Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Datenplangesteuerte Evakuierung
Es gibt mehrere Lösungen, die Sie implementieren können, um eine Availability Zone-Evakuierung mithilfe von Aktionen nur auf der Datenebene durchzuführen. In diesem Abschnitt werden drei davon und die Anwendungsfälle beschrieben, in denen Sie möglicherweise einen dem anderen vorziehen sollten.
Wenn Sie eine dieser Lösungen verwenden, müssen Sie sicherstellen, dass Sie in den verbleibenden Availability Zones über ausreichend Kapazität verfügen, um die Last der Availability Zone zu bewältigen, von der Sie wegwechseln. Der stabilste Weg, dies zu erreichen, besteht darin, die erforderliche Kapazität in jeder Availability Zone vorab bereitzustellen. Wenn Sie drei Availability Zones verwenden, würden Sie in jeder Zone 50% der für die Bewältigung Ihrer Spitzenlast erforderlichen Kapazität bereitstellen, sodass Ihnen beim Verlust einer einzigen Availability Zone immer noch 100% Ihrer benötigten Kapazität zur Verfügung stehen, ohne sich auf eine Steuerungsebene verlassen zu müssen, um mehr bereitzustellen.
Wenn Sie EC2 Auto Scaling verwenden, stellen Sie außerdem sicher, dass Ihre Auto Scaling-Gruppe (ASG) während der Schicht nicht skaliert, sodass Sie am Ende der Schicht immer noch über genügend Kapazität in der Gruppe verfügen, um Ihren Kundenverkehr abzuwickeln. Sie können dies tun, indem Sie sicherstellen, dass die gewünschte Mindestkapazität Ihrer ASG Ihre aktuelle Kundenlast bewältigen kann. Sie können auch sicherstellen, dass Ihr ASG nicht versehentlich skaliert, indem Sie in Ihren Kennzahlen Durchschnittswerte verwenden und nicht Perzentilmetriken wie P90 oder P99 als Ausreißer verwenden.
Während einer Schicht sollten die Ressourcen, die den Verkehr nicht mehr bedienen, eine sehr geringe Auslastung aufweisen, aber die anderen Ressourcen werden ihre Auslastung mit dem neuen Verkehr erhöhen, sodass der Durchschnitt ziemlich konstant bleibt, wodurch eine Scale-In-Aktion verhindert würde. Schließlich können Sie die Gesundheitseinstellungen für Zielgruppen auch verwenden fürALBundNLBum DNS-Failover entweder mit einem Prozentsatz oder einer Anzahl intakter Hosts anzugeben. Dadurch wird verhindert, dass Datenverkehr an eine Availability Zone weitergeleitet wird, die nicht über genügend gesunde Hosts verfügt.
Zonale Verschiebung im Route 53 Application Recovery Controller (ARC)
Die erste Lösung für die Evakuierung von Availability ZonesZonenverschiebung auf der Route 53 ARC. Diese Lösung kann für Anforderungs-/Antwort-Workloads verwendet werden, die eine NLB oder ALB als Eingangspunkt für den Kundenverkehr verwenden.
Wenn Sie feststellen, dass eine Availability Zone beeinträchtigt ist, können Sie mit Route 53 ARC eine Zonenverschiebung einleiten. Sobald dieser Vorgang abgeschlossen ist und vorhandene zwischengespeicherte DNS-Antworten ablaufen, werden alle neuen Anfragen nur an Ressourcen in den verbleibenden Availability Zones weitergeleitet. Die folgende Abbildung zeigt, wie die zonale Verschiebung funktioniert. In der folgenden Abbildung haben wir einen Route 53-Aliasdatensatz fürwww.example.comdas deutet darauf hinmy-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com. Die Zonenverschiebung wird für Availability Zone 3 durchgeführt.
