Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verfügbarkeit mit Redundanz
Wenn ein Workload mehrere, unabhängige und redundante Subsysteme nutzt, kann ein höheres Maß an theoretischer Verfügbarkeit erreicht werden, als wenn ein einzelnes Subsystem verwendet würde. Stellen Sie sich zum Beispiel eine Arbeitslast vor, die aus zwei identischen Subsystemen besteht. Es kann vollständig betriebsbereit sein, wenn entweder das erste Teilsystem oder das zweite Teilsystem betriebsbereit ist. Damit das gesamte System ausgefallen ist, müssen beide Teilsysteme gleichzeitig ausgefallen sein.
Wenn die Ausfallwahrscheinlichkeit eines Teilsystems 1 − α ist, dann ist die Wahrscheinlichkeit, dass zwei redundante Teilsysteme gleichzeitig ausfallen, das Produkt der Ausfallwahrscheinlichkeit jedes Teilsystems, F = (1− α1) × (1− α). 2 Für eine Arbeitslast mit zwei redundanten Subsystemen ergibt sich unter Verwendung von Gleichung (3) eine Verfügbarkeit, die wie folgt definiert ist:
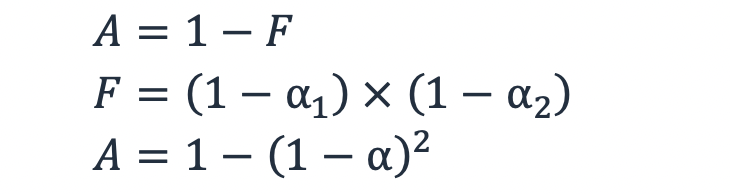
Gleichung 5
Für zwei Subsysteme mit einer Verfügbarkeit von 99% beträgt die Wahrscheinlichkeit, dass eines ausfällt, also 1% und die Wahrscheinlichkeit, dass beide ausfallen, beträgt (1− 99%) × (1− 99%) = 0,01%. Das macht die Verfügbarkeit bei Verwendung von zwei redundanten Subsystemen zu 99,99%.
Dies kann generalisiert werden, um auch zusätzliche redundante Ersatzteile einzubeziehen. In Gleichung (5) wurde nur von einem einzigen Ersatzgerät ausgegangen, aber ein Workload kann aus zwei, drei oder mehr Ersatzteilen bestehen, sodass er den gleichzeitigen Verlust mehrerer Subsysteme überstehen kann, ohne die Verfügbarkeit zu beeinträchtigen. Wenn eine Arbeitslast aus drei Subsystemen besteht und zwei Ersatzsysteme sind, beträgt die Wahrscheinlichkeit, dass alle drei Subsysteme gleichzeitig ausfallen, (1− α) × (1− α) × (1− α) oder (1− α) 3. Im Allgemeinen schlägt ein Workload mit S-Ersatzteilen nur fehl, wenn s + 1-Subsysteme ausfallen.
Bei einer Arbeitslast mit n Subsystemen und s Spares ist f die Anzahl der Ausfallursachen oder die Art und Weise, wie s + 1-Subsysteme von n ausfallen können.
Das ist quasi der Binomialsatz, die kombinatorische Mathematik, bei der k Elemente aus einer Menge von n ausgewählt werden, oder „n wähle k“. In diesem Fall ist k s + 1.
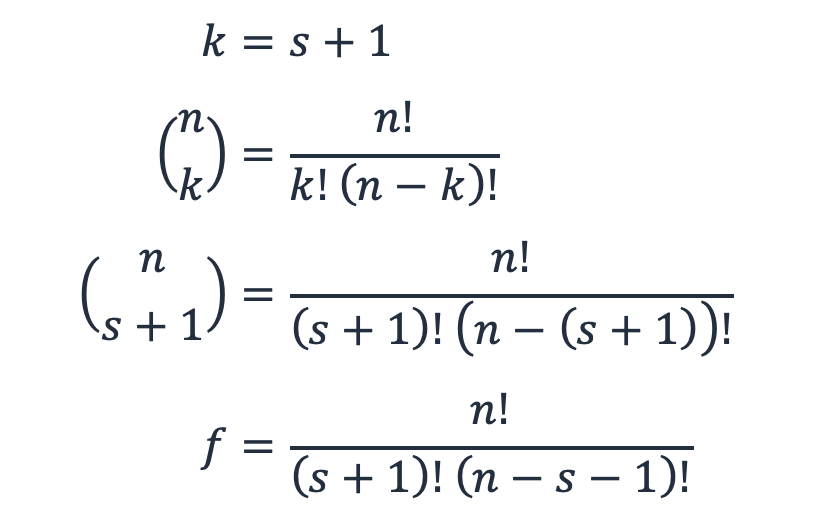
Gleichung 6
Wir können dann eine allgemeine Näherung der Verfügbarkeit erstellen, die die Anzahl der Ausfallursachen und die Einsparung berücksichtigt. (Um zu verstehen, warum das ungefähr so ist, siehe Anhang 2 von Highleyman et al. Die Verfügbarkeitsbarriere durchbrechen

Gleichung 7
Sparing kann auf jede Abhängigkeit angewendet werden, die Ressourcen bereitstellt, die unabhängig voneinander ausfallen. Beispiele hierfür AWS-Regionen sind Amazon EC2 EC2-Instances in verschiedenen AZs oder Amazon S3 S3-Buckets in verschiedenen. Die Verwendung von Ersatzteilen trägt dazu bei, dass diese Abhängigkeit eine höhere Gesamtverfügbarkeit erreicht, um die Verfügbarkeitsziele des Workloads zu erreichen.
