Szenario 5: Telemetriedatenüberwachung in Echtzeit mit Apache Kafka
ABC1Cabs ist ein Online-Taxibuchungsunternehmen. Alle Taxis sind mit IoT-Geräten ausgestattet, die Telemetriedaten von den Fahrzeugen sammeln. Derzeit betreibt ABC1Cabs Apache-Kafka-Cluster, die für die Nutzung von Echtzeit-Ereignissen, die Erfassung von Systemzustandsmetriken und die Verfolgung von Aktivitäten ausgelegt sind und die Daten in die auf einem On-Premises-Hadoop-Cluster aufgebaute Apache-Spark-Streaming-Plattform einspeisen.
ABC1Cabs verwendet OpenSearch Dashboards für Geschäftsmetriken, Debugging, Warnungen und das Erstellen anderer Dashboards. Das Unternehmen interessiert sich für den Einsatz von Amazon MSK, Amazon EMR mit Spark Streaming und OpenSearch Service mit OpenSearch Dashboards. Der Verwaltungsaufwand für die Wartung von Apache-Kafka- und Hadoop-Clustern soll reduziert und gleichzeitig vertraute Open-Source-Software und APIs für die Orchestrierung seiner Datenpipeline genutzt werden. Das folgende Architekturdiagramm zeigt seine Lösung in AWS.
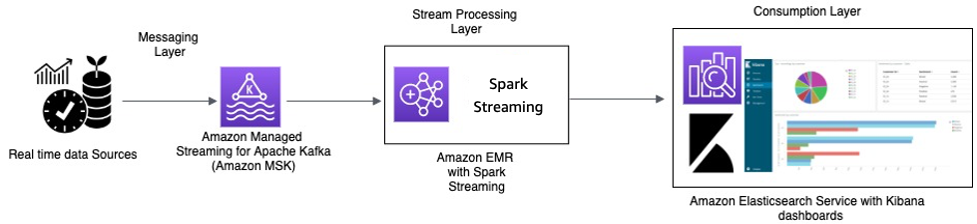
Echtzeitverarbeitung mit Amazon MSK und Datenstromverarbeitung mit Apache Spark Streaming in Amazon EMR und Amazon OpenSearch Service mit OpenSearch Dashboards
Die IoT-Geräte im Taxi sammeln Telemetriedaten und senden sie an einen Quell-Hub. Der Quell-Hub ist so konfiguriert, dass er Daten in Echtzeit an Amazon MSK sendet. Mithilfe der APIs der Apache-Kafka-Produzentenbibliothek wird Amazon MSK so konfiguriert, dass die Daten in einen Amazon-EMR-Cluster gestreamt werden. Auf dem Amazon EMR-Cluster sind ein Kafka-Client und Spark Streaming installiert, um die Datenströme nutzen und verarbeiten zu können.
Spark Streaming verfügt über Senken-Konnektoren, die Daten direkt in definierte Indizes von Elasticsearch schreiben können. Elasticsearch-Cluster mit OpenSearch Dashboards können für Metriken und Dashboards verwendet werden. Amazon MSK, Amazon EMR mit Spark Streaming und OpenSearch Service mit OpenSearch Dashboards sind allesamt verwaltete Services, bei denen AWS den undifferenzierten Aufwand der Infrastrukturverwaltung verschiedener Cluster übernimmt, sodass Sie Ihre Anwendung mit vertrauter Open-Source-Software mit wenigen Klicks erstellen können. Im nächsten Abschnitt werden diese Services näher beleuchtet.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Apache Kafka ist eine Open-Source-Plattform, mit der Kunden Streaming-Daten wie Clickstream-Ereignisse, Transaktionen, IoT-Ereignisse sowie Anwendungs- und Maschinenprotokolle erfassen können. Mit diesen Informationen können Sie Anwendungen entwickeln, die Echtzeit-Analysen durchführen, kontinuierliche Transformationen ausführen und diese Daten in Echtzeit an Data Lakes und Datenbanken verteilen.
Sie können Kafka als Streaming-Datenspeicher verwenden, um Anwendungen von Produzenten und Verbrauchern zu entkoppeln und eine zuverlässige Datenübertragung zwischen den beiden Komponenten zu ermöglichen. Zwar ist Kafka eine gängige Daten-Streaming- und Messaging-Plattform für Unternehmen, es kann sich jedoch schwierig gestalten, sie in der Produktion einzurichten, zu skalieren und zu verwalten.
