Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Instrumentierungsfunktionen AWS Lambda
Anmerkung
SDK/Daemon X-Ray-Wartungshinweis — Am 25. Februar 2026 wechselt das AWS X-Ray SDKs/Daemon in den Wartungsmodus, in dem die Versionen von X-Ray SDK und Daemon auf Sicherheitsprobleme beschränkt AWS werden. Weitere Informationen zum Zeitplan für den Support finden Sie unter. Zeitplan für die Support von X-Ray SDK und Daemon Wir empfehlen die Migration zu OpenTelemetry. Weitere Informationen zur Migration zu OpenTelemetry finden Sie unter Migration von X-Ray-Instrumentierung zu OpenTelemetry Instrumentierung.
Scorekeep verwendet zwei Funktionen. AWS Lambda Bei der ersten handelt es sich um eine Node.js-Funktion der lambda-Verzweigung, die zufällige Namen für neue Benutzer generiert. Wenn ein Benutzer eine Sitzung erstellt, ohne einen Namen einzugeben, ruft die Anwendung eine Funktion namens random-name mit dem AWS SDK für Java auf. Das X-Ray SDK for Java zeichnet Informationen über den Aufruf von Lambda in einem Untersegment auf, wie jeder andere Aufruf, der mit einem instrumentierten AWS SDK-Client getätigt wird.
Anmerkung
Die Ausführung der random-name Lambda-Funktion erfordert die Erstellung zusätzlicher Ressourcen außerhalb der Elastic Beanstalk Beanstalk-Umgebung. Weitere Informationen und Anweisungen finden Sie in der Readme-Datei: AWS
Lambda Integration
Die zweite Funktion, scorekeep-worker, ist eine Python-Funktion, die unabhängig von der Scorekeep-API ausgeführt wird. Wenn ein Spiel endet, schreibt die API die Sitzungs- und Spiele-ID in eine SQS-Warteschlange. Die Worker-Funktion liest Elemente aus der Warteschlange und ruft die Scorekeep-API auf, um vollständige Aufzeichnungen jeder Spielsitzung für die Speicherung in Amazon S3 zu erstellen.
Scorekeep enthält CloudFormation Vorlagen und Skripte zur Erstellung beider Funktionen. Da Sie das X-Ray-SDK mit dem Funktionscode bündeln müssen, erstellen die Vorlagen die Funktionen ohne Code. Wenn Sie Scorekeep bereitstellen, erstellt eine im Ordner .ebextensions enthaltene Konfigurationsdatei ein Quell-Bundle, in dem das SDK enthalten ist, und aktualisiert den Funktionscode und die Konfiguration mit der AWS Command Line Interface.
Funktionen
Zufälliger Name
Scorekeep ruft die Funktion für zufällige Namen auf, wenn ein Benutzer eine Spielesitzung beginnt, ohne dass er sich anmeldet oder einen Benutzernamen angibt. Wenn Lambda den Aufruf von verarbeitetrandom-name, liest es den Tracing-Header, der die vom X-Ray SDK for Java geschriebene Trace-ID und die Sampling-Entscheidung enthält.
Für jede gesampelte Anfrage führt Lambda den X-Ray-Daemon aus und schreibt zwei Segmente. Das erste Segment zeichnet Informationen über den Aufruf von Lambda auf, der die Funktion aufruft. Dieses Segment enthält dieselben Informationen wie das von Scorekeep aufgezeichnete Untersegment, jedoch aus Lambda-Sicht. Das zweite Segment repräsentiert die von der Funktion durchgeführte Arbeit.
Lambda übergibt das Funktionssegment über den Funktionskontext an das X-Ray-SDK. Wenn Sie eine Lambda-Funktion instrumentieren, verwenden Sie das SDK nicht, um ein Segment für eingehende Anfragen zu erstellen. Lambda stellt das Segment bereit, und Sie verwenden das SDK, um Clients zu instrumentieren und Untersegmente zu schreiben.
