Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Übersicht über die Lösung
Ein skalierbares ML-Framework
In einem Unternehmen mit Millionen von Kunden, die über mehrere Geschäftsbereiche verteilt sind, erfordern ML-Workflows die Integration von Daten, die sich im Besitz isolierter Teams befinden und von diesen verwaltet werden. Dabei werden unterschiedliche Tools verwendet, um den Geschäftswert zu steigern. Banken haben sich zum Schutz der Daten ihrer Kunden verpflichtet. Gleichermaßen unterliegt auch die für die Entwicklung von ML-Modellen verwendete Infrastruktur hohen Sicherheitsstandards. Diese zusätzliche Sicherheit erhöht die Komplexität und beeinträchtigt die Wertschöpfungszeit für neue ML-Modelle. In einem skalierbaren ML-Framework können Sie ein modernisiertes, standardisiertes Toolset verwenden, um den Aufwand für die Kombination verschiedener Tools zu reduzieren und den route-to-live Prozess für neue ML-Modelle zu vereinfachen.
Traditionellerweise wird die Verwaltung und Unterstützung von datenwissenschaftlichen Aktivitäten in der FS-Branche von einem zentralen Plattformteam gesteuert, das die Anforderungen sammelt, die Ressourcen bereitstellt und die Infrastruktur für Datenteams in der gesamten Organisation betreibt. Um die Anwendung von ML in verbundenen Teams in der gesamten Organisation schnell zu skalieren, können Sie ein skalierbares ML-Framework verwenden, um Selbstbedienungsfunktionen für Entwickler neuer Modelle und Pipelines bereitzustellen. So können diese Entwickler eine moderne, vorab genehmigte, standardisierte und sichere Infrastruktur bereitstellen. Letztlich reduzieren diese Selbstbedienungsfunktionen die Abhängigkeit Ihrer Organisation von zentralisierten Plattformteams und beschleunigen die Amortisierungszeit für die Entwicklung von ML-Modellen.
Das skalierbare ML-Framework ermöglicht es Datennutzern (z. B. Datenwissenschaftlern oder ML-Ingenieuren), geschäftlichen Nutzen zu erschließen, indem es ihnen folgende Möglichkeiten bietet:
Suchen und erkunden von vorab genehmigten Daten, die für das Modelltraining erforderlich sind
Schnell und einfach Zugriff auf vorab genehmigte Daten erhalten
Vorab genehmigte Daten verwenden, um die Realisierbarkeit des Modells nachzuweisen
Das geprüfte Modell für die Produktion freigeben, damit andere es verwenden können
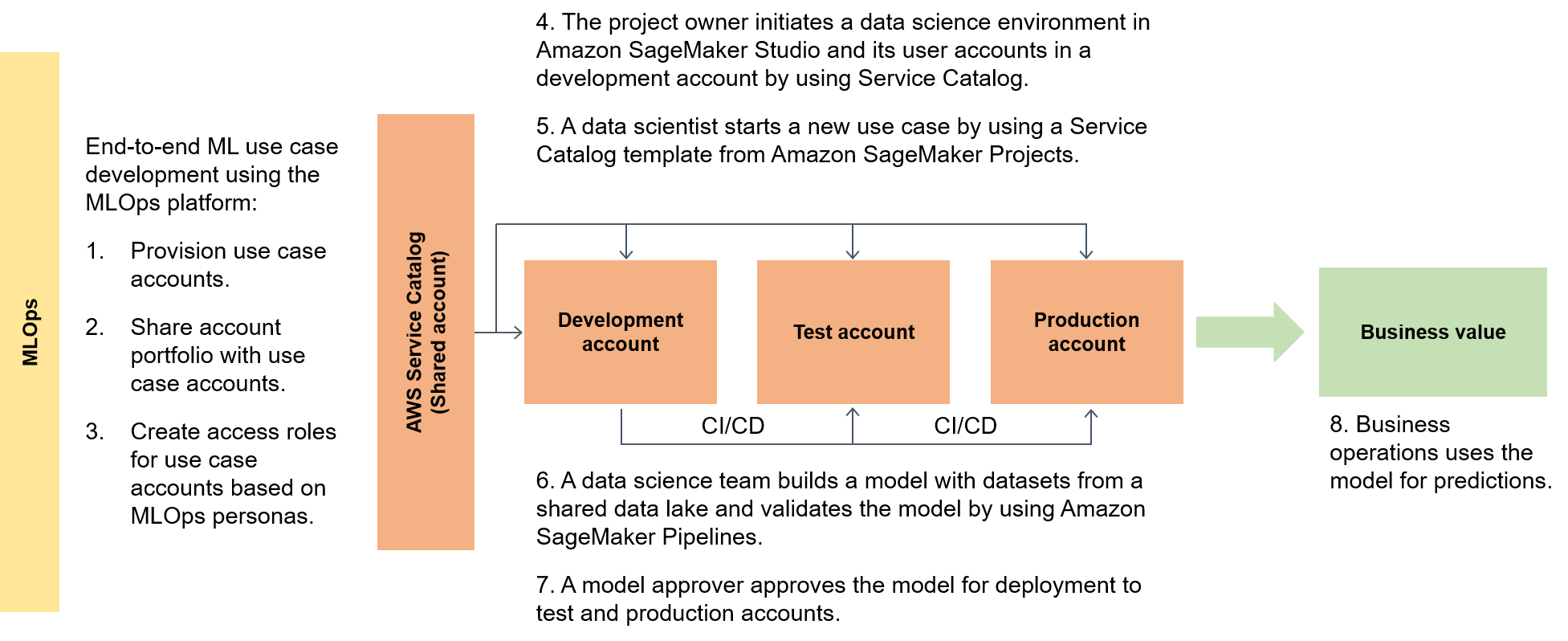
Das folgende Diagramm verdeutlicht den end-to-end Ablauf des Frameworks und den vereinfachten Weg zur Umsetzung von ML-Anwendungsfällen.
