Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Architektur
Das folgende Diagramm zeigt die Architektur der in diesem Handbuch beschriebenen Lösung. Ein AWS Glue Job liest Daten aus einem Amazon Simple Storage Service (Amazon S3) -Bucket, einem cloudbasierten Objektspeicher-Service, der Sie beim Speichern, Schützen und Abrufen von Daten unterstützt. Sie können das initiieren AWS Glue Spark SQL Job über die AWS Management Console, AWS Command Line Interface (AWS CLI) oder die AWS Glue API. Das AWS Glue Spark SQL Job verarbeitet die Rohdaten in einem Amazon S3 S3-Bucket und speichert die verarbeiteten Daten dann in einem anderen Bucket.
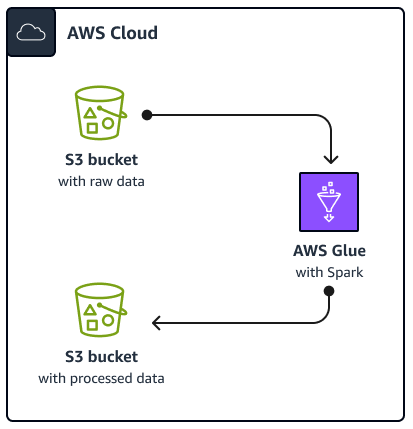
In diesem Handbuch werden zum Beispiel grundlegende Informationen beschrieben AWS GlueSpark SQL Job, der geschrieben ist Python and Spark SQL (PySpark). Dieser AWS Glue Job dient der Demonstration von Best Practices für Spark SQL Tuning. Obwohl sich dieser Leitfaden auf Amazon EMR konzentriert AWS Glue, gelten die Best Practices in diesem Handbuch auch für Amazon EMR Spark SQL Arbeitsplätze.
Das folgende Diagramm zeigt den Lebenszyklus eines Spark SQL abfragen. Das Tool Spark SQL Catalyst Optimizer generiert einen Abfrageplan. Ein Abfrageplan besteht aus einer Reihe von Schritten, wie Anweisungen, die für den Zugriff auf die Daten in einem relationalen SQL-Datenbanksystem verwendet werden. Zur Entwicklung eines leistungsoptimierten Spark
SQL Bei der Abfrage eines Plans besteht der erste Schritt darin, den EXPLAIN Plan anzusehen, ihn zu interpretieren und dann den Plan zu optimieren. Sie können das Spark SQL Benutzeroberfläche (UI) oder Spark SQL History Server zur Visualisierung des Plans.
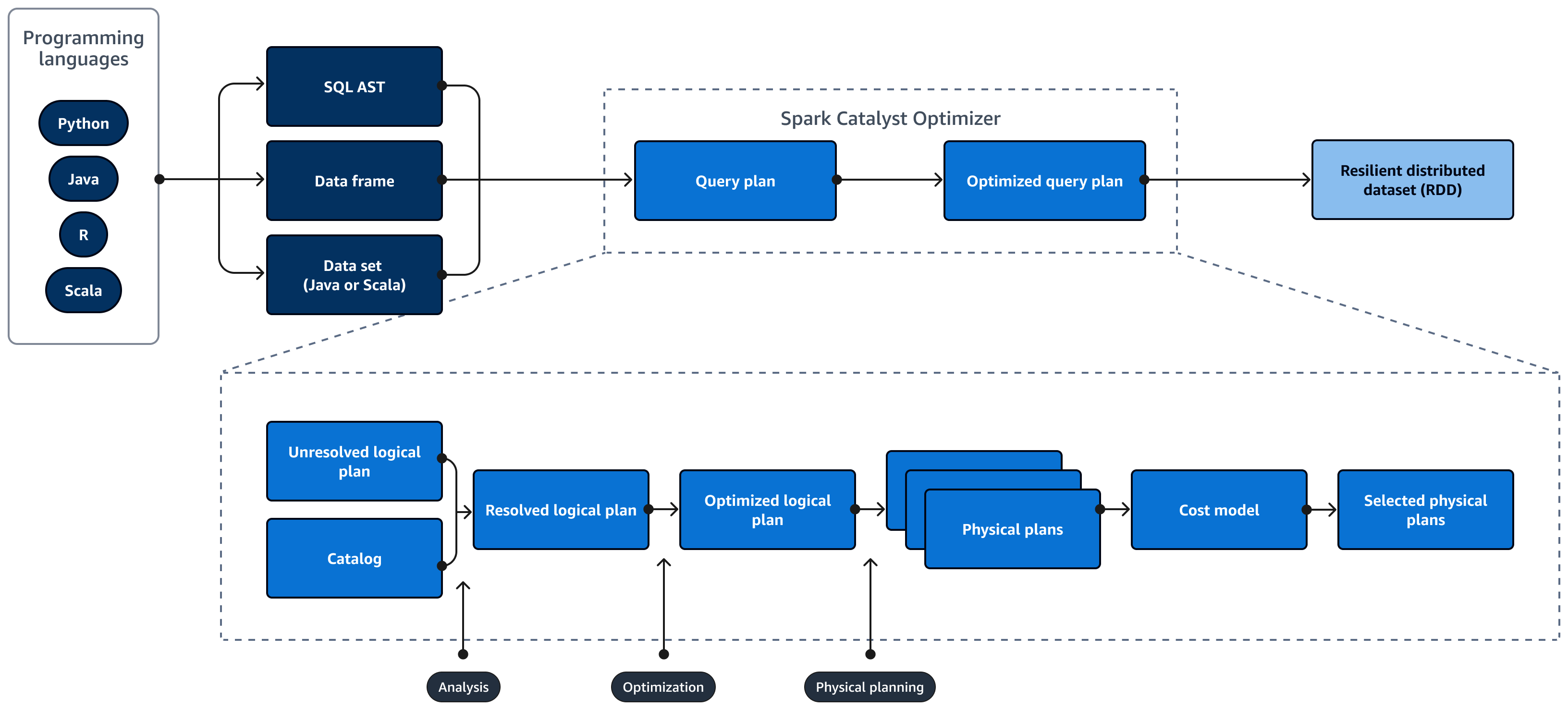
Spark Catalyst Optimizer konvertiert den ursprünglichen Abfrageplan wie folgt in einen optimierten Abfrageplan:
-
Analyse und Deklaration APIs — Die Analysephase ist der erste Schritt. Der ungelöste logische Plan, bei dem Objekte, auf die in der SQL-Abfrage verwiesen wird, nicht bekannt sind oder keiner Eingabetabelle zugeordnet sind, wird mit ungebundenen Attributen und Datentypen generiert. Das Tool Spark SQL Catalyst Optimizer wendet dann eine Reihe von Regeln an, um einen logischen Plan zu erstellen. Der SQL-Parser kann einen SQL Abstract Syntax Tree (AST) generieren und diesen als Eingabe für den logischen Plan bereitstellen. Bei der Eingabe kann es sich auch um einen Datenrahmen oder ein Datensatzobjekt handeln, das mithilfe einer API erstellt wurde. Die folgende Tabelle zeigt, wann Sie SQL, Datenrahmen oder Datensätze verwenden sollten.
