Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Ergebnisse der Analyse
Nach Abschluss SageMaker eines Clarif-Verarbeitungsauftrags können Sie die Ausgabedateien herunterladen, um sie zu überprüfen, oder Sie können die Ergebnisse in SageMaker Studio Classic visualisieren. Im folgenden Thema werden die von SageMaker Clarify generierten Analyseergebnisse beschrieben, z. B. das Schema und der Bericht, der durch Verzerrungsanalysen, SHAP-Analysen, Computer Vision-Erklärbarkeitsanalysen und partielle Abhängigkeitsdiagramme () PDPs generiert wurde. Wenn die Konfigurationsanalyse Parameter zur Berechnung mehrerer Analysen enthält, werden die Ergebnisse in einer Analyse- und einer Berichtsdatei zusammengefasst.
Das Ausgabeverzeichnis für den SageMaker Clarif-Verarbeitungsjob enthält die folgenden Dateien:
-
analysis.json– Eine Datei, die Messwerte für Verzerrungen und die Bedeutung von Features im JSON-Format enthält. -
report.ipynb– Ein statisches Notebook, das Code enthält, mit dem Sie Messwerte zu Verzerrungen und die Bedeutung von Features visualisieren können. -
explanations_shap/out.csv– Ein Verzeichnis, das erstellt wird und automatisch generierte Dateien enthält, die auf Ihren spezifischen Analysekonfigurationen basieren. Wenn Sie beispielsweise densave_local_shap_valuesParameter aktivieren, werden lokale SHAP-Werte pro Instance imexplanations_shapVerzeichnis gespeichert. Ein weiteres Beispiel: Wenn Ihranalysis configurationkeinen Wert für den SHAP-Baseline-Parameter enthält, berechnet der SageMaker Clarify-Erklärbarkeits-Job eine Baseline, indem der Eingabe-Datensatz geclustert wird. Anschließend wird die generierte Baseline im Verzeichnis gespeichert.
Ausführlichere Informationen finden Sie in den folgenden Abschnitten.
Themen
Analyse der Verzerrung
Amazon SageMaker Clarify verwendet die in dokumentierte TerminologieAmazon SageMaker klärt die Bedingungen für Voreingenommenheit und Fairness, um Vorurteile und Fairness zu erörtern.
Schema für die Analysedatei
Die Analysedatei hat das JSON-Format und ist in zwei Abschnitte unterteilt: Verzerrungsmetriken vor dem Training und Verzerrungsmetriken nach dem Training. Die Parameter für Bias-Metriken vor und nach dem Training lauten wie folgt.
-
pre_training_bias_metrics – Parameter für Bias-Metriken vor dem Training. Weitere Informationen erhalten Sie unter Messwerte zu Verzerrungen vor dem Training und Konfigurationsdateien für die Analyse.
-
label – Der Ground-Truth-Beschriftungsname, der durch den
labelParameter der Analysekonfiguration definiert wird. -
label_value_or_threshold – Eine Zeichenfolge, die die Beschriftungwerte oder das durch den
label_values_or_thresholdParameter der Analysekonfiguration definierte Intervall enthält. Wenn beispielsweise ein Wert für ein binäres Klassifizierungsproblem angegeben1wird, dann lautet die Zeichenfolge1. Wenn für ein Problem mit mehreren Klassen mehrere Werte[1,2]angegeben werden, dann ist die Zeichenfolge1,2. Wenn ein Schwellenwert40für das Regressionsproblem angegeben wird, handelt es sich bei der Zeichenfolge um eine interne Zeichenfolge,(40, 68]bei der68es sich um den Maximalwert der Beschriftung im Eingabedatensatz handelt. -
Facetten – Der Abschnitt enthält mehrere Schlüssel-Wert-Paare, wobei der Schlüssel dem durch den
name_or_indexParameter der Facettenkonfiguration definierten Facettennamen entspricht und der Wert ein Array von Facettenobjekten ist. Jedes Facettenobjekt hat die folgenden Mitglieder:-
value_or_threshold – Eine Zeichenfolge, die die Facettenwerte oder das durch den
value_or_thresholdParameter der Facettenkonfiguration definierte Intervall enthält. -
metrics – Der Abschnitt enthält eine Reihe von Bias-Metrikelementen, und jedes Bias-Metrikelement hat die folgenden Attribute:
-
name – Der Kurzname der Bias-Metrik. Beispiel,
CI. -
Beschreibung – Der vollständige Name der Bias-Metrik. Beispiel,
Class Imbalance (CI). -
Wert – Der Wert der Bias-Metrik oder der JSON-Nullwert, wenn die Bias-Metrik aus einem bestimmten Grund nicht berechnet wird. Die Werte ±∞ werden jeweils als Zeichenketten
∞und-∞dargestellt. -
error – Eine optionale Fehlermeldung, die erklärt, warum die Bias-Metrik nicht berechnet wurde.
