Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden Sie den SageMaker AI DeepAR-Prognosealgorithmus
Der Amazon SageMaker AI DeepAR-Prognosealgorithmus ist ein überwachter Lernalgorithmus zur Prognose skalarer (eindimensionaler) Zeitreihen mithilfe von rekurrenten neuronalen Netzwerken (RNN). Bei klassischen Prognoseverfahren wie z. B. ARIMA (Autoregressive Integrated Moving Average) oder ETS (Exponential Smoothing) wird ein Modell für jede einzelne Zeitreihe verwendet. Mit diesem Modell wird dann die Zeitreihe in die Zukunft extrapoliert.
In vielen Anwendungen haben Sie jedoch mehrere ähnliche Zeitreihen über eine Reihe abschnittsübergreifender Einheiten hinweg. Beispiel: Sie haben möglicherweise Zeitreihengruppierungen für unterschiedlichen Produktbedarf, Serverauslastung und Webseitenanforderungen. Für diesen Anwendungstyp ist das Training eines einzelnen Modells gemeinsam über alle Zeitreihen nützlich. DeepAR verwendet diesen Ansatz. Sobald der Datensatz Hunderte verwandter Zeitreihen enthält, liefert die DeepAR-Methode bessere Ergebnisse als die Standardmethoden ARIMA und ETS. Sie können das trainierte Modell auch zum Generieren von Prognosen für neue Zeitreihen verwenden, die ähnlich sind wie diejenigen, mit denen es trainiert wurde.
Die Trainingseingabe für den DeepAR-Algorithmus ist/sind eine oder vorzugsweise mehrere target-Zeitreihe(n), die durch den gleichen Prozess oder ähnliche Prozesse erzeugt wurde(n). Basierend auf diesem Eingabedatensatz schult der Algorithmus ein Modell, das eine Approximation dieses/dieser Prozesses/Prozesse erlernt und daraus die Entwicklung der Ziel-Zeitreihe vorhersagt. Jede Zielzeitreihe kann optional mit einem Vektor statischer (zeitunabhängiger) kategorischen Features verknüpft werden, die durch das Feld cat bereitgestellt werden, sowie mit einem Vektor dynamischer (zeitabhängiger) Zeitreihen, die durch das Feld dynamic_feat bereitgestellt werden. SageMaker KI trainiert das DeepAR-Modell, indem sie nach dem Zufallsprinzip Trainingsbeispiele aus jeder Zielzeitreihe im Trainingsdatensatz auswählt. Jedes Trainingsbeispiel besteht aus einem Paar benachbarter Kontext- und Prognosefenstern mit festen vordefinierten Längen. Um zu steuern, wie weit in die Vergangenheit das Netzwerk sehen kann, verwenden Sie den context_length-Hyperparameter. Um zu steuern, wie weit in die Zukunft Prognosen erstellt werden können, verwenden Sie den prediction_length-Hyperparameter. Weitere Informationen finden Sie unter So funktioniert der DeepAR-Algorithmus.
Themen
Eingabe/Ausgabe-Schnittstelle für den DeepAR-Algorithmus
DeepAR unterstützt zwei Datenkanäle. Der erforderliche train-Kanal beschreibt den Trainingsdatensatz. Der optionale test-Kanal beschreibt einen Datensatz, den der Algorithmus zur Bewertung der Modellgenauigkeit nach Trainings verwendet. Sie können den Trainings- und Testdatensatz im JSON Lines
Bei der Angabe der Pfade für das Trainings- und Testdaten können Sie eine einzelne Datei oder ein Verzeichnis mit mehreren Dateien bereitstellen, die in Unterverzeichnissen gespeichert werden können. Wenn Sie ein Verzeichnis angeben, verwendet DeepAR alle Dateien im Verzeichnis als Eingabewerte für den entsprechenden Kanal, mit Ausnahme derjenigen, die mit einem Punkt (.) beginnen, und derjenigen mit der Bezeichnung SUCCESS. Auf diese Weise wird sichergestellt, dass Sie Ausgabeordner, die von Spark-Jobs erstellt wurden, direkt als Eingabekanäle für Ihre DeepAR-Trainingsaufträge verwenden können.