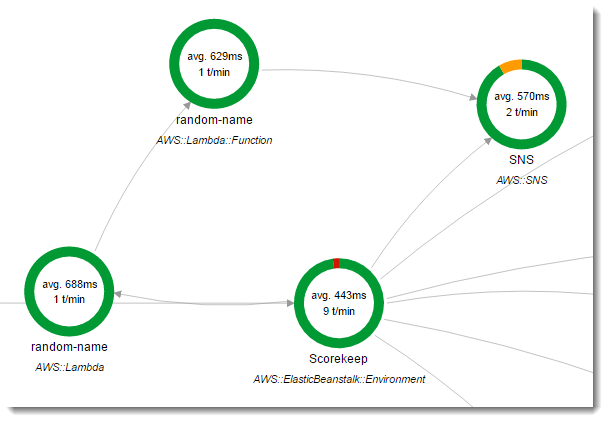
Die random-name-Funktion wird in Node.js implementiert. Es verwendet das SDK für JavaScript in Node.js, um Benachrichtigungen mit Amazon SNS zu senden, und das X-Ray SDK für Node.js, um den SDK-Client zu AWS instrumentieren. Zum Schreiben von Anmerkungen erstellt die Funktion ein benutzerdefiniertes Untersegment mit AWSXRay.captureFunc und schreibt die Anmerkungen in die instrumentierte Funktion. In Lambda können Sie Anmerkungen nicht direkt in das Funktionssegment schreiben, sondern nur in ein Untersegment, das Sie erstellen.
Beispiel function/index.js
var AWSXRay = require('aws-xray-sdk-core');
var AWS = AWSXRay.captureAWS(require('aws-sdk'));
AWS.config.update({region: process.env.AWS_REGION});
var Chance = require('chance');
var myFunction = function(event, context, callback) {
var sns = new AWS.SNS();
var chance = new Chance();
var userid = event.userid;
var name = chance.first();
AWSXRay.captureFunc('annotations', function(subsegment){
subsegment.addAnnotation('Name', name);
subsegment.addAnnotation('UserID', event.userid);
});
// Notify
var params = {
Message: 'Created randon name "' + name + '"" for user "' + userid + '".',
Subject: 'New user: ' + name,
TopicArn: process.env.TOPIC_ARN
};
sns.publish(params, function(err, data) {
if (err) {
console.log(err, err.stack);
callback(err);
}
else {
console.log(data);
callback(null, {"name": name});
}
});
};
exports.handler = myFunction;Diese Funktion wird automatisch erstellt, wenn Sie die Beispielanwendung für Elastic Beanstalk bereitstellen. Der xray Zweig enthält ein Skript zum Erstellen einer leeren Lambda-Funktion. Die Konfigurationsdateien im .ebextensions Ordner erstellen das Funktionspaket mit npm install während der Bereitstellung und aktualisieren dann die Lambda-Funktion mit der AWS CLI.
Worker
Die instrumentierten Worker-Funktion wird in einer eigenen Verzweigung, xray-worker, bereitgestellt, da sie nur ausgeführt werden kann, wenn Sie die Worker-Funktion und verwandte Ressourcen zuerst erstellen. Detaillierte Anweisungen finden Sie in der Readme-Datei zur Verzweigung
Die Funktion wird alle 5 Minuten durch ein gebündeltes Amazon CloudWatch Events-Ereignis ausgelöst. Wenn sie ausgeführt wird, ruft die Funktion ein Element aus einer Amazon SQS SQS-Warteschlange ab, die von Scorekeep verwaltet wird. Jede Nachricht enthält Informationen zu einem abgeschlossenen Spiel.
Der Worker ruft den Spieledatensatz und die Spieledokumente von anderen Tabellen ab, auf die der Spieledatensatz verweist. Beispielsweise enthält der Spieldatensatz in DynamoDB eine Liste der Züge, die während des Spiels ausgeführt wurden. Die Liste enthält nicht die Züge selbst, sondern IDs Züge, die in einer separaten Tabelle gespeichert sind.