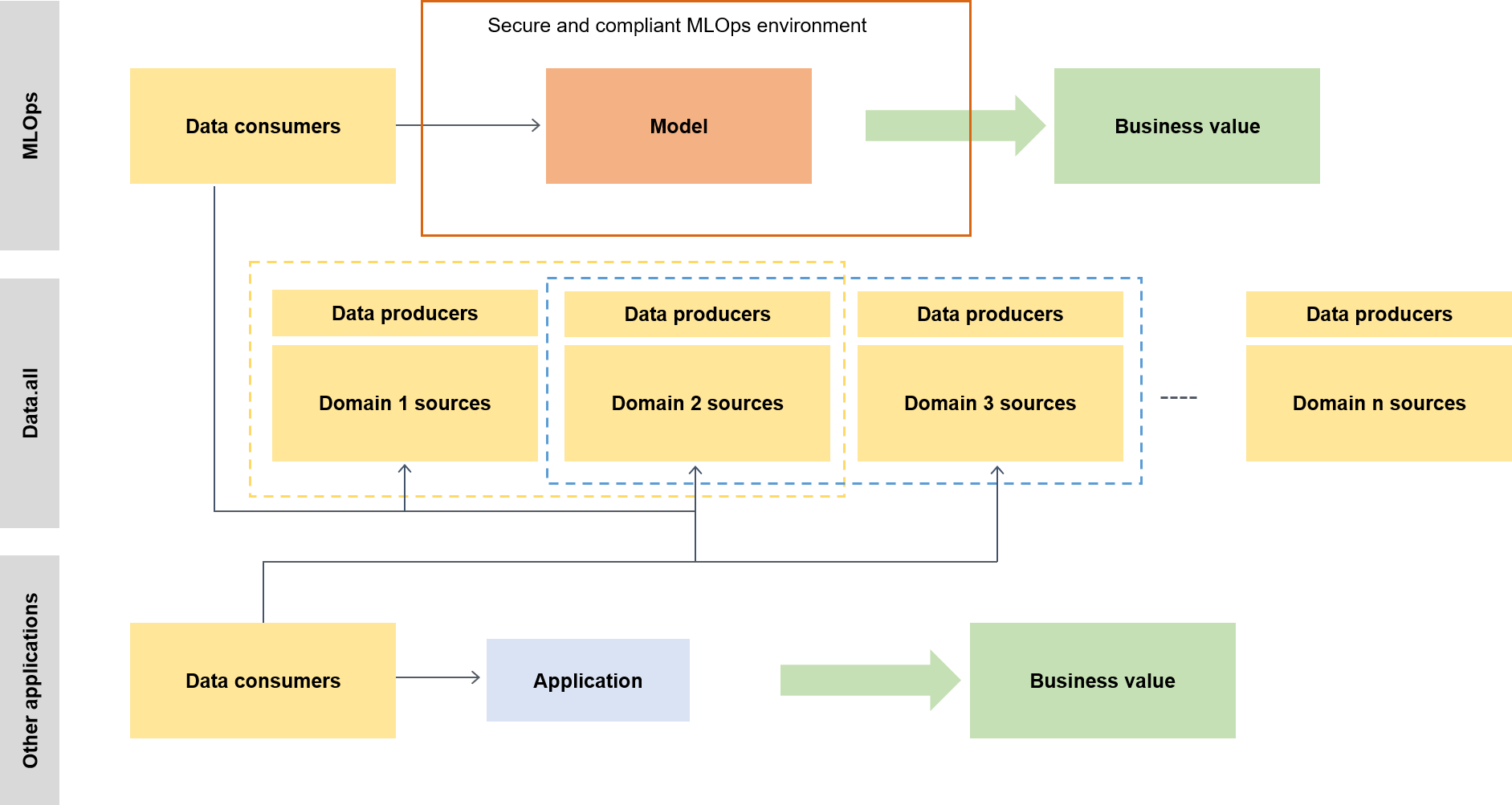
Im weiteren Kontext verwenden Datennutzer einen Serverless-Beschleuniger namens Data.all um Daten aus mehreren Data Lakes zu beziehen und diese Daten dann zum Trainieren ihrer Modelle zu verwenden, wie das folgende Diagramm zeigt.
