Get started with DynamoDB
Application logic is important, but an essential component is your data.
You are likely familiar with storing data in SQL and NoSQL databases in traditional solutions. Due to its rapid response and low latency, Amazon DynamoDB, a NoSQL data store released in 2012 is a frequently used data storage service for serverless solutions.
What is DynamoDB?
Amazon DynamoDB is a fully managed serverless NoSQL database service. DynamoDB stores data in tables. Tables hold items. Items are composed of attributes. Although these components sound similar to a traditional SQL table with rows and fields, there are also differences which will be explained in the fundamentals section.
Data access is generally predictable and fast, in the millisecond (ms) range. If you need even faster response time, the DynamoDB Accelerator (DAX) provides in-memory acceleration for microsecond level access to data.

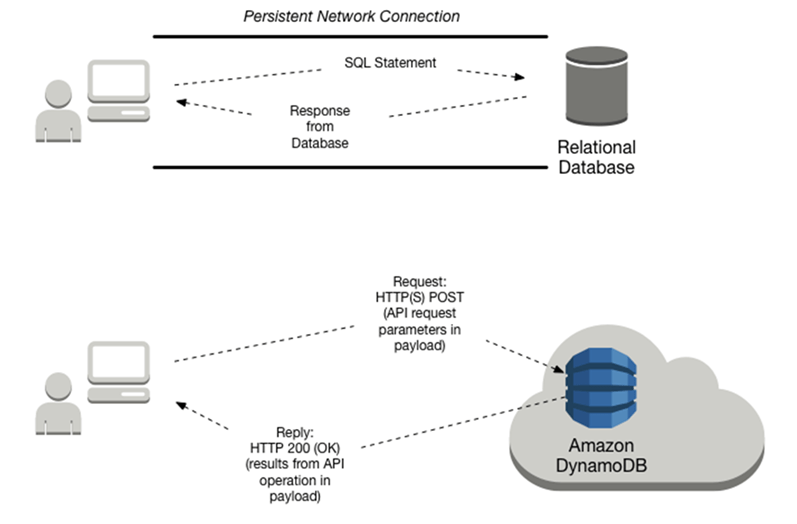
Traditional web frameworks maintain persistent network connections to SQL databases with connection pools to avoid latency accessing data. With serverless architecture and DynamoDB, connection pools are not necessary to rapidly connect and scale the database. Instead, you can adjust your tables' throughput capacity, as needed.
For rapid local development, modeling, and testing, AWS provides a downloadable version of DynamoDB that you can run on your computer. The local database instance provides the same API as the cloud-based service.
Fundamentals
In DynamoDB, tables, items, and attributes are the core components. Data items stored in tables are identified with a primary key, which can be a simple partition hash key or a composite of a partition key and a sort key. Although these terms may sound familiar, we will define all of them to clarify how similar and different they are from traditional SQL database terms.
Core Components
A table is a collection of items, and each item is a collection of attributes.
-
Table – a collection of data. For example, a table called People could store personal contact information about friends, family, or anyone else of interest. You could also have a Cars table to store information about vehicles that people drive.
Data in a DynamoDB is uniquely identified with a primary key, and optional secondary indexes for query flexibility. DynamoDB tables are schemaless. Other than the primary key, you do not need to define additional attributes when you create a table.
Each table contains zero or more items.
-
Item – An item is a group of attributes that is uniquely identifiable among all of the other items. In a People table, each item represents a person. For a Cars table, each item represents one vehicle.
Items in DynamoDB are similar to rows, records, or tuples in other database systems. In DynamoDB, there is no limit to the number of items you can store in a table. DynamoDB items have a size limit of 400KB. An item collection, a group of related items that share the same partition key value, are used to model one-to-many relationships. (1)
Each item is composed of one or more attributes:
-
Attribute –An attribute is a fundamental data element, something that does not need to be broken down any further. For example, an item in a People table contains attributes called PersonID, LastName, FirstName, and so on. In a Cars table, attributes could include Make, Model, BuildYear, and RetailPrice. For a Department table, an item might have attributes such as DepartmentID, Name, Manager, and so on. Attributes in DynamoDB are similar in many ways to fields or columns in other database systems.
Most of attributes are scalar, which means that they can have only one value. Strings and numbers are common examples of scalars. Attributes may be nested, up to 32 levels deep. An example could be an Address which contains Street, City, and PostalCode.
Watch an AWS Developer Advocate explain these core concepts in this video: Tables, items, and attributes (6 min)
As mentioned in the video, the primary key for the following table consists of both a partition key and sort key. The sort keys “inventory::armor” and “inventory::weapons” contain double colons to add query flexibility to get all inventory. This is not a DynamoDB requirements, just a convention by the developer to make retrieval more flexible.

All of the data for account1234 will be stored in the same database partition to ensure retrieval of related data is quick.