Amazon MSK übernimmt diese Verwaltungsaufgaben und erleichtert das Einrichten, Konfigurieren und Ausführen von Kafka zusammen mit Apache Zookeeper in einer Umgebung, die den bewährten Methoden für hohe Verfügbarkeit und Sicherheit entspricht. Sie können weiterhin Kafkas Operationen auf der Steuer- und Datenebene verwenden, um die Erzeugung und den Verbrauch von Daten zu verwalten.
Da Amazon MSK Open-Source-Apache Kafka ausführt und verwaltet, können Kunden bestehende Apache-Kafka-Anwendungen einfach auf AWS migrieren und ausführen, ohne Änderungen am Anwendungscode vornehmen zu müssen.
Skalierung
Amazon MSK bietet Skalierungsoperationen an, sodass der Benutzer den Cluster aktiv skalieren kann, während er ausgeführt wird. Während des Erstellens eines Amazon-MSK-Clusters können Sie beim Start des Clusters den Instance-Typ der Broker angeben. Sie können mit wenigen Brokern innerhalb eines Amazon-MSK-Clusters beginnen. Anschließend können Sie mithilfe der AWS Management Console oder AWS CLI bis zu Hunderten von Brokern pro Cluster skalieren.
Alternativ können Sie Ihre Cluster skalieren, indem Sie die Größe oder Familie Ihrer Apache-Kafka-Broker ändern. Das Ändern der Größe oder der Familie Ihrer Broker gibt Ihnen die Flexibilität, die Datenverarbeitungskapazität Ihres Amazon-MSK-Clusters an Änderungen Ihrer Workloads anzupassen. Verwenden Sie die Tabelle Amazon MSK: Dimensionierung und Preise
Nach dem Erstellen des Amazon-MSK-Clusters können Sie den EBS-Speicherplatz pro Broker erhöhen, jedoch nicht verringern. Während dieses Skalierungsvorgangs bleiben Speichervolumen verfügbar. Es werden zwei Arten von Skalierungsoperationen angeboten: Automatische Skalierung (Auto Scaling) und Manuelle Skalierung (Manual Scaling).
Amazon MSK unterstützt die automatische Erweiterung des Clusterspeichers als Reaktion auf eine erhöhte Nutzung mithilfe von Auto-Scaling-Anwendungsrichtlinien. Ihre automatische Skalierungsrichtlinie legt die Auslastung der Zielfestplatte und die maximale Skalierungskapazität fest.
Der Schwellenwert für die Speicherauslastung hilft Amazon MSK dabei, eine automatische Skalierungsoperation auszulösen. Um den Speicherplatz durch manuelle Skalierung zu erhöhen, warten Sie, bis sich der Cluster im Zustand ACTIVE befindet. Die Speicherskalierung weist eine Ruhephase von mindestens sechs Stunden zwischen den Ereignissen auf. Auch wenn durch den Vorgang sofort zusätzlicher Speicherplatz verfügbar gemacht wird, führt der Service Optimierungen an Ihrem Cluster durch, die bis zu 24 Stunden oder länger dauern können.
Die Dauer dieser Optimierungen ist proportional zu Ihrer Speichergröße. Darüber hinaus bietet der Service auch die Replikation in mehreren Availability Zones innerhalb einer AWS-Region an, um die Hochverfügbarkeit zu gewährleisten.
Konfiguration
Amazon MSK bietet eine Standardkonfiguration für Broker, Themen und Apache-ZooKeeper-Knoten. Ebenso können Sie benutzerdefinierte Konfigurationen erstellen und sie verwenden, um neue Amazon-MSK-Cluster zu erstellen oder vorhandene Cluster zu aktualisieren. Wenn Sie einen MSK-Cluster erstellen, ohne eine benutzerdefinierte Amazon-MSK-Konfiguration anzugeben, erstellt und verwendet Amazon MSK eine Standardkonfiguration. Eine Liste dieser Standardwerte finden Sie unter Konfiguration von Apache Kafka.
