Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Zuordnen von Voraussageergebnissen zu Eingabedatensätzen
Wenn Sie Voraussagen für einen großen Datensatz erstellen, können Sie nicht für die Prognose benötigte Attribute ausschließen. Nachdem die Prognosen vorgenommen wurden, können Sie einige der ausgeschlossenen Attribute diesen Prognosen oder anderen Eingabedaten in Ihrem Bericht zuordnen. Wenn diese Datenverarbeitungsschritte mithilfe der Stapeltransformation ausgeführt werden, entfällt häufig eine zusätzliche Vor- oder Nachverarbeitung. Sie können Eingabedateien nur im JSON- und CSV-Format verwenden.
Themen
Workflow für die Zuordnung von Inferenzen zu Eingabedatensätzen
Das folgende Diagramm zeigt den Workflow für die Zuordnung von Inferenzen zu Eingabedatensätzen.
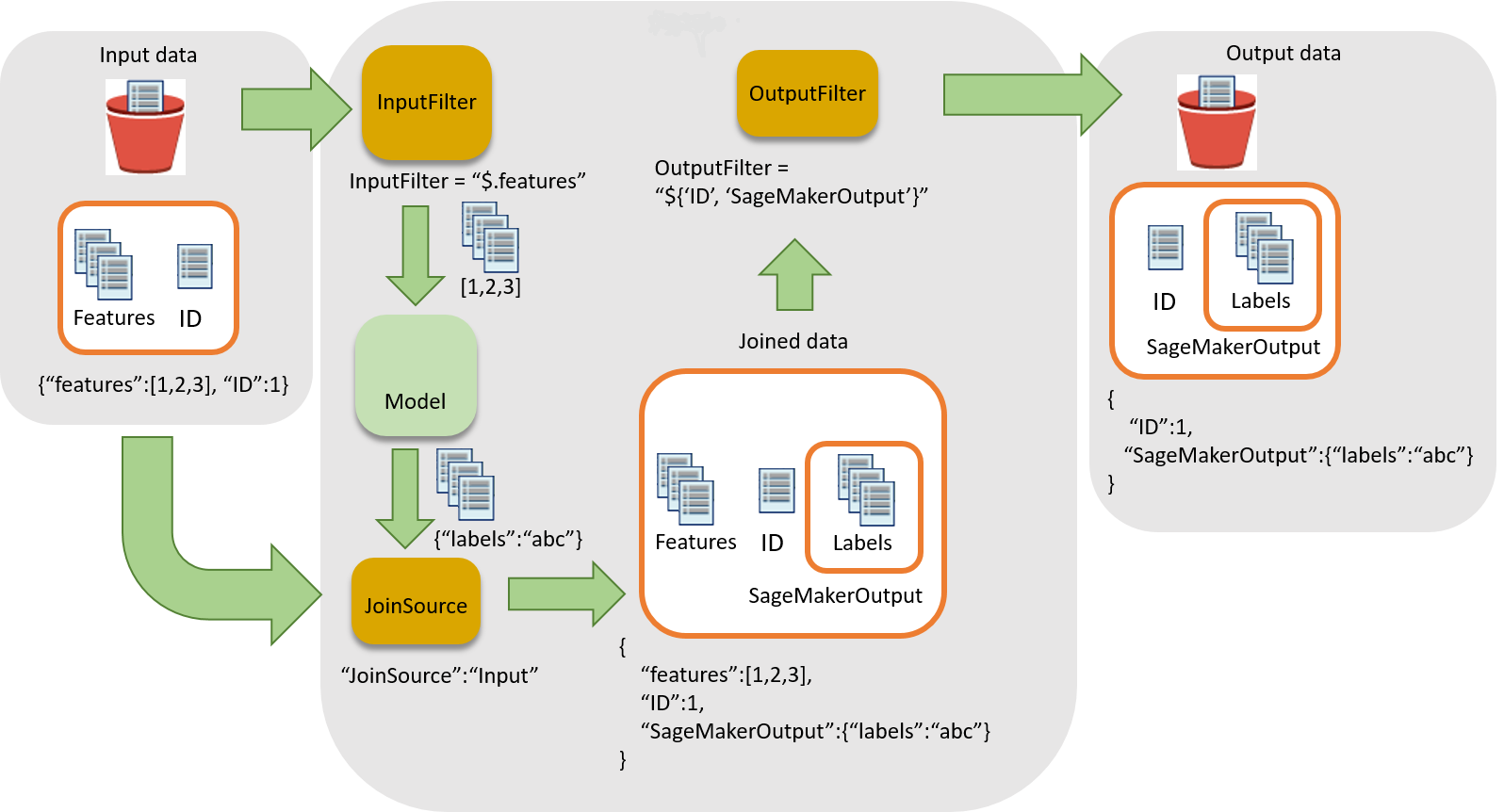
Inferenzen werden in drei Hauptschritten mit Eingabedaten verknüpft:
-
Filtern Sie die Eingabedaten, die für die Inferenz nicht erforderlich sind, bevor sie an den Stapeltransformationsauftrag übergeben werden. Verwenden Sie den Parameter
InputFilter, um zu bestimmen, welche Attribute als Eingabe für das Modell verwendet werden. -
Ordnen Sie die Eingabedaten den Inferenzergebnissen zu. Verwenden Sie den Parameter
JoinSource, um die Eingabedaten mit der Inferenz zu kombinieren. -
Filtern Sie die verknüpften Daten, um die Eingaben beizubehalten, die erforderlich sind, um Kontext für die Interpretation der Prognosen in den Berichten bereitzustellen. Verwenden Sie
OutputFilterzum Speichern des angegebenen Teils des verknüpften Datensatzes in der Ausgabedatei.
Verwenden der Datenverarbeitung in Stapelumwandlungsaufträgen
Beim Erstellen eines Stapeltransformationsauftrags mit CreateTransformJob zum Verarbeiten von Daten:
-
Geben Sie den Teil der Eingabe an, die dem Modell mit dem
InputFilter-Parameter in derDataProcessing-Datenstruktur übergeben werden soll. -
Verknüpfen Sie die unformatierten Eingabedaten mithilfe des
JoinSource-Parameters mit den transformierten Daten. -
Geben Sie mit dem
