Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
So funktioniert der Object2Vec-Algorithmus
Wenn Sie den Amazon SageMaker AI Object2Vec-Algorithmus verwenden, folgen Sie dem Standard-Workflow: Verarbeiten Sie die Daten, trainieren das Modell und ziehen Sie Schlussfolgerungen.
Themen
Schritt 1: Verarbeiten von Daten
Während der Vorverarbeitung konvertieren Sie die Daten in das Textdateiformat JSON Linesnp.random.shuffle und für Unix shuf verwenden.
Schritt 2: Schulen eines Modells
Der SageMaker AI Object2Vec-Algorithmus besteht aus den folgenden Hauptkomponenten:
-
Zwei Eingabekanäle – Die zwei Eingabekanäle akzeptieren ein Objektpaar des gleichen oder verschiedener Typen als Eingaben und übergeben sie an unabhängige und anpassbare Encoder.
-
Zwei Encoder – Die beiden Encoder, enc0 und enc1, konvertieren jedes Objekt in einen eingebetteten Vektor mit fester Länge. Die codierten Einbettungen der Objekte im Paar werden dann in einen Vergleichsoperator übergeben.
-
Ein Vergleichsoperator – Der Vergleichsoperator vergleicht die Einbettungen auf unterschiedliche Weise und gibt Ergebnisse aus, die die Stärke der Beziehung zwischen den gepaarten Objekten angeben. Im Ausgabeergebnis für ein Satzpaar. Beispielsweise gibt "1" eine starke Beziehung zwischen einem Satzpaar und "0" eine schwache Beziehung an.
Zum Zeitpunkt des Trainings akzeptiert der Algorithmus Paare von Objekten und deren Beziehungsbezeichnungen oder Ergebnisse als Eingaben. Die Objekte in jedem Paar können wie zuvor beschrieben unterschiedlichen Typs sein. Wenn die Eingaben für beide Encoder aus den gleichen Einheiten auf Token-Ebene bestehen, können Sie ein gemeinsames Token verwenden und die Ebene durch Festlegen des Hyperparameters tied_token_embedding_weight auf True einbetten, wenn Sie den Trainingsauftrag erstellen. Dies ist z. B. möglich, wenn Sie Sätze vergleichen, die beide über Einheiten auf Wort-Token-Ebene verfügen. Um negative Stichproben zu einer festgelegten Rate zu generieren, legen Sie den Hyperparameter negative_sampling_rate auf das gewünschte Verhältnis von positiven zu negativen Stichproben fest. Dieser Hyperparameter beschleunigt das Lernen bezüglich der Unterscheidung zwischen den positiven Stichproben, die in den Trainingsdaten beobachtet wurden, und den negativen Stichproben, die wahrscheinlich nicht beobachtet werden.
Objektpaare werden durch unabhängige, anpassbare Encoder übergeben, die mit den Eingabetypen von entsprechenden Objekten kompatibel sind. Die Encoder konvertieren jedes Objekt in einem Paar in einen eingebetteten Vektor mit gleicher Länge. Das Vektorpaar wird an einen Vergleichsoperator übergeben, der die Vektoren in einem einzigen Vektor mit dem Wert zusammensetzt, der im Hyperparameter comparator_list angegeben ist. Der zusammengesetzte Vektor wird dann über eine Multi-Layer Perceptron (MLP)-Ebene übergeben, die eine Ausgabe erzeugt, die die Vergleichsfunktion mit den Bezeichnungen vergleicht, die Sie angegeben haben. Bei diesem Vergleich wird die Stärke der Beziehung zwischen den Objekten im Paar wie vom Modell vorhergesagt bewertet. Die folgende Abbildung veranschaulicht diesen Workflow.
