Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen eines benutzerdefinierten Vokabulars mithilfe einer Tabelle
Ein Tabellenformat ist die bevorzugte Methode zur Erstellung Ihres benutzerdefinierten Vokabulars. Vokabeltabellen müssen aus vier Spalten bestehen (Phrase, SoundsLike, IPA, and DisplayAs), die in beliebiger Reihenfolge aufgenommen werden können:
| Phrase | SoundsLike | IPA | DisplayAs |
|---|---|---|---|
|
Erforderlich Jede Zeile in Ihrer Tabelle muss einen Eintrag in dieser Spalte enthalten. Verwenden Sie keine Leerzeichen in dieser Spalte. Wenn Ihr Eintrag mehrere Wörter enthält, trennen Sie jedes Wort mit einem Bindestrich (-). Zum Beispiel Bei Akronymen müssen alle ausgesprochenen Buchstaben durch einen Punkt getrennt werden. Auch der abschließende Punkt muss ausgesprochen werden. Wenn Ihr Akronym im Plural steht, müssen Sie einen Bindestrich zwischen dem Akronym und dem „s“ verwenden. Zum Beispiel ist 'CLI' Wenn Ihr Satz aus einem Wort und einem Akronym besteht, müssen diese beiden Bestandteile durch einen Bindestrich getrennt werden. Zum Beispiel ist „DynamoDB“ In dieser Spalte dürfen keine Ziffern stehen; die Zahlen müssen ausgeschrieben werden. Zum Beispiel ist „VX02Q“ |
|
|
Optional. Zeilen in dieser Spalte können leer gelassen werden. Sie können in dieser Spalte Leerzeichen verwenden. Legt fest, wie Ihr Eintrag in Ihrer Transkriptionsausgabe aussehen soll. Zum Beispiel ist Wenn eine Zeile in dieser Spalte leer ist, Amazon Transcribe verwendet es den Inhalt der Sie können in dieser Spalte Ziffern ( |
Das sollten Sie bei der Erstellung Ihrer Tabelle beachten:
-
Ihre Tabelle muss alle vier Spaltenüberschriften enthalten (Phrase, SoundsLike, IPA, and DisplayAs). Die
PhraseSpalte muss in jeder Zeile einen Eintrag enthalten. Die Möglichkeit, Ausspracheeingaben überIPAundSoundsLikeeinzugeben, wird nicht mehr unterstützt, und Sie können die Spalte leer lassen. Alle Werte in diesen Spalten werden ignoriert. -
Jede Spalte muss mit TAB oder Komma (,) getrennt sein. Dies gilt für jede Zeile in Ihrer benutzerdefinierten Vokabulardatei. Wenn eine Zeile leere Spalten enthält, müssen Sie trotzdem ein Trennzeichen (TAB oder Komma) für jede Spalte angeben.
-
Leerzeichen sind nur innerhalb der Spalten
IPAundDisplayAserlaubt. Verwenden Sie keine Leerzeichen zur Trennung von Spalten. -
IPAundSoundsLikewerden für Custom Vocabulary nicht mehr unterstützt. Bitte lassen Sie die Spalte leer. Alle Werte in dieser Spalte werden ignoriert. Wir werden die Unterstützung für diese Spalte in future entfernen. -
Die Spalte
DisplayAsunterstützt Symbole und Sonderzeichen (z. B. C++). Alle anderen Spalten unterstützen die Zeichen, die auf der Seite mit dem Zeichensatz Ihrer Sprache aufgeführt sind. -
Wenn Sie in der Spalte
PhraseZahlen angeben möchten, müssen Sie diese buchstabieren. Ziffern (0-9) werden nur in der SpalteDisplayAsunterstützt. -
Sie müssen Ihre Tabelle als Klartextdatei (*.txt) im Format
LFspeichern. Wenn Sie ein anderes Format verwenden, z. B.CRLF, kann Ihr benutzerdefiniertes Vokabular nicht verarbeitet werden. -
Sie müssen Ihre benutzerdefinierte Vokabeldatei in einen Amazon S3 Bucket hochladen und sie mithilfe dieser Daten verarbeiten,
CreateVocabularybevor Sie sie in eine Transkriptionsanfrage aufnehmen können. Anweisungen finden Sie unter Erstellen von benutzerdefinierten Vokabulartabellen.
