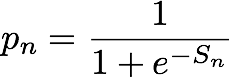Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
So funktioniert IP Insights
Amazon SageMaker AI IP Insights ist ein unbeaufsichtigter Algorithmus, der beobachtete Daten in Form von (Entitäts-, IPv4 Adress-) Paaren verwendet, die Entitäten IP-Adressen zuordnen. IP Insights bestimmt, wie wahrscheinlich es ist, dass eine Entity eine bestimmte IP-Adresse verwendet, indem latente Vektordarstellungen sowohl für Entitys als auch IP-Adressen erlernt werden. Der Abstand zwischen diesen beiden Darstellungen kann dann als Proxy dazu dienen, wie wahrscheinlich diese Zuordnung ist.
Der IP Insights-Algorithmus verwendet ein neuronales Netzwerk, um die latenten Vektordarstellungen für Entitys und IP-Adressen zu lernen. Entitys werden zuerst an einem großen, aber festen Hash-Speicherplatz gehasht und anschließend mit einer einfachen Einbettungsebene codiert. Zeichenketten wie Benutzernamen oder Konten IDs können direkt in IP Insights eingegeben werden, da sie in Protokolldateien erscheinen. Sie müssen die Daten für die Entity-IDs nicht vorverarbeiten. Sie können Entitys als beliebigen Zeichenfolgenwert sowohl während des Trainings als auch der Inferenz bereitstellen. Die Hash-Größe sollte mit einem Wert konfiguriert werden, der hoch genug ist, um sicherzustellen, dass die Anzahl der Kollisionen, die auftreten, wenn verschiedene Entitäten auf denselben latenten Vektor abgebildet werden, unbedeutend bleibt. Weitere Informationen zum Auswählen geeigneter Hash-Größen finden Sie unter Feature Hashing for Large Scale Multitask Learning
Während des Trainings generiert IP Insights automatisch negative Stichproben, indem Entitys und IP-Adressen nach dem Zufallsprinzip gekoppelt werden. Diese negativen Stichproben stehen für Daten, deren Auftreten in Wirklichkeit weniger wahrscheinlich ist. Das Modell ist zur Unterscheidung zwischen den positiven Stichproben, die in den Trainingsdaten erkannt werden, und diesen negativen Stichproben trainiert. Genauer gesagt wird das Modell trainiert, die Kreuz-Entropie, auch als Protokollverlust bezeichnet, zu minimieren, die wie folgt definiert ist:
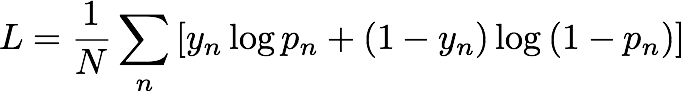
yn ist die Bezeichnung, die angibt, ob die Stichprobe aus der realen Verteilung der beobachteten Daten (yn=1) oder aus der Verteilung stammt, die negative Stichproben erzeugt (yn=0). pn ist die Wahrscheinlichkeit, dass die Stichprobe aus der realen Verteilung stammt, wie sie vom Modell vorhergesagt wurde.
Das Generieren von negativen Stichproben ist ein wichtiger Prozess, der verwendet wird, um ein präzises Modell der beobachteten Daten zu erreichen. Wenn negative Stichproben äußerst unwahrscheinlich sind, z. B., wenn alle IP-Adressen in negativen Stichproben 10.0.0.0 lauten, dann lernt das Modell trivial, negative Stichproben zu unterscheiden, und kann die Merkmale des tatsächlich beobachteten Datsatzes nicht präzise angeben. Um negative Stichproben realistischer zu gestalten, generiert IP Insights negative Stichproben sowohl durch zufälliges Generieren von IP-Adressen als auch durch zufälliges Auswählen von IP-Adressen aus den Trainingsdaten. Sie können die Art der negativen Stichprobenerhebung und die Raten, mit denen negative Stichproben generiert werden, mit den Hyperparametern random_negative_sampling_rate und shuffled_negative_sampling_rate konfigurieren.
Bei einem n-ten Paar (Entität, IP-Adresse) gibt das IP Insights-Modell ein Ergebnis, Sn aus, welches angibt, wie kompatibel die Entität mit der IP-Adresse ist. Diese Punktzahl entspricht dem Log Odds Ratio (logarithmiertes Chancenverhältnis) für ein bestimmtes Paar (Entity, IP-Adresse), das aus einer realen Verteilung stammt, im Vergleich zu einem Paar aus einer negativen Verteilung. Sie wird wie folgt definiert:
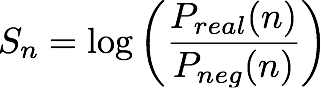
Die Punktzahl ist im Wesentlichen ein Maß für die Ähnlichkeit der Vektordarstellungen der n-ten Entity und IP-Adresse. Sie erlaubt eine Interpretation, wie wahrscheinlicher es ist, dieses Ereignis in Wirklichkeit zu beobachten, als in einem nach dem Zufallsprinzip generierten Datensatz. Während des Trainings verwendet der Algorithmus dieses Ergebnis, um eine Schätzung der Wahrscheinlichkeit zu berechnen, dass eine Stichprobe aus der realen Verteilung stammt, pn, um sie bei der Kreuzentropieminimierung zu verwenden, wobei: