This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Streaming architecture patterns using a modern data architecture
Organizations perform streaming analytics to build better customer experiences in near real-time to stay ahead of their competitors because the value of data diminishes over time. To be near real time, data needs to be produced, captured, and processed with low latency. Organizations need a system that scales to support the modern data architecture needs, but also allows them to build their own applications on top of the data collected. The order is critical, because applications need to be able to tell the story of what happened, when it happened, and how it happened, relative to other events in the pipeline.
The modern data architecture on AWS provides a strategic vision of how multiple AWS data and analytics services can be combined into a multi-purpose data processing and analytics environment to address these challenges.
Low latency modern data streaming applications
The following are a few use cases for when you need to move data around your purpose-built data services with low latency for faster insights, and how to build these streaming application architectures with AWS streaming technologies.
Build access logs streaming applications using Firehose and Managed Service for Apache Flink
Customers perform log analysis that involves searching, analyzing, and visualizing machine data generated by their IT systems and technology infrastructure. It includes logs and metrics such as user transactions, customer behavior, sensor activity, machine behavior, and security threats. This data is complex, but also the most valuable because it contains operational intelligence for IT, security, and business.
In this use case, customers have collected log data in an Amazon S3 data lake. We need to access log data and analyze it in a variety of ways, using the right tool for the job for various security and compliance requirements. There are several data consumers including auditors, streaming analytics users, enterprise data warehouse users, and so on. They need to keep a copy of the data for regulatory purposes.
The following diagram illustrates the modern data architecture with access logs data as an input to derive near real-time dashboards and notifications.
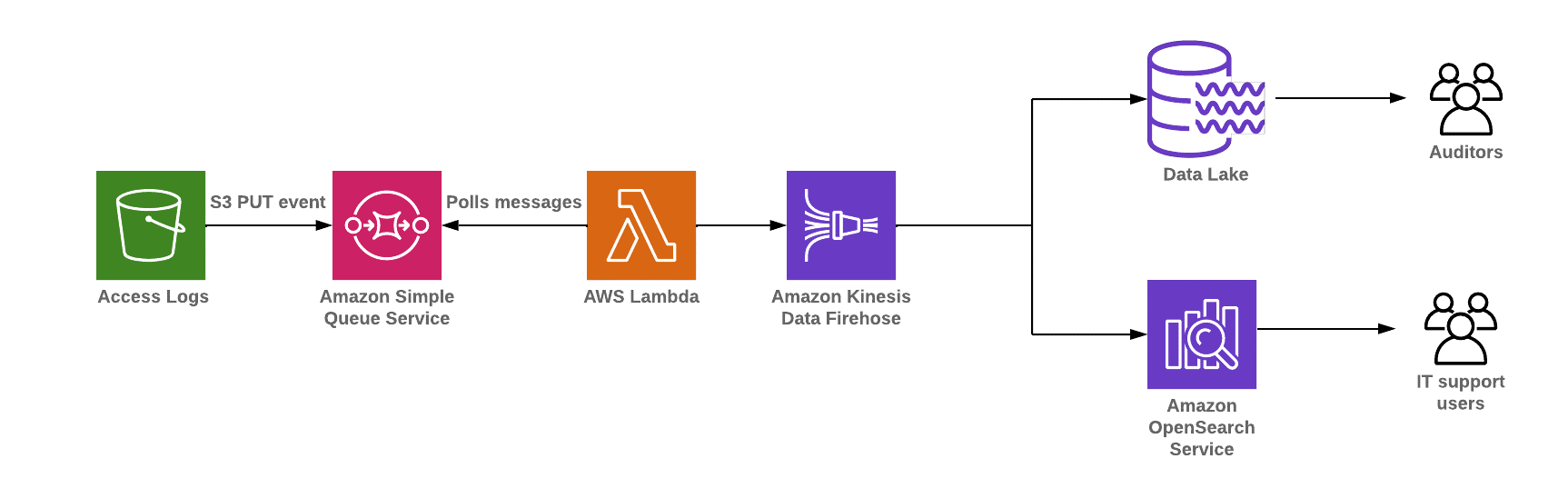
Access logs streaming applications for anomaly detection using Amazon Managed Service for Apache Flink and Amazon OpenSearch Service
The steps that follow the architecture are:
-
Logs from multiple sources such as Amazon CloudFront
access logs, VPC Flow Logs, API logs, and application logs are pushed into the data lake. -
Amazon S3 PUT events are published to Amazon SQS events. AWS Lambda polls the events from Amazon SQS and invokes a Lambda function to move data into multiple sources such as Amazon S3 and Amazon OpenSearch Service.
-
You can build low latency modern data streaming applications by creating a near real-time OpenSearch dashboard.
-
You can also store access log data into Amazon S3 for archival, and load sub-access log summary data into Amazon Redshift, depending on your use case.
Stream data from diverse source systems into the data lake using MSK for near real-time reports
Customers want to stream near real-time data from diverse source systems such as Software as a Service (SaaS) applications, databases, and social media into Amazon S3, and to online analytical processing (OLAP) systems such as Amazon Redshift, to derive user behavior insights and to build better customer experiences. Hopefully, this will drive customers toward more reactive, intelligent, near real-time experiences. You can use this data in Amazon Redshift to develop customer-centric business reports to improve overall customer experience.
The following diagram illustrates the modern data architecture with input stream data to derive near real-time dashboards.
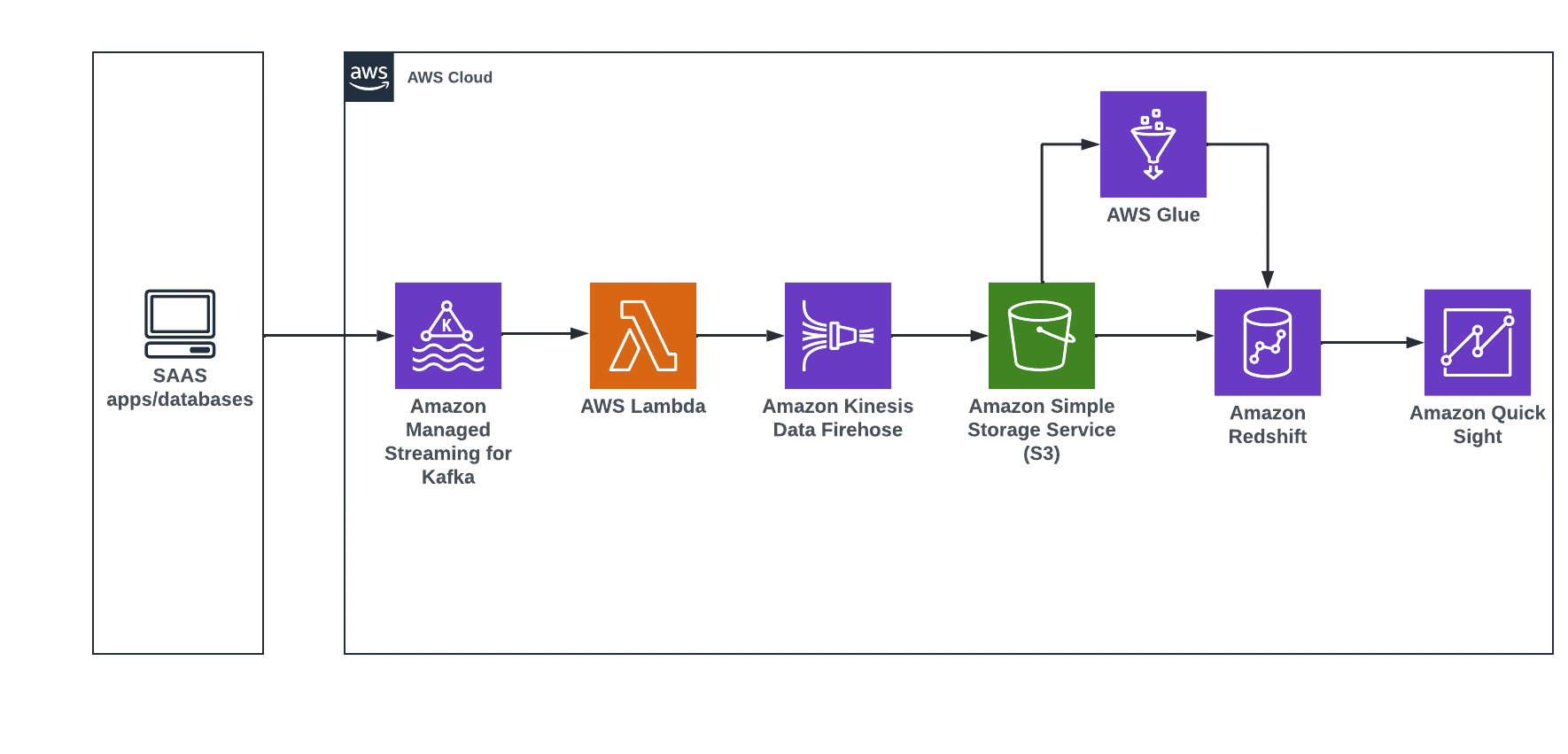
Derive insights from input data coming from diverse source systems for near real-time dashboards with QuickSight.
The steps that follow the architecture are:
-
You can stream near real-time data from source systems such as social media using Amazon MSK, Lambda, and Firehose into Amazon S3.
-
You can use AWS Glue for data processing, and load transformed data into Amazon Redshift using a Glue development endpoint such as Amazon SageMaker AI notebook instances.
-
When data is in Amazon Redshift, you can create a customer-centric business report using QuickSight.
Build a serverless streaming data pipeline using Amazon Kinesis and AWS Glue
Customers want low-latency near real-time analytics to process user behavior and respond almost instantaneously with relevant offers and recommendations. The customer’s attention will be lost if these recommendations are not available for days, hours, or even minutes – they need to happen in near real-time. The following diagram illustrates a typical modern data architecture for a streaming data pipeline to keep the application up to date, and to store streaming data into a data lake for offline analysis.
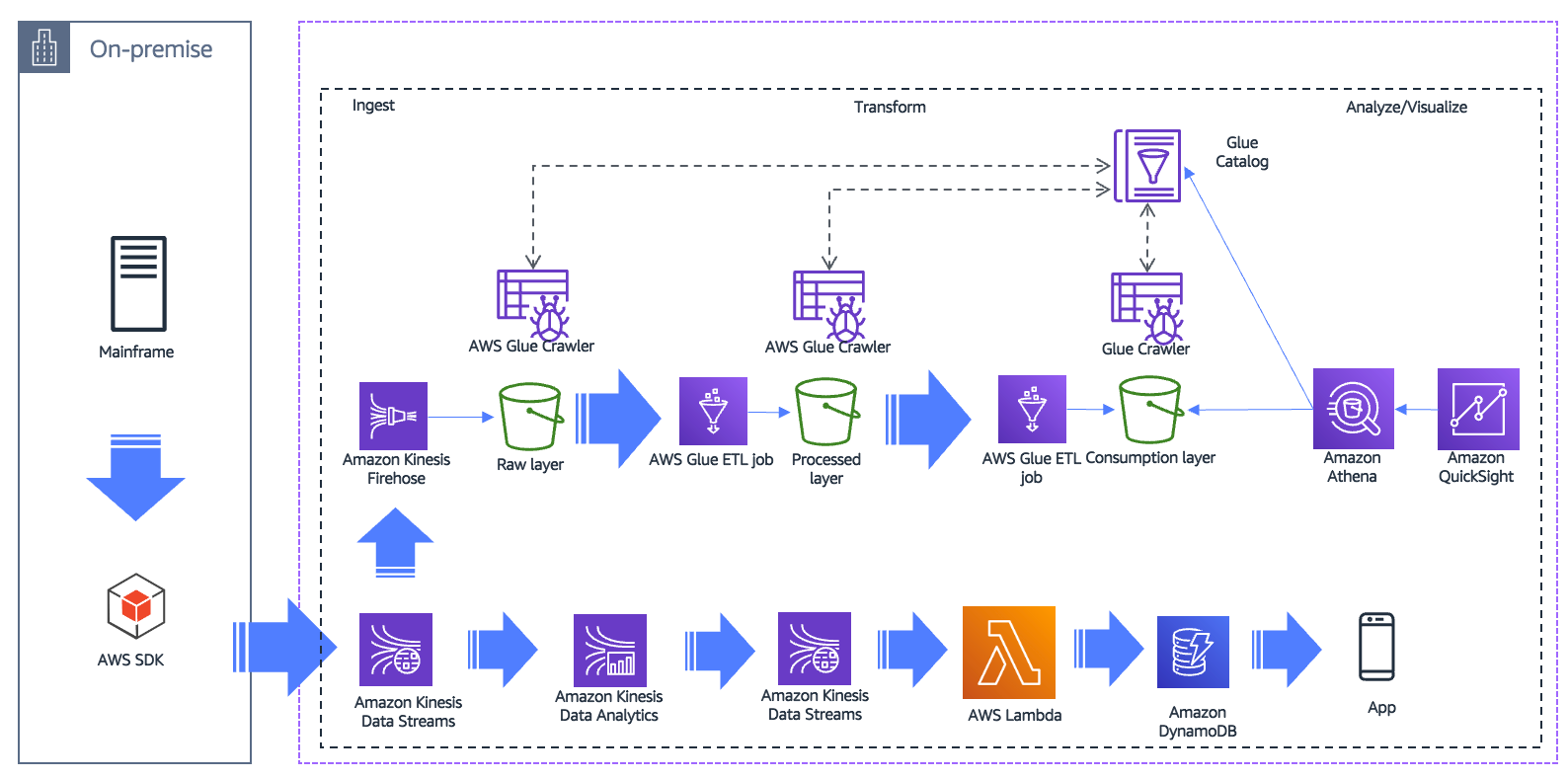
Build a serverless streaming data pipeline
The steps that follow the architecture are:
-
Extract data in near real-time from an on-premises legacy system to a streaming platform such as Apache Kafka. From Kafka, you can move the data to Kinesis Data Streams.
-
Use Managed Service for Apache Flink to analyze streaming data, gain actionable insights, and respond to your business and customer needs in near real-time.
-
Store analyzed data in cloud scale databases such as Amazon DynamoDB, and push to your end users in near real-time.
-
Kinesis Data Streams can use Firehose to send the same streaming content to the data lake for non-real-time analytics use cases.
-
AWS Glue includes an ETL engine that you can use to transform data. AWS Glue crawlers automatically update the metadata store as new data is ingested.
-
Analytics teams use data in the consumption layer with analytics solutions such as Athena and QuickSight.
Set up near real-time search on DynamoDB table using Kinesis Data Streams and OpenSearch Service
Organizations want to build a search service for their customers to find the right product, service, document, or answer to their problem as quickly as possible. Their searches will be across both semi-structured and unstructured data, and across different facets and attributes. Search results have to be relevant and delivered in near real-time. For example, if you have an ecommerce platform, you want customers to quickly find the product they're looking for.
You can use both DynamoDB and OpenSearch Service to build a near real-time search service. You can use DynamoDB as a durable store, and OpenSearch Service to extend its search capabilities. When you set up your DynamoDB tables and streams to replicate your data into OpenSearch Service, you can perform near real-time, full-text search on your data.
The following diagram illustrates the modern data architecture with Amazon DynamoDB and Amazon OpenSearch Service.
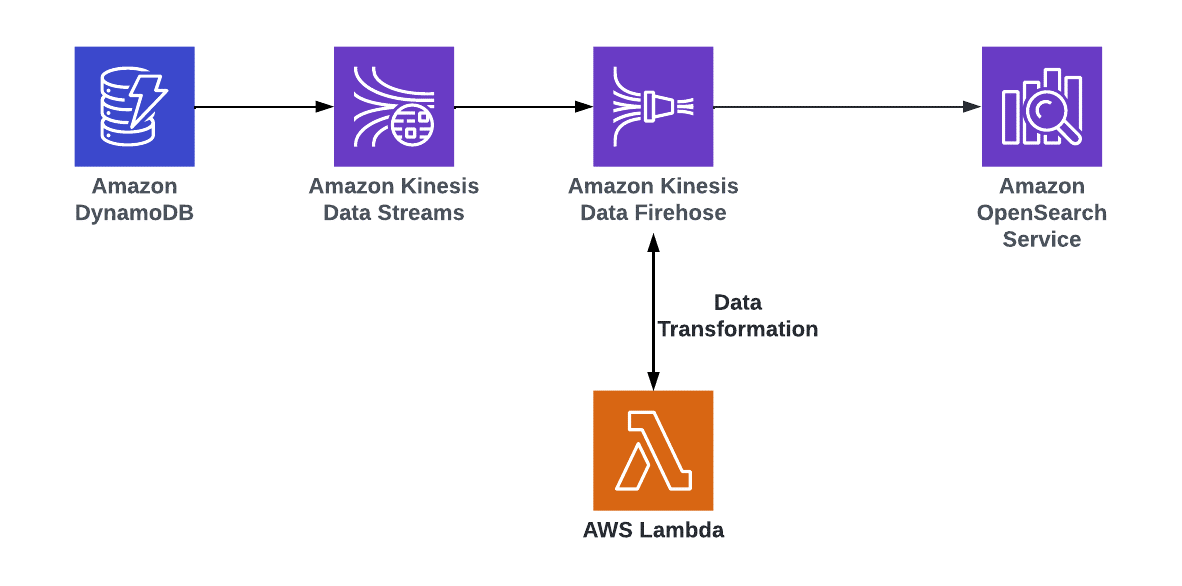
Derive insights from Amazon DynamoDB data by setting up near real-time search using Amazon OpenSearch Service
The steps that follow the architecture are:
-
In this design, the DynamoDB table is used as the primary data store. An Amazon OpenSearch Service
cluster is used to serve all types of searches by indexing the table. -
DynamoDB has an integration with Kinesis Data Streams for change data capture (CDC) any update, deletion, or new item on the main table is captured and processed using AWS Lambda. Lambda makes appropriate calls to OpenSearch Service to index the data in near real-time.
-
For more details about this architecture, refer to Indexing Amazon DynamoDB Content with Amazon OpenSearch Service Using AWS Lambda
and Loading Streaming Data into Amazon OpenSearch Service from Amazon DynamoDB. -
You can use the streaming functionality to send the changes to OpenSearch Service or Amazon Redshift by using a Data Firehose delivery stream. Before you load data into OpenSearch Service, you might need to transform the data. You can use Lambda functions to perform this task. For more information, refer to Amazon Data Firehose Data Transformation.
Build a real-time fraud prevention system using Amazon MSK and Amazon Fraud Detector
Organizations with online businesses have to be on guard constantly for fraudulent activity such as fake accounts or payments made with stolen credit cards. One way they try to identify fraudsters is by using fraud detection applications. Emerging technologies like artificial intelligence (AI) and machine learning (ML) can provide a solution that shifts from enforcing rule-based validations to using validations based on learning from examples and trends directly found in the transaction data by specifying the key features that might contribute to fraudulent behavior, such as customer-related information (card number, email, IP address, and location) and transaction-related information (time, amount, and currency).
The following diagram illustrates the modern streaming data architecture for building fraud prevention system using Amazon MSK, Amazon Managed Service for Apache Flink, and Amazon Fraud Detector.
