Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Ergebnisse der Empfehlungen
Jedes Ergebnis eines Inference Recommender-Jobs enthält InstanceType, InitialInstanceCount und EnvironmentParameters, bei denen es sich um optimierte Umgebungsvariablenparameter für Ihren Container handelt, um dessen Latenz und Durchsatz zu verbessern. Die Ergebnisse beinhalten auch Leistungs- und Kostenkennzahlen wieMaxInvocations, ModelLatency, CostPerHour, CostPerInference, CpuUtilization, und MemoryUtilization.
In der folgenden Tabelle finden Sie eine Beschreibung dieser Kennzahlen. Diese Metriken können Ihnen helfen, Ihre Suche nach der besten Endpunktkonfiguration für Ihren Anwendungsfall einzugrenzen. Wenn Ihre Motivation beispielsweise das allgemeine Preis-Leistungs-Verhältnis mit Schwerpunkt auf dem Durchsatz ist, sollten Sie sich auf Folgendes konzentrieren CostPerInference.
| Metrik | Beschreibung | Anwendungsfall |
|---|---|---|
|
|
Das Zeitintervall, das ein Modell benötigt, um zu reagieren, aus Sicht der SageMaker KI. Dieses Intervall enthält die lokale Kommunikationszeitspanne für das Senden der Anforderung und Abrufen der Antwort vom Container eines Modells sowie die Zeitspanne für das Abschließen der Inferenz im Container. Einheiten: Millisekunden |
Latenzempfindliche Workloads wie Anzeigenschaltung und medizinische Diagnose |
|
|
Die maximale Anzahl von Einheiten: keine |
Auf den Durchsatz ausgerichtete Workloads wie Videoverarbeitung oder Batch-Inferenz |
|
|
Die geschätzten Kosten pro Stunde für Ihren Echtzeit-Endpunkt. Einheiten: US-Dollar |
Kostensensible Workloads ohne Latenzfristen |
|
|
Die geschätzten Kosten pro Inferenzgespräch für Ihren Echtzeit-Endpunkt. Einheiten: US-Dollar |
Maximieren Sie das allgemeine Preis-/Leistungsverhältnis und konzentrieren Sie sich dabei auf den Durchsatz |
|
|
Die erwartete CPU-Auslastung bei maximalen Aufrufen pro Minute für die Endpunkt-Instance. Einheiten: Prozent |
Verschaffen Sie sich einen Überblick über den Zustand der Instance beim Benchmarking, indem Sie Einblick in die Kern-CPU-Auslastung der Instance haben |
|
|
Die erwartete Speicherauslastung bei maximalen Aufrufen pro Minute für die Endpunkt-Instance. Einheiten: Prozent |
Verschaffen Sie sich einen Überblick über den Zustand der Instance beim Benchmarking, indem Sie Einblick in die Kernspeichernutzung der Instance haben |
In einigen Fällen möchten Sie vielleicht andere SageMaker KI Endpoint Invocation-Metriken untersuchen, wie CPUUtilization z. Jedes Inference Recommender-Job-Ergebnis enthält die Namen der Endpunkte, die während des Auslastungstests gestartet wurden. Sie können CloudWatch damit die Protokolle für diese Endpunkte überprüfen, auch nachdem sie gelöscht wurden.
Die folgende Abbildung zeigt ein Beispiel für CloudWatch Kennzahlen und Diagramme, die Sie anhand Ihres Empfehlungsergebnisses für einen einzelnen Endpunkt überprüfen können. Dieses Empfehlungsergebnis stammt aus einem Standardjob. Die Skalarwerte aus den Empfehlungsergebnissen lassen sich so interpretieren, dass sie auf dem Zeitpunkt basieren, zu dem sich das Aufruf-Diagramm zum ersten Mal zu nivellieren beginnt. Der gemeldete ModelLatency Wert befindet sich beispielsweise am Anfang des Plateaus um 03:00:31.
