Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Amazon SageMaker Debugger-Architektur
In diesem Thema erhalten Sie einen allgemeinen Überblick über den Amazon SageMaker Debugger-Workflow.
Der Debugger unterstützt Profiling-Funktionen zur Leistungsoptimierung, um Rechenprobleme wie Systemengpässe und Unterauslastung zu identifizieren und die Auslastung der Hardwareressourcen in großem Umfang zu optimieren.
Die Debugging-Funktionalität des Debuggers für die Modelloptimierung dient der Analyse nicht konvergierender Trainingsprobleme, die auftreten können, bei gleichzeitiger Minimierung der Verlustfunktionen mithilfe von Optimierungsalgorithmen, wie z. B. dem Gradientenabstieg und seinen Variationen.
Das folgende Diagramm zeigt die Architektur von SageMaker Debugger. Debugger analysiert Ihren Trainingsjob anhand der Blöcke mit fetten Grenzlinien.
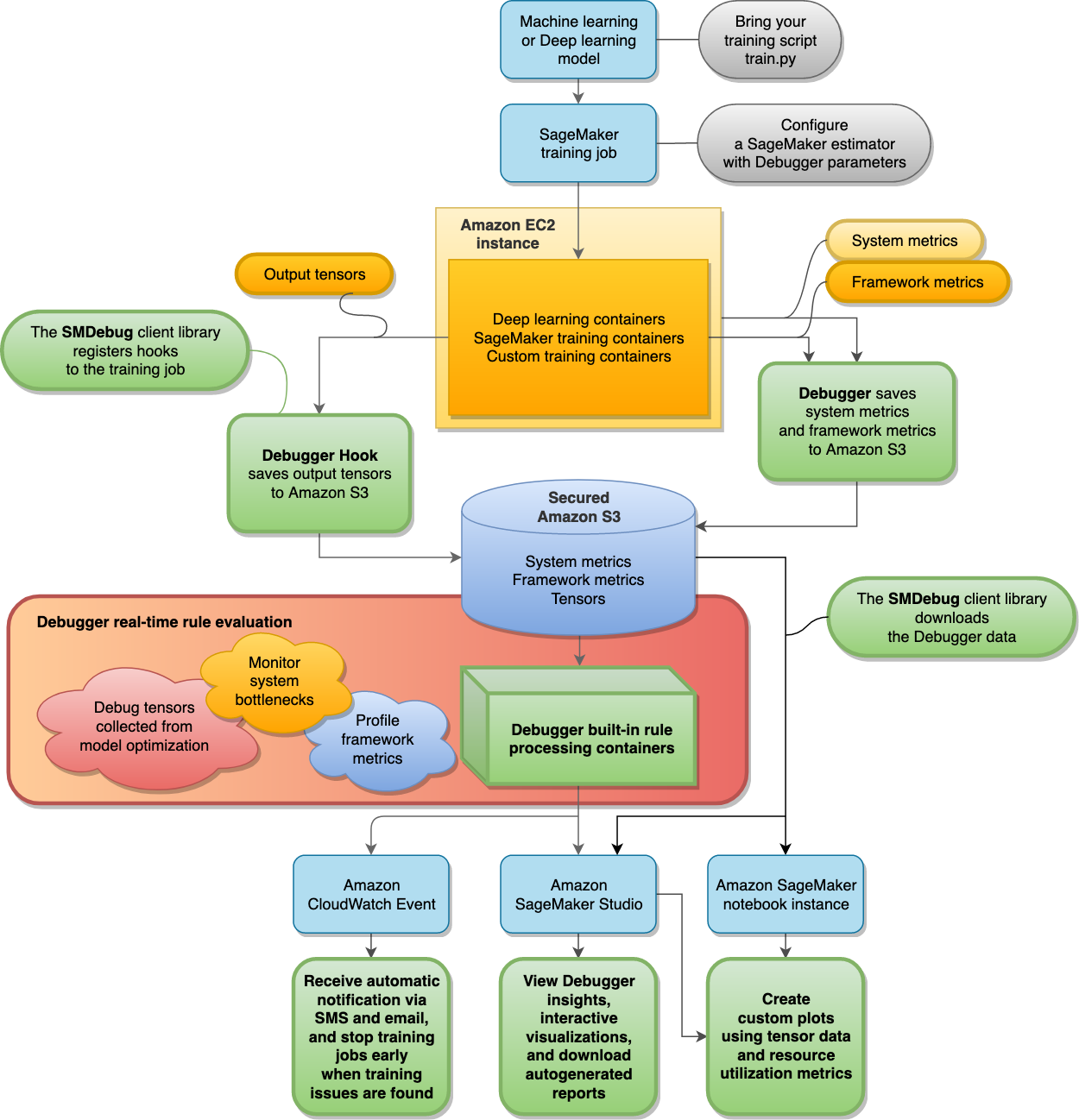
Debugger speichert die folgenden Daten aus Ihren Trainingsjobs in Ihrem gesicherten Amazon-S3-Bucket:
-
Ausgabetensoren – Sammlungen von Skalaren und Modellparametern, die während des Trainings von ML-Modellen während der Vorwärts- und Rückwärtsläufe kontinuierlich aktualisiert werden. Die Ausgabetensoren umfassen Skalarwerte (Genauigkeit und Verlust) und Matrizen (Gewichte, Gradienten, Eingabe- und Ausgabeschichten).
Anmerkung
Standardmäßig überwacht und debuggt der Debugger SageMaker Trainingsjobs, ohne dass Debugger-spezifische Parameter in AI-Schätzern konfiguriert sind. SageMaker Der Debugger erfasst alle 500 Millisekunden Systemmetriken und alle 500 Schritte grundlegende Ausgabetensoren (skalare Ausgaben wie Verlust und Genauigkeit). Außerdem wird die
ProfilerReportRegel ausgeführt, um die Systemmetriken zu analysieren und das Studio Debugger Insights-Dashboard und einen Profilerstellungsbericht zusammenzufassen. Debugger speichert die Ausgabedaten in Ihrem gesicherten Amazon-S3-Bucket.
Die integrierten Debuger-Regeln werden auf Verarbeitungscontainern ausgeführt, die darauf ausgelegt sind, Modelle für Machine Learning zu bewerten, indem sie die in Ihrem S3-Bucket gesammelten Trainingsdaten verarbeiten (siehe Prozessdaten und Modelle auswerten). Die integrierten Regeln werden vollständig vom Debugger verwaltet. Sie können auch eigene, auf Ihr Modell zugeschnittene Regeln erstellen, um auf Probleme zu achten, die Sie überwachen möchten.