Standardmäßig bestimmt das DeepAR-Modell das Eingabeformat aus der Dateierweiterung (.json, .json.gz oder .parquet) im angegebenen Eingabepfad. Wenn der Pfad nicht auf eine dieser Erweiterungen endet, müssen Sie das Format im SDK für Python explizit angeben. Verwenden Sie den content_type-Parameter der s3_input
Die Datensätze in Ihren Eingabedateien sollten die folgenden Felder enthalten:
-
start-Eine Zeichenfolge mit dem FormatYYYY-MM-DD HH:MM:SS. Der Start-Zeitstempel darf keine Zeitzoneninformationen enthalten. -
target- Eine Reihe von Gleitkommawerten oder ganzen Zahlen, die die Zeitreihe darstellen. Sie können fehlende Werte alsnull-Literale, als"NaN"-Zeichenfolgen in JSON oder alsnan-Gleitkomma-Werte in Parquet codieren. -
dynamic_feat(optional) – Ein Array von Arrays aus Gleitkommawerten oder Ganzzahlen, das den Vektor von Zeitreihen für benutzerdefinierte Features (dynamische Funktionen) darstellt. Wenn Sie dieses Feld festlegen, müssen alle Datensätze die gleiche Anzahl von inneren Arrays (die gleiche Anzahl von Funktionszeitreihen) besitzen. Darüber hinaus muss jedes innere Array die gleiche Länge haben wie der zugehörigetarget-Wert plusprediction_length. Fehlende Werte werden in den Funktionen nicht unterstützt. Wenn beispielsweise eine Ziel-Zeitreihe die Nachfrage verschiedener Produkte repräsentiert, kann ein zugehörigesdynamic_feateine boolesche Zeitreihe sein, die angibt, ob eine Werbeaktion für das jeweilige Produkt zum Einsatz kam (1) oder nicht (0):{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(optional) – Eine Reihe von kategorischen Features, mit denen die Gruppen kodiert werden können, zu denen der Datensatz gehört. Kategorische Features müssen als 0-basierte Reihenfolge von positiven Ganzzahlen codiert werden. Beispiel: Die kategorische Domain {R, G, B} kann als {0, 1, 2} codiert werden. Alle Werte von jeder kategorischen Domain müssen im Trainingsdatensatz repräsentiert werden. Dies liegt daran, dass der DeepAR-Algorithmus Prognosen nur für Kategorien erstellen kann, die während des Trainings beobachtet wurden. Jedes kategorische Feature ist außerdem in einen Raum mit geringer Dimensionalität eingebettet, dessen Dimensionalität durch denembedding_dimension-Hyperparameter gesteuert wird. Weitere Informationen finden Sie unter DeepAR-Hyperparameter.
Wenn Sie eine JSON-Datei verwenden, muss diese im JSON Lines
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
In diesem Beispiel verfügt jede Zeitreihe über zwei zugehörige kategorische Features und eine Zeitreihenfunktion.
Bei Parquet verwenden Sie dieselben drei Felder als Spalten. Außerdem kann "start" vom Typ datetime sein. Sie können Parquet-Dateien mit gzip (gzip) oder mit der Snappy-Komprimierungsbibliothek (snappy) komprimieren.
Wird der Algorithmus ohne – catund dynamic_feat-Felder trainiert, lernt er ein „globales” Modell, d. h. ein Modell, das die spezifische Identität der Ziel-Zeitreihe zur Inferenzzeit ignoriert und nur von ihrer Form abhängig ist.
Wenn das Modell auf den für jede Zeitreihe zur Verfügung gestellten – catund dynamic_feat-Funktionsdaten basiert, wird die Voraussage wahrscheinlich durch die Art der Zeitreihe mit den entsprechenden cat-Funktionen beeinflusst. Wenn die target-Zeitreihe beispielsweise den Bedarf an Kleidungsstücken darstellt, können Sie einen zweidimensionalen cat-Vektor zuordnen, der die Art des Artikels (z. B. 0 = Schuhe, 1 = Kleidungsstück) in der ersten Komponente und die Farbe eines Artikels (z. B. 0 = Rot, 1 = Blau) in der zweiten Komponente kodiert. Ein Beispiel für eine Eingabe sähe wie folgt aus:
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
Zur Inferenzzeit können Sie Vorhersagen für Ziele mit cat-Werten anfordern, die Kombinationen der in den Trainingsdaten beobachteten cat-Werte sind, zum Beispiel:
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
Die folgenden Richtlinien gelten für Trainingsdaten:
-
Die Startzeit und Länge der Zeitreihen können sich unterscheiden. Im Marketing werden beispielsweise Produkte oft zu unterschiedlichen Terminen in einem Versandkatalog erfasst, sodass sich ihre Beginndaten naturgemäß unterscheiden. Alle Reihen müssen jedoch die gleiche Häufigkeit, Anzahl von kategorischen Features sowie Anzahl der dynamischen Funktionen aufweisen.
-
Es erfolgt eine zufällige Wiedergabe der Trainingsdatei in Bezug auf die Position der Zeitreihen in der Datei. Anders ausgedrückt sollte die Reihenfolge der Zeitreihe in der Datei zufällig sein.
