Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verfügbarkeit verteilter Systeme
Verteilte Systeme bestehen sowohl aus Software- als auch aus Hardwarekomponenten. Einige der Softwarekomponenten können selbst ein anderes verteiltes System sein. Die Verfügbarkeit sowohl der zugrunde liegenden Hardware- als auch der Softwarekomponenten wirkt sich auf die daraus resultierende Verfügbarkeit Ihres Workloads aus.
Die Berechnung der Verfügbarkeit mithilfe von MTBF und MTTR hat ihre Wurzeln in Hardwaresystemen. Verteilte Systeme scheitern jedoch aus ganz anderen Gründen als ein Teil der Hardware. Während ein Hersteller konsistent die durchschnittliche Zeit berechnen kann, bis eine Hardwarekomponente abgenutzt ist, können dieselben Tests nicht auf die Softwarekomponenten eines verteilten Systems angewendet werden. Hardware folgt in der Regel der „Badewannenkurve“ der Ausfallrate, während Software einer gestaffelten Kurve folgt, die durch zusätzliche Fehler verursacht wird, die mit jeder neuen Version auftreten (siehe Softwarezuverlässigkeit
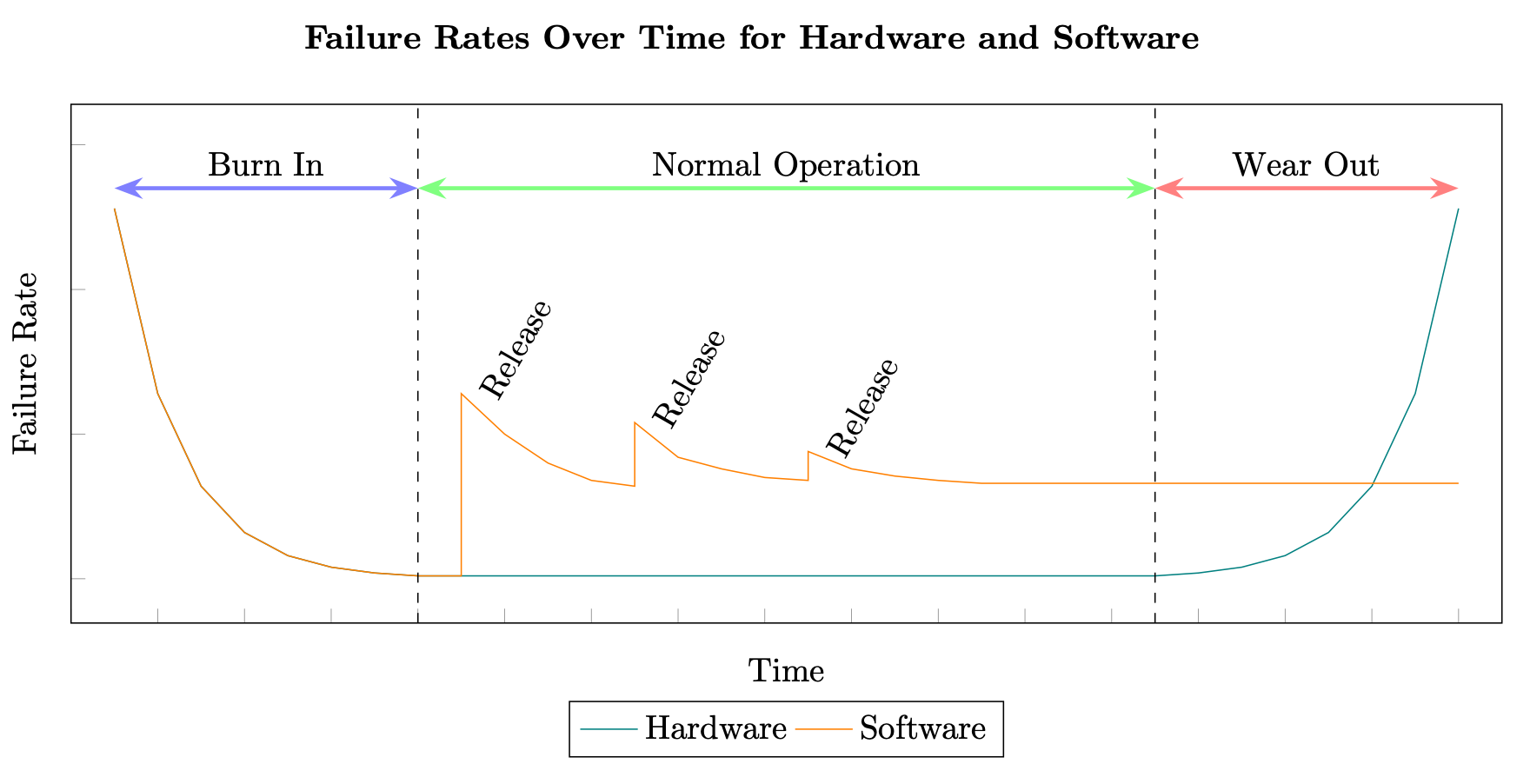
Hardware- und Softwareausfallraten
Darüber hinaus ändert sich die Software in verteilten Systemen in der Regel exponentiell schneller als die Hardware. Beispielsweise kann eine magnetische Standardfestplatte eine durchschnittliche jährliche Ausfallrate (AFR) von 0,93% aufweisen, was in der Praxis für eine Festplatte eine Lebensdauer von mindestens 3—5 Jahren bedeuten kann, bevor sie den Verschleißzeitraum erreicht, möglicherweise länger (siehe Backblaze
Hardware unterliegt auch dem Konzept der geplanten Obsoleszenz, d. h. sie hat eine feste Lebensdauer und muss nach einer bestimmten Zeit ausgetauscht werden. (Siehe Die große Glühbirnenverschwörung
All dies bedeutet, dass dieselben Test- und Prognosemodelle, die für Hardware zur Generierung von MTBF- und MTTR-Zahlen verwendet werden, nicht für Software gelten. Seit den 1970er Jahren gab es Hunderte von Versuchen, Modelle zur Lösung dieses Problems zu entwickeln, aber sie lassen sich im Allgemeinen alle in zwei Kategorien einteilen: Vorhersagemodellierung und Schätzmodellierung. (Siehe Liste der Modelle zur Softwarezuverlässigkeit
Daher wird die Berechnung einer vorausschauenden MTBF und MTTR für verteilte Systeme und somit einer vorausschauenden Verfügbarkeit immer von einer Art von Vorhersage oder Prognose abgeleitet. Sie können durch prädiktive Modellierung, stochastische Simulation, historische Analysen oder strenge Tests generiert werden, aber diese Berechnungen sind keine Garantie für Verfügbarkeit oder Ausfallzeit.
