Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Messung der Verfügbarkeit
Wie wir bereits gesehen haben, ist die Erstellung eines zukunftsorientierten Verfügbarkeitsmodells für ein verteiltes System schwierig und bietet möglicherweise nicht die gewünschten Erkenntnisse. Was mehr Nutzen bringen kann, ist die Entwicklung einheitlicher Methoden zur Messung der Verfügbarkeit Ihres Workloads.
Die Definition von Verfügbarkeit als Verfügbarkeit und Ausfallzeit stellt einen Ausfall als binäre Option dar, entweder ist der Workload gestiegen oder nicht.
Dies ist jedoch selten der Fall. Ausfälle haben gewisse Auswirkungen und treten häufig auf einen Teil der Arbeitslast auf. Sie betreffen einen Prozentsatz der Benutzer oder Anfragen, einen Prozentsatz der Standorte oder ein Perzentil der Latenz. Dies sind alles Teilfehlermodi.
Und obwohl MTTR und MTBF nützlich sind, um zu verstehen, was die resultierende Verfügbarkeit eines Systems beeinflusst und wie es verbessert werden kann, dienen sie nicht als empirisches Maß für die Verfügbarkeit. Darüber hinaus bestehen Workloads aus vielen Komponenten. Ein Workload wie ein Zahlungsabwicklungssystem besteht beispielsweise aus vielen Anwendungsprogrammierschnittstellen (APIs) und Subsystemen. Also, wenn wir eine Frage stellen wollen wie: „Wie ist die Verfügbarkeit des gesamten Workloads?“ , es ist eigentlich eine komplexe und nuancierte Frage.
In diesem Abschnitt werden wir drei Möglichkeiten untersuchen, wie die Verfügbarkeit empirisch gemessen werden kann: Erfolgsrate serverseitiger Anfragen, Erfolgsquote clientseitiger Anfragen und jährliche Ausfallzeiten.
Erfolgsquote serverseitiger und clientseitiger Anfragen
Die ersten beiden Methoden sind sich sehr ähnlich und unterscheiden sich nur in der Sichtweise, in der die Messung durchgeführt wird. Serverseitige Metriken können anhand der Instrumentierung im Service erfasst werden. Sie sind jedoch nicht vollständig. Wenn Kunden den Service nicht erreichen können, können Sie diese Kennzahlen nicht erfassen. Um das Kundenerlebnis zu verstehen, ist es einfacher, kundenseitige Metriken zu sammeln, anstatt sich auf Telemetrie von Kunden zu verlassen, wenn es um fehlgeschlagene Anfragen geht, indem Sie den Kundenverkehr mit Canaries simulieren, einer Software, die Ihre Dienste regelmäßig überprüft und Kennzahlen aufzeichnet.
Diese beiden Methoden berechnen die Verfügbarkeit als den Bruchteil der gesamten gültigen Arbeitseinheiten, die der Dienst empfängt, und der Arbeitseinheiten, die er erfolgreich verarbeitet hat (dabei werden ungültige Arbeitseinheiten ignoriert, z. B. eine HTTP-Anfrage, die zu einem 404-Fehler führt).

Gleichung 8
Bei einem auf Anfrage basierenden Dienst ist die Arbeitseinheit die Anfrage, wie bei einer HTTP-Anfrage. Bei ereignisbasierten oder aufgabenbasierten Diensten handelt es sich bei den Arbeitseinheiten um Ereignisse oder Aufgaben, z. B. die Verarbeitung einer Nachricht aus einer Warteschlange. Dieses Maß für die Verfügbarkeit ist in kurzen Zeitintervallen, z. B. in Zeitfenstern von einer Minute oder fünf Minuten, aussagekräftig. Es eignet sich auch am besten für eine granulare Perspektive, z. B. auf API-Ebene für einen anforderungsbasierten Dienst. Die folgende Abbildung zeigt, wie die Verfügbarkeit im Laufe der Zeit aussehen könnte, wenn sie auf diese Weise berechnet wird. Jeder Datenpunkt in der Grafik wird mithilfe von Gleichung (8) über ein Fünf-Minuten-Fenster berechnet (Sie können andere Zeitdimensionen wie Intervalle von einer Minute oder zehn Minuten wählen). Datenpunkt 10 zeigt beispielsweise eine Verfügbarkeit von 94,5%. Das bedeutet, dass in den Minuten t+45 bis t+50, wenn der Dienst 1.000 Anfragen erhielt, nur 945 davon erfolgreich bearbeitet wurden.