Regel 5
Verwenden Sie Sparing, um die Verfügbarkeit von Abhängigkeiten in einem Workload zu erhöhen.
Sparing ist jedoch mit Kosten verbunden. Jedes weitere Ersatzteil kostet genauso viel wie das Originalmodul, was die Kosten zumindest linear ansteigen lässt. Der Aufbau einer Workload, die Ersatzteile verwenden kann, erhöht auch deren Komplexität. Es muss wissen, wie man Fehler in Abhängigkeit erkennt, die Arbeit davon abwälzt und auf eine gesunde Ressource umverteilt und die Gesamtkapazität der Arbeitslast verwaltet.
Redundanz ist ein Optimierungsproblem. Zu wenige Ersatzteile, und der Workload kann häufiger ausfallen als gewünscht, zu viele Ersatzteile und der Betrieb des Workloads kostet zu viel. Es gibt einen bestimmten Schwellenwert, ab dem das Hinzufügen weiterer Ersatzteile mehr kostet als die zusätzliche Verfügbarkeit, die sie erreichen.
Unter Verwendung unserer Formel für allgemeine Verfügbarkeit mit Ersatzteilen, Gleichung (7), für ein Subsystem mit einer Verfügbarkeit von 99,5% beträgt die Verfügbarkeit der Arbeitslast bei zwei Ersatzteilen A ≈ 1 − (1) (1−.995) 3 = 99,9999875% (ca. 3,94 Sekunden Ausfallzeit pro Jahr), und bei 10 Ersatzteilen erhalten wir A ≈ 1 − (1) (1−.995) 11 = 25,5 9 ′ s (die ungefähre Ausfallzeit) wäre 1,26252 × 10 −15 m s pro Jahr, effektiv 0). Beim Vergleich dieser beiden Workloads haben wir die Kosten für das Sparen um das Fünffache erhöht, sodass wir die Ausfallzeiten pro Jahr um vier Sekunden reduzieren konnten. Bei den meisten Workloads wäre der Anstieg der Kosten aufgrund dieser Erhöhung der Verfügbarkeit ungerechtfertigt. Die folgende Abbildung zeigt diesen Zusammenhang.
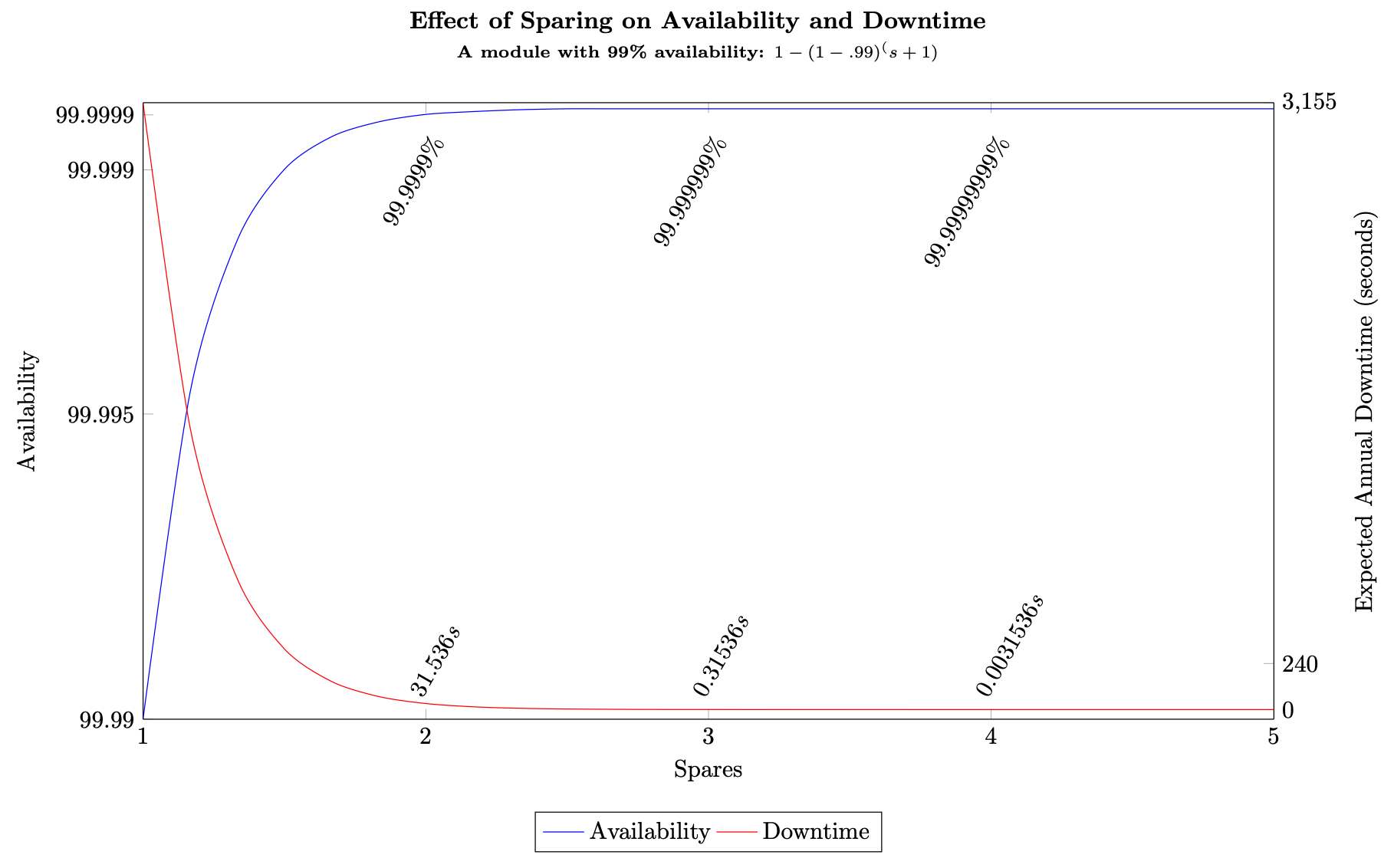
Sinkende Renditen aufgrund verstärkter Sparsamkeit
Bei drei Ersatzteilen und mehr führt dies zu Sekundenbruchteilen der erwarteten Ausfallzeit pro Jahr, was bedeutet, dass Sie nach diesem Zeitpunkt den Bereich mit sinkenden Renditen erreichen. Möglicherweise besteht der Drang, „einfach mehr hinzuzufügen“, um eine höhere Verfügbarkeit zu erreichen, aber in Wirklichkeit verschwindet der Kostenvorteil sehr schnell. Die Verwendung von mehr als drei Ersatzteilen bringt keinen wesentlichen Nutzen. Ein spürbarer Gewinn für fast alle Workloads, wenn das Subsystem selbst eine Verfügbarkeit von mindestens 99% aufweist.
