Performing a cross-Region failback
AWS Elastic Disaster Recovery (AWS DRS) allows you to perform failover and failback your EC2-based applications from one AWS Region to another AWS Region. The failover process is the same as failing over into an AWS Region from a source outside of AWS, but the failback process is different. The instructions below describe the complete cross-Region failover and failback process. In the examples, we use us-east-1 as the source AWS Region and us-east-2 as the recovery AWS Region, but any combination of AWS Regions that are supported by DRS will work.
Note
Cross-Partition failback features between commercial, and AWS GovCloud partitions are not supported. Cross-Region failback features within the AWS GovCloud partition are available between AWS GovCloud Regions (us-gov-west-1 and us-gov-east-1)
Overview and prerequisites
The failback process starts after the failover process ends. During failover, AWS DRS allows you to replace the EC2 source instance (A1) with the EC2 recovered instance (B3). The current AWS resource state is illustrated in this diagram:
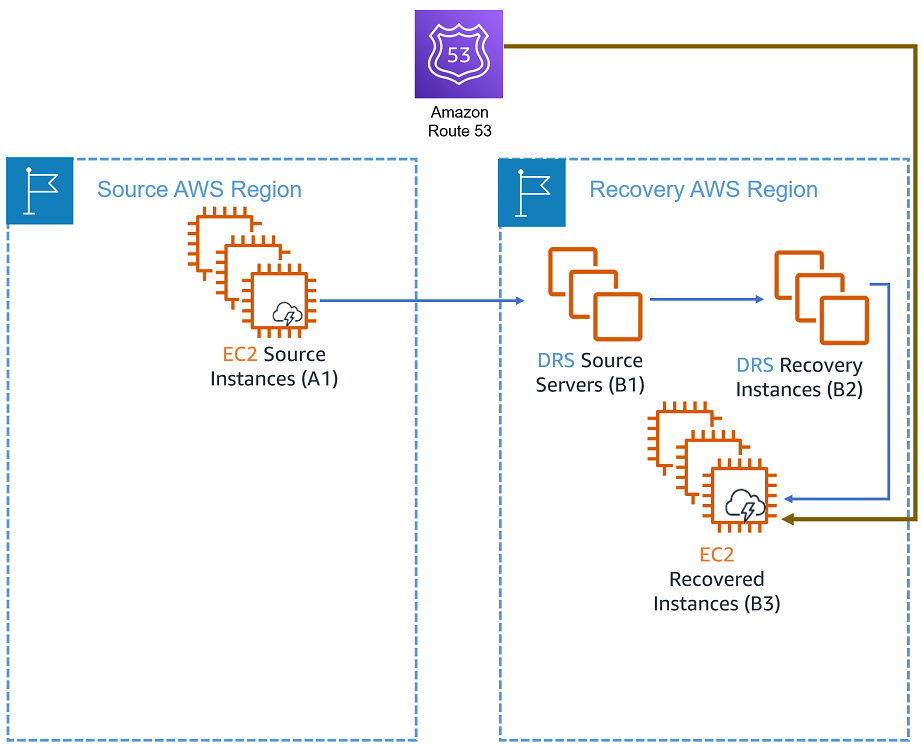
After performing a recovery, your applications are running on EC2 instances in the recovery region. However, these recovered instances (marked B3 in the diagram above) are not protected against other potential outages. In order to avoid data loss, you should start a reversed replication immediately. Starting reversed replication involves copying the data from the EC2 recovered instances (B3) to the original region, an operation that takes time and incurs cross-Region data transfer costs.
Once replication has reached a healthy state, failing back to the source region is possible using the DRS console on that region, assuming DRS has been initialized in the source region.
Important
-
To ensure operational continuity, initialize the AWS DRS in advance in both the source and target AWS Regions, and conduct regular failover and failback drills.
-
Before starting a failback, make sure the EC2 recovered instances (B3) have a network interface while meeting the specified network requirements.
-
Access to EC2 instance metadata is required. If you have a custom network setup that modifies the operating system route, ensure that access to metadata is intact. Learn how to verify metadata access for Linux and for Windows.
-
EC2 Instances that have failed over must resolve via DNS the regional DRS endpoint of the failback region. The resolved endpoint must be accessible from the EC2 Instance via TCP 443.
Performing cross-region failback
-
Start reversed replication.