Sitzungen und Status werden ebenfalls als Referenzen gespeichert. Auf diese Weise wird verhindert, dass die Einträge in der Spieletabelle zu groß werden. Allerdings sind zusätzliche Aufrufe notwendig, um alle Informationen zum Spiel zu erhalten. Der Worker dereferenziert all diese Einträge und erstellt eine vollständige Aufzeichnung des Spiels als einzelnes Dokument in Amazon S3. Wenn Sie die Daten analysieren möchten, können Sie Abfragen direkt in Amazon S3 mit Amazon Athena ausführen, ohne leseintensive Datenmigrationen durchführen zu müssen, um Ihre Daten aus DynamoDB zu holen.
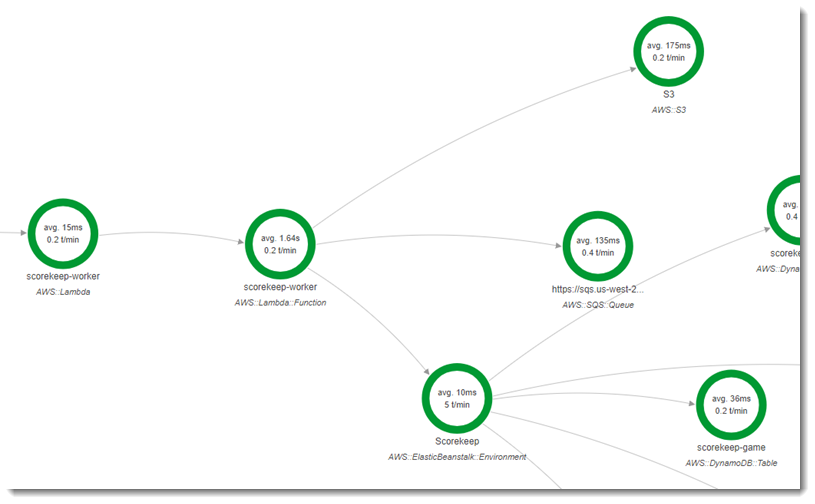
Für die Worker-Funktion ist die aktive Nachverfolgung in der Konfiguration in AWS Lambda aktiviert. Im Gegensatz zur Funktion mit zufälligen Namen erhält der Worker keine Anfrage von einer instrumentierten Anwendung und somit auch AWS Lambda keinen Tracing-Header. Bei aktivem Tracing erstellt Lambda die Trace-ID und trifft Stichprobenentscheidungen.
Das X-Ray-SDK für Python ist nur ein paar Zeilen am Anfang der Funktion, die das SDK importieren und seine patch_all Funktion zum Patchen ausführen AWS SDK für Python (Boto) und HTTclients die zum Aufrufen von Amazon SQS und Amazon S3 verwendet werden. Wenn der Auftragnehmer die Scorekeep-API aufruft, fügt das SDK den Ablaufverfolgungs-Header zur Anforderung hinzu, um Aufrufe über die API nachzuverfolgen.
Beispiel_lambda/scorekeep-worker/scorekeep-worker.py
import os
import boto3
import json
import requests
import time
from aws_xray_sdk.core import xray_recorder
from aws_xray_sdk.core import patch_all
patch_all()
queue_url = os.environ['WORKER_QUEUE']
def lambda_handler(event, context):
# Create SQS client
sqs = boto3.client('sqs')
s3client = boto3.client('s3')
# Receive message from SQS queue
response = sqs.receive_message(
QueueUrl=queue_url,
AttributeNames=[
'SentTimestamp'
],
MaxNumberOfMessages=1,
MessageAttributeNames=[
'All'
],
VisibilityTimeout=0,
WaitTimeSeconds=0
)
...