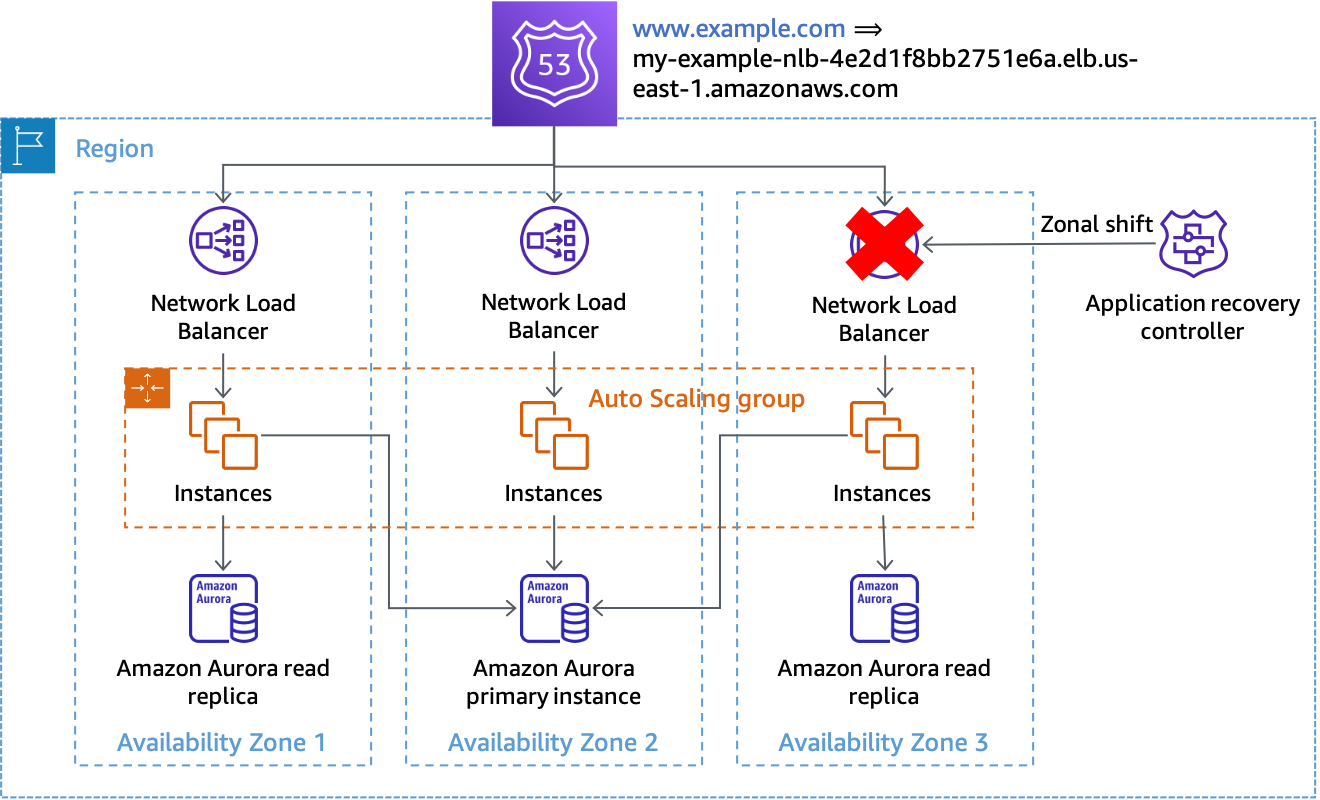
Zonale Verschiebung
Befindet sich im Beispiel die primäre Datenbankinstanz nicht in Availability Zone 3, ist die Durchführung der Zonenverschiebung die einzige Aktion, die erforderlich ist, um das erste Ergebnis der Evakuierung zu erzielen. Dadurch wird verhindert, dass Arbeit in der betroffenen Availability Zone verarbeitet wird. Befindet sich der primäre Knoten in Availability Zone 3, könnten Sie in Abstimmung mit der Zonenverschiebung einen manuell initiierten Failover durchführen (der auf der Amazon RDS-Steuerungsebene basiert), sofern Amazon RDS nicht bereits automatisch ein Failover durchgeführt hat. Dies gilt für alle datenplangesteuerten Lösungen in diesem Abschnitt.
Sie sollten die Zonenverschiebung mithilfe von CLI-Befehlen oder der API einleiten, um die Abhängigkeiten zu minimieren, die für den Start der Evakuierung erforderlich sind. Je einfacher der Evakuierungsprozess ist, desto zuverlässiger wird er sein. Die spezifischen Befehle können in einem lokalen Runbook gespeichert werden, auf das Techniker im Bereitschaftsdienst problemlos zugreifen können. Zonal Shift ist die bevorzugte und einfachste Lösung für die Evakuierung einer Availability Zone.
