Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Kontrollflugzeuggesteuerte Evakuierung
Das erste Muster verwendet Operationen auf der Datenebene, um die Ausführung von Arbeiten in einer betroffenen Availability Zone zu verhindern und die Auswirkungen eines Ereignisses zu mildern. Möglicherweise verwenden Sie jedoch eine Architektur, die keine Load Balancer verwendet, oder bei der die Konfiguration eines Zustandschecks pro Host nicht möglich ist. Oder Sie möchten möglicherweise verhindern, dass neue Kapazitäten in der betroffenen Availability Zone bereitgestellt werden, indem Sie Auto Scaling oder die normale Arbeitsplanung verwenden.
Um beide Situationen zu lösen, sind Aktionen auf der Steuerungsebene erforderlich, um die Konfiguration der Ressource zu aktualisieren. Das Muster funktioniert für jeden Service, dessen Netzwerkkonfiguration aktualisiert werden kann, z. B. EC2 Auto Scaling, Amazon ECS, Lambda und mehr. Es erfordert das Schreiben von Code für jeden Dienst, aber die Geschäftslogik folgt einem Standardmuster. Der Code sollte lokal von einem Operator ausgeführt werden, der auf das Ereignis reagiert, um die erforderlichen Abhängigkeiten zu minimieren. Der grundlegende Ablauf der Skriptlogik ist in der folgenden Abbildung dargestellt.
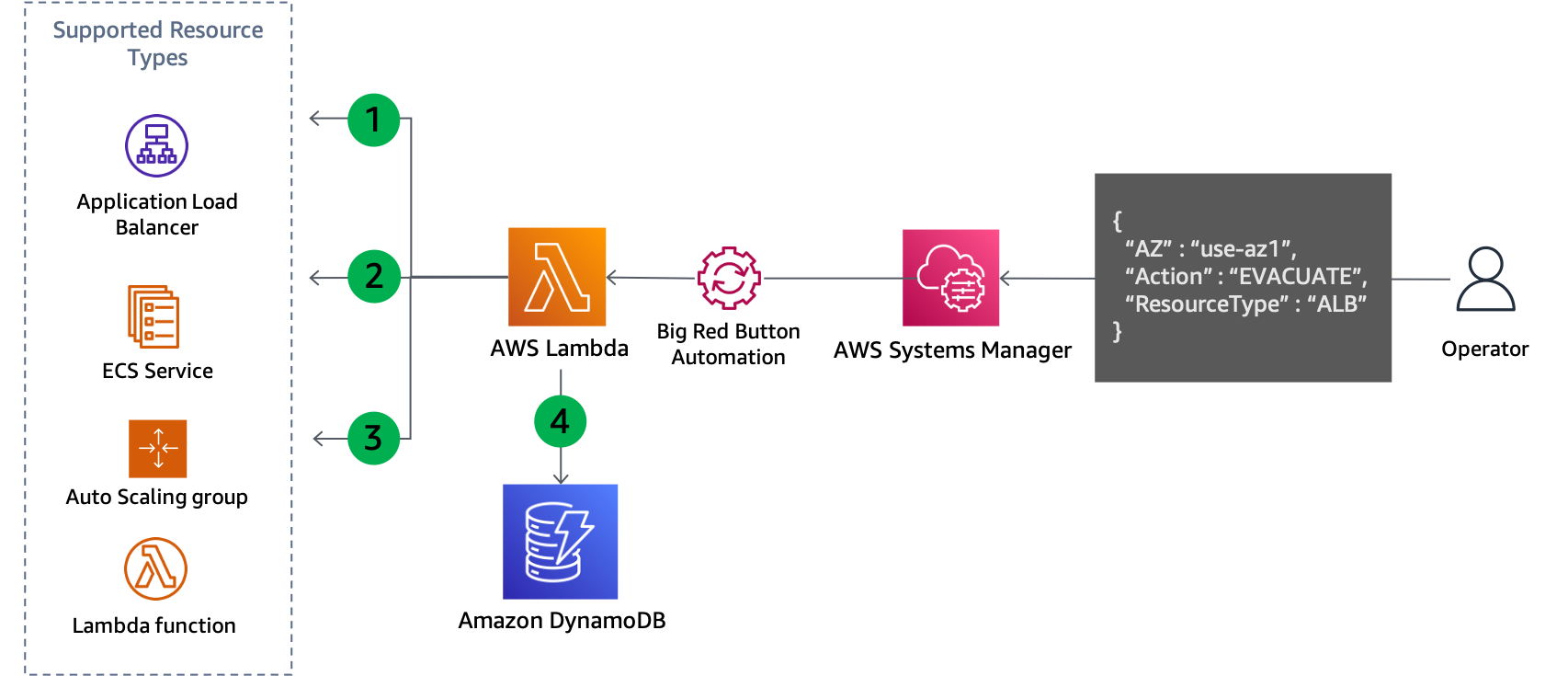
Aktualisierung der Kontrollebene zur Evakuierung einer Availability Zone
-
Das Skript listet alle Ressourcen des angegebenen Typs auf, z. B. Auto Scaling-Gruppe, ECS-Service oder Lambda-Funktion, und ruft ihre Subnetze aus den Ressourceninformationen ab. Die unterstützten Ressourcen hängen davon ab, wofür das Skript konfiguriert wurde, um es zu unterstützen.