-
Stellen Sie sicher, dass Sie das
start-Feld korrekt festlegen. Der Algorithmus verwendet denstart-Zeitstempel zum Ableiten der internen Funktionen. -
Wenn Sie kategorische Features (
cat) verwenden, müssen alle Zeitreihen die gleiche Anzahl von kategorischen Features aufweisen. Wenn der Datensatz dascat-Feld enthält, wird er vom Algorithmus verwendet und die Kardinalität der Gruppen aus dem Datensatz wird extrahiert. Der Standardwert fürcardinalityist"auto". Wenn der Datensatz dascat-Feld enthält, Sie es aber nicht verwenden möchten, können Sie es deaktivieren, indem Siecardinalityauf""festlegen. Wenn ein Modell mit einercat-Funktion trainiert wurde, müssen Sie sie als Inferenz einschließen. -
Wenn Ihr Datensatz das
dynamic_feat-Feld enthält, wird es vom Algorithmus automatisch verwendet. Alle Zeitreihen müssen die gleiche Anzahl von Feature-Zeitreihen besitzen. Die Zeitpunkte in jeder der Feature-Zeitreihen one-to-one entsprechen den Zeitpunkten im Ziel. Darüber hinaus sollte der Eintrag imdynamic_feat-Feld die gleiche Länge aufweisen wie dastarget. Wenn der Datensatz dasdynamic_feat-Feld enthält, Sie es aber nicht verwenden möchten, deaktivieren Sie es, indem Sienum_dynamic_featauf""festlegen. Wenn das Modell mit demdynamic_feat-Feld trainiert wurde, müssen Sie dieses Feld als Inferenz bereitstellen. Darüber hinaus muss jede Funktion die Länge des angegebenen Ziels plusprediction_lengthhaben. Mit anderen Worten: Sie müssen den Funktionswert in der Zukunft angeben.
Falls Sie optionale Testkanaldaten angeben, wertet der DeepAR-Algorithmus das trainierte Modell mit unterschiedlichen Genauigkeitsmetriken aus. Der Algorithmus berechnet die Wurzel des mittleren quadratischen Prognosefehlers (Root Mean Square Error, RMSE) für die Testdaten wie folgt:
-y(i,t))^2))](images/deepar-1.png)
yi,t ist der wahre Wert der Zeitreihe i zum Zeitpunkt t. ŷi,t ist die mittlere Voraussage. Die Summe umfasst alle n Zeitreihen der Testdaten und die letzten "T" Zeitpunkte jeder Zeitreihe, wobei "Τ" dem Prognosehorizont entspricht. Die Länge des Prognosehorizonts legen Sie mit dem Hyperparameter prediction_length fest. Weitere Informationen finden Sie unter DeepAR-Hyperparameter.
Darüber hinaus wertet der Algorithmus die Genauigkeit der Prognosenverteilung anhand des gewichteten Quantilverlusts aus. Für ein Quantil des Bereichs [0, 1] wird der gewichtete Quantilverlust wie folgt definiert:
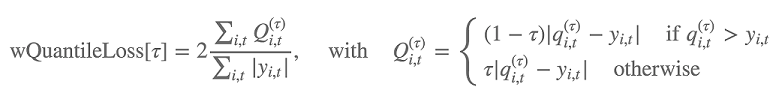
qi,t(τ) ist das τ-Quantil der Verteilung, die das Modell vorhersagt. Um anzugeben, für welche Quantile der Verlust berechnet werden soll, legen Sie den test_quantiles-Hyperparameter fest. Zusätzlich wird der Durchschnitt der vorgegebenen Quantilverluste im Rahmen der Trainingsprotokolle gemeldet. Weitere Informationen finden Sie unter DeepAR-Hyperparameter.
Für Inferenzen akzeptiert DeepAR das JSON-Format und die folgenden Felder:
-
"instances", das eine oder mehrere Zeitreihen im JSON Lines-Format umfasst -
Ein
"configuration"-Name, der die Parameter zur Generierung der Prognose enthält
Weitere Informationen finden Sie unter DeepAR-Inferenzformate.