Route 53 ARC
Die zweite Lösung nutzt die Funktionen von Route 53 ARC, um den Zustand bestimmter DNS-Einträge manuell zu spezifizieren. Diese Lösung hat den Vorteil, dass sie die hochverfügbare Route 53 ARC-Cluster-Datenebene verwendet, wodurch sie widerstandsfähig gegenüber Beeinträchtigungen durch bis zu zwei verschiedeneAWS-Regionen. Es hat den Nachteil zusätzlicher Kosten und erfordert eine zusätzliche Konfiguration von DNS-Einträgen. Um dieses Muster zu implementieren, müssen Sie Aliasdatensätze für das erstellenAvailability Zonenspezifische DNS-Namenbereitgestellt vom Load Balancer (ALB oder NLB). Dies ist in der folgenden Tabelle dargestellt.
Tabelle 3: Route 53-Aliaseinträge, die für die zonalen DNS-Namen des Load Balancers konfiguriert sind
|
Routing-Richtlinie: gewichtet Name (Name: Typ: Value (Wert): Gewicht: Bewerten Sie die Gesundheit des Ziels: wahr |
Routing-Richtlinie:gewichtet Name (Name: Typ: Wert: Gewicht: Bewerten Sie den Zustand des Ziels: |
Routing-Richtlinie:gewichtet Name (Name: Typ: Wert: Gewicht: Bewerten Sie den Zustand des Ziels: |
Für jeden dieser DNS-Einträge würden Sie eine Route 53-Integritätsprüfung konfigurieren, die mit einem Route 53-ARC verknüpft ist.Routing-Steuerung. Wenn Sie eine Evakuierung der Availability Zone einleiten möchten, setzen Sie den Status der Routing-Kontrolle aufOff.AWSempfiehlt, dies mithilfe der CLI oder API zu tun, um die Abhängigkeiten zu minimieren, die erforderlich sind, um die Evakuierung der Availability Zone zu starten. Alsbeste Praxis, sollten Sie eine lokale Kopie der Route 53 ARC-Cluster-Endpunkte aufbewahren, damit Sie diese nicht aus der ARC-Steuerebene abrufen müssen, wenn Sie eine Evakuierung durchführen müssen.
Um die Kosten bei der Verwendung dieses Ansatzes zu minimieren, können Sie einen einzigen Route 53-ARC-Cluster erstellen und die Systemdiagnosen in einem einzigen Schritt durchführen.AWS-Kontoundteilen Sie die Gesundheitschecks mit anderenAWS-Kontenuse1-az1) statt des Namens der Availability Zone (zum Beispielus-east-1a) für Ihre Routing-Kontrollen. WeilAWSordnet die physische Availability Zone nach dem Zufallsprinzip den Availability Zone-Namen für jede Zone zuAWS-Konto, die Verwendung der AZ-ID bietet eine konsistente Möglichkeit, auf dieselben physischen Standorte zu verweisen. Wenn Sie eine Evakuierung der Availability Zone einleiten, sagen wir füruse1-az2, die Route 53-Datensätze in jedemAWS-Kontosollten sicherstellen, dass sie das AZ-ID-Mapping verwenden, um den richtigen Gesundheitscheck für jeden NLB-Datensatz zu konfigurieren.
Nehmen wir zum Beispiel an, wir haben eine Route 53-Zustandsprüfung, die mit einer Route 53 ARC-Routingsteuerung verknüpft ist füruse1-az2, mit einer ID von0385ed2d-d65c-4f63-a19b-2412a31ef431. Wenn in einem anderenAWS-Kontoder diesen Gesundheitscheck nutzen will,us-east-1cwurde zugeordnetuse1-az2, du müsstest denuse1-az2Gesundheitscheck für das Protokollus-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com. Sie würden die Gesundheitscheck-ID verwenden0385ed2d-d65c-4f63-a19b-2412a31ef431mit diesem Ressourcendatensatz.
Verwendung eines selbstverwalteten HTTP-Endpunkts
Sie können diese Lösung auch implementieren, indem Sie Ihren eigenen HTTP-Endpunkt verwalten, der den Status einer bestimmten Availability Zone angibt. Damit können Sie anhand der Antwort des HTTP-Endpunkts manuell angeben, wann eine Availability Zone fehlerhaft ist. Diese Lösung kostet weniger als die Verwendung von Route 53 ARC, ist aber teurer als Zonal Shift und erfordert die Verwaltung zusätzlicher Infrastruktur. Es hat den Vorteil, dass es für verschiedene Szenarien viel flexibler ist.