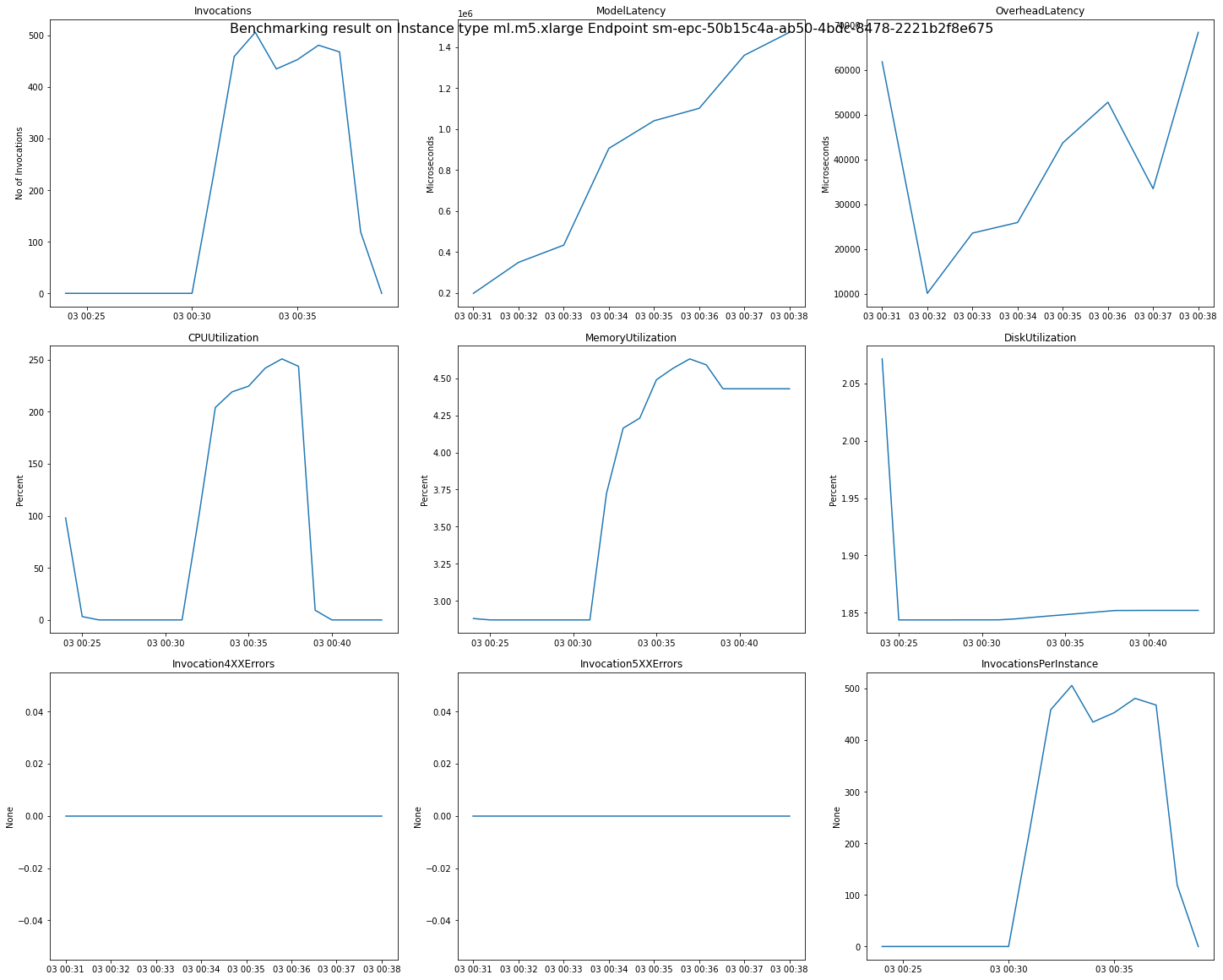
Vollständige Beschreibungen der in den vorherigen Diagrammen verwendeten CloudWatch Metriken finden Sie unter SageMaker KI Endpoint Invocation-Metriken.
Im /aws/sagemaker/InferenceRecommendationsJobs namespace finden Sie auch Leistungskennzahlen wie ClientInvocations und NumberOfUsers von Inference Recommender veröffentlicht. Eine vollständige Liste der Metriken und Beschreibungen, die von Inference Recommender veröffentlicht wurden, finden Sie unter SageMaker Kennzahlen für Jobs von Inference Recommender.
Im Notizbuch Amazon SageMaker Inference Recommender — CloudWatch Metrics