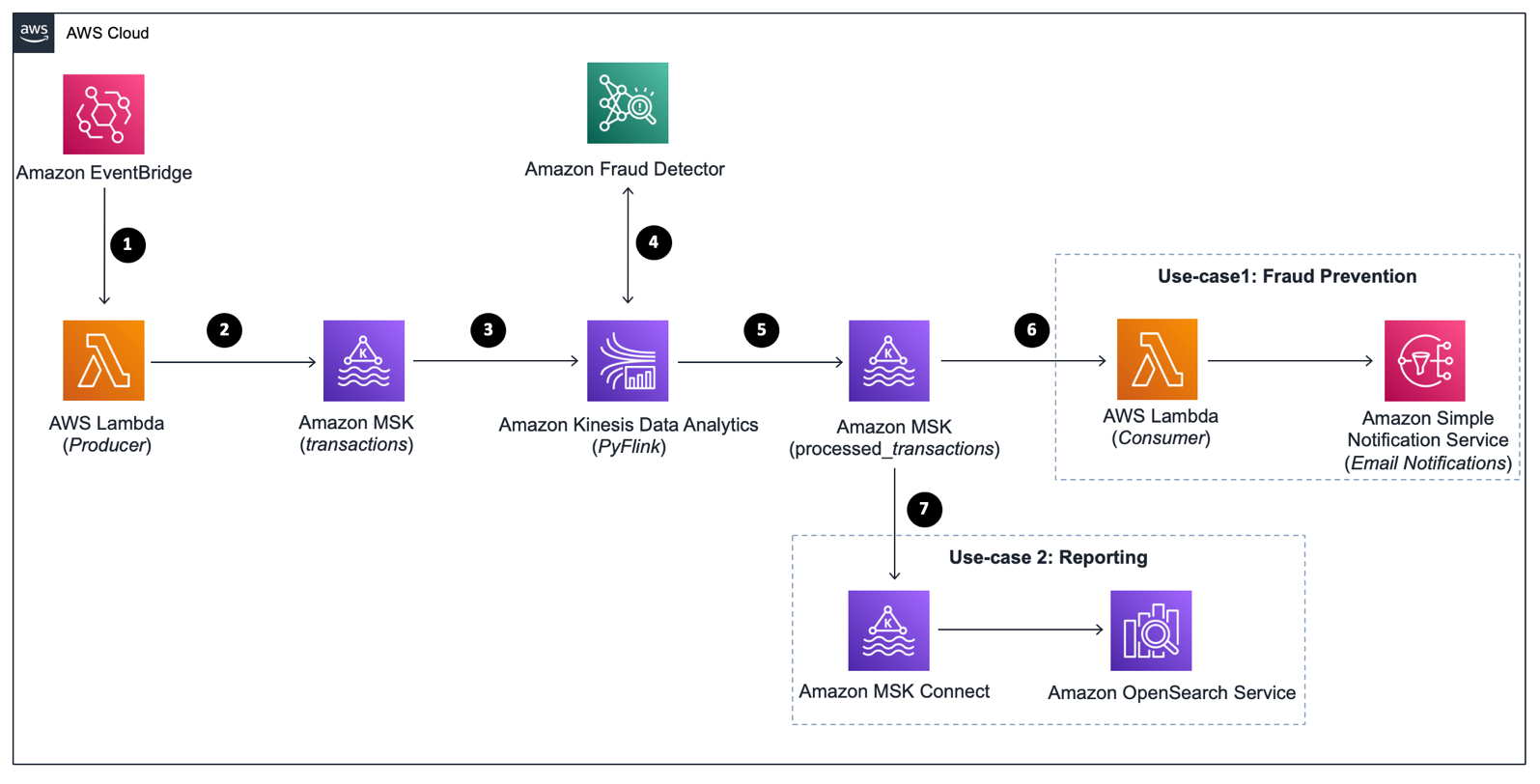
Build a fraud detection system on AWS
The first use case demonstrates fraud prevention by identifying fraudulent transactions, flagging them to be blocked, and sending an alert notification. The second writes all transactions in real time to Amazon OpenSearch Service, which enables real-time transaction reporting using OpenSearch dashboards.
The steps that follow the architecture are:
-
Use AWS Lambda
function as a real-time transactions producer that can be scheduled to run every minute using an Amazon EventBridge rule. -
Each transaction is written into an input Amazon MSK topic called transactions.
-
Process the payments in real time by using Apache Flink Table API
, which allows intuitive processing using relational operators such as selection, filter, and join. You can use the PyFlink Table API running as a Kinesis data analytics application. -
The Kinesis data analytics application calls the Amazon Fraud Detector GetEventPrediction API to get the predictions in real time.
-
The Kinesis data analytics application writes the output containing the transaction outcome (fraud prediction) into an output Amazon MSK topic called processed_transactions.
-
Use a AWS Lambda function to evaluate the outcome of each transaction. If the outcome is block, it generates an Amazon Simple Notification Service
(Amazon SNS) notification to notify you by email. -
Use Amazon MSK Connect to sink the data in real time to an OpenSearch Service visualization dashboard with fraud prediction results.
For more details about this architecture, refer to the Build and visualize a real-time fraud prevention system
Stream games data from diverse source systems into a Lake using Kinesis Data Streams for real-time game insights
The Game Analytics Pipeline solution helps game developers launch a scalable serverless data pipeline to ingest, store, and analyze telemetry data generated from games and services. The solution supports streaming ingestion of data, allowing users to gain insights from their games and other applications within minutes.