Das Muster kann mit NLB- oder ALB-Architekturen und Route 53-Gesundheitschecks verwendet werden. Es kann auch in Architekturen ohne Lastausgleich eingesetzt werden, wie etwa in Systemen zur Serviceerkennung oder zur Verarbeitung von Warteschlangen, in denen Worker-Knoten ihre eigenen Integritätsprüfungen durchführen. In diesen Szenarien können die Hosts einen Hintergrund-Thread verwenden, in dem sie regelmäßig mit ihrer AZ-ID eine Anfrage an den HTTP-Endpunkt stellen (sieheAnhang A — Abrufen der Availability Zone-ID um zu erfahren, wie Sie das finden) und erhalten Sie eine Antwort über den Zustand der Availability Zone.
Wenn die Availability Zone für fehlerhaft erklärt wurde, haben sie mehrere Optionen, wie sie reagieren können. Sie können sich dafür entscheiden, eine externe Integritätsprüfung aus Quellen wie ELB, Route 53 oder benutzerdefinierte Integritätsprüfungen in Service Discovery-Architekturen nicht zu bestehen, sodass sie für diese Dienste als fehlerhaft erscheinen. Sie können auch sofort mit einem Fehler antworten, falls sie eine Anfrage erhalten, sodass der Client einen Rückzieher machen und es erneut versuchen kann. In ereignisgesteuerten Architekturen können Knoten absichtlich daran scheitern, Arbeit zu verarbeiten, z. B. indem sie absichtlich eine SQS-Nachricht an die Warteschlange zurücksenden. In Router-Architekturen, in denen zentrale Dienstpläne auf bestimmten Hosts funktionieren, können Sie dieses Muster ebenfalls verwenden. Der Router kann den Status einer Availability Zone überprüfen, bevor er einen Worker, einen Endpunkt oder eine Zelle auswählt. In Service Discovery-Architekturen, die Folgendes verwendenAWS Cloud Map, du kannstEntdecken Sie Endpunkte, indem Sie in Ihrer Anfrage einen Filter angeben
Die folgende Abbildung zeigt, wie dieser Ansatz für mehrere Arten von Workloads verwendet werden kann.
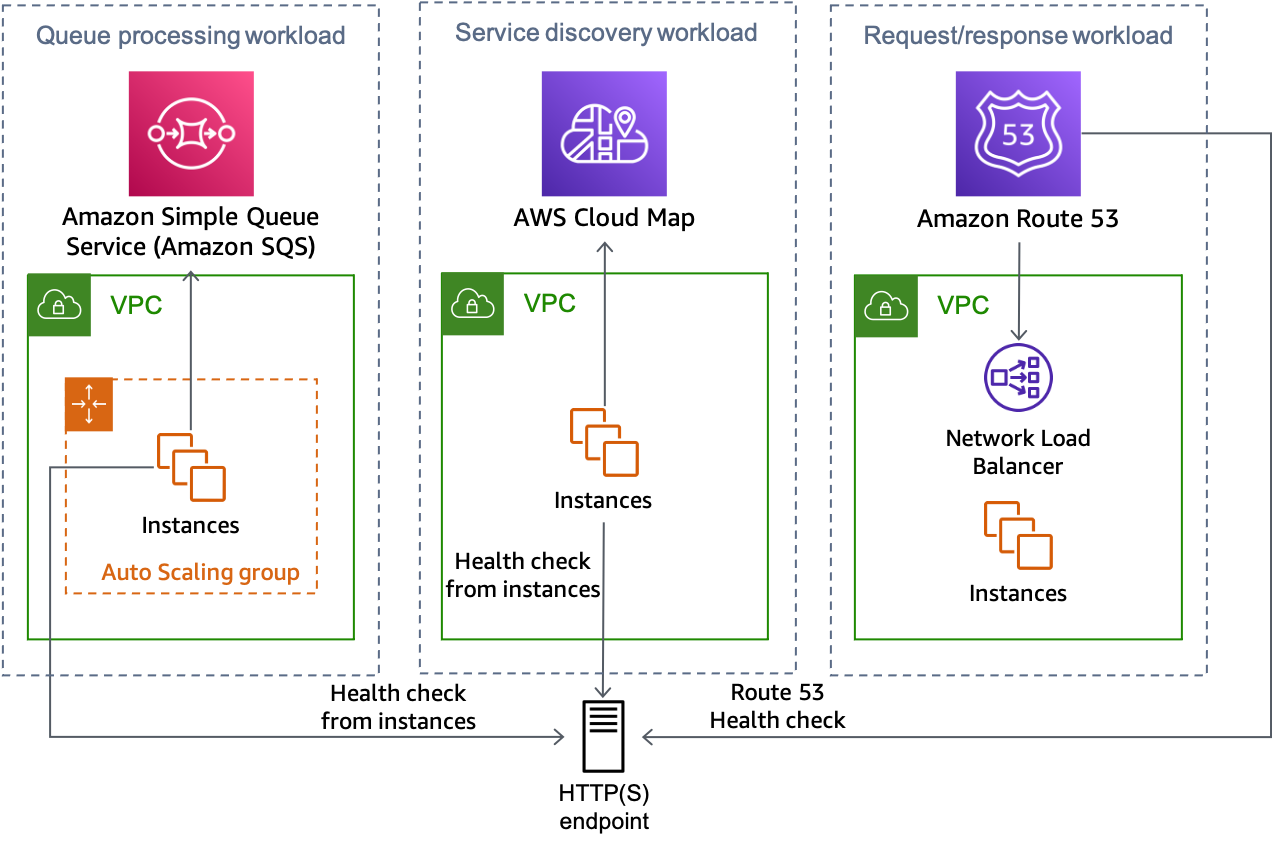
Die HTTP-Endpunktlösung kann von mehreren Workload-Typen verwendet werden
Es gibt mehrere Möglichkeiten, den HTTP-Endpunktansatz zu implementieren. Zwei davon werden im Folgenden beschrieben.
Verwenden von Amazon S3
Dieses Muster wurde ursprünglich in diesem vorgestelltBlogbeitrag