Zu Überwachungszwecken sammelt Amazon MSK Apache-Kafka-Metriken und sendet sie an Amazon CloudWatch, wo Sie sich diese anzeigen lassen können. Die Metriken, die Sie für Ihren MSK-Cluster konfigurieren, werden automatisch gesammelt und an CloudWatch übergeben. Durch die Überwachung der Verzögerung bei den Verbrauchern können Sie langsame oder hängen gebliebene Verbraucher identifizieren, die bei den neuesten verfügbaren Daten zu einem Thema nicht auf dem aktuellen Stand sind. Bei Bedarf können Sie dann Abhilfemaßnahmen ergreifen, z. B. die Skalierung oder den Neustart dieser Verbraucher vornehmen.
Migration zu Amazon MSK
Die Migration von On-Premises zu Amazon MSK kann mit einer der folgenden Methoden durchgeführt werden.
-
MirrorMaker2.0 – MirrorMaker2.0 (MM2) ist eine Multi-Cluster-Datenreplikations-Engine, die auf dem Apache-Kafka-Connect Framework basiert.. MM2 ist eine Kombination aus einem Apache-Kafka-Quellenkonnektor und einem Senkenkonnektor. Sie können einen einzelnen MM2-Cluster verwenden, um Daten zwischen mehreren Clustern zu migrieren. MM2 erkennt automatisch neue Themen und Partitionen und stellt gleichzeitig sicher, dass die Themenkonfigurationen zwischen den Clustern synchronisiert werden. MM2 unterstützt Migrations-ACLs, Themenkonfigurationen und Offset-Übersetzung. Weitere Einzelheiten zur Migration finden Sie unter Migrieren von Clustern mit Apache Kafkas MirrorMaker. MM2 wird für Anwendungsfälle im Zusammenhang mit der Replikation von Themenkonfigurationen und der automatischen Offset-Übersetzung verwendet.
-
Apache Flink – MM2 unterstützt mindestens Semantik, die genau einmal abgeschlossen wird. Datensätze können am Zielort dupliziert werden, und Verbrauchern müssen idempotent sein, um doppelte Datensätze verarbeiten zu können. In Szenarien mit „Genau Einmal“-Semantik müssen Kunden Apache Flink verwenden können. Es bietet eine Alternative, um „Genau Einmal“-Semantik zu erreichen.
Apache Flink kann auch für Szenarien verwendet werden, in denen Daten vor der Übermittlung an den Zielcluster Mapping- oder Transformationsaktionen erfordern. Apache Flink bietet Konnektoren für Apache Kafka mit Quellen und Senken, die Daten von einem Apache-Kafka-Cluster lesen und in einen anderen schreiben können. Apache Flink kann in AWS ausgeführt werden, indem ein Amazon-EMR-Cluster gestartet wird oder indem Apache Flink als Anwendung mit Amazon Kinesis Data Analytics ausgeführt wird.
-
AWS Lambda – Mit der Unterstützung von Apache Kafka als Ereignisquelle für AWS Lambda
können Kunden jetzt Nachrichten aus einem Thema über eine Lambda-Funktion verwenden. Der AWS Lambda-Service fragt intern nach neuen Datensätzen oder Nachrichten von der Ereignisquelle ab und ruft dann synchron die Ziel-Lambda-Funktion auf, um diese Nachrichten zu verwenden. Lambda liest die Nachrichten in Batches und stellt die Nachrichten-Batches Ihrer Funktion in der Ereignisnutzlast zur Verarbeitung zur Verfügung. Die verwendeten Nachrichten können dann transformiert und/oder direkt in den Ziel-Amazon-MSK-Cluster geschrieben werden.
Amazon EMR mit Spark Streaming
Bei Amazon EMR
Amazon EMR bietet die Fähigkeiten von Spark und kann zum Starten von Spark Streaming verwendet werden, um Daten aus Kafka zu nutzen. Spark Streaming ist eine Erweiterung der Spark-Kern-API, die eine skalierbare, durchsatzstarke und fehlertolerante Datenstromverarbeitung von Live-Datenströmen ermöglicht.
Sie können einen Amazon-EMR-Cluster mit der AWS Command Line Interface
Die verarbeiteten Daten können an Dateisysteme, Datenbanken und Live-Dashboards weitergeleitet werden.