Anmerkung
Geben Sie Akronyme oder andere Wörter, deren Buchstaben einzeln ausgesprochen werden müssen, als einzelne, durch Punkte getrennte Buchstaben ein (A.B.C.). Um die Pluralform eines Akronyms wie 'ABCs' einzugeben, trennen Sie das 's' vom Akronym durch einen Bindestrich (). A.B.C.-s Sie können Groß- oder Kleinbuchstaben verwenden, um ein Akronym zu definieren. Akronyme werden nicht in allen Sprachen unterstützt; siehe Unterstützte Sprachen und sprachspezifische Funktionen.
Hier ist eine Beispieltabelle für ein benutzerdefiniertes Vokabular (wobei [TAB] ein Tabulatorzeichen darstellt):
Phrase[TAB]SoundsLike[TAB]IPA[TAB]DisplayAs
Los-Angeles[TAB][TAB][TAB]Los Angeles
Eva-Maria[TAB][TAB][TAB]
A.B.C.-s[TAB][TAB][TAB]ABCs
Amazon-dot-com[TAB][TAB][TAB]Amazon.com
C.L.I.[TAB][TAB][TAB]CLI
Andorra-la-Vella[TAB][TAB][TAB]Andorra la Vella
Dynamo-D.B.[TAB][TAB][TAB]DynamoDB
V.X.-zero-two[TAB][TAB][TAB]VX02
V.X.-zero-two-Q.[TAB][TAB][TAB]VX02QZur Verdeutlichung sehen Sie hier die gleiche Tabelle mit ausgerichteten Spalten. Fügen Sie in Ihrer benutzerdefinierten Vokabulartabellekeine Leerzeichen zwischen den Spalten ein; Ihre Tabelle sollte wie im vorangegangenen Beispiel schief aussehen.
Phrase [TAB]SoundsLike [TAB]IPA [TAB]DisplayAs
Los-Angeles [TAB] [TAB] [TAB]Los Angeles
Eva-Maria [TAB] [TAB] [TAB]
A.B.C.-s [TAB] [TAB] [TAB]ABCs
amazon-dot-com [TAB] [TAB] [TAB]amazon.com
C.L.I. [TAB] [TAB] [TAB]CLI
Andorra-la-Vella[TAB] [TAB] [TAB]Andorra la Vella
Dynamo-D.B. [TAB] [TAB] [TAB]DynamoDB
V.X.-zero-two [TAB] [TAB] [TAB]VX02
V.X.-zero-two-Q.[TAB] [TAB] [TAB]VX02QErstellen von benutzerdefinierten Vokabulartabellen
In den folgenden Beispielen erfahren Sie Amazon Transcribe, wie Sie eine benutzerdefinierte Vokabeltabelle für die Verwendung mit bearbeiten können:
-
Melden Sie sich an der AWS Management Console
an. -
Wählen Sie im Navigationsbereich die Option Benutzerdefiniertes Vokabular. Dies öffnet die Seite Benutzerdefiniertes Vokabular, auf der Sie vorhandene Vokabulare ansehen oder ein neues erstellen können.
-
Wählen Sie Vokabular erstellen.
Sie gelangen auf die Seite Vokabular erstellen. Geben Sie einen Namen für Ihr neues benutzerdefiniertes Vokabular ein.
Hier haben Sie drei Möglichkeiten:
-
Laden Sie eine txt- oder csv-Datei von Ihrem Computer hoch.
Sie können entweder Ihr benutzerdefiniertes Vokabular von Grund auf neu erstellen oder eine Vorlage herunterladen, die Ihnen den Einstieg erleichtert. Ihr Vokabular wird dann automatisch im Bereich Vokabular anzeigen und bearbeiten ausgefüllt.

-
Importiert eine TXT- oder CSV-Datei von einem beliebigen Ort. Amazon S3
Sie können entweder Ihr benutzerdefiniertes Vokabular von Grund auf neu erstellen oder eine Vorlage herunterladen, die Ihnen den Einstieg erleichtert. Laden Sie Ihre fertige Vokabulardatei in einen Amazon S3 -Bucket hoch und geben Sie dessen URI in Ihrer Anfrage an. Ihr Vokabular wird dann automatisch im Bereich Vokabular anzeigen und bearbeiten ausgefüllt.

-
Erstellen Sie Ihr Vokabular manuell in der Konsole.
Blättern Sie zum Bereich Ansicht und Vokabular bearbeiten und wählen Sie 10 Zeilen hinzufügen. Sie können nun Begriffe manuell eingeben.