In diesem Szenario würden Sie Route 53-DNS-Ressourceneintragssätze für jeden zonalen DNS-Eintrag erstellen, genau wie derRoute 53 ARCdas obige Szenario sowie die zugehörigen Gesundheitschecks. Für diese Implementierung werden die Integritätsprüfungen jedoch nicht mit Route 53 ARC-Routing-Steuerelementen verknüpft, sondern so konfiguriert, dass sie eineHTTP-Endpunktund sind invertiert, um zu verhindern, dass eine Beeinträchtigung in Amazon S3 versehentlich eine Evakuierung auslöst. Der Gesundheitscheck wird berücksichtigtgesundwenn das Objekt abwesend ist undungesundwenn das Objekt vorhanden ist. Dieses Setup ist in der folgenden Tabelle dargestellt.
Tabelle 4: Konfiguration des DNS-Eintrags für die Verwendung von Route 53-Zustandsprüfungen pro Availability Zone
|
Typ des Gesundheitschecks: einen Endpunkt überwachen Protocol (Protokoll): ID: URL: |
Typ des Gesundheitschecks: einen Endpunkt überwachen Protocol (Protokoll): ID: URL: |
Typ des Gesundheitschecks: einen Endpunkt überwachen Protocol (Protokoll): ID: URL: |
← | Gesundheitschecks |
| ↑ | ↑ | ↑ | ||
|
Routing-Richtlinie: gewichtet Name (Name: Typ: Value (Wert): Gewicht: Bewerten Sie die Gesundheit des Ziels: |
Routing-Richtlinie:gewichtet Name (Name: Typ: Value (Wert): Gewicht: Bewerten Sie den Zustand des Ziels: |
Routing-Richtlinie:gewichtet Name (Name: Typ: Value (Wert): Gewicht: Bewerten Sie den Zustand des Ziels: |
← | Gleichmäßig gewichtete Alias-A-Datensätze auf oberster Ebene verweisen auf NLB AZ-spezifische Endpunkte |
Nehmen wir an, dass die Availability Zoneus-east-1aist zugeordnetuse1-az3in dem Konto, in dem wir einen Workload haben, für den wir eine Evakuierung der Availability Zone durchführen möchten. Für den Ressourcendatensatz, der erstellt wurde fürus-east-1a.load-balancer-name.elb.us-east-1.amazonaws.comwürde einen Gesundheitscheck verknüpfen, der die URL testethttps://. Wenn Sie eine Evakuierung der Availability Zone für einleiten möchtenbucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3, lade eine Datei mit dem Namen hochuse1-az3.txtmit der CLI oder API zum Bucket. Die Datei muss keinen Inhalt enthalten, aber sie muss öffentlich sein, damit der Route 53-Gesundheitscheck darauf zugreifen kann. Die folgende Abbildung zeigt, dass diese Implementierung zur Evakuierung verwendet wird.use1-az3.