Related resources:
-
Item collections - how to model one-to-many relationships in DynamoDB - example of using an item collection, a group of related items that share the same partition key value, as a way to model one-to-many relationships
-
Characteristics of databases - comparison of SQL and NoSQL qualities of DynamoDB
Reading data
DynamoDB is a non-relational NoSQL database that does not support table joins. Instead, applications read data from one table at a time. There are four ways to read data:
-
GetItem– Retrieves a single item from a table. This is the most efficient way to read a single item because it provides direct access to the physical location of the item. (DynamoDB also provides theBatchGetItemoperation, allowing you to perform up to 100GetItemcalls in a single operation.) -
Query– Retrieves all of the items that have a specific partition key. Within those items, you can apply a condition to the sort key and retrieve only a subset of the data.Queryprovides quick, efficient access to the partitions where the data is stored. -
Scan– Retrieves all of the items in the specified table. This operation should not be used with large tables because it can consume large amounts of system resources. Think of it like a “SELECT * FROM BIG_TABLE” in SQL. You should generally prefer Query over Scan. -
ExecuteStatementretrieves a single or multiple items from a table.BatchExecuteStatementretrieves multiple items from different tables in a single operation. Both of these operations use PartiQL, a SQL-compatible query language.
Primary keys and indexes
-
Partition key - also called a hash key, identifies the partition where the data is stored in the database.
-
Sort key - also called a range key, represents 1:many relationships
The primary key can be a partition key, nothing more. Or, it can be a composite key which is a combination of a partition key and sort key. When querying, you must give the partition key, and optionally provide the sort key.
Amazon DynamoDB provides fast access to items in a table by specifying primary key values. However, many applications might benefit from having one or more secondary (or alternate) keys available, to allow efficient access to data with attributes other than the primary key. To address this, you can create one or more secondary indexes on a table and issue Query or Scan requests against these indexes.
A secondary index is a data structure that contains a subset of attributes from a table, along with an alternate key to support Query operations. You can retrieve data from the index using a Query, in much the same way as you use Query with a table. A table can have multiple secondary indexes, which give your applications access to many different query patterns.
DynamoDB supports two types of secondary indexes:
-
Global secondary index — An index with a partition key and a sort key that can be different from those on the base table. A global secondary index is considered "global" because queries on the index can span all of the data in the base table, across all partitions. A global secondary index is stored in its own partition space away from the base table and scales separately from the base table.
-
Local secondary index — An index that has the same partition key as the base table, but a different sort key. A local secondary index is "local" in the sense that every partition of a local secondary index is scoped to a base table partition that has the same partition key value.
In DynamoDB, you perform Query and Scan operations directly on the index, in the same way that you would on a table.
Data types
DynamoDB supports many different data types for attributes within a table. They can be categorized as follows:
-
Scalar Types – A scalar type can represent exactly one value. The scalar types are number, string, binary, Boolean, and null.
-
Document Types – A document type can represent a complex structure with nested attributes, such as you would find in a JSON document. The document types are list and map.
-
Set Types – A set type can represent multiple scalar values. The set types are string set, number set, and binary set.
Related resource:
Operations on tables
Operations are divided into Control plane, Data plane, Streams, and Transactions:
-
Control plane operations let you create and manage DynamoDB tables. They also let you work with indexes, streams, and other objects that are dependent on tables. Operations include CreateTable, DescribeTable, ListTables, UpdateTable, DeleteTable.
-
Data plane operations let you perform create, read, update, and delete (also called CRUD) actions on data in a table. Some of the data plane operations also let you read data from a secondary index. Operations include: ExecuteStatement, BatchExecuteStatement, PutItem, BatchWriteItem (to create or delete data), Get Item, BatchGetItem, Query, Scan, UpdateItem, DeleteItem
-
DynamoDB Streams operations let you enable or disable a stream on a table, and allow access to the data modification records contained in a stream. Operations include: ListStreams, DescribeStreams, GetSharedIterator, GetRecords
-
Transactions provide atomicity, consistency, isolation, and durability (ACID) enabling you to maintain data correctness in your applications more easily. Operations include: ExecuteTransaction, TransactWriteItems, TransactGetItems
Note: you can also use PartiQL - a SQL-compatible query language for Amazon DynamoDB, to perform data plane and transactional operations.
Advanced Topics
You can do a lot just creating a DynamoDB table with a primary key. As you progress on your journey, you should explore the following more advanced topics.
-
Create more complex data models in NoSQL WorkBench.
-
Use DynamoDB Streams to trigger functions when data is created, updated, or deleted.
-
Coordinate all-or-nothing changes with transactions.
-
Query and control the database using SQL-compatible PartiQL query language.
-
Reduce millisecond access times to microseconds with the in-memory DynamoDB Accelerator (DAX).
NoSQL Workbench & Local DynamoDB
NoSQL Workbench is a cross-platform visual application that provides data modeling, data visualization, and query development features to help you design, create, query, and manage DynamoDB tables.

-
Data modeling - build new data models, or design models based on existing data models.