-
-
Sie können Ihr Vokabular im Bereich Ansicht und Vokabularbearbeitung bearbeiten. Um Änderungen vorzunehmen, klicken Sie auf den Eintrag, den Sie ändern möchten.
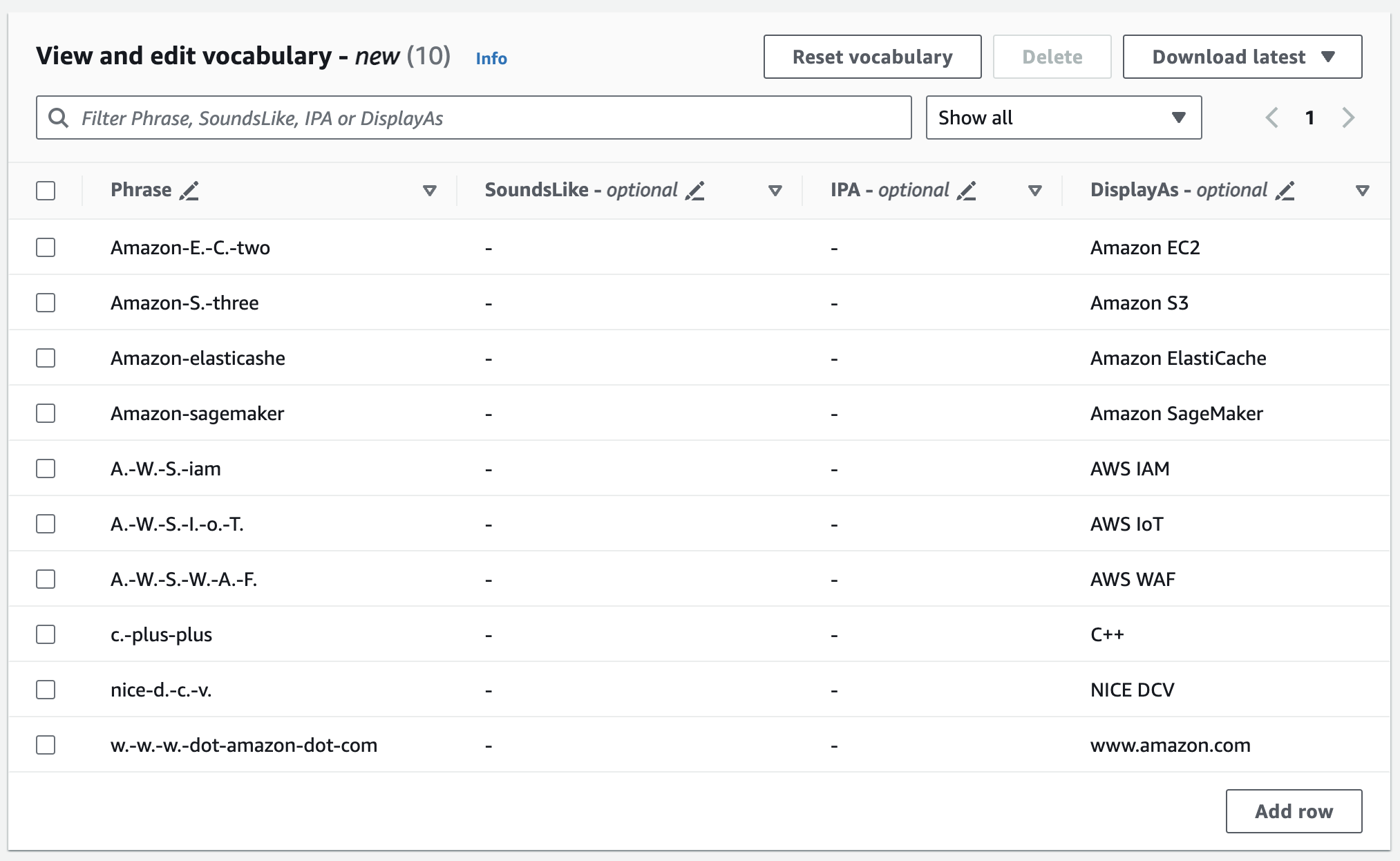
Wenn Ihnen ein Fehler unterläuft, erhalten Sie eine detaillierte Fehlermeldung, sodass Sie eventuelle Probleme vor der Bearbeitung Ihres Vokabulars beheben können. Beachten Sie, dass Ihre Vokabularanfrage fehlschlägt, wenn Sie nicht alle Fehler korrigieren, bevor Sie Vokabular erstellen auswählen.
