Schritt 1: Daten sammeln und aggregieren
Die folgende Abbildung zeigt ein mentales Modell für das Prognoseproblem. Ziel ist es, die Zeitreihe z_t in die Zukunft zu prognostizieren und dabei so viele relevante Informationen wie möglich zu verwenden, um eine möglichst präzise Prognose zu liefern. Deshalb besteht der erste und wichtigste Schritt darin, so viele richtige Daten wie möglich zu sammeln.

Eine Zeitreihe z_t mit dazugehörigen Merkmalen oder Kovariaten (x_t) und mehreren Prognosen
In der vorherigen Abbildung sind rechts neben der vertikalen Linie mehrere Prognosen dargestellt. Diese Prognosen sind Stichproben aus der probabilistischen Prognoseverteilung (oder können im Gegenteil zur Darstellung der probabilistischen Prognose verwendet werden).
Die wichtigsten Daten, die ein Einzelhandelsunternehmen erfassen muss, sind:
-
Transaktionsdaten: Zum Beispiel Stock Keeping Unit (SKU), Standort, Zeitstempel und verkaufte Einheiten.
-
Detaillierte SKU-Daten: Metadaten eines Artikels. Z. B. Farbe, Abteilung, Größe usw.
-
Preisdaten: Die Preiszeitreihe jedes Artikels mit Zeitstempeln.
-
Daten zu Werbeaktionen: Verschiedene Arten von Werbeaktionen, entweder für eine Sammlung an Artikeln (Kategorie) oder für einzelne Artikel mit Zeitstempeln.
-
Lagerinformationen: Information, die für jede einzelne Zeiteinheit angibt, ob eine SKU vorrätig war oder noch gekauft werden konnte oder im Gegenteil nicht mehr vorrätig war.
-
Standortdaten: Der Standort eines Artikels oder Verkaufs zu einem bestimmten Zeitpunkt kann als Zeichenfolge
location_idstore_idoder als tatsächliche Geolokalisierung dargestellt werden. Für Geolokalisierungen kann eine Ländervorwahlnummer und eine fünfstellige Postleitzahl verwendet werden oder dielatitude_longitude-Koordinate. Der Standort drückt die „Dimension“ der Transaktion aus.
In Amazon Forecast
Hinweis: Lagerbestandsdaten sind wichtig, da dieses Problem die Nachfrage-Prognose betrifft und nicht die Umsatz-Prognose. Das Unternehmen speichert aber lediglich die Verkaufsdaten. Wenn eine SKU nicht mehr vorrätig ist, ist die Anzahl der Verkäufe geringer als die potenzielle Nachfrage. Daher ist es wichtig zu wissen und festzuhalten, wann solche Fälle auftreten.
Weitere Datensätze, die berücksichtigt werden sollten, sind die Anzahl der Webseitenbesuche, Informationen zu Suchbegriffen, soziale Medien und Wetterinformationen. Oft ist es wichtig, über Vergangenheitsdaten und Zukunftsdaten zu verfügen, um sie in Modellen verwenden zu können. Dies ist eine Voraussetzung für viele Prognosemodelle und für das Backtesting (siehe Abschnitt Schritt 4: Prognoseauswertung).
Bei einigen Prognoseproblemen stimmt die Häufigkeit der Rohdaten perfekt mit der Häufigkeit des Prognoseproblems überein. Ein Beispiel hierfür ist die Anforderung an das Servervolumen, das minutenweise abgetastet wird, wenn Sie eine Prognose im Minutentakt erstellen möchten.
Oft werden für die Aufzeichnung von Daten innerhalb eines Zeitabschnitts eine feinere Frequenz oder schlichtweg zufällige Zeitstempel verwendet, für das Prognoseproblem wird jedoch eine gröbere Granularität festgelegt. Dies kommt häufig in Fallstudien aus dem Bereich Einzelhandel vor. Hier werden die Verkaufsdaten normalerweise als Transaktionsdaten aufgezeichnet. Wenn z. B. Verkäufe getätigt werden, besteht das Format aus einem Zeitstempel mit einer feinen Granularität. Im Anwendungsfall für Prognosen ist eine geringe Granularität wahrscheinlich nicht erforderlich und es ist wahrscheinlich sinnvoller, diese Daten im Stunden- oder Tagesformat zu aggregieren. Hier entspricht die Aggregationsebene dem nachgelagerten Problem, z. B. der Bestandsverwaltung oder der Ressourcenplanung.
Beispiel
In der folgenden Abbildung zeigt das linke Diagramm ein Beispiel für die Rohdaten der Kundenverkäufe, die in Amazon Forecast als CSV-Datei (durch Kommas getrennte Werte) eingegeben werden können. In diesem Beispiel wurde für die Verkaufsdaten ein feineres Tagesraster eingestellt und das Problem besteht darin, die zukünftige wöchentliche Nachfrage auf Basis eines gröberen Zeitrasters vorherzusagen. Amazon Forecast aggregiert die Tageswerte in einer bestimmten Woche imcreate_predictor API-Aufruf.
Das Ergebnis wandelt die Rohdaten in eine Sammlung an wohlgeformten Zeitreihen um, für die eine wöchentliche Frequenz eingestellt wurde. Das rechte Diagramm veranschaulicht diese Aggregation für die Zielzeitreihe, wobei für die Aggregation als Summe die Standardmethode verwendet wird. Andere Aggregationsmethoden unterstützen Berechnungen von Mittelwert, Maximum, Minimum oder die Auswahl eines einzelnen (z. B. des ersten) Punktes. Die Aggregationsgranularität und die Methode müssen so gewählt werden, dass sie genau zu dem Anwendungsfall der Daten passen. In diesem Beispiel entspricht der aggregierte Wert der wöchentlichen Aggregation. Benutzer können andere Aggregationsmethoden mithilfe desFeaturizationMethodParameters-Schlüssels desFeaturizationConfig-Parameters dercreate_predictor-API einstellen.
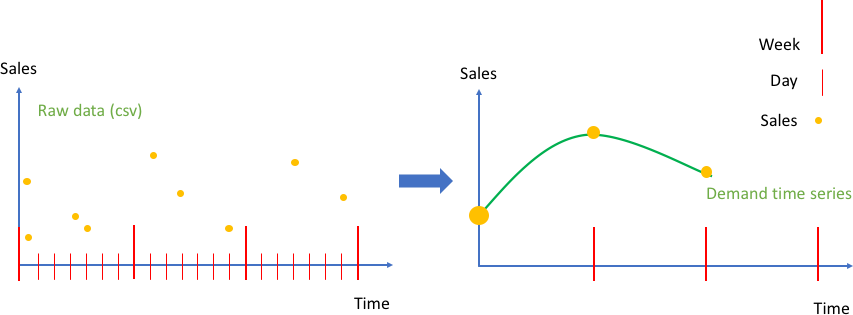
Aggregation von Rohverkaufsdaten zu Ereignissen (links), eine Zeitreihe mit gleichen Intervallen (rechts)