Auf einer niedrigeren Ebene enthält das skalierbare ML-Framework Folgendes:
Bereitstellung der Self-Service-Infrastruktur – Reduzieren Sie Ihre Abhängigkeit von zentralisierten Teams.
Zentrales Python-Paketverwaltungssystem – Stellen Sie vorab genehmigte Python-Pakete für die Modellentwicklung zur Verfügung.
CI/CD-Pipelines für die Modellentwicklung und -förderung – Verkürzen Sie die Einsatzzeit, indem Sie Continuous-Integrations- und Continuous-Pipelines (CI/CD) als Teil Ihrer Infrastructure as Code (IaC)-Vorlagen integrieren.
Funktionen zum Testen von Modellen — Nutzen Sie Funktionen für Komponententests, Modelltests, end-to-end Integrationstests und Tests, die automatisch für neue Modelle verfügbar sind.
Modellentkopplung und Orchestrierung — Vermeiden Sie unnötigen Rechenaufwand und machen Sie Ihre Bereitstellungen robuster, indem Sie die Modellschritte entsprechend den Anforderungen an die Rechenressourcen entkoppeln und die verschiedenen Schritte mithilfe von Amazon AI Pipelines orchestrieren. SageMaker
Codestandardisierung — Verbessern Sie die Qualität Ihres Codes, indem Sie die CI/CD Pipeline-Integration zur Validierung von Python Enhancement Proposal (PEP 8
) -Standards verwenden. Generische ML-Vorlagen für den Schnellstart — Holen Sie sich Service Catalog-Vorlagen, die Ihre ML-Modellierungsumgebungen (Entwicklung, Vorproduktion und Produktion) und die zugehörigen Pipelines mit einem Klick instanziieren, indem Sie KI-Projekte für die Bereitstellung verwenden. SageMaker
Überwachung der Daten- und Modellqualität — Stellen Sie sicher, dass Ihre Modelle den betrieblichen Anforderungen und Ihrer Risikotoleranz entsprechen, indem Sie Amazon SageMaker AI Model Monitor verwenden, um Abweichungen in Ihrer Daten- und Modellqualität automatisch zu überwachen.
Überwachung von Verzerrungen – Ermöglichen Sie Ihren Modelleigentümern, faire und gerechte Entscheidungen zu treffen, indem Sie automatisch prüfen, ob die Daten unausgewogen sind und ob Veränderungen in der Welt zu Verzerrungen in Ihrem Modell geführt haben.
Ein zentraler Knotenpunkt für Metadaten
Data.all
SageMaker Validierung
Um die Fähigkeiten der SageMaker KI in einer Reihe von Datenverarbeitungs- und ML-Architekturen nachzuweisen, wählt das Team, das die Funktionen implementiert, zusammen mit dem Bankleitungsteam Anwendungsfälle unterschiedlicher Komplexität aus verschiedenen Bereichen von Bankkunden aus. Die Anwendungsfalldaten werden verschleiert und in einem lokalen Amazon Simple Storage Service (Amazon S3)
Wenn die Modellmigration von der ursprünglichen Trainingsumgebung zu einer SageMaker KI-Architektur abgeschlossen ist, stellt Ihr in der Cloud gehosteter Data Lake die Daten zur Verfügung, damit sie von den Produktionsmodellen gelesen werden können. Die von den Produktionsmodellen generierten Vorhersagen werden dann in den Data Lake zurückgeschrieben.
Nachdem die möglichen Anwendungsfälle migriert wurden, erstellt das skalierbare ML-Framework eine erste Basislinie für die Zielmetriken. Sie können die Basislinie mit früheren Zeitmessungen On-Premises oder bei anderen Cloud-Anbietern vergleichen, um die Zeitverbesserungen zu belegen, die durch das skalierbare ML-Framework ermöglicht werden.