-
-
-
-
post_training_bias_metrics – Der Abschnitt enthält die Bias-Metriken nach dem Training und hat ein ähnliches Layout und eine ähnliche Struktur wie der Abschnitt vor dem Training. Weitere Informationen finden Sie unter Daten und Modellverzerrungsmetriken nach dem Training.
Im Folgenden finden Sie ein Beispiel für eine Analysekonfiguration, mit der sowohl Messwerte für Verzerrungen vor als auch nach dem Training berechnet werden.
{ "version": "1.0", "pre_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "CDDL", "description": "Conditional Demographic Disparity in Labels (CDDL)", "value": -0.06 }, { "name": "CI", "description": "Class Imbalance (CI)", "value": 0.6 }, ... ] }] } }, "post_training_bias_metrics": { "label": "Target", "label_value_or_threshold": "1", "facets": { "Gender": [{ "value_or_threshold": "0", "metrics": [ { "name": "AD", "description": "Accuracy Difference (AD)", "value": -0.13 }, { "name": "CDDPL", "description": "Conditional Demographic Disparity in Predicted Labels (CDDPL)", "value": 0.04 }, ... ] }] } } }
Bericht zur Analyse von Verzerrungen
Der Bericht zur Bias-Analyse enthält mehrere Tabellen und Diagramme, die detaillierte Erklärungen und Beschreibungen enthalten. Dazu gehören, ohne darauf beschränkt zu sein, die Verteilung der Beschriftungswerte, die Verteilung der Facettenwerte, ein allgemeines Modellleistungsdiagramm, eine Tabelle mit Bias-Metriken und deren Beschreibungen. Weitere Informationen zu Bias-Metriken und deren Interpretation finden Sie unter Erfahren Sie, wie Amazon SageMaker Clarify Bias erkennt
SHAP-Analyse
SageMaker Clarify: Verarbeitungsaufträge verwenden den Kernel-SHAP-Algorithmus zur Berechnung von Feature-Attributionen. Der Verarbeitungsauftrag SageMaker Clarify erzeugt sowohl lokale als auch globale SHAP-Werte. Diese helfen dabei, den Beitrag der einzelnen Features zu den Modellvorhersagen zu bestimmen. Lokale SHAP-Werte stellen die Bedeutung der Features für jede einzelne Instance dar, während globale SHAP-Werte die lokalen SHAP-Werte für alle Instances im Datensatz aggregieren. Weitere Informationen zu SHAP-Werten und wie Sie sie interpretieren finden Sie unter Feature-Attributionen, die Shapley-Werte verwenden.
Schema für die SHAP-Analysedatei
Die globalen SHAP-Analyseergebnisse werden im Abschnitt mit den Erläuterungen der Analysedatei unter der kernel_shap Methode gespeichert. Die verschiedenen Parameter der SHAP-Analysedatei lauten wie folgt:
-
Erläuterungen – Der Abschnitt der Analysedatei, der die Ergebnisse der Analyse der Featureswichtigkeit enthält.
-
kernal_shap – Der Abschnitt der Analysedatei, der das globale SHAP-Analyseergebnis enthält.