-
Es bestimmt, welche Subnetze entfernt werden sollten, indem der Availability Zone-Name jedes Subnetzes mit der zugeordneten Availability Zone-ID verglichen wird, die als Eingabeparameter angegeben wurde.
-
Die Netzwerkkonfiguration der Ressource wird aktualisiert, um die identifizierten Subnetze zu entfernen.
-
Die Details des Updates werden in einer DynamoDB-Tabelle aufgezeichnet. Die Availability Zone-ID wird gespeichert alsPartitionsschlüsselund die Ressourcen-ARN oder der Name wird gespeichert alsSortierschlüssel. Die entfernten Subnetze werden als String-Array gespeichert. Schließlich wird der Ressourcentyp auch gespeichert und als Hash-Schlüssel für eineGlobaler Sekundärindex(GSI).
Da Schritt vier die vorgenommenen Aktualisierungen aufzeichnet, bietet sich dieser Ansatz auch an, um leicht rückgängig zu machen, wenn Sie zur Wiederherstellung bereit sind, wie in der folgenden Abbildung dargestellt.
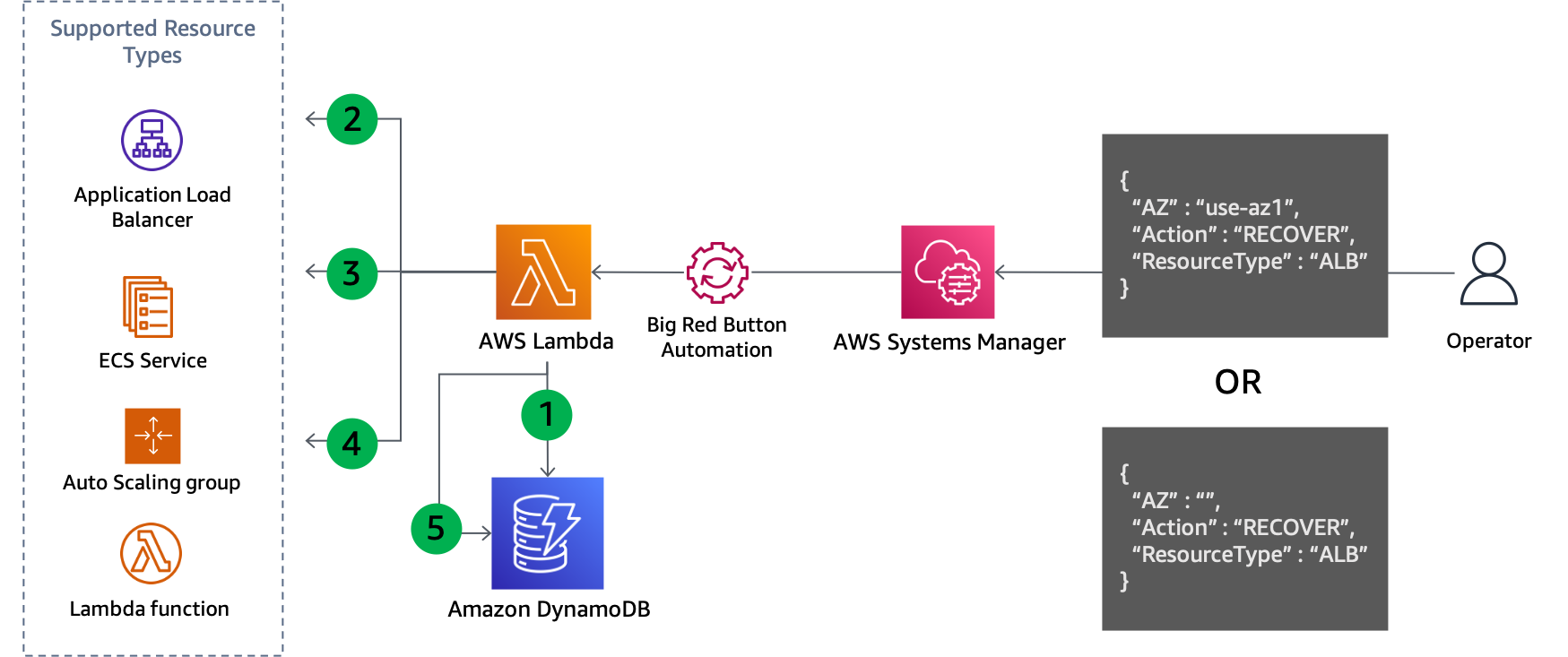
Aktualisierung der Steuerungsebene zur Wiederherstellung nach der Evakuierung der Availability Zone
Schritte zur Wiederherstellung:
-
Fragen Sie die GSI ab, um die Subnetze für jede Ressource des angegebenen Typs in der angegebenen Availability Zone (oder alle Availability Zones, falls keine angegeben ist) zu entfernen.