OutputFilter-Parameter an, welcher Teil der verknüpften Eingabedaten und transformierten Daten aus dem Stapeltransformationauftrag in die Ausgabedatei eingeschlossen werden soll. -
Wählen Sie entweder JSON- oder CSV-formatted Dateien für die Eingabe:
-
Bei JSON- oder Lines-formatted JSON-Eingabedateien fügt SageMaker AI entweder das
SageMakerOutputAttribut zur Eingabedatei hinzu oder erstellt eine neue JSON-Ausgabedatei mit denSageMakerOutputAttributenSageMakerInputund. Weitere Informationen finden Sie unterDataProcessing. -
Bei CSV-formatted Eingabedateien folgen auf die verknüpften Eingabedaten die transformierten Daten und die Ausgabe ist eine CSV-Datei.
-
Wenn Sie einen Algorithmus mit der DataProcessing-Struktur verwenden, muss diese das ausgewählte Format sowohl für Eingabe- als auch Ausgabedateien unterstützen. Mit dem Feld TransformOutput der CreateTransformJob-API müssen Sie z. B. die Parameter ContentType und Accept auf einen der folgenden Werte festlegen: text/csv, application/json oder application/jsonlines. Die Syntax für die Angabe von Spalten in einer CSV-Datei und von Attributen in einer JSON-Datei ist unterschiedlich. Durch Verwenden der falschen Syntax wird ein Fehler verursacht. Weitere Informationen finden Sie unter Beispiele für die Stapeltransformation. Weitere Informationen zu Eingabe- und Ausgabedateiformaten für integrierte Algorithmen finden Sie unter Built-in Algorithmen und vortrainierte Modelle in Amazon SageMaker.
Die Datensatztrennzeichen für die Ein- und Ausgabe müssen außerdem mit der von Ihnen ausgewählten Dateieingabe konsistent sein. Der Parameter SplitType gibt an, wie die Datensätze im Eingabedatensatz aufgeteilt werden sollen. Der Parameter AssembleWith gibt an, wie die Wiederherstellung der Datensätze für die Ausgabe erfolgen soll. Wenn Sie Ein- und Ausgabeformate auf text/csv festlegen, müssen Sie auch die Parameter SplitType und AssembleWith auf line einstellen. Wenn Sie die Ein- und Ausgabeformate auf application/jsonlines festlegen, können Sie die sowohl SplitType als auch AssembleWith auf line einstellen.