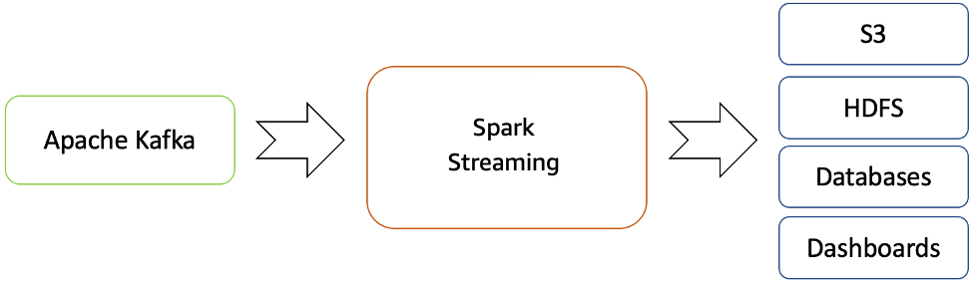
Echtzeit-Streaming-Fluss von Apache Kafka zur Hadoop-Umgebung
Apache Spark Streaming verfügt standardmäßig über ein Micro-Batch-Ausführungsmodell. Seit dem Erscheinen von Spark 2.3 hat Apache jedoch einen neuen Verarbeitungsmodus mit niedriger Latenz namens Continuous Processing eingeführt und End-to-End-Latenzen von nur einer Millisekunde mit At-Least-Once-Garantien erreichen kann.
Ohne die Dataset/DataFrames-Operationen in Ihren Abfragen zu ändern, können Sie den Modus entsprechend den Anforderungen Ihrer Anwendung wählen. Einige der Vorteile von Spark Streaming sind:
-
Es bringt die sprachintegrierte API
von Apache Spark in die Datenstromverarbeitung ein, sodass Sie Streaming-Aufträge auf die gleiche Weise schreiben können wie Batch-Aufträge. -
Es unterstützt Java, Scala und Python.
-
Es kann sowohl verlorene Arbeit als auch den Operator-Zustand (z. B. Schiebefenster) wiederherstellen, ohne dass Sie einen zusätzlichen Code eingeben müssen.
-
Durch das Ausführen auf Spark ermöglicht Spark Streaming die Wiederverwendung desselben Codes für die Batch-Verarbeitung, das Verknüpfen von Streams mit historischen Daten oder das Ausführen von Ad-hoc-Abfragen auf dem Stream-Status und das Erstellen leistungsstarker interaktiver Anwendungen, nicht nur für die Analytik.
-
Nachdem der Datenstrom mit Spark Streaming verarbeitet wurde, kann der OpenSearch-Senken-Konnektor verwendet werden, um Daten in den OpenSearch Service-Cluster zu schreiben, und im Gegenzug kann OpenSearch Service mit OpenSearch Dashboards als Verbrauchsebene verwendet werden.
Amazon OpenSearch Service mit OpenSearch Dashboards
OpenSearch Service ist ein verwalteter Service für das einfache Bereitstellen, Betreiben und Skalieren von OpenSearch-Clustern in der AWS Cloud. OpenSearch ist eine beliebte Such- und Analyse-Engine für Anwendungsfälle wie beispielsweise Analysen, Anwendungsüberwachung in Echtzeit und Clickstream-Analysen.
OpenSearch Dashboards
OpenSearch Dashboards bietet eine enge Integration in OpenSearch
Übersicht
Mit Apache Kafka, das als verwalteter Service in AWS angeboten wird, können Sie sich auf die Nutzung statt auf die Verwaltung der Koordination zwischen den Brokern konzentrieren, was in der Regel ein umfassendes Verständnis von Apache Kafka erfordert. Funktionen wie Hochverfügbarkeit, Broker-Skalierbarkeit und differenzierte Zugriffskontrolle werden von der Amazon-MSK-Plattform verwaltet.
Das Unternehmen ABC1Cabs nutzte diese Services, um eine Produktionsanwendung zu erstellen, für die kein Fachwissen in Bezug auf die Infrastrukturverwaltung erforderlich ist. Es konnte sich auf die Verarbeitungsebene konzentrieren, um Daten von Amazon MSK zu nutzen und an die Visualisierungsebene weiterzuleiten.
Spark Streaming auf Amazon EMR kann die Echtzeitanalyse von Streaming-Daten und die Veröffentlichung auf OpenSearch-Dashboards