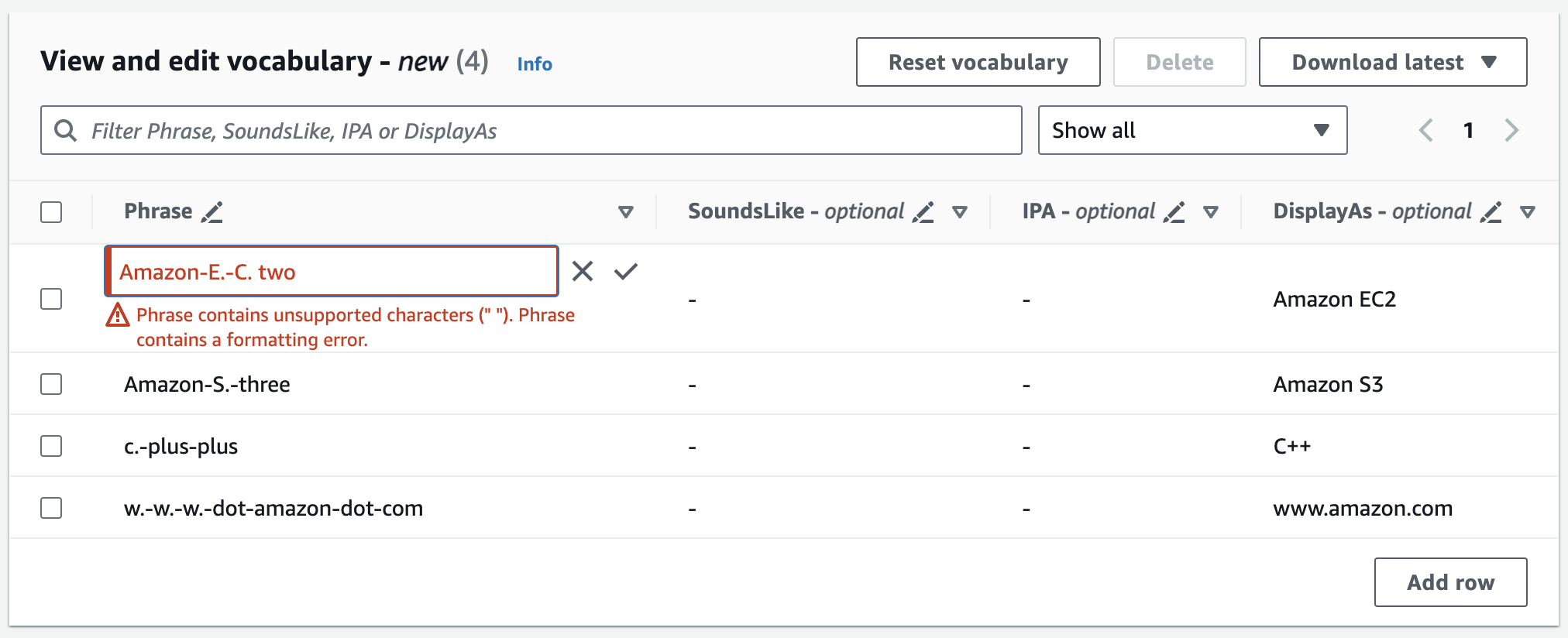
Wählen Sie das Häkchen (✓), um Ihre Änderungen zu speichern, oder das „X“, um Ihre Änderungen zu verwerfen.
-
Optional können Sie Ihrem benutzerdefinierten Vokabular Tags hinzufügen. Wenn Sie alle Felder ausgefüllt haben und mit Ihrem Vokabular zufrieden sind, wählen Sie unten auf der Seite Vokabular erstellen. Dies bringt Sie zurück zur Seite Benutzerdefiniertes Vokabular, wo Sie den Status Ihres benutzerdefinierten Vokabulars einsehen können. Wenn der Status von „Ausstehend“ auf „Bereit“ wechselt, kann Ihr benutzerdefiniertes Vokabular mit einer Transkription verwendet werden.

-
Wenn sich der Status in „Fehlgeschlagen“ ändert, wählen Sie den Namen Ihres benutzerdefinierten Vokabulars aus, um zu dessen Informationsseite zu gelangen.