Die Gründe, warum ein verteiltes System in der Vergangenheit ausgefallen ist, werden sich möglicherweise nie wiederholen. Die Gründe, warum es in future scheitert, sind wahrscheinlich unterschiedlich und möglicherweise nicht erkennbar. Die erforderlichen Wiederherstellungsmechanismen können sich auch für future Ausfälle von denen unterscheiden, die in der Vergangenheit verwendet wurden, und sie können erheblich unterschiedliche Zeiträume in Anspruch nehmen.
Außerdem handelt es sich bei MTBF und MTTR um Durchschnittswerte. Es wird eine gewisse Abweichung zwischen dem Durchschnittswert und den tatsächlich gemessenen Werten geben (die Standardabweichung, σ, misst diese Variation). Daher kann es bei Workloads im Produktionsbetrieb zu kürzeren oder längeren Zeitabständen zwischen Ausfällen und Wiederherstellungen kommen.
Davon abgesehen ist die Verfügbarkeit der Softwarekomponenten, aus denen ein verteiltes System besteht, nach wie vor wichtig. Software kann aus zahlreichen Gründen ausfallen (mehr dazu im nächsten Abschnitt) und beeinträchtigt die Verfügbarkeit der Arbeitslast. Daher sollte bei hochverfügbaren verteilten Systemen der Schwerpunkt auf die Berechnung, Messung und Verbesserung der Verfügbarkeit von Softwarekomponenten ebenso gelegt werden wie auf Hardware- und externe Softwaresubsysteme.
Regel 2
Die Verfügbarkeit der Software in Ihrem Workload ist ein wichtiger Faktor für die Gesamtverfügbarkeit Ihres Workloads und sollte ebenso berücksichtigt werden wie andere Komponenten.
Es ist wichtig zu beachten, dass MTBF und MTTR für verteilte Systeme zwar schwer vorherzusagen sind, sie aber dennoch wichtige Erkenntnisse zur Verbesserung der Verfügbarkeit bieten. Die Verringerung der Ausfallhäufigkeit (höhere MTBF) und die Verkürzung der Wiederherstellungszeit nach einem Ausfall (niedrigere MTTR) werden beide zu einer höheren empirischen Verfügbarkeit führen.
Arten von Ausfällen in verteilten Systemen
In verteilten Systemen gibt es im Allgemeinen zwei Arten von Fehlern, die sich auf die Verfügbarkeit auswirken. Sie werden liebevoll Bohrbug und Heisenbug genannt (siehe „A Conversation with Bruce Lindsay“, ACM Queue Band 2, Nr. 8 — November 2004).
Ein Bohrbug ist ein wiederholbares funktionales Softwareproblem. Bei derselben Eingabe erzeugt der Fehler immer dieselbe falsche Ausgabe (wie das deterministische Bohr-Atommodell, das solide und leicht zu erkennen ist). Diese Arten von Fehlern treten selten auf, wenn ein Workload in Betrieb genommen wird.
Ein Heisenbug ist ein vorübergehender Fehler, was bedeutet, dass er nur unter bestimmten und ungewöhnlichen Bedingungen auftritt. Diese Bedingungen beziehen sich normalerweise auf Dinge wie Hardware (z. B. ein vorübergehender Gerätefehler oder Besonderheiten der Hardwareimplementierung wie die Registergröße), Compileroptimierungen und Sprachimplementierung, Grenzbedingungen (z. B. vorübergehender Speichermangel) oder Race-Bedingungen (z. B. die Nichtverwendung einer Semaphore für Multithread-Operationen).
Heisenbugs machen den Großteil der Fehler in der Produktion aus und sind schwer zu finden, da sie schwer zu finden sind und ihr Verhalten zu ändern scheinen oder zu verschwinden scheinen, wenn man versucht, sie zu beobachten oder zu debuggen. Wenn Sie das Programm jedoch neu starten, wird der fehlgeschlagene Vorgang wahrscheinlich erfolgreich sein, da die Betriebsumgebung etwas anders ist, wodurch die Bedingungen, die den Heisenbug verursacht haben, beseitigt sind.
Daher sind die meisten Produktionsausfälle vorübergehender Natur, und wenn der Vorgang erneut versucht wird, ist es unwahrscheinlich, dass er erneut fehlschlägt. Um widerstandsfähig zu sein, müssen verteilte Systeme fehlertolerant gegenüber Heisenbugs sein. Wie dies erreicht werden kann, werden wir im Abschnitt Erhöhung der MTBF für verteilte Systeme untersuchen.