-
Go to the recovery AWS Region (in this example, us-east-2).
-
Choose the AWS Elastic Disaster Recovery service.
-
Navigate to the Recovery instances page.
-
Select the servers that you want to protect and click Start reversed replication.
-
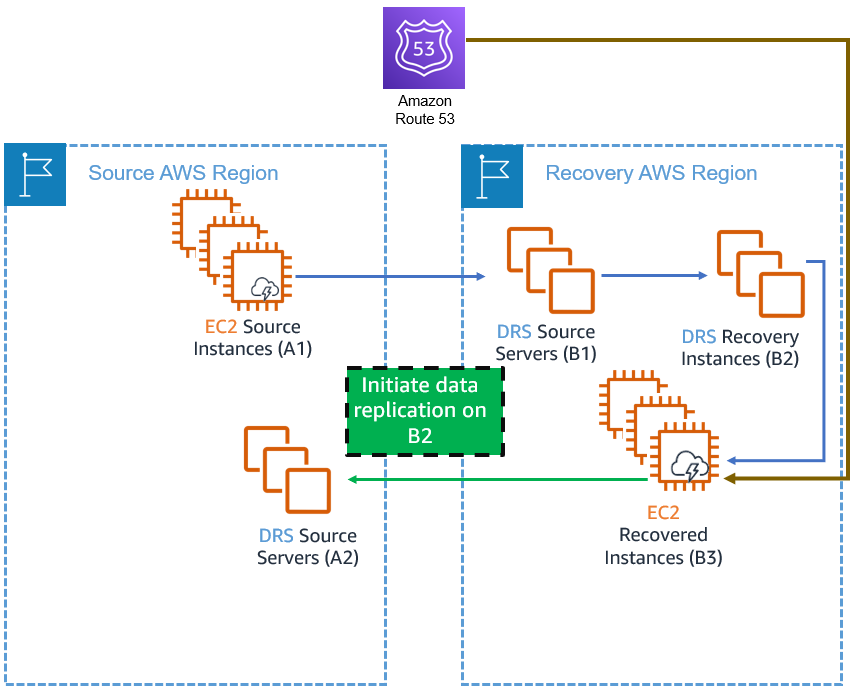
A Source server (A2) will be created in the source region, as shown in this diagram.
Note
All server data is transferred over the wire during this step. This process could take some time and will result in cross-Region data transfer costs
. Moreover, starting reversed replication creates additional replication resources (A2). To avoid double billing, you can stop replicating the source instances (A1) by navigating to the AWS DRS source server in the recovery region (B1) and clicking Stop replication in the replication drop-down menu. Make sure that you only stop the replication after validating the failover instances because once replication is stopped, all previous points in time are deleted. Important
Once replication is stopped, all previous points in time are deleted. This is done to minimize costs.
-
-
Launch, validate, and redirect traffic.
After the Reversed direction launch state is marked as Ready, take these steps to complete the failback:
-
Find the relevant source servers (A2) in the source region by clicking the Replicating to source server link in the recovery instance (B2).
Note
You can also find it directly on the Source servers page in AWS DRS console at the source region.
-
If the state is Ready (or Ready with lag), click Launch for failback under Initiate recovery job.
Important
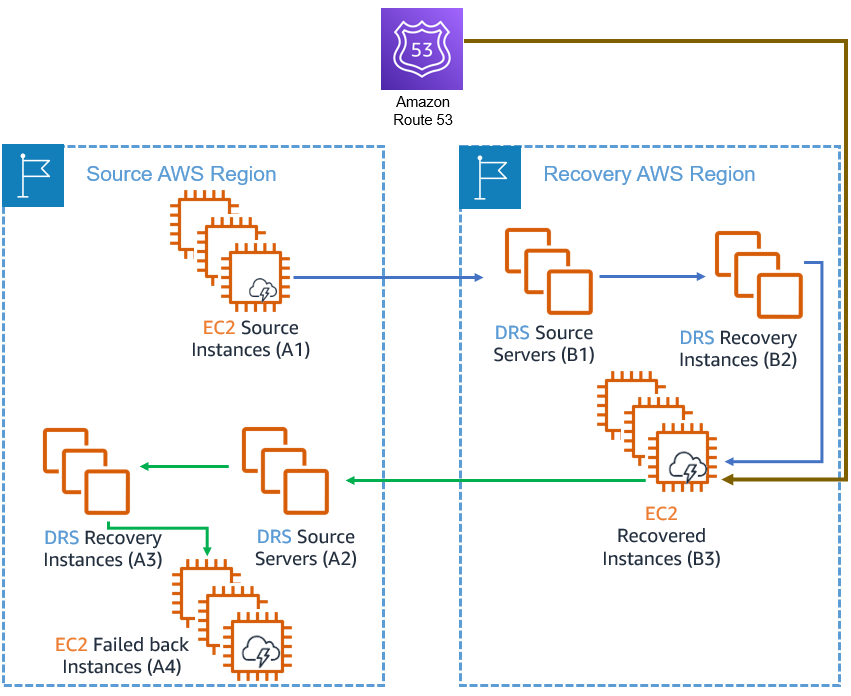
Make sure that your applications (A4) are working as expected. If you run into any issues, you can relaunch the instances and try again. Until you opt to failback, your recovery instances (B3) will continue to run in your recovery AWS Region to ensure business continuity.