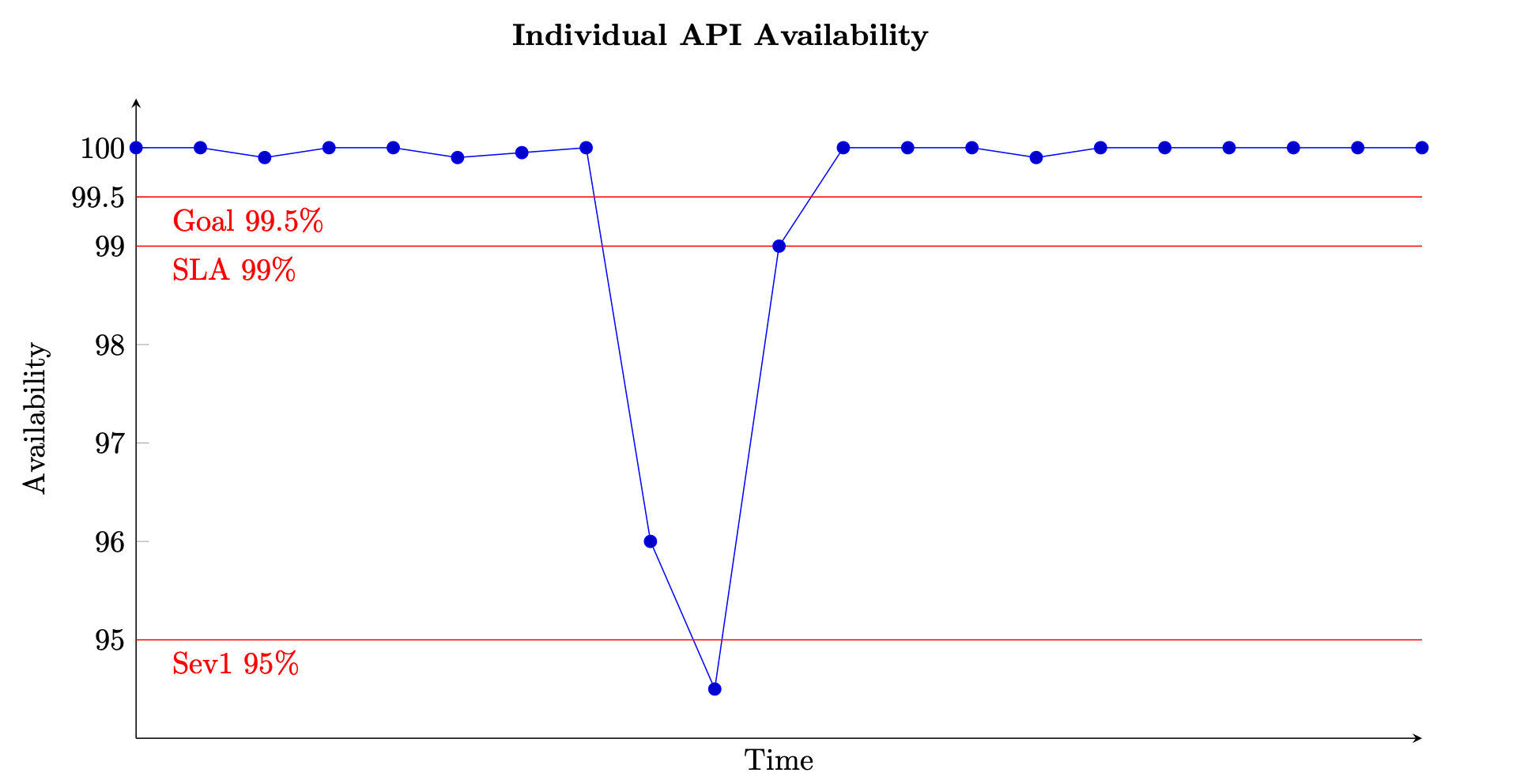
Beispiel für die Messung der Verfügbarkeit im Zeitverlauf für eine einzelne API
Die Grafik zeigt auch das Verfügbarkeitsziel der API, nämlich eine Verfügbarkeit von 99,5%, das Service Level Agreement (SLA), das sie den Kunden anbietet, eine Verfügbarkeit von 99% und den Schwellenwert für einen Alarm mit hohem Schweregrad von 95% Ohne den Kontext dieser verschiedenen Schwellenwerte bietet ein Verfügbarkeitsdiagramm möglicherweise keinen aussagekräftigen Einblick in die Funktionsweise Ihres Dienstes.