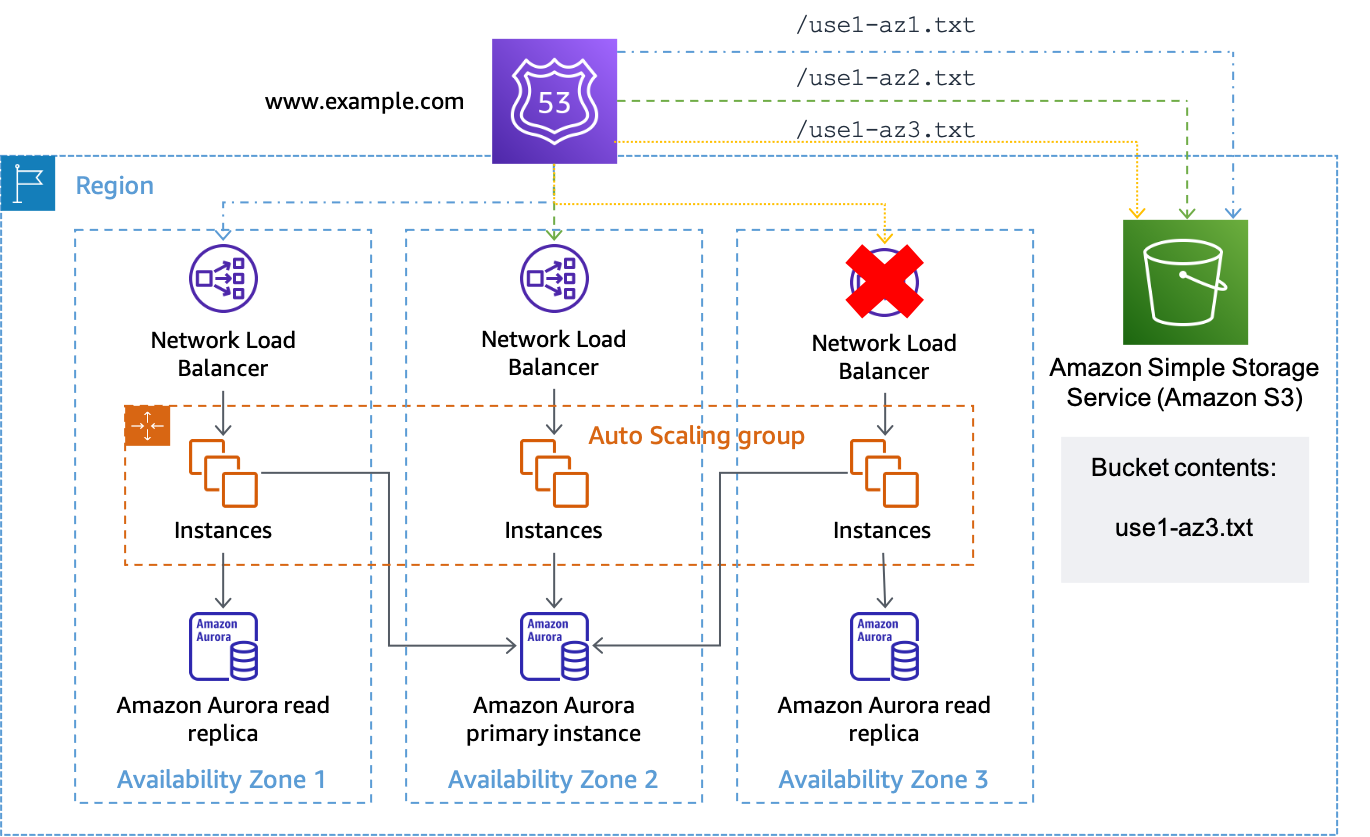
Amazon S3 als Ziel für einen Route 53-Gesundheitscheck verwenden
Verwendung von API Gateway und DynamoDB
Die zweite Implementierung dieses Musters verwendet eineAmazon-API-Gateway
Wenn Sie diese Lösung mit einer NLB- oder ALB-Architektur verwenden, richten Sie Ihre DNS-Einträge auf die gleiche Weise wie im obigen Amazon S3-Beispiel ein, außer dass Sie den Pfad zur Integritätsprüfung ändern, um den API Gateway-Endpunkt zu verwenden, und geben Sie dieAZ-IDim URL-Pfad. Wenn das API-Gateway beispielsweise mit einer benutzerdefinierten Domäne von konfiguriert istaz-status.example.com, die vollständige Anfrage füruse1-az1würde aussehen wiehttps://az-status.example.com/status/use1-az1. Wenn Sie eine Evakuierung der Availability Zone einleiten möchten, können Sie ein DynamoDB-Element mithilfe der CLI oder API erstellen oder aktualisieren. Der Artikel verwendet dieAZ-IDals Primärschlüssel und hat dann ein boolesches Attribut namensHealthywelche verwendet werden, geben an, wie API Gateway reagiert. Im Folgenden finden Sie einen Beispielcode, der in der API-Gateway-Konfiguration verwendet wird, um diese Entscheidung zu treffen.