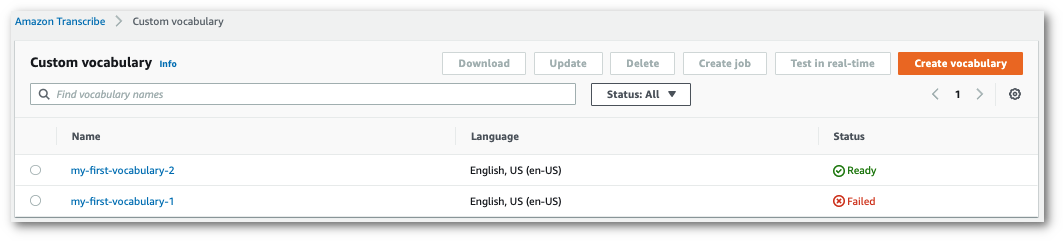
Oben auf dieser Seite befindet sich ein Banner mit dem Grund für das Scheitern, das Auskunft darüber gibt, warum Ihr benutzerdefiniertes Vokabular nicht funktioniert hat. Korrigieren Sie den Fehler in Ihrer Textdatei und versuchen Sie es erneut.

In diesem Beispiel wird der Befehl create-vocabulary mit einer tabellenformatierten Vokabulardatei verwendet. Weitere Informationen finden Sie unter CreateVocabulary.
Um ein vorhandenes benutzerdefiniertes Vokabular in einem Transkriptionsauftrag zu verwenden, geben Sie das VocabularyName in das SettingsFeld ein, wenn Sie den StartTranscriptionJobVorgang aufrufen, oder wählen Sie das AWS Management Console benutzerdefinierte Vokabular aus der Dropdownliste aus.
aws transcribe create-vocabulary \ --vocabulary-namemy-first-vocabulary\ --vocabulary-file-uri s3://amzn-s3-demo-bucket/my-vocabularies/my-vocabulary-file.txt \ --language-codeen-US
Hier ein weiteres Beispiel mit dem Befehl create-vocabulary und einem Anforderungstext, der Ihr benutzerdefiniertes Vokabular erstellt.
aws transcribe create-vocabulary \ --cli-input-json file://filepath/my-first-vocab-table.json
Die Datei my-first-vocab-table.json enthält den folgenden Anfragetext.
{ "VocabularyName": "my-first-vocabulary", "VocabularyFileUri": "s3://amzn-s3-demo-bucket/my-vocabularies/my-vocabulary-table.txt", "LanguageCode": "en-US" }
Sobald VocabularyState von PENDING auf READYwechselt, ist Ihr benutzerdefiniertes Vokabular bereit für die Verwendung mit einer Transkription. Um den aktuellen Status Ihres benutzerdefinierten Vokabulars anzuzeigen, führen Sie Folgendes aus:
aws transcribe get-vocabulary \ --vocabulary-namemy-first-vocabulary
In diesem Beispiel wird mithilfe der AWS SDK für Python (Boto3) Methode create_vocabularyCreateVocabulary.
Um ein vorhandenes benutzerdefiniertes Vokabular in einem Transkriptionsauftrag zu verwenden, legen Sie das VocabularyName in dem SettingsFeld fest, wenn Sie den StartTranscriptionJobVorgang aufrufen, oder wählen Sie das AWS Management Console benutzerdefinierte Vokabular aus der Dropdownliste aus.
Weitere Beispiele für die Verwendung von AWS SDKs, einschließlich funktionsspezifischer, szenarienspezifischer und dienstübergreifender Beispiele, finden Sie im Kapitel. Codebeispiele für Amazon Transcribe mit AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary" response = transcribe.create_vocabulary( LanguageCode = 'en-US', VocabularyName = vocab_name, VocabularyFileUri = 's3://amzn-s3-demo-bucket/my-vocabularies/my-vocabulary-table.txt' ) while True: status = transcribe.get_vocabulary(VocabularyName = vocab_name) if status['VocabularyState'] in ['READY', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Anmerkung
Wenn Sie einen neuen Amazon S3 Bucket für Ihre benutzerdefinierten Vokabeldateien erstellen, stellen Sie sicher, dass die IAM Rolle, die die CreateVocabularyAnfrage stellt, über Zugriffsberechtigungen für diesen Bucket verfügt. Wenn die Rolle nicht über die richtigen Berechtigungen verfügt, schlägt Ihre Anfrage fehl. Sie können optional eine IAM Rolle in Ihrer Anfrage angeben, indem Sie den DataAccessRoleArn Parameter angeben. Weitere Informationen zu IAM Rollen und Richtlinien finden Sie unterAmazon Transcribe Beispiele für identitätsbasierte Richtlinien. Amazon Transcribe