-
Beschreiben Sie jede Ressource, die in der DynamoDB-Abfrage gefunden wurde, um ihre aktuelle Netzwerkkonfiguration abzurufen.
-
Kombinieren Sie die Subnetze aus der aktuellen Netzwerkkonfiguration mit denen, die aus der DynamoDB-Abfrage abgerufen wurden.
-
Aktualisieren Sie die Netzwerkkonfiguration der Ressource mit dem neuen Subnetzsatz.
-
Entfernen Sie den Datensatz aus der DynamoDB-Tabelle, nachdem das Update erfolgreich abgeschlossen wurde.
Dieses generalisierte Muster verhindert sowohl die Weiterleitung von Arbeit an die betroffene Availability Zone als auch die Bereitstellung neuer Kapazitäten dort. Im Folgenden finden Sie Beispiele dafür, wie dies für verschiedene Dienste erreicht wird.
-
Lambda— Aktualisiere die FunktionenVPC-Konfigurationum die Subnetze in der angegebenen Availability Zone zu entfernen.
-
Auto Scaling-Gruppe—Entfernen Sie die Subnetze aus der ASG-Konfigurationwas diese Kapazität in den verbleibenden Availability Zones ersetzen wird.
-
Amazon ECS—Aktualisieren Sie die VPC-Konfiguration des ECS-Serviceum die Subnetze zu entfernen.
-
Amazon EKS— BewerbenVerderbungen
an Knoten in der betroffenen Availability Zone, um bestehende Pods zu entfernen und zu verhindern, dass dort weitere Pods geplant werden.
Jeder Dienst reagiert unterschiedlich auf das Konfigurationsupdate. Amazon ECS folgt beispielsweise demBereitstellungskonfiguration des Dienstes nach einem Updateund lösen eine fortlaufende Bereitstellung oder eine blaue/grüne Bereitstellung neuer Aufgaben aus.
Diese Updates können die Arbeit für einige Workloads zu schnell in die intakten Availability Zones verlagern. Sie sind zwar so konfiguriert, dass sie bei einem Ausfall statisch stabil sind (in den verbleibenden Availability Zones ist genügend Kapazität vorinstalliert, um die Arbeit der betroffenen Availability Zone zu bewältigen), Sie sollten aber auch die Kapazität der betroffenen Availability Zone schrittweise abbauen.
Wenn Sie planen, die Netzwerkkonfiguration Ihrer Auto Scaling-Gruppe zu aktualisieren, ist dies eine Zielgruppe für einen Load Balancer mit zonenübergreifendem Load BalancingBehinderte, folgen Sie dieser Anleitung.
Auto Scaling reagiert auf diese Änderung mit seinerLogik zur Neuverteilung der Availability Zone. Es werden Instances in den anderen Availability Zones gestartet, um Ihre gewünschte Kapazität zu erreichen, und Instances in der Availability Zone, die Sie entfernt haben, beendet. Der Load Balancer verteilt den Traffic jedoch weiterhin gleichmäßig auf jede Availability Zone, einschließlich der, die Sie aus der ASG entfernt haben, während die Instances beendet werden. Dies könnte dazu führen, dass die verbleibende Kapazität in dieser Availability Zone ausgeschöpft wird, bis alle Instances dort erfolgreich beendet sind. Dies ist das gleiche Problem, das in beschrieben wirdVerfügbarkeit, Zonenunabhängigkeitbezüglich des Ungleichgewichts in der Availability Zone, wenn der zonenübergreifende Lastenausgleich deaktiviert ist. Um dies zu verhindern, können Sie entweder:
-
Führen Sie immer zuerst die Evakuierung Ihrer Availability Zone durch, sodass der Traffic nur auf die verbleibenden Availability Zones aufgeteilt wird.
-
Spezifizieren Sie einminimale Anzahl intakter Ziele mit DNS-Failoverum Ihre erforderliche Mindestanzahl für diese Availability Zone zu erreichen.
Dadurch wird sichergestellt, dass kein Traffic an die Availability Zone gesendet wird, die Sie entfernt haben, nachdem die Instances beendet wurden.