SQL Datenframes Datensätze Syntaxfehler Laufzeit Zeit der Kompilierung Zeit zum Kompilieren Fehler bei der Analyse Laufzeit Laufzeit Zeit zum Kompilieren Weitere Informationen zu den Eingabetypen finden Sie in den folgenden Abschnitten:
-
Eine Datensatz-API stellt eine typisierte Version bereit. Dies reduziert die Leistung, da stark von benutzerdefinierten Lambda-Funktionen abhängig ist. RDD oder Datensätze sind statisch typisiert. Wenn Sie beispielsweise ein RDD definieren, müssen Sie die Schemadefinition explizit angeben.
-
Eine Datenrahmen-API bietet untypisierte relationale Operationen. Datenrahmen werden dynamisch typisiert. Ähnlich wie bei RDD bleibt das Schema unverändert, wenn Sie einen Datenrahmen definieren. Die Daten sind immer noch strukturiert. Diese Informationen sind jedoch nur zur Laufzeit verfügbar. Dies ermöglicht es dem Compiler, SQL-ähnliche Anweisungen zu schreiben und im Handumdrehen neue Spalten zu definieren. Beispielsweise kann er Spalten an einen vorhandenen Datenrahmen anhängen, ohne dass für jede Operation eine neue Klasse definiert werden muss.
-
A Spark SQL Die Abfrage wird während der Laufzeit auf Syntax- und Analysefehler überprüft, was zu schnelleren Laufzeiten führt.
-
-
Katalog —Spark SQL Verwendungszwecke Apache Hive Metastore (HMS) um die Metadaten persistenter relationaler Entitäten wie Datenbanken, Tabellen, Spalten und Partitionen zu verwalten.
-
Optimierung — Der Optimierer schreibt den Abfrageplan mithilfe von Heuristiken und Kosten neu. Er führt die folgenden Schritte aus, um einen optimierten logischen Plan zu erstellen:
-
Pflaumen, Säulen
-
Drückt Prädikate nach unten
-
Ordnet Verknüpfungen neu an
-
-
Physische Pläne und der Planer — Spark SQL Catalyst Optimizer konvertiert den logischen Plan in eine Reihe von physischen Plänen. Das heißt, es konvertiert das Was in das Wie.
-
Ausgewählte physische Pläne — Spark SQL Catalyst Optimizer wählt den kostengünstigsten physischen Plan aus.
-
Optimierter Abfrageplan — Spark SQL führt den leistungs- und kostenoptimierten Abfrageplan aus. Spark SQL Memory Management verfolgt die Speichernutzung und verteilt den Speicher zwischen Aufgaben und Operatoren. Das Tool Spark SQL Die Tungsten-Engine kann die Speicher- und CPU-Effizienz für erheblich verbessern Spark SQL Anwendungen. Es implementiert auch die Verarbeitung binärer Datenmodelle und arbeitet direkt mit Binärdaten. Dadurch wird die Notwendigkeit einer Deserialisierung umgangen und der mit der Datenkonvertierung und Deserialisierung verbundene Aufwand erheblich reduziert.