The following diagram illustrates the modern data streaming architecture with streaming games data from various devices to derive real-time insights.
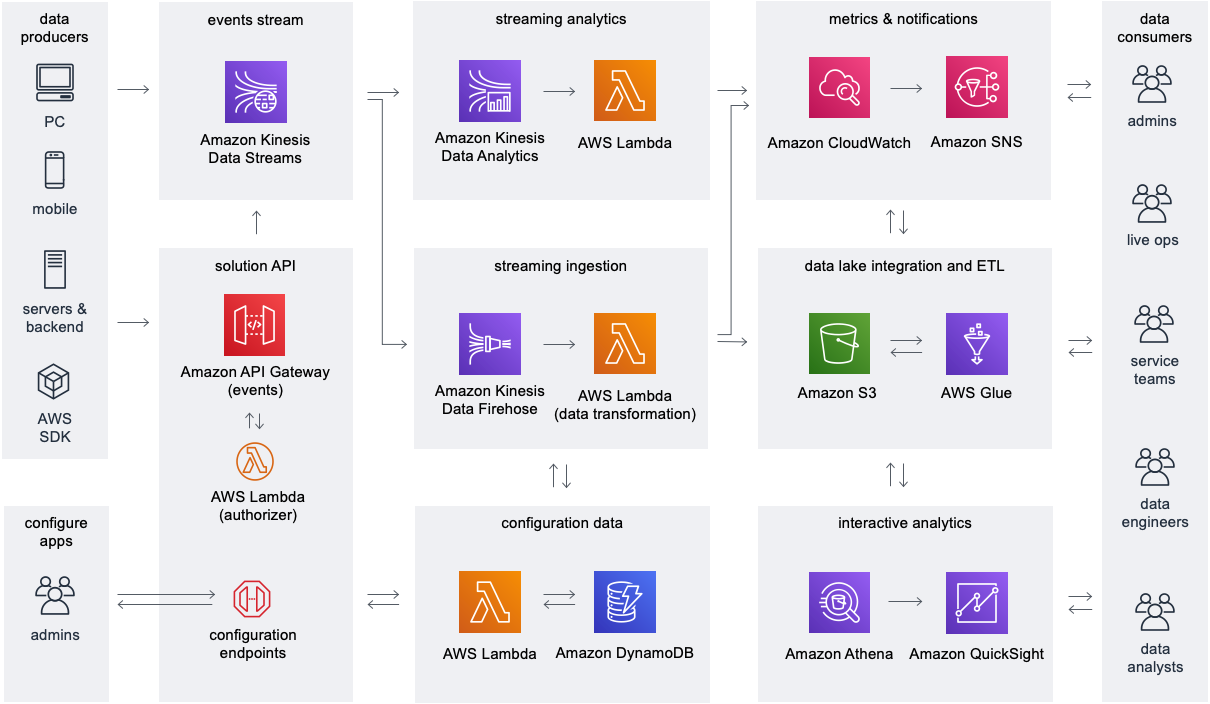
Derive real-time persona-centric games insights from various devices
The steps that follow the architecture are:
-
API Gateway provides REST API endpoints for registering game applications with the solution and for ingesting game telemetry data, which sends the events to Kinesis Data Streams. DynamoDB stores game application configurations and API keys.
-
You can send streaming game data to Kinesis Data Streams from your data producers, including game clients, game servers, and other applications, and enable real-time data processing by Firehose and Managed Service for Apache Flink. Firehose consumes the streaming data from Kinesis Data Streams and invokes Lambda with batches of events for serverless data processing and transformation before ingestion into Amazon S3 for storage.
-
AWS Glue provides ETL processing workflows and metadata storage in the AWS Glue Data Catalog, which provides the basis for a data lake for integration with flexible analytics tools. Sample Athena queries analyze game events, and integration with QuickSight is available for reporting and visualization. CloudWatch monitors, logs, and generates alarms for the utilization of AWS resources and creates an operational dashboard. Amazon Simple Notification Service (Amazon SNS) provides delivery of notifications to solution administrators and other data consumers when CloudWatch alarms are triggered.