Wir möchten auch in der Lage sein, die Verfügbarkeit eines größeren Subsystems, wie einer Steuerungsebene, oder eines gesamten Dienstes nachzuverfolgen und zu beschreiben. Eine Möglichkeit, dies zu tun, besteht darin, den Durchschnitt jedes Fünf-Minuten-Datenpunkts für jedes Subsystem zu ermitteln. Das Diagramm sieht ähnlich aus wie das vorherige, ist aber repräsentativ für einen größeren Satz von Eingaben. Außerdem wird allen Subsystemen, aus denen Ihr Service besteht, das gleiche Gewicht beigemessen. Ein alternativer Ansatz könnte darin bestehen, alle eingegangenen und erfolgreich verarbeiteten Anfragen von allen APIs im Service zusammenzufassen, um die Verfügbarkeit in Intervallen von fünf Minuten zu berechnen.
Diese letztere Methode kann jedoch eine einzelne API verbergen, die einen niedrigen Durchsatz und eine schlechte Verfügbarkeit aufweist. Stellen Sie sich als einfaches Beispiel einen Dienst mit zwei APIs vor.
Die erste API empfängt innerhalb von fünf Minuten 1.000.000 Anfragen und verarbeitet 999.000 davon erfolgreich, was einer Verfügbarkeit von 99,9% entspricht. Die zweite API empfängt 100 Anfragen in demselben Fünf-Minuten-Fenster und verarbeitet nur 50 davon erfolgreich, was einer Verfügbarkeit von 50% entspricht.
Wenn wir die Anfragen von jeder API zusammenfassen, gibt es insgesamt 1.000.100 gültige Anfragen, von denen 999.050 erfolgreich verarbeitet wurden, was einer Verfügbarkeit des Dienstes insgesamt von 99,895% entspricht. Wenn wir jedoch den Durchschnitt der Verfügbarkeiten der beiden APIs berechnen, die erstere Methode, erhalten wir eine resultierende Verfügbarkeit von 74,95%, was möglicherweise aussagekräftiger für die tatsächliche Erfahrung ist.
Keiner der beiden Ansätze ist falsch, zeigt aber, wie wichtig es ist, zu verstehen, was Verfügbarkeitsmetriken Ihnen sagen. Sie könnten sich dafür entscheiden, Anfragen für alle Subsysteme zusammenzufassen, wenn Ihr Workload in allen Subsystemen ein ähnliches Anforderungsvolumen erhält. Dieser Ansatz konzentriert sich auf die „Anfrage“ und ihren Erfolg als Maß für die Verfügbarkeit und das Kundenerlebnis. Alternativ können Sie den Durchschnitt der Subsystemverfügbarkeiten festlegen, um deren Wichtigkeit trotz unterschiedlicher Anforderungsmengen gleichmäßig darzustellen. Dieser Ansatz konzentriert sich auf das Subsystem und die Fähigkeit jedes einzelnen, stellvertretend für das Kundenerlebnis zu stehen.