-
global_shap_values – Ein Abschnitt der Analysedatei, der mehrere Schlüssel-Wert-Paare enthält. Jeder Schlüssel im Schlüssel-Wert-Paar steht für einen Feature-Namen aus dem Eingabedatensatz. Jeder Wert im Schlüssel-Wert-Paar entspricht dem globalen SHAP-Wert des Features. Der globale SHAP-Wert wird ermittelt, indem die SHAP-Werte des Features pro Instance mithilfe der
agg_methodKonfiguration aggregiert werden. Wenn dieuse_logitKonfiguration aktiviert ist, wird der Wert anhand der logistischen Regressionskoeffizienten berechnet, die als logarithmische Chancenverhältnisse interpretiert werden können. -
expected_value – Die durchschnittliche Vorhersage des Basisdatensatzes. Wenn die
use_logitKonfiguration aktiviert ist, wird der Wert anhand der logistischen Regressionskoeffizienten berechnet. -
global_top_shap_text — Wird für die NLP-Erklärbarkeitsanalyse verwendet. Ein Abschnitt der Analysedatei, der eine Reihe von Schlüssel-Wert-Paaren enthält. SageMaker Clarify: Verarbeitungsaufträge aggregieren die SHAP-Werte jedes Tokens und wählen dann die Top-Tokens auf der Grundlage ihrer globalen SHAP-Werte aus. Die
max_top_tokensKonfiguration definiert die Anzahl der auszuwählenden Token.Jedes der ausgewählten Top-Token hat ein Schlüssel-Wert-Paar. Der Schlüssel im Schlüssel-Wert-Paar entspricht dem Text-Feature-Namen eines Top-Tokens. Jeder Wert im Schlüssel-Wert-Paar entspricht den globalen SHAP-Werten des Top-Tokens. Ein Beispiel für ein
global_top_shap_textSchlüssel-Wert-Paar finden Sie in der folgenden Ausgabe.
-
-
Das folgende Beispiel zeigt die Ausgabe der SHAP-Analyse eines tabellarischen Datensatzes.
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Age": 0.022486410860333206, "Gender": 0.007381025261958729, "Income": 0.006843906804137847, "Occupation": 0.006843906804137847, ... }, "expected_value": 0.508233428001 } } } }
Das folgende Beispiel zeigt die Ausgabe der SHAP-Analyse eines Textdatensatzes. Die der Spalte entsprechende Ausgabe Comments ist ein Beispiel für eine Ausgabe, die nach der Analyse eines Text-Features generiert wird.
{ "version": "1.0", "explanations": { "kernel_shap": { "Target": { "global_shap_values": { "Rating": 0.022486410860333206, "Comments": 0.058612104851485144, ... }, "expected_value": 0.46700941970297033, "global_top_shap_text": { "charming": 0.04127962903247833, "brilliant": 0.02450240786522321, "enjoyable": 0.024093569652715457, ... } } } } }
Schema für die generierte Baseline-Datei
Wenn keine SHAP-Basiskonfiguration bereitgestellt wird, generiert der SageMaker Clarif-Verarbeitungsauftrag einen Basisdatensatz. SageMaker Clarify verwendet einen entfernungsbasierten Clustering-Algorithmus, um einen Basisdatensatz aus Clustern zu generieren, die aus dem Eingabe-Datensatz erstellt wurden. Der resultierende Basisdatensatz wird in einer CSV-Datei gespeichert, die sich unter explanations_shap/baseline.csv befindet. Diese Ausgabedatei enthält eine Kopfzeile und mehrere Instances, die auf dem in der Analysekonfiguration angegebenen num_clusters Parameter basieren. Der Basisdatensatz besteht nur aus Feature-Spalten. Das folgende Beispiel zeigt eine Baseline, die durch Clustering des Eingabe-Datasets erstellt wurde.
Age,Gender,Income,Occupation 35,0,2883,1 40,1,6178,2 42,0,4621,0
Schema für lokale SHAP-Werte aus der Erklärbarkeitsanalyse von tabellarischen Datensätzen
Wenn bei tabellarischen Datensätzen eine einzelne Recheninstanz verwendet wird, speichert der Verarbeitungsauftrag SageMaker Clarify die lokalen SHAP-Werte in einer CSV-Datei mit dem Namen. explanations_shap/out.csv Wenn Sie mehrere Recheninstances verwenden, werden lokale SHAP-Werte in mehreren CSV-Dateien im explanations_shap Verzeichnis gespeichert.