Für CSV-Dateien können Sie keine eingebetteten Zeilenumbruchzeichen verwenden. Für JSON-Dateien ist der Attributname SageMakerOutput für die Ausgabe reserviert. Die JSON-Eingabedatei darf kein Attribut mit diesem Namen enthalten. Wenn dies der Fall ist, werden die Daten in der Eingabedatei möglicherweise überschrieben.
Unterstützte JSONPath-Operatoren
Verwenden Sie zum Filtern und Verknüpfen der Eingabedaten und Inferenzen einen JSONPath-Unterausdruck. SageMaker AI unterstützt nur eine Teilmenge der definierten JSONPath-Operatoren. In der folgenden Tabelle sind die unterstützten JSONPath-Operatoren aufgeführt. Bei CSV-Daten wird jede Zeile als JSON-Array genommen, sodass nur indexbasierte JSONPaths angewendet werden können, z. B. $[0], $[1:]. CSV-Daten sollten auch dem RFC-Format
| JSONPath-Operator | Description | Beispiel |
|---|---|---|
$ |
Das Root-Element für eine Abfrage. Dieser Operator ist am Anfang alle Pfadausdrücke erforderlich. |
$ |
. |
Ein untergeordnetes Element in Punkt-Notation. |
|
* |
Platzhalter Verwenden Sie diesen anstelle eines Attributnamens oder numerischen Werts. |
|
[' |
Ein Element oder mehrere untergeordnete Elemente in Klammer-Notation. |
|
[ |
Ein Index oder Array von Indizes. Negative Indexwerte werden ebenfalls unterstützt. Der Index |
|
[ |
Ein Array-Slice-Operator. Die Array-Slice()-Methode extrahiert einen Abschnitt eines Arrays und gibt ein neues Array zurück. Wenn Sie es weglassen |
|
Wenn Sie die Klammern verwenden, um mehrere untergeordnete Elemente eines bestimmten Felds anzugeben, wird eine zusätzliche Verschachtelung von untergeordneten Elementen in Klammern nicht unterstützt. Beispielsweise $.field1.['child1','child2'] wird unterstützt, während $.field1.['child1','child2.grandchild'] es nicht ist.
Weitere Informationen zu JSONPath-Operatoren finden Sie unter JsonPath
Beispiele für die Stapeltransformation
Die folgenden Beispiele zeigen einige gängige Möglichkeiten zur Verknüpfung von Eingabedaten mit Prognoseergebnissen.
Beispiel: Ausgeben nur von Inferenzen
Standardmäßig verbindet der Parameter DataProcessing keine Inferenzergebnisse mit der Eingabe. Sie gibt nur die Inferenzergebnisse aus.
Wenn Sie explizit angeben möchten, dass Ergebnisse nicht mit Eingaben verknüpft werden sollen, verwenden Sie das Amazon SageMaker Python SDK
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
Um Inferenzen mit dem AWS SDK für Python auszugeben, fügen Sie Ihrer CreateTransformJob Anfrage den folgenden Code hinzu. Mit dem folgenden Code wird das Standardverhalten nachgeahmt.
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
Beispiel: Ausgabe von Inferenzen in Verbindung mit Eingabedaten
Wenn Sie das Amazon SageMaker Python SDKaccept Parameter assemble_with und an, wenn Sie das Transformer-Objekt initialisieren. Wenn Sie den Transform-Aufruf verwenden, geben Sie Input für den Parameter join_source an und geben Sie auch die Parameter split_type und content_type an. Der Parameter split_type muss denselben Wert wie assemble_with haben, und der Parameter content_type muss denselben Wert wie haben accept. Weitere Informationen zu den Parametern und ihren akzeptierten Werten finden Sie auf der Transformer-Seite
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
Wenn Sie das AWS SDK für Python (Boto 3) verwenden, verknüpfen Sie alle Eingabedaten mit der Inferenz, indem Sie Ihrer CreateTransformJobAnfrage den folgenden Code hinzufügen. Die Werte für Accept und ContentType müssen übereinstimmen, und die Werte für AssembleWith und SplitType müssen ebenfalls übereinstimmen.
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Für JSON- oder JSON Lines-Eingabedateien sind die Ergebnisse im SageMakerOutput-Schlüssel in der JSON-Eingabedatei enthalten. Beispiel: Wenn die Eingabe eine JSON-Datei mit dem Schlüssel-Wert-Paar {"key":1} ist, lautet das Ergebnis der Datentransformation z. B. {"label":1}.