-
Redirect traffic to failed back instances (A4), which will now become your new primary instances. Traffic redirection is not conducted using DRS. Choose a service according to your preferences (consider using Amazon Route 53).
-
-
Protect your new failed back instances.
Important
Do not perform this step when performing a drill. This step replaces the instances that AWS DRS replicates (from the Source instances, A1, to the failed back instances, A4). In a drill, the source instances (A1) are still your production environment.
The newly launched failed-back instances (A4) are not protected. In order to protect them, follow these steps:
-
Navigate to the recovery instance (A3) in the source region.
-
Click Start reversed replication. This step will replace the Instances that the Source Server (B1) protects (A4 instead of A1).

-
-
Clean your environment.
After the failover to failback cycle is complete, you may be left with multiple AWS resources that you no longer need and that are costly to maintain. These include the source and failover EC2 instances (A1,B3), the recovery instances (B2, A3), and the Source servers (A2). Consider removing them.
Cleanup steps:
-
Stop replication on the source servers (A2) of the source region.
Navigate to the source server in the source region (A2), and click on Stop replication under the Replication menu. This step is required before terminating the recovery instance (B2).
-
Terminate the recovery instances (B2).
These instances, launched in your recovery AWS Region, are no longer needed now that you have launched new primary instances in your original source AWS Region. To terminate these instances, navigate to the AWS DRS Console in your recovery AWS Region (B2). After termination, those instances will no longer appear in the Recovery Instances page of the DRS Console. This process also terminates the recovered EC2 instances (B3).
-
Terminate the source region EC2 instances (A1).
These have now been replaced by the new instances launched in step 2 above (EC2 failed back instances, A3). You might have stopped these instances after the failover, and you can now terminate them using the AWS EC2 Console.
-
Remove the recovery instance (A3) in the source region.
Navigate to the Recovery instances in the AWS DRS console. Select the relevant recovery instance and click Delete server under the Action drop-down menu.
Note
If you have started reversed replication for the recovery instance (A3), you will not be able to disconnect it. To remove the recovery instances (A3) in the source region, simply delete the server. This will ensure that the newly launched failed-back instances (A4) remains protected.
-
Remove the source servers (A2) in the source region.
Navigate to the Source servers in the AWS DRS console. Select the relevant source server and select Disconnect from AWS under the Actions drop-down menu. Then, select Delete server under the same Actions menu.
-
Performing a drill
To conduct a drill, follow the steps 1 and 2 as described above, and then perform a different cleanup process as described below.
Note
-
Do not to stop the source server (B1) in the recovery AWS region as recommended in the note of step 1-e.
-
Do not perform step 3, Protecting the failed back instances would affect your production data.
Cleaning up after a drill
After a successful drill your AWS environment should look like this:

The only two AWS resources that need to remain are your actual production environment (A1) and its replication backup (B1). Since DRS protects replication servers, you must stop the replication first.
-
Stop the replication of the Source servers (A2) in the Source region.
Important
Make sure you don’t stop replicating the Source servers (B1) in the recovery region.
-
Terminate the recovery instances (A3) in the source region and the recovery instances (B2) in the recovery region. As a result of this action, both the recovered instances (B3) and the failback instances (A4) are terminated as well.
Note
Performing cross-region replication, failover and failback accrues
additional costs, not detailed in the AWS DRS pricing
examples