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
Wenn das Attribut isttrue(oder nicht vorhanden), API Gateway reagiert auf die Integritätsprüfung mit einem HTTP 200. Wenn dieser Wert falsch ist, antwortet es mit HTTP 500. Diese Implementierung ist in der folgenden Abbildung dargestellt.
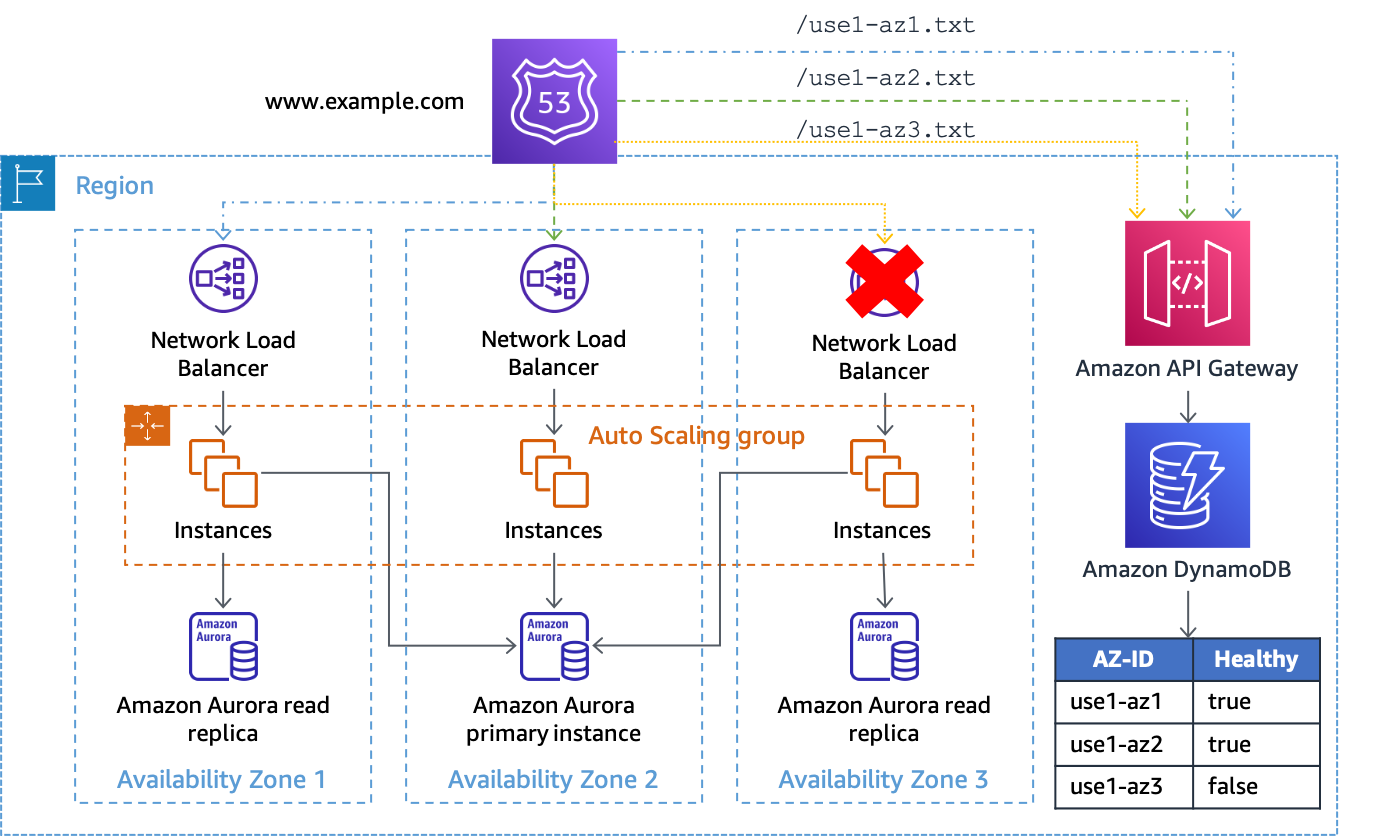
Verwendung von API Gateway und DynamoDB als Ziel von Route 53-Gesundheitschecks
In dieser Lösung müssen Sie API Gateway vor DynamoDB verwenden, damit Sie den Endpunkt öffentlich zugänglich machen und die Anforderungs-URL in eineGetItemAnfrage für DynamoDB. Die Lösung bietet auch Flexibilität, wenn Sie zusätzliche Daten in die Anfrage aufnehmen möchten. Wenn Sie beispielsweise detailliertere Statusangaben erstellen möchten, z. B. pro Anwendung, können Sie die Integritätsprüfungs-URL so konfigurieren, dass sie eine Anwendungs-ID im Pfad oder in der Abfragezeichenfolge bereitstellt, die auch mit dem DynamoDB-Element abgeglichen wird.