Bewährte Methoden zur Nutzung des DeepAR-Algorithmus
Folgen Sie bei der Vorbereitung Ihrer Zeitreihendaten diesen bewährten Methoden, um bestmögliche Ergebnisse zu erzielen:
-
Stellen Sie immer die gesamten Zeitreihen für Trainings, Tests und beim Aufrufen des Modells für Inferenz bereit, es sei denn, Sie teilen Ihren Datensatz für Trainings und Tests auf. Unabhängig davon, wie Sie
context_lengthfestlegen, sollten Sie die Zeitreihen nie unterteilen oder nur teilweise angeben. Das Modell verwendet Datenpunkte weiter zurück als durch den incontext_lengthfestgelegten Wert für die isolierte Wertefunktion angegeben. -
Beim Optimieren eines DeepAR-Modells können Sie den Datensatz aufteilen, um einen Trainings- und einen Testdatensatz zu erstellen. In einer typischen Auswertung testen Sie das Modell in derselben Zeitreihe, die für das Training verwendet wird, aber für zukünftige
prediction_length-Zeitpunkte, die sofort auf den letzten während des Trainings sichtbaren Zeitpunkt folgen. Sie können Trainings- und Testdatensätze erstellen, die diese Kriterien erfüllen, indem Sie den gesamten Datensatz (die vollständige Länge aller verfügbaren Zeitreihen) als Testdatensatz verwenden und die letztenprediction_length-Punkte aus jeder Zeitreihe für Trainings entfernen. Während des Trainings sieht das Modell keine Zielwerte für Zeitpunkte, für die es während des Tests ausgewertet wird. Während des Tests hält der Algorithmus die letztenprediction_length-Punkte jeder Zeitreihe im Testdatensatz zurück und generiert eine Prognose. Anschließend vergleicht er die Prognose mit den einbehaltenen Werten. Sie können komplexere Auswertungen erstellen, indem Sie Zeitreihen mehrmals im Testdatensatz wiederholen, sie aber an verschiedenen Endpunkten abschneiden. Mit diesem Ansatz werden Genauigkeitsmetriken über mehrere Prognosen von verschiedenen Zeitpunkten gemittelt. Weitere Informationen finden Sie unter Optimieren eines DeepAR-Modells. -
Vermeiden Sie die Verwendung von sehr großen Werten (>400) für die
prediction_length, da das Modell dadurch langsamer und weniger genau wird. Wenn Sie weiter in die Zukunft prognostizieren wollen, sollten Sie Ihre Daten mit einer geringeren Häufigkeit aggregieren. Verwenden Sie z. B.5minstatt1min. -
Da Zeitdifferenzen verwendet werden, kann ein Modell in der Zeitreihe weiter zurück reichen als der für
context_lengthangegebene Wert. Aus diesem Grund müssen Sie diesen Parameter nicht auf einen großen Wert festlegen. Wir empfehlen Ihnen, mit dem Wert, den Sie fürprediction_lengthverwendet haben, zu beginnen. -
Schulen Sie ein DeepAR-Modell am besten mit allen verfügbaren Zeitreihen. Auch wenn ein mit einer einzelnen Zeitreihe trainiertes DeepAR-Modell gut funktionieren kann, liefern Standardprognosealgorithmen, wie ARIMA oder ETS, möglicherweise genauere Ergebnisse. Der DeepAR-Algorithmus liefert bessere Ergebnisse als die Standardmethoden, sobald der Datensatz Hunderte verwandter Zeitreihen enthält. Derzeit erfordert DeepAR, dass die Gesamtanzahl der Beobachtungen, die in allen Trainingszeitreihen verfügbar sind, mindestens 300 beträgt.
EC2 Instanzempfehlungen für den DeepAR-Algorithmus
Sie können DeepAR sowohl auf GPU- als auch auf CPU-Instances und in Einzel- und Multi-Maschinen-Umgebungen trainieren. Es wird empfohlen, mit einer einzelnen CPU-Instance zu beginnen (z. B. ml.c4.2xlarge oder ml.c4.4xlarge) und nur zu GPU-Instances und mehreren Maschinen zu wechseln, wenn dies unbedingt erforderlich ist. Die Verwendung GPUs mehrerer Maschinen verbessert den Durchsatz nur bei größeren Modellen (mit vielen Zellen pro Schicht und vielen Schichten) und bei großen Mini-Batch-Größen (z. B. mehr als 512).
Für Inferenzen unterstützt DeepAR nur CPU-Instances.
Durch Angeben großer Werte für context_length, prediction_length, num_cells, num_layers oder mini_batch_size können Modelle erstellt werden, die für Small Instances zu groß sind. Verwenden Sie in diesem Fall einen größeren Instance-Typ oder reduzieren Sie die Werte für diese Parameter. Dieses Problem tritt häufig beim Ausführen von Hyperparameteroptimierungsaufträgen auf. Verwenden Sie in diesem Fall einen Instance-Typ, der für den Modelloptimierungsauftrag groß genug ist, und begrenzen Sie ggf. die oberen Werte der kritischen Parameter, um ein Misserfolg von Aufträgen zu vermeiden.
DeepAR-Beispiel-Notebooks
Ein Beispielnotizbuch, das zeigt, wie ein Zeitreihendatensatz für das Training des SageMaker KI-DeepAR-Algorithmus vorbereitet und wie das trainierte Modell für die Durchführung von Schlussfolgerungen eingesetzt wird, finden Sie in der DeepAR-Demo zum Elektrizitätsdatensatz, in der die erweiterten Funktionen von DeepAR anhand eines realen Datensatzes
Weitere Informationen zum Amazon SageMaker AI DeepAR-Algorithmus finden Sie in den folgenden Blogbeiträgen:
