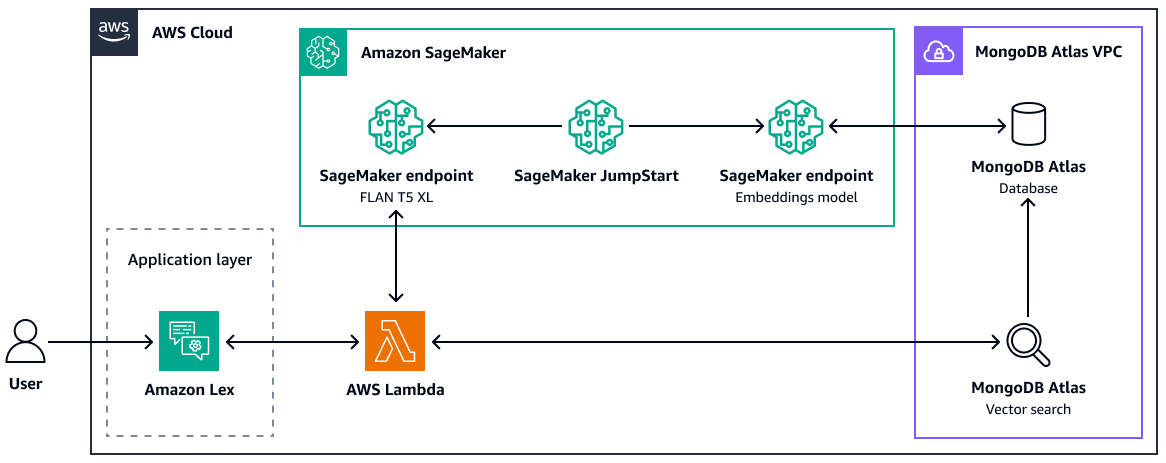
Im Folgenden sind die Vorteile der Verwendung der MongoDB Atlas Vektorsuche aufgeführt:
-
Sie können Ihre bestehende Implementierung von verwendenMongoDB Atlas, um Vektoreinbettungen zu speichern und zu durchsuchen.
-
Sie können die MongoDBAbfrage-API
verwenden, um die Vektoreinbettungen abzufragen. -
Sie können die Vektorsuche und die Datenbank unabhängig voneinander skalieren.
-
Vektoreinbettungen werden in der Nähe der Quelldaten (Dokumente) gespeichert, was die Indizierungsleistung verbessert.
Weaviate
Weaviate
Im Folgenden sind die Vorteile der Verwendung von: Weaviate
-
Es ist Open Source und wird von einer starken Community unterstützt.
-
Es ist für die Hybridsuche (sowohl Vektoren als auch Schlüsselwörter) konzipiert.
-
Sie können es AWS als verwaltetes Software-as-a-Service (SaaS) -Angebot oder als Kubernetes-Cluster bereitstellen.