SageMaker AI speichert beide in der Eingabedatei im SageMakerInput Schlüssel.
{ "key":1, "SageMakerOutput":{"label":1} }
Anmerkung
Das verknüpfte Ergebnis für JSON muss ein Schlüssel-Wert-Paar-Objekt sein. Wenn es sich bei der Eingabe nicht um ein Schlüssel-Wert-Paar-Objekt handelt, erstellt SageMaker AI eine neue JSON-Datei. In der neuen JSON-Datei werden die Eingabedaten im SageMakerInput-Schlüssel und die Ergebnisse als SageMakerOutput-Wert gespeichert.
Wenn der Datensatz für eine CSV-Datei z. B. [1,2,3] lautet und das Beschriftungsergebnis [1] ist, dann würde die Ausgabedatei [1,2,3,1] enthalten.
Beispiel: Mit Eingabedaten verknüpfte Inferenzen ausgeben und die ID-Spalte von der Eingabe ausschließen (CSV)
Wenn Sie das Amazon SageMaker Python SDKinput_filter in Ihrem Transformer-Aufruf an. Beispiel: Wenn Ihre Eingabedaten fünf Spalten umfassen, wobei die erste die ID-Spalte ist, verwenden Sie die folgende Transformer-Anforderung, um alle Spalten außer der ID-Spalte als Merkmale zu verwenden. Der Transformator gibt weiterhin alle Eingabespalten aus, die mit den Inferenzen verknüpft sind. Weitere Informationen zu den Parametern und ihren akzeptierten Werten finden Sie auf der Transformer-Seite
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
Wenn Sie das AWS SDK für Python (Boto 3) verwenden, fügen Sie Ihrer
CreateTransformJob Anfrage den folgenden Code hinzu.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Verwenden Sie den Index der Array-Elemente, um Spalten in SageMaker AI anzugeben. Die erste Spalte ist Index 0, die zweite Spalte ist Index 1 und die sechste Spalte ist Index 5.
Um die erste Spalte aus der Eingabe auszuschließen, legen Sie InputFilter auf "$[1:]" fest. Der Doppelpunkt (:) weist SageMaker AI an, alle Elemente zwischen zwei Werten (einschließlich) einzubeziehen. $[1:4] gibt beispielsweise die zweite bis fünfte Spalte an.
Wenn Sie die Zahl nach dem Doppelpunkt weglassen, z. B. [5:], enthält die Teilmenge alle Spalten von der 6. bis zur letzten Spalte. Wenn Sie die Zahl vor dem Doppelpunkt weglassen, z. B. [:5], enthält die Teilmenge alle Spalten von der ersten Spalte (Index 0) bis zur sechsten Spalte.
Beispiel: Ausgabe von Inferenzen in Verbindung mit einer ID-Spalte und Ausschließen der ID-Spalte aus der Eingabe (CSV)
Wenn Sie das Amazon SageMaker Python SDKoutput_filter im Transformer-Aufruf angeben. Der output_filter verwendet einen JSONPath-Unterausdruck, um anzugeben, welche Spalten als Ausgabe zurückgegeben werden sollen, nachdem die Eingabedaten mit den Inferenzergebnissen verknüpft wurden. Die folgende Anforderung zeigt, wie Sie Vorhersagen treffen können, während Sie eine ID-Spalte ausschließen und dann die ID-Spalte mit den Inferenzen verknüpfen können. Beachten Sie, dass im folgenden Beispiel die letzte Spalte (-1) der Ausgabe die Inferenzen enthält. Wenn Sie JSON-Dateien verwenden, speichert SageMaker AI die Inferenzergebnisse im Attribut. SageMakerOutput Weitere Informationen zu den Parametern und ihren akzeptierten Werten finden Sie auf der Transformer-Seite
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
Wenn Sie das AWS SDK für Python (Boto 3) verwenden, verknüpfen Sie nur die ID-Spalte mit den Inferenzen, indem Sie Ihrer CreateTransformJobAnfrage den folgenden Code hinzufügen.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
Warnung
Wenn Sie eine JSON-formatted Eingabedatei verwenden, darf die Datei den Attributnamen nicht enthalten. SageMakerOutput Dieser Attributname ist für die Inferenzen in der Ausgabedatei reserviert. Wenn Ihre JSON-formatted Eingabedatei ein Attribut mit diesem Namen enthält, werden Werte in der Eingabedatei möglicherweise mit der Inferenz überschrieben.