-
Data visualization - map queries and visualize the access patterns (facets) of the application without writing code. Every facet corresponds to a different access pattern in DynamoDB. You can manually add data to your data model.
-
Operation builder - use the operation builder to develop and test queries, and query live datasets. You can also build and perform data plane operations, including creating projection and condition expressions, and generating sample code in multiple languages.
You can also run a local instance of DynamoDB on your workstation. Combined with NoSQL workbench, this can provide a fast local setup for experimentation and learning.
Related resources:
-
NoSQL Workbench & Building data models with NoSQL Workbench - model and query data with a desktop tool
DynamoDB Streams
DynamoDB Streams is an optional feature that captures data modification events. The data about these events appear in the stream in near-real time, and in the order that the events occurred, as a stream record.

If you enable a stream on a table, DynamoDB Streams writes a stream record whenever one of the following events occurs:
-
A new item is added to the table: the stream captures an image of the entire item, including all of its attributes.
-
An item is updated: the stream captures the "before" and "after" image of any attributes that were modified in the item.
-
An item is deleted from the table: the stream captures an image of the entire item before it was deleted.
Each stream record also contains the name of the table, the event timestamp, and other metadata. Stream records have a lifetime of 24 hours; after that, they are automatically removed from the stream.
You can use DynamoDB Streams together with AWS Lambda to create an event source mapping—a resource that invokes your Lambda function automatically whenever an event of interest appears in a stream
For example, consider a Customers table that contains customer information for a company. Suppose that you want to send a "welcome" email to each new customer. You could enable a stream on that table, and then associate the stream with a Lambda function. The Lambda function would run whenever a new stream record appears, but only process new items added to the Customers table. For any item that has an EmailAddress attribute, the Lambda function would invoke Amazon Simple Email Service (Amazon SES) to send an email to that address.
Related resources:
-
Change data capture with Amazon DynamoDB -- stream item-level change data in near-real time
-
Change data capture for DynamoDB Streams - DynamoDB Streams captures a time-ordered sequence of item-level modifications in any DynamoDB table and stores this information in a log for up to 24 hours.
Transactions
Amazon DynamoDB transactions simplify the developer experience of making coordinated, all-or-nothing changes to multiple items both within and across tables. Transactions provide atomicity, consistency, isolation, and durability (ACID) enabling you to maintain data correctness in your applications more easily.
You can use the DynamoDB transactional read and write APIs to manage complex business workflows that require adding, updating, or deleting multiple items as a single, all-or-nothing operation. With the transaction write API, you can group multiple Put, Update, Delete, and ConditionCheck actions. You can then submit the actions as a single TransactWriteItems operation that either succeeds or fails as a unit.
Related resource:
-
DynamoDB Transactions: How it works - Explains how to group actions together and submit as all-or-nothing TransactWriteItems or TransactGetItems operations
PartiQL Query Access
Amazon DynamoDB supports PartiQL
You can run ad hoc PartiQL queries against tables. PartiQL operations provide the same availability, latency, and performance as the other DynamoDB data plane operations.
Related resources:
-
PartiQL - a SQL-compatible query language for Amazon DynamoDB
-
PartiQL Tutorial
- learn how to write queries using the interactive shell, or REPL.
DynamoDB Accelerator (DAX) In-memory acceleration
In most cases, the DynamoDB response times can be measured in single-digit milliseconds. If your use case requires a response in microseconds, is read-heavy, or has bursty workloads, DAX provides fast response times for accessing eventually consistent data, increased throughput, and potential operational cost savings.
Related resource:
-
In-memory acceleration with DynamoDB Accelerator (DAX) - for response times in microseconds, increased throughput, and potential operational cost savings for large read-heavy or bursty workloads.
Additional resources
Official AWS documentation:
-
Amazon DynamoDB Developer Guide - extensive and complete documentation for Amazon DynamoDB
-
Getting started with DynamoDB - tutorial to create a table, write/read/update and query data. You will use the AWS CLI, with the option to run PartiQL DB queries.
-
Getting Started Resource Center - Choosing an AWS database service
- Choosing the right database requires you to make a series of decisions based on your organizational needs. This decision guide will help you ask the right questions, provide a clear path for implementation, and help you migrate from your existing database.
Resources from the serverless community:
-
Creating a single-table design with Amazon DynamoDB
- blog article by James Beswick (26 JUL 2021) showing how to model many to one and many to many relationships with indexes in DynamoDB. -
Additional Amazon DynamoDB Resources - more links to blog posts, guides, presentations, training, and tools
Next steps
In parallel to this guide, a group of Amazon engineers are building a series of workshops based on architectural and design patterns that customers commonly use in real-world solutions. You get hands-on experience with infrastructure and code that you could actually deploy as part of a production solution.
Learn serverless techniques in an online workshop
Learn by doing in the Serverless Patterns Workshop
Additional modules provide practical examples using infrastructure as code to deploy resources, test, and build with common architectural patterns used in serverless solutions.