Regel 6
Es gibt eine Obergrenze für die Kosteneffizienz von Sparsamkeit. Verwenden Sie die wenigsten Ersatzteile, die erforderlich sind, um die erforderliche Verfügbarkeit zu erreichen.
Bei der Auswahl der richtigen Anzahl von Ersatzteilen sollten Sie die Fehlereinheit berücksichtigen. Schauen wir uns zum Beispiel einen Workload an, für den 10 EC2-Instances erforderlich sind, um Spitzenkapazität zu bewältigen, und die in einer einzigen AZ bereitgestellt werden.
Da AZs als Grenzen zur Fehlerisolierung konzipiert sind, handelt es sich bei der Ausfalleinheit nicht nur um eine einzelne EC2-Instance, da eine gesamte Anzahl von EC2-Instances zusammen ausfallen kann. In diesem Fall sollten Sie die Redundanz durch eine weitere AZ erhöhen und 10 zusätzliche EC2-Instances bereitstellen, um die Last im Fall eines AZ-Ausfalls zu bewältigen, also insgesamt 20 EC2-Instances (entsprechend dem Muster der statischen Stabilität).
Dies scheint zwar 10 Ersatz-EC2-Instances zu sein, aber in Wirklichkeit handelt es sich nur um eine einzige Ersatz-AZ, sodass wir den Punkt sinkender Renditen nicht überschritten haben. Sie können jedoch noch kosteneffizienter arbeiten und gleichzeitig Ihre Verfügbarkeit erhöhen, indem Sie drei AZs verwenden und fünf EC2-Instances pro AZ bereitstellen.
Auf diese Weise steht eine Ersatz-AZ mit insgesamt 15 EC2-Instances (gegenüber zwei AZs mit 20 Instances) zur Verfügung, sodass immer noch die insgesamt erforderlichen 10 Instances zur Verfügung stehen, um die Spitzenkapazität während eines Ereignisses, das sich auf eine einzelne AZ auswirkt, zu bedienen. Daher sollten Sie Sparing einbauen, um über alle vom Workload verwendeten Grenzen der Fehlerisolierung (Instanz, Zelle, AZ und Region) hinweg fehlertolerant zu sein.