Eine Ausgabedatei, die lokale SHAP-Werte enthält, enthält eine Zeile mit den lokalen SHAP-Werten für jede Spalte, die durch die Header definiert ist. Die Header folgen der Benennungskonvention, Feature_Label bei der an den Feature-Namen ein Unterstrich angehängt wird, gefolgt vom Namen Ihrer Zielvariablen.
Bei Problemen mit mehreren Klassen variieren zuerst die Feature-Namen in der Kopfzeile, dann die Beschriftungen. Beispielsweise sind zwei Features F1, F2 und zwei Klassen L1 und L2 in den Überschriften F1_L1, F2_L1. F1_L2, und F2_L2. Wenn die Analysekonfiguration einen Wert für den joinsource_name_or_index Parameter enthält, wird die in der Verknüpfung verwendete Schlüsselspalte an das Ende des Headernamens angehängt. Dies ermöglicht die Zuordnung der lokalen SHAP-Werte zu Instances des Eingabedatensatzes. Es folgt ein Beispiel für eine Ausgabedatei mit SHAP-Werten.
Age_Target,Gender_Target,Income_Target,Occupation_Target 0.003937908,0.001388849,0.00242389,0.00274234 -0.0052784,0.017144491,0.004480645,-0.017144491 ...
Schema für lokale SHAP-Werte aus der NLP-Erklärbarkeitsanalyse
Wenn für die NLP-Erklärbarkeitsanalyse eine einzelne Recheninstanz verwendet wird, speichert der SageMaker Clarif-Verarbeitungsjob lokale SHAP-Werte in einer JSON Lines-Datei mit dem Namen. explanations_shap/out.jsonl Wenn Sie mehrere Compute-Instances verwenden, werden die lokalen SHAP-Werte in mehreren JSON Lines-Dateien im explanations_shap Verzeichnis gespeichert.
Jede Datei, die lokale SHAP-Werte enthält, hat mehrere Datenzeilen, und jede Zeile ist ein gültiges JSON-Objekt. Dieses JSON -Objekt hat die folgenden Attribute:
-
Erklärungen – Der Abschnitt der Analysedatei, der eine Reihe von Kernel-SHAP-Erklärungen für eine einzelne Instance enthält. Jedes Element im Array hat die folgenden Mitglieder:
-
feature_name – Der Header-Name der Funktionen, die in der Header-Konfiguration bereitgestellt werden.
-
data_type — Der vom Clarif-Verarbeitungsjob abgeleitete Feature-Typ. SageMaker Zu den gültigen Werten für Textfeatures gehören
numerical,categorical, undfree_text(für Textfeatures). -
Attributionen – Eine merkmalsspezifische Anordnung von Attributionsobjekten. Ein Textfeature kann mehrere Zuordnungsobjekte haben, jedes für eine durch die
granularityKonfiguration definierte Einheit. Das Attribut-Objekt hat die folgenden Member:-
Zuordnung – Ein klassenspezifisches Array von Wahrscheinlichkeitswerten.
-
Beschreibung – (für Textfeature) Die Beschreibung der Texteinheiten.
-
partial_text — Der Teil des Textes, der durch den Verarbeitungsauftrag Clarify erklärt wird. SageMaker
-
start_idx – Ein auf Null basierender Index zur Identifizierung der Array-Position, die den Anfang des partiellen Textfragments angibt.
-
-
-
Im Folgenden finden Sie ein Beispiel für eine einzelne Zeile aus einer lokalen SHAP-Wertedatei, die zur besseren Lesbarkeit verschönert wurde.