Der Status-Endpunkt der Availability Zone kann zentral bereitgestellt werden, sodass mehrere Ressourcen für die Integritätsprüfung überAWS-Kontenkönnen alle dieselbe konsistente Ansicht des Zustands der Availability Zone verwenden (wobei sichergestellt wird, dass Ihre API-Gateway-REST-API und Ihre DynamoDB-Tabelle so skaliert sind, dass sie die Last bewältigen) und macht die gemeinsame Nutzung von Route 53-Zustandsprüfungen überflüssig.
Die Lösung könnte auch auf mehrere skaliert werdenAWS-Regionenunter Verwendung einesGlobale Amazon DynamoDB-Tabelle
Wenn Sie eine Lösung entwickeln würden, die einzelne Hosts als Mechanismus zur Bestimmung des Zustands ihrer AZ verwenden können, können Sie als Alternative Push-Benachrichtigungen verwenden, anstatt einen Pull-Mechanismus für Zustandsprüfungen bereitzustellen. Eine Möglichkeit, dies zu tun, ist ein SNS-Thema, das Ihre Verbraucher abonnieren. Wenn Sie den Schutzschalter auslösen möchten, veröffentlichen Sie im SNS-Thema eine Meldung, in der angegeben wird, welche Availability Zone beeinträchtigt ist. Dieser Ansatz geht Kompromisse mit ersteren ein. Dadurch entfällt die Notwendigkeit, die API-Gateway-Infrastruktur zu erstellen und zu betreiben und ein Kapazitätsmanagement durchzuführen. Es kann möglicherweise auch zu einer schnelleren Konvergenz des Availability Zone-Status führen. Es verhindert jedoch die Möglichkeit, Ad-hoc-Abfragen durchzuführen, und stützt sich auf dieRichtlinie zur Wiederholung der SNS-Zustellungum sicherzustellen, dass jeder Endpunkt die Benachrichtigung erhält. Außerdem muss jeder Workload oder Dienst eine Möglichkeit finden, die SNS-Benachrichtigung zu empfangen und entsprechende Maßnahmen zu ergreifen.
Beispielsweise muss jede neue EC2-Instance oder jeder neue Container, der gestartet wird, das Thema mit einem HTTP-Endpunkt während des Bootstraps abonnieren. Anschließend muss jede Instanz eine Software implementieren, die auf diesem Endpunkt abhört, an dem die Benachrichtigung zugestellt wird. Wenn die Instance von dem Ereignis betroffen ist, erhält sie außerdem möglicherweise keine Push-Benachrichtigung und arbeitet weiter. Bei einer Pull-Benachrichtigung weiß die Instance dagegen, ob ihre Pull-Anfrage fehlschlägt, und kann wählen, welche Maßnahmen als Reaktion ergriffen werden sollen.
Eine zweite Möglichkeit, Push-Benachrichtigungen zu senden, ist LongliveWebSocketVerbindungen. Amazon API Gateway kann verwendet werden, um eine bereitzustellenWebSocketAPIdass Verbraucher eine Verbindung herstellen und eine Nachricht empfangen können, wennvom Backend gesendet. Mit einemWebSocket, können Instances sowohl regelmäßige Pulls durchführen, um sicherzustellen, dass ihre Verbindung einwandfrei ist, als auch Push-Benachrichtigungen mit niedriger Latenz erhalten.