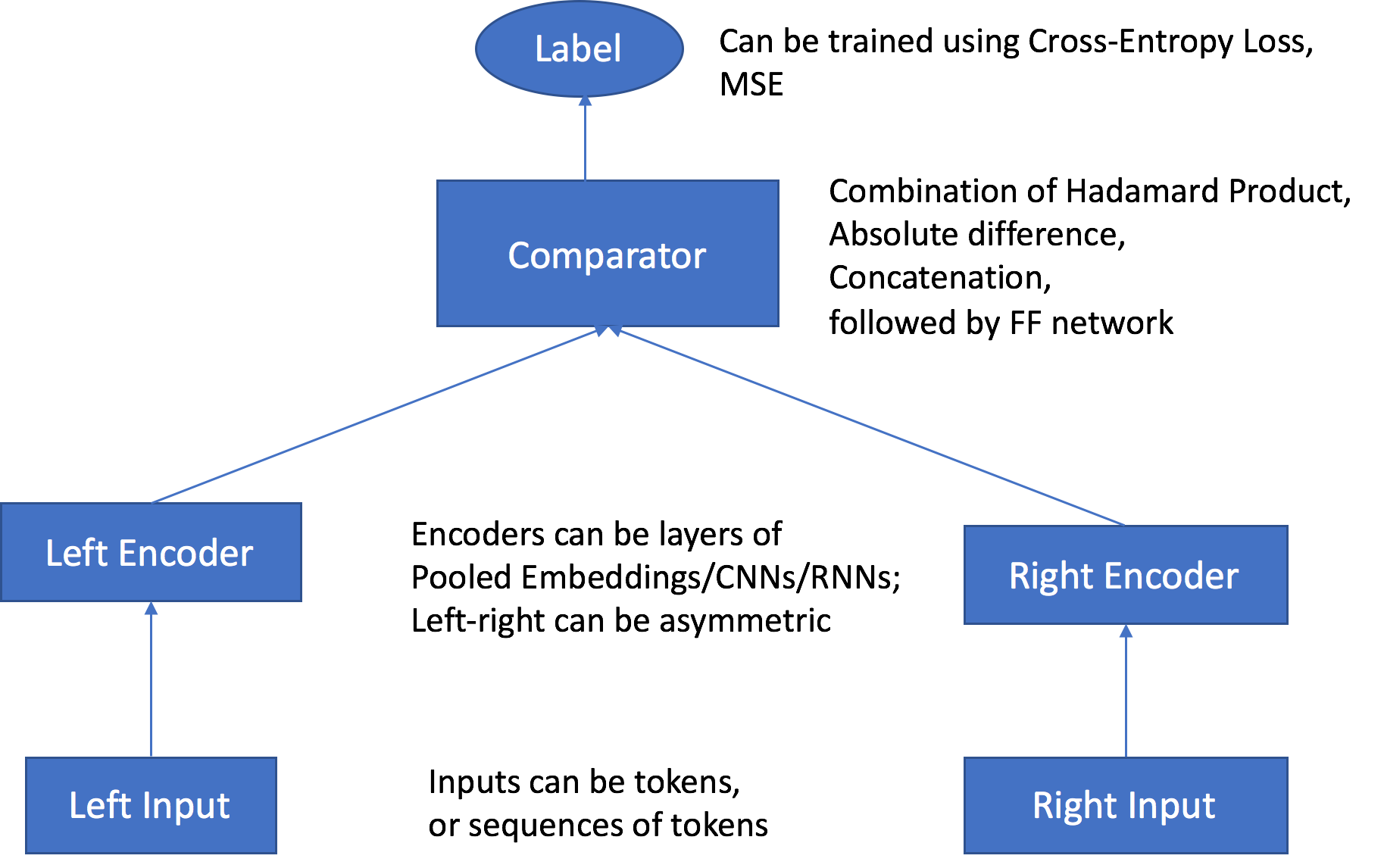
Architektur des Object2Vec-Algorithmus von Dateneingaben zu Ergebnissen
Schritt 3: Erstellen von Inferenzen
Nachdem das Modell trainiert wurde, können Sie den trainierten Encoder verwenden, um Eingabeobjekte vorzubereiten oder zwei Arten von Inferenzen auszuführen:
-
Zum Konvertieren von Singleton-Eingabeobjekten in Einbettungen mit fester Länge mithilfe des entsprechenden Encoders
-
Zum Voraussagen der Beziehungsbezeichnung oder der Bewertung zwischen einem Paar von Eingabeobjekten
Der Inferenzserver findet auf Grundlage der Eingabedaten automatisch heraus, welche der Arten angefordert wird. Zum Abrufen der Einbettungen als Ausgabe stellen Sie nur eine Eingabe zur Verfügung. Zum Voraussagen der Beziehungsbezeichnung oder der Bewertung stellen Sie beide Eingaben im Paar zur Verfügung.