{ "explanations": [ { "feature_name": "Rating", "data_type": "categorical", "attributions": [ { "attribution": [0.00342270632248735] } ] }, { "feature_name": "Comments", "data_type": "free_text", "attributions": [ { "attribution": [0.005260534499999983], "description": { "partial_text": "It's", "start_idx": 0 } }, { "attribution": [0.00424190349999996], "description": { "partial_text": "a", "start_idx": 5 } }, { "attribution": [0.010247314500000014], "description": { "partial_text": "good", "start_idx": 6 } }, { "attribution": [0.006148907500000005], "description": { "partial_text": "product", "start_idx": 10 } } ] } ] }
SHAP-Analysebericht
Der SHAP-Analysebericht enthält ein Balkendiagramm mit einem Maximum der 10 wichtigsten globalen SHAP-Werte. Das folgende Diagrammbeispiel zeigt die SHAP-Werte für die wichtigsten 4 Funktionen.
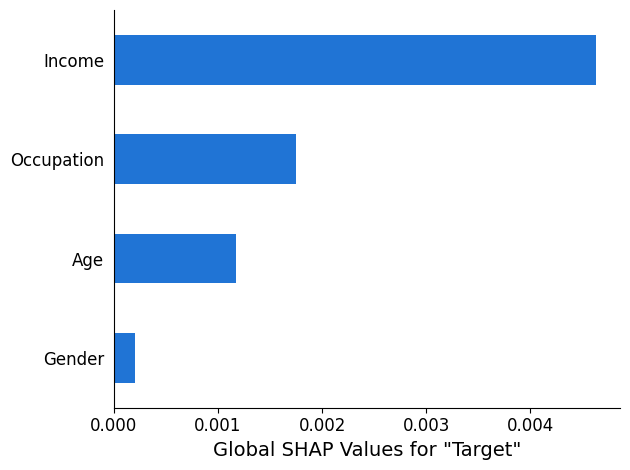
Analyse der Erklärbarkeit von Computer Vision (CV)
SageMaker Clarify Computer Vision Explainability verwendet einen Datensatz, der aus Bildern besteht, und behandelt jedes Bild als eine Sammlung von Superpixeln. Nach der Analyse gibt der Verarbeitungsauftrag SageMaker Clarify einen Datensatz mit Bildern aus, wobei jedes Bild die Heatmap der Superpixel zeigt.
Das folgende Beispiel zeigt links ein Eingabe-Geschwindigkeitsbegrenzungszeichen und rechts eine Heatmap die Größe der SHAP-Werte. Diese SHAP-Werte wurden mit einem Resnet-18-Bilderkennungsmodell berechnet, das darauf trainiert ist, deutsche Verkehrszeichen

Weitere Informationen finden Sie in den Beispielnotizbüchern Explaining Image Classification with SageMaker Clarify
Analyse partieller Abhängigkeitsdiagramme (PDPs)
Partielle Abhängigkeitsdiagramme zeigen die Abhängigkeit der vorhergesagten Zielreaktion von einer Reihe interessierender Eingabefeature. Diese Features sind gegenüber den Werten aller anderen Eingabefeature marginalisiert und werden als Komplementfeature bezeichnet. Intuitiv können Sie die partielle Abhängigkeit als die Zielantwort interpretieren, die als Funktion jedes interessierenden Eingabefeature erwartet wird.
Schema für die Analysedatei
Die PDP-Werte werden im explanations Abschnitt der Analysedatei unter der pdp Methode gespeichert. Die Parameter für sind explanations wie folgt:
-
Erläuterungen – Der Abschnitt der Analysedateien, der die Ergebnisse der Analyse der Featuresbedeutung enthält.
-
pdp – Der Abschnitt der Analysedatei, der eine Reihe von PDP-Erklärungen für eine einzelne Instance enthält. Jedes Element des Arrays hat die folgenden Mitglieder:
-
feature_name – Der Header-Name der in der
headersKonfiguration bereitgestellten Funktionen. -
data_type — Der vom Verarbeitungsjob SageMaker Clarify abgeleitete Feature-Typ. Zu den gültigen Werten für
data_typegehören numerische und kategoriale Werte. -
feature_values – Enthält die im Feature vorhandenen Werte. Wenn der von
data_typeSageMaker Clarify abgeleitete Wert kategorisch ist,feature_valuesenthält er alle Einzelwerte, die das Feature haben könnte. Wenn das vondata_typeSageMaker Clarify abgeleitete Objekt numerisch ist,feature_valuesenthält es eine Liste der zentralen Werte der generierten Buckets. Dergrid_resolutionParameter bestimmt die Anzahl der Buckets, die zur Gruppierung der Feature-Spaltenwerte verwendet werden. -
data_distribution – Eine Reihe von Prozentsätzen, wobei jeder Wert dem Prozentsatz der Instances entspricht, die ein Bucket enthält. Der
grid_resolutionParameter bestimmt die Anzahl der Buckets. Die Werte der Feature-Spalte sind in diesen Buckets gruppiert. -
model_predictions – Ein Array von Modellvorhersagen, wobei jedes Element des Arrays ein Array von Vorhersagen ist, das einer Klasse in der Ausgabe des Modells entspricht.