Jährliche Ausfallzeiten
Der dritte Ansatz ist die Berechnung der jährlichen Ausfallzeiten. Diese Form der Verfügbarkeitsmetrik eignet sich eher für die Festlegung und Überprüfung längerfristiger Ziele. Dazu muss definiert werden, was Ausfallzeiten für Ihre Arbeitslast bedeuten. Anschließend können Sie die Verfügbarkeit anhand der Anzahl der Minuten messen, in denen sich der Workload nicht in einem „Ausfall“ befand, im Verhältnis zur Gesamtzahl der Minuten im angegebenen Zeitraum.
Bei einigen Workloads kann Ausfallzeit möglicherweise so definiert werden, dass die Verfügbarkeit einer einzelnen API oder Workload-Funktion für ein Intervall von einer Minute oder fünf Minuten unter 95% fällt (was in der vorherigen Verfügbarkeitsgrafik der Fall war). Sie können Ausfallzeiten auch nur in Betracht ziehen, da sie für einen Teil der kritischen Datenebenenoperationen gelten. Beispielsweise gilt das Service Level Agreement von Amazon Messaging (SQS, SNS)
Größere, komplexere Workloads müssen möglicherweise systemweite Verfügbarkeitsmetriken definieren. Für eine große E-Commerce-Website kann eine systemweite Kennzahl so etwas wie die Bestellrate von Kunden sein. Hier kann ein Rückgang der Bestellungen um 10% oder mehr im Vergleich zur prognostizierten Menge innerhalb eines Fünf-Minuten-Fensters zu Ausfallzeiten führen.
Bei beiden Ansätzen können Sie dann alle Ausfallzeiten summieren, um eine jährliche Verfügbarkeit zu berechnen. Wenn es beispielsweise in einem Kalenderjahr 27 Ausfallzeiten von jeweils fünf Minuten gegeben hätte, was definiert ist, dass die Verfügbarkeit einer API auf Datenebene unter 95% fiel, betrug die Gesamtausfallzeit 135 Minuten (einige Fünf-Minuten-Perioden könnten aufeinanderfolgend gewesen sein, andere isoliert), was einer jährlichen Verfügbarkeit von 99,97% entspricht.
Diese zusätzliche Methode zur Messung der Verfügbarkeit kann Daten und Erkenntnisse liefern, die in den clientseitigen und serverseitigen Metriken fehlen. Stellen Sie sich zum Beispiel eine Arbeitslast vor, die beeinträchtigt ist und bei der die Fehlerquoten deutlich erhöht sind. Kunden mit diesem Workload könnten ganz aufhören, ihre Dienste anzurufen. Vielleicht haben sie einen Schutzschalter aktiviert oder ihren Notfallwiederherstellungsplan
Latency
Schließlich ist es auch wichtig, die Latenz der Verarbeitung von Arbeitseinheiten innerhalb Ihres Workloads zu messen. Ein Teil der Verfügbarkeitsdefinition besteht darin, die Arbeit innerhalb einer festgelegten SLA zu erledigen. Wenn die Rückgabe einer Antwort länger dauert als das Client-Timeout, geht der Client davon aus, dass die Anfrage fehlgeschlagen ist und der Workload nicht verfügbar ist. Auf der Serverseite scheint die Anfrage jedoch erfolgreich verarbeitet worden zu sein.
Die Messung der Latenz bietet eine weitere Möglichkeit, die Verfügbarkeit zu bewerten. Die Verwendung von Perzentilen und dem getrimmten Mittelwert ist eine gute Statistik für diese Messung. Sie werden üblicherweise im 50. Perzentil (P50 und TM50) und 99. Perzentil (P99 und TM99) gemessen. Die Latenz sollte anhand von Kanariendaten gemessen werden, um das Kundenerlebnis abzubilden, sowie anhand serverseitiger Metriken. Immer wenn die durchschnittliche Latenz eines bestimmten Perzentils, wie P99 oder TM99,9, über einem Ziel-SLA liegt, können Sie diese Ausfallzeit berücksichtigen, die zu Ihrer jährlichen Ausfallzeitberechnung beiträgt.