label_headers – Die von der
label_headersKonfiguration bereitgestellten Beschriftung-Header. -
error – Eine Fehlermeldung, die generiert wird, wenn die PDP-Werte aus einem bestimmten Grund nicht berechnet werden. Diese Fehlermeldung ersetzt den Inhalt der Felder
feature_values,data_distributions, undmodel_predictions.
-
-
Im Folgenden finden Sie ein Beispiel für die Ausgabe einer Analysedatei, die ein PDP-Analyseergebnis enthält.
{ "version": "1.0", "explanations": { "pdp": [ { "feature_name": "Income", "data_type": "numerical", "feature_values": [1046.9, 2454.7, 3862.5, 5270.2, 6678.0, 8085.9, 9493.6, 10901.5, 12309.3, 13717.1], "data_distribution": [0.32, 0.27, 0.17, 0.1, 0.045, 0.05, 0.01, 0.015, 0.01, 0.01], "model_predictions": [[0.69, 0.82, 0.82, 0.77, 0.77, 0.46, 0.46, 0.45, 0.41, 0.41]], "label_headers": ["Target"] }, ... ] } }
PDP-Analysebericht
Sie können einen Analysebericht erstellen, der für jedes Feature ein PDP-Diagramm enthält. Das PDP-Diagramm wird feature_values entlang der X-Achse und das Diagramm model_predictions entlang der Y-Achse dargestellt. Bei Modellen mit mehreren Klassen model_predictions ist dies ein Array, und jedes Element dieses Arrays entspricht einer der Modellvorhersageklassen.
Im Folgenden finden Sie ein Beispiel für ein PDP-Diagramm für das Feature Age. In der Beispielausgabe zeigt das PDP die Anzahl der Feature-Werte, die in Gruppen gruppiert sind. Die Anzahl der Buckets wird durch grid_resolution bestimmt. Die Gruppen mit Feature-Werten werden anhand der Modellvorhersagen grafisch dargestellt. In diesem Beispiel haben die höheren Featureswerte dieselben Modellvorhersagewerte.
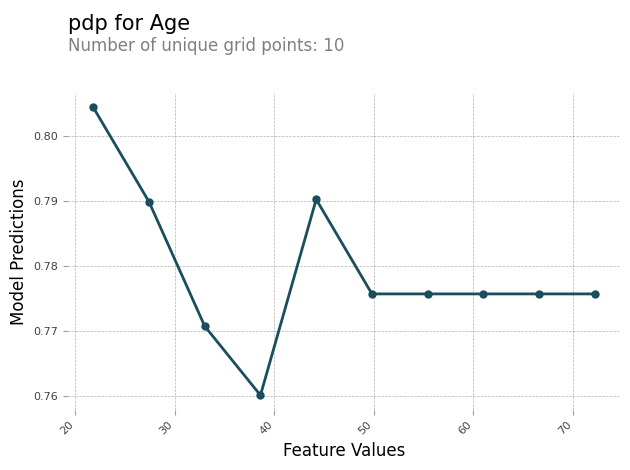
Asymmetrische Shapley-Werte
SageMaker Clarify: Verarbeitungsaufträge verwenden den asymmetrischen Shapley-Wertalgorhythmus, um die Erläuterungen von Zeitreihenprognosemodellen zu berechnen. Dieser Algorithmus bestimmt den Beitrag der Eingabe-Features bei jedem Zeitschritt zu den prognostizierten Vorhersagen.
Schema für die Analysedatei mit asymmetrischen Shapley-Werten
Asymmetrische Shapley-Wertergebnisse werden in einem Amazon S3 S3-Bucket gespeichert. Den Speicherort dieses Buckets finden Sie im Abschnitt Erläuterungen zur Analysedatei. Dieser Abschnitt enthält die Ergebnisse der Analyse der Merkmalswichtigkeit. Die folgenden Parameter sind in der Datei zur Analyse asymmetrischer Shapley-Werte enthalten.
asymmetric_shapley_value — Der Abschnitt der Analysedatei, der Metadaten zu den Ergebnissen des Erklärungsjobs enthält, darunter die folgenden:
explanation_results_path — Der Amazon S3 S3-Standort mit den Erklärungsergebnissen
direction — Die vom Benutzer bereitgestellte Konfiguration für den Konfigurationswert von
directionGranularität — Die vom Benutzer bereitgestellte Konfiguration für den Konfigurationswert von
granularity
Der folgende Ausschnitt zeigt die zuvor genannten Parameter in einer Beispielanalysedatei:
{ "version": "1.0", "explanations": { "asymmetric_shapley_value": { "explanation_results_path": EXPLANATION_RESULTS_S3_URI, "direction": "chronological", "granularity": "timewise", } } }
In den folgenden Abschnitten wird beschrieben, wie die Struktur der Erklärungsergebnisse vom Wert von granularity in der Konfiguration abhängt.
Zeitliche Granularität
Wenn die Granularität gegeben ist, wird timewise die Ausgabe in der folgenden Struktur dargestellt. Der scores Wert stellt die Zuordnung für jeden Zeitstempel dar. Der offset Wert stellt die Vorhersage des Modells anhand der Basisdaten dar und beschreibt das Verhalten des Modells, wenn es keine Daten empfängt.
Der folgende Ausschnitt zeigt eine Beispielausgabe für ein Modell, das Vorhersagen für zwei Zeitschritte trifft. Daher handelt es sich bei allen Attributionen um eine Liste von zwei Elementen, wobei sich der erste Eintrag auf den ersten vorhergesagten Zeitschritt bezieht.
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.1]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.2]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.45, 0.3]}, ] } { "item_id": "item2", "offset": [1.0, 1.2], "explanations": [ {"timestamp": "2019-09-11 00:00:00", "scores": [0.51, 0.35]}, {"timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.22]}, {"timestamp": "2019-09-13 00:00:00", "scores": [0.46, 0.31]}, ] }
Feinkörnige Granularität
Das folgende Beispiel zeigt die Attributionsergebnisse, wenn die Granularität aktiviert ist. fine_grained Der offset Wert hat dieselbe Bedeutung wie im vorherigen Abschnitt beschrieben. Die Attributionen werden für jedes Eingabe-Feature zu jedem Zeitstempel für eine Zielzeitreihe und zugehörige Zeitreihen, falls verfügbar, und für jede statische Kovariate, falls verfügbar, berechnet.
{ "item_id": "item1", "offset": [1.0, 1.2], "explanations": [ {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.11, 0.11]}, {"feature_name": "tts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.34, 0.43]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.15, 0.51]}, {"feature_name": "tts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.81, 0.18]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-11 00:00:00", "scores": [0.01, 0.10]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-12 00:00:00", "scores": [0.14, 0.41]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-13 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_1", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-11 00:00:00", "scores": [0.65, 0.56]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-12 00:00:00", "scores": [0.43, 0.34]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-13 00:00:00", "scores": [0.16, 0.61]}, {"feature_name": "rts_feature_name_2", "timestamp": "2019-09-14 00:00:00", "scores": [0.95, 0.59]}, {"feature_name": "static_covariate_1", "scores": [0.6, 0.1]}, {"feature_name": "static_covariate_2", "scores": [0.1, 0.3]}, ] }
timewiseSowohl für Anwendungsfälle als auch für fine-grained Anwendungsfälle werden die Ergebnisse im Format JSON Lines (.jsonl) gespeichert.